Tidigare publicerade vi en blogg som diskuterade Achieving MySQL Failover &Failback på Google Cloud Platform (GCP) och i den här bloggen kommer vi att titta på hur den konkurrent, Amazon Relational Database Service (RDS), hanterar failover. Vi kommer också att titta på hur du kan utföra en failback av din tidigare huvudnod och återföra den till sin ursprungliga ordning som en master.
När man jämför de tekniska gigantiska offentliga molnen som stöder hanterade relationsdatabastjänster, är Amazon den enda som erbjuder ett alternativt alternativ (tillsammans med MySQL/MariaDB, PostgreSQL, Oracle och SQL Server) för att leverera sin egen typ av databashantering kallad Amazon Aurora. För de som inte är bekanta med Aurora är det en helt hanterad relationsdatabasmotor som är kompatibel med MySQL och PostgreSQL. Aurora är en del av den hanterade databastjänsten Amazon RDS, en webbtjänst som gör det enkelt att sätta upp, driva och skala en relationsdatabas i molnet.
Varför skulle du behöva failover eller failback?
Att designa ett stort system som är feltolerant, högtillgängligt och utan Single-Point-Of-Failure (SPOF) kräver ordentliga tester för att avgöra hur det skulle reagera när saker går fel.
Om du är orolig över hur ditt system skulle prestera när det reagerar på ditt systems feldetektering, isolering och återställning (FDIR), bör failover och failback vara av stor vikt.
Databasfailover i Amazon RDS
Failover sker automatiskt (eftersom manuell failover kallas växling). Som diskuterats i en tidigare blogg uppstår behovet av failover när din nuvarande databasmaster upplever ett nätverksfel eller onormal avslutning av värdsystemet. Failover växlar den till ett stabilt tillstånd av redundans eller till en standby-datorserver, system, hårdvarukomponent eller nätverk.
I Amazon RDS behöver du inte göra detta, och du behöver inte heller övervaka det själv, eftersom RDS är en hanterad databastjänst (vilket innebär att Amazon sköter jobbet åt dig). Den här tjänsten hanterar saker som hårdvaruproblem, säkerhetskopiering och återställning, programuppdateringar, lagringsuppgraderingar och till och med programvarukorrigering. Vi kommer att prata om det senare i den här bloggen.
Databasfel i Amazon RDS
I den förra bloggen tog vi också upp varför du skulle behöva failback. I en typisk replikerad miljö måste mastern vara tillräckligt kraftfull för att bära en enorm belastning, speciellt när arbetsbelastningskravet är högt. Din huvudinställning kräver adekvata hårdvaruspecifikationer för att säkerställa att den kan bearbeta skrivningar, generera replikeringshändelser, bearbeta kritiska läsningar, etc, på ett stabilt sätt. När failover krävs under katastrofåterställning (eller för underhåll) är det inte ovanligt att när du marknadsför en ny master kan du använda sämre hårdvara. Den här situationen kan vara okej tillfälligt, men i det långa loppet måste den utsedda mastern tas tillbaka för att leda replikeringen efter att den bedömts vara frisk (eller underhållet har slutförts).
Tvärtemot failover, sker failback-operationer vanligtvis i en kontrollerad miljö genom att använda switchover. Det görs sällan i panikläge. Detta tillvägagångssätt ger dina ingenjörer tillräckligt med tid att planera noggrant och repetera övningen för att säkerställa en smidig övergång. Dess huvudsakliga mål är att helt enkelt föra tillbaka den goda, gamla mästaren till det senaste tillståndet och återställa replikeringsinställningarna till dess ursprungliga topologi. Eftersom vi har att göra med Amazon RDS, behöver du verkligen inte oroa dig för den här typen av problem eftersom det är en hanterad tjänst där de flesta jobb hanteras av Amazon.
Hur hanterar Amazon RDS databasfel?
När du distribuerar dina Amazon RDS-noder kan du ställa in ditt databaskluster med Multi-Availability Zone (AZ) eller till en Single-Availability Zone. Låt oss kontrollera var och en av dem om hur failover bearbetas.
