Introduktion
Förr eller senare får vilket informationssystem som helst en databas, ofta – mer än en. Med tiden samlar databasen väldigt mycket data, från flera GB till dussintals TB. För att förstå hur funktionerna kommer att fungera när datavolymerna ökar, måste vi generera data för att fylla databasen.

Alla skript som presenteras och implementeras kommer att köras på JobEmplDB databas för en rekryteringstjänst. Databasförverkligandet finns tillgängligt här.
Tillvägagångssätt för datafyllning i databaser för testning och utveckling
Databasutveckling och testning involverar två primära metoder för att fylla i data:
- Att kopiera hela databasen från produktionsmiljön med personliga och andra känsliga uppgifter ändrade. På så sätt säkerställer du data och raderar konfidentiell data.
- För att generera syntetisk data. Det innebär att man genererar testdata som liknar verkliga data i utseende, egenskaper och sammankopplingar.
Fördelen med Approach 1 är att den approximerar data och deras distribution med olika kriterier till produktionsdatabasen. Det gör det möjligt för oss att analysera allting exakt och därför dra slutsatser och prognoser därefter.
Detta tillvägagångssätt låter dig dock inte utöka själva databasen många gånger. Det blir problematiskt att förutse förändringar i hela informationssystemets funktionalitet i framtiden.
Å andra sidan kan du analysera opersonlig sanerad data hämtad från produktionsdatabasen. Baserat på dem kan du definiera hur du genererar testdata som skulle likna den verkliga data genom deras utseende, egenskaper och inbördes samband. På så sätt producerar Approach 1 Approach 2.
Låt oss nu i detalj granska båda metoderna för datafyllning i databaser för testning och utveckling.
Datakopiering och ändring i en produktionsdatabas
Låt oss först definiera den allmänna algoritmen för att kopiera och ändra data från produktionsmiljön.
Den allmänna algoritmen
Den allmänna algoritmen är som följer:
- Skapa en ny tom databas.
- Skapa ett schema i den nyskapade databasen – samma system som det från produktionsdatabasen.
- Kopiera nödvändig data från produktionsdatabasen till den nyskapade databasen.
- Sanera och ändra den hemliga informationen i den nya databasen.
- Gör en säkerhetskopia av den nyskapade databasen.
- Leverera och återställ säkerhetskopian i nödvändig miljö.
Algoritmen blir dock mer komplicerad efter steg 5. Till exempel kräver steg 6 en specifik, skyddad miljö för preliminär testning. Det steget måste säkerställa att all data är opersonlig och att de hemliga uppgifterna ändras.
Efter det steget kan du återgå till steg 5 igen för den testade databasen i den skyddade icke-produktionsmiljön. Sedan vidarebefordrar du den testade säkerhetskopian till nödvändiga miljöer för att återställa den och använda den för utveckling och testning.
Vi har presenterat den allmänna algoritmen för produktionsdatabasens datakopiering och ändring. Låt oss beskriva hur man implementerar det.
Realisering av den allmänna algoritmen
En ny tom databas skapas
Du kan skapa en tom databas med hjälp av konstruktionen CREATE DATABASE som här.
Databasen heter JobEmplDB_Test . Den har tre filgrupper:
- PRIMÄRT – det är den primära filgruppen som standard. Den definierar två filer:JobEmplDB_Test1(sökväg D:\DBData\JobEmplDB_Test1.mdf) , och JobEmplDB_Test2 (sökväg D:\DBData\JobEmplDB_Test2.ndf) . Varje fils initiala storlek är 64 Mb, och tillväxtsteget är 8 Mb för varje fil.
- DBTableGroup – en anpassad filgrupp som bestämmer två filer:JobEmplDB_TestTableGroup1 (sökväg D:\DBData\JobEmplDB_TestTableGroup1.ndf) och JobEmplDB_TestTableGroup2 (sökväg D:\DBData\JobEmplDB_TestTableGroup2.ndf) . Den initiala storleken på varje fil är 8 Gb, och tillväxtsteget är 1 Gb för varje fil.
- DBIndexGroup – en anpassad filgrupp som bestämmer två filer:JobEmplDB_TestIndexGroup1 (sökväg D:\DBData\JobEmplDB_TestIndexGroup1.ndf) , och JobEmplDB_TestIndexGroup2 (sökväg D:\DBData\JobEmplDB_TestIndexGroup2.ndf) . Den ursprungliga storleken är 16 Gb för varje fil, och tillväxtsteget är 1 Gb för varje fil.
Den här databasen innehåller också en transaktionsjournal:JobEmplDB_Testlog , sökväg E:\DBLog\JobEmplDB_Testlog.ldf . Den ursprungliga storleken på filen är 8 Gb och tillväxtsteget är 1 Gb.
Kopiering av schemat och nödvändiga data från produktionsdatabasen till en nyskapad databas
För att kopiera schemat och nödvändiga data från produktionsdatabasen till den nya kan du använda flera verktyg. För det första är det Visual Studio (SSDT). Eller så kan du använda tredjepartsverktyg som:
- DbForge Schema Compare och DbForge Data Compare
- ApexSQL Diff och Apex Data Diff
- SQL Compare Tool och SQL Data Compare Tool
Gör skript för dataändringar
Väsentliga krav för dataändringarnas skript
1. Det måste vara omöjligt att återställa den verkliga datan med det skriptet.
t.ex. linjernas inversion kommer inte att passa, eftersom det tillåter oss att återställa den verkliga datan. Vanligtvis är metoden att ersätta varje tecken eller byte med ett pseudoslumpmässigt tecken eller byte. Detsamma gäller för datum och tid.
2. Dataändringen får inte ändra selektiviteten för deras värden.
Det fungerar inte att tilldela NULL till tabellens fält. Istället måste du se till att samma