Vad är en Multi-AZ-installation?
När en katastrof eller katastrof inträffar, till exempel oplanerade avbrott eller naturkatastrofer där dina databasinstanser påverkas, växlar Amazon RDS automatiskt till en standby-replika i en annan tillgänglighetszon. Denna A-Ö finns vanligtvis i en annan gren av datacentret, ofta långt från den aktuella tillgänglighetszonen där instanser finns. Dessa A-Ö är mycket tillgängliga, toppmoderna faciliteter som skyddar dina databasinstanser. Failovertider beror på slutförandet av installationen som ofta baseras på databasens storlek och aktivitet samt andra förhållanden som fanns när den primära DB-instansen blev otillgänglig.
Undervikelsetider är vanligtvis 60-120 sekunder. De kan dock vara längre, eftersom stora transaktioner eller en långvarig återställningsprocess kan öka failover-tiden. När övergången är klar kan det också ta ytterligare tid för RDS-konsolen (UI) att återspegla den nya tillgänglighetszonen.
Vad är en Single-AZ-installation?
Single-AZ-inställningar bör endast användas för dina databasinstanser om din RTO (Recovery Time Objective) och RPO (Recovery Point Objective) är tillräckligt höga för att tillåta det. Det finns risker med att använda en Single-AZ, som stora stilleståndstider som kan störa affärsverksamheten.
Vanliga RDS-felscenarier
Mängden stillestånd beror på typen av fel. Låt oss gå igenom vad dessa är och hur återställning av instansen hanteras.
Återställbar instansfel
Ett Amazon RDS-instansfel uppstår när den underliggande EC2-instansen drabbas av ett fel. Vid händelse kommer AWS att utlösa ett händelsemeddelande och skicka ut en varning till dig med hjälp av Amazon RDS Event Notifications. Detta system använder AWS Simple Notification Service (SNS) som varningsprocessor.
RDS kommer automatiskt att försöka starta en ny instans i samma tillgänglighetszon, ansluter EBS-volymen och försöker återställa. I det här scenariot är RTO vanligtvis under 30 minuter. RPO är noll eftersom EBS-volymen kunde återvinnas. EBS-volymen finns i en enda tillgänglighetszon och denna typ av återställning sker i samma tillgänglighetszon som den ursprungliga instansen.
Icke-återställningsbara instansfel eller EBS-volymfel
För misslyckad RDS-instansåterställning (eller om den underliggande EBS-volymen drabbas av ett dataförlustfel) krävs punkt-i-tidsåterställning (PITR). PITR hanteras inte automatiskt av Amazon, så du måste antingen skapa ett skript för att automatisera det (med AWS Lambda) eller göra det manuellt.
RTO-timingen kräver att du startar en ny Amazon RDS-instans, som kommer att ha ett nytt DNS-namn när det väl skapats, och sedan tillämpar alla ändringar sedan den senaste säkerhetskopieringen.
RPO:n är vanligtvis 5 minuter, men du kan hitta den genom att ringa RDS:describe-db-instances:LatestRestorableTime. Tiden kan variera från 10 minuter till timmar beroende på antalet stockar som behöver appliceras. Det kan endast fastställas genom att testa eftersom det beror på storleken på databasen, antalet ändringar som gjorts sedan den senaste säkerhetskopieringen och arbetsbelastningsnivåerna på databasen. Eftersom säkerhetskopiorna och transaktionsloggarna lagras i Amazon S3, kan denna återställning ske i vilken tillgänglig tillgänglighetszon som helst i regionen som stöds.
När den nya instansen har skapats måste du uppdatera din klients slutpunktsnamn. Du har också möjlighet att byta namn på den till den gamla DB-instansens slutpunktsnamn (men det kräver att du tar bort den gamla misslyckade instansen), men det gör det omöjligt att fastställa grundorsaken till problemet.
Störningar i tillgänglighetszonen
avbrott i tillgänglighetszonen kan vara tillfälliga och är sällsynta, men om AZ-felet är mer permanent kommer instansen att ställas in på ett misslyckat tillstånd. Återställningen skulle fungera som beskrivits tidigare och en ny instans skulle kunna skapas i en annan A-Ö, med hjälp av punkt-i-tidsåterställning. Detta steg måste göras manuellt eller genom skript. Strategin för denna typ av återställningsscenario bör vara en del av dina större planer för katastrofåterställning (DR).
Om felet i tillgänglighetszonen är tillfälligt kommer databasen att vara nere men förblir i tillgängligt tillstånd. Du ansvarar för övervakning på applikationsnivå (med antingen Amazons eller tredjepartsverktyg) för att upptäcka denna typ av scenario. Om detta inträffar kan du vänta tills tillgänglighetszonen återställs, eller så kan du välja att återställa instansen till en annan tillgänglighetszon med en återställning vid tidpunkten.
RTO skulle vara den tid det tar att starta upp en ny RDS-instans och sedan tillämpa alla ändringar sedan den senaste säkerhetskopieringen. RPO:n kan vara längre fram till den tidpunkt då tillgänglighetszonfelet inträffade.
Testar Failover och Failback på Amazon RDS
Vi skapade och konfigurerade en Amazon RDS Aurora med db.r4.large med en Multi-AZ-distribution (som kommer att skapa en Aurora-replika/läsare i en annan Aurora) som endast är tillgänglig via EC2. Du måste se till att välja det här alternativet vid skapandet om du tänker ha Amazon RDS som failover-mekanism.
Under provisioneringen av vår RDS-instans tog det ungefär ~11 minuter innan instanserna blev tillgängliga och tillgängliga. Nedan är en skärmdump av noderna som är tillgängliga i RDS efter skapandet:
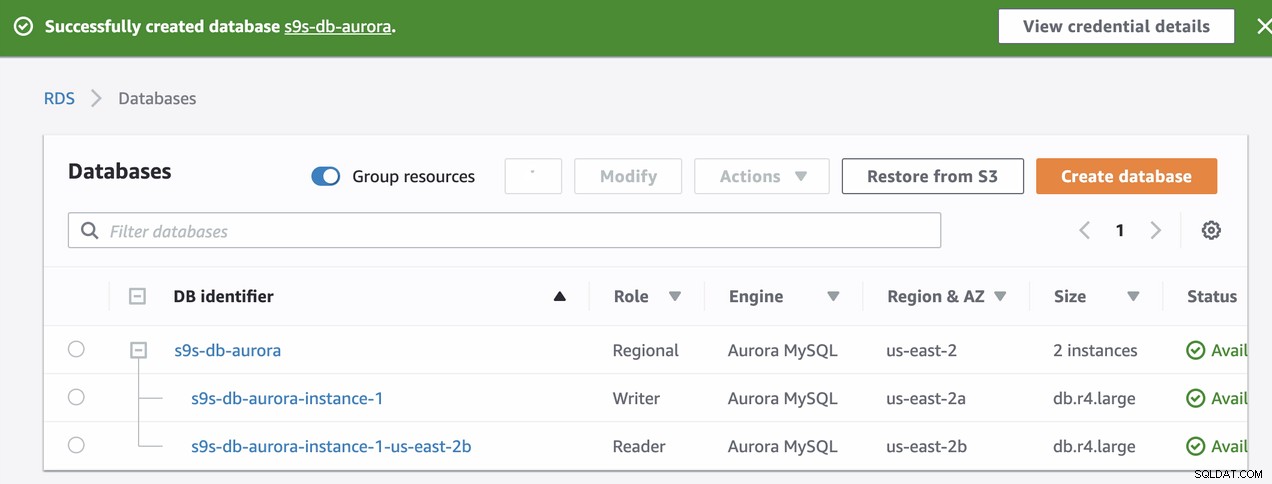
Dessa två noder kommer att ha sina egna angivna slutpunktsnamn, som vi kommer att använda för att ansluta från klientens perspektiv. Verifiera det först och kontrollera det underliggande värdnamnet för var och en av dessa noder. För att kontrollera kan du köra det här bash-kommandot nedan och bara ersätta värdnamnen/slutpunktsnamnen i enlighet med detta:
example@sqldat.com:~# host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done;
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Resultatet förtydligas enligt följande,
s9s-db-aurora-instance-1 = s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-0-94 (read-write)
s9s-db-aurora-instance-1-us-east-2b = s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-1-139 (read-only)Simulerar Amazon RDS-failover
Låt oss nu simulera en krasch för att simulera en failover för Amazon RDS Aurora writer-instansen, som är s9s-db-aurora-instance-1 med slutpunkten s9s-db-aurora.cluster-cmu8qdlvkepg.us -east-2.rds.amazonaws.com.
För att göra detta, anslut till din writer-instans med hjälp av mysql-klientens kommandotolk och utfärda sedan syntaxen nedan:
ALTER SYSTEM SIMULATE percentage_of_failure PERCENT DISK FAILURE [ IN DISK index | NODE index ]
FOR INTERVAL quantity [ YEAR | QUARTER | MONTH | WEEK| DAY | HOUR | MINUTE | SECOND ];Att utfärda detta kommando har dess Amazon RDS-återställningsdetektering och fungerar ganska snabbt. Även om frågan är avsedd för teständamål kan den skilja sig åt när denna händelse inträffar i en faktisk händelse. Du kanske är intresserad av att veta mer om att testa en instanskrasch i deras dokumentation. Se hur vi hamnar nedan:
mysql> ALTER SYSTEM SIMULATE 100 PERCENT DISK FAILURE FOR INTERVAL 3 MINUTE;
Query OK, 0 rows affected (0.01 sec)Att köra SQL-kommandot ovan innebär att det måste simulera diskfel i minst 3 minuter. Jag övervakade tidpunkten för att påbörja simuleringen och det tog cirka 18 sekunder innan failover börjar.
Se nedan om hur RDS hanterar simuleringsfelet och failoveren,
Tue Sep 24 10:06:29 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
….
…..
………..
Tue Sep 24 10:06:44 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
……..
………..
Tue Sep 24 10:06:51 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
….
………..
…………………
Tue Sep 24 10:07:13 UTC 2019
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Resultaten av denna simulering är ganska intressanta. Låt oss ta det här en i taget.
- Omkring 10:06:29 började jag köra simuleringsfrågan enligt ovan.
- Omkring 10:06:44 visar den att slutpunkten s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com med tilldelat värdnamnet ip-10-20-1- 139 där det faktiskt är den skrivskyddade instansen, blev otillgänglig trots att simuleringskommandot kördes under läs-skriv-instansen.
- Omkring 10:06:51 visar den att slutpunkten s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com med tilldelat värdnamn ip-10-20-1- 139 är uppe men har markerat som läs-skriv-tillstånd. Notera att variabeln innodb_read_only, för Aurora MySQL-hanterade instanser, är detta dess identifierare för att avgöra om värden är läs-skriv- eller skrivskyddad nod och Aurora körs också endast på InnoDB-lagringsmotorn för MySQL-kompatibla instanser.
- Omkring 10:07:13 har ordningen ändrats. Detta betyder att failoveren gjordes och att instanserna har tilldelats dess angivna slutpunkter.
Kolla in resultatet nedan som visas i RDS-konsolen:
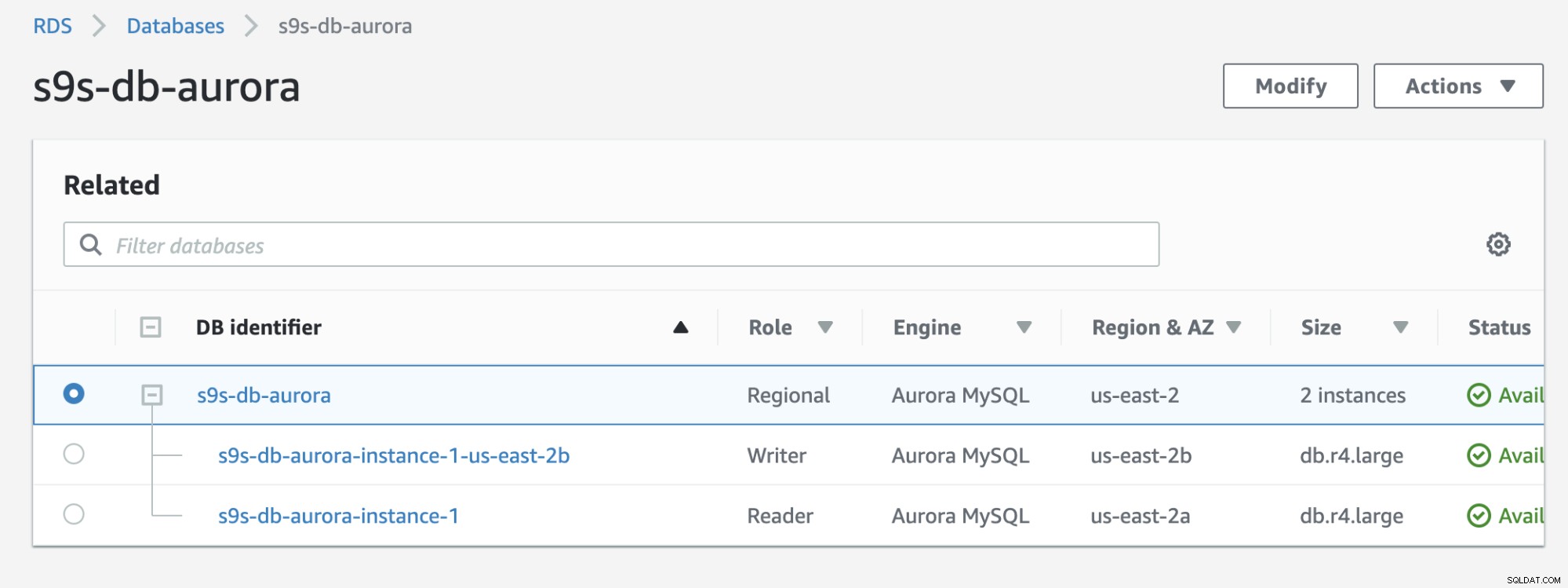
Om du jämför med den tidigare, s9s-db-aurora- instans-1 var en läsare, men befordrades sedan som författare efter failover. Processen inklusive testet tog cirka 44 sekunder för att slutföra uppgiften, men failover visar slutförd på nästan 30 sekunder. Det är imponerande och snabbt för en failover, särskilt med tanke på att detta är en databas för hanterade tjänster; vilket innebär att du inte behöver oroa dig för maskinvaru- eller underhållsproblem.
Utföra en Failback i Amazon RDS
Filback i Amazon RDS är ganska enkelt. Innan vi går igenom det, låt oss lägga till en ny läsarreplik. Vi behöver ett alternativ för att testa och identifiera vilken nod AWS RDS skulle välja från när den försöker misslyckas tillbaka till önskad master (eller failback till föregående master) och för att se om den väljer rätt nod baserat på prioritet. Den aktuella listan över instanser från och med nu och dess slutpunkter visas nedan.
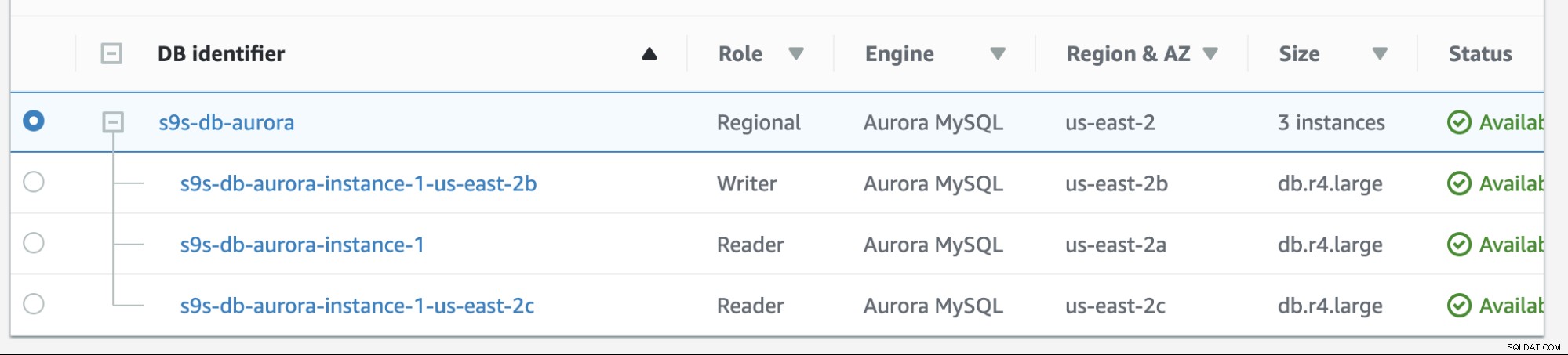

Den nya repliken finns på us-east-2c AZ med db värdnamn av ip-10-20-2-239.
Vi kommer att försöka göra en failback med hjälp av instansen s9s-db-aurora-instance-1 som önskat failback-mål. I den här inställningen har vi två läsarinstanser. För att säkerställa att rätt nod plockas upp under failover, måste du fastställa om prioritet eller tillgänglighet är överst (tier-0> tier-1> tier-2 och så vidare till tier-15). Detta kan göras genom att modifiera instansen eller under skapandet av repliken.
Du kan verifiera detta i din RDS-konsol.
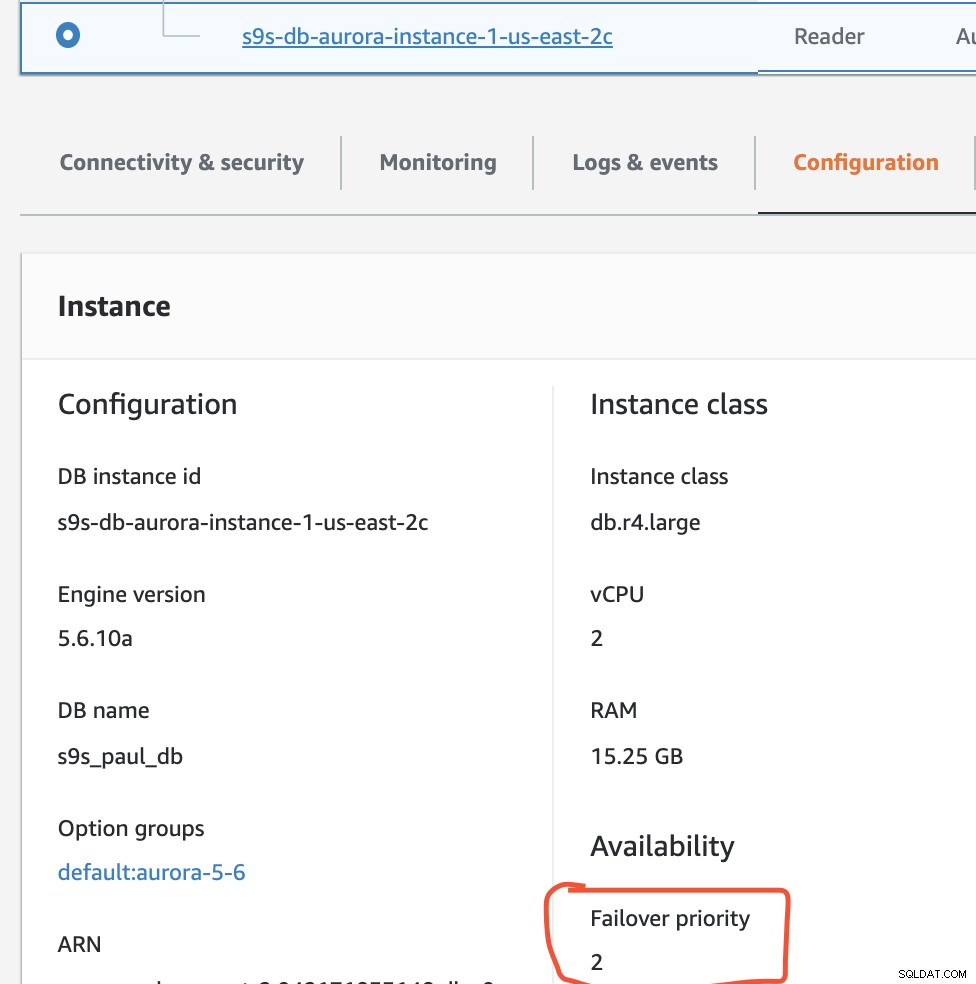
I den här installationen har s9s-db-aurora-instance-1 prioritet =0 (och är en läs-replik), s9s-db-aurora-instans-1-us-east-2b har prioritet =1 (och är den nuvarande skribenten), och s9s-db-aurora-instans-1-us- east-2c har prioritet =2 (och är också en läs-replik). Låt oss se vad som händer när vi försöker göra fel.
Du kan övervaka tillståndet genom att använda detta kommando.
$ host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); while true; do echo -e "\n==========================================="; date; echo -e "===========================================\n"; for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done; sleep 1; done;Efter att failover har utlösts kommer den att failback till vårt önskade mål, som är noden s9s-db-aurora-instance-1.
===========================================
Tue Sep 24 13:30:59 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
…
……
………
===========================================
Tue Sep 24 13:31:35 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
…..
===========================================
Tue Sep 24 13:31:38 UTC 2019
===========================================
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Feilback-försöket startade 13:30:59 och det slutfördes runt 13:31:38 (närmaste 30 sekunder). Det slutar på ~32 sekunder på detta test, vilket fortfarande är snabbt.
Jag har verifierat failover/failback flera gånger och det har konsekvent utbytt sitt läs-skriv-tillstånd mellan instanserna s9s-db-aurora-instance-1 och s9s-db-aurora-instance-1- us-öst-2b. Detta lämnar s9s-db-aurora-instance-1-us-east-2c oplockad om inte båda noderna har problem (vilket är mycket sällsynt eftersom de alla är belägna på olika A-Ö).
Under failover/failback-försöken går RDS i en snabb övergångstakt under failover på cirka 15 - 25 sekunder (vilket är mycket snabbt). Tänk på att vi inte har stora datafiler lagrade på den här instansen, men det är fortfarande ganska imponerande med tanke på att det inte finns något mer att hantera.
Slutsats
Att köra en Single-AZ skapar fara när man utför en failover. Amazon RDS låter dig modifiera och konvertera din Single-AZ till en multi-AZ-kompatibel installation, även om detta kommer att lägga till några kostnader för dig. Single-AZ kan vara bra om du är ok med en högre RTO- och RPO-tid, men rekommenderas definitivt inte för högtrafikerade, verksamhetskritiska affärsapplikationer.
Med Multi-AZ kan du automatisera failover och failback på Amazon RDS, ägna din tid åt att fokusera på frågejustering eller optimering. Detta underlättar många problem som DevOps eller DBAs möter.
Medan Amazon RDS kan orsaka ett dilemma i vissa organisationer (eftersom det inte är plattformsoberoende), är det fortfarande värt att överväga; speciellt om din applikation kräver en långsiktig DR-plan och du inte vill behöva lägga tid på att oroa dig för hårdvara och kapacitetsplanering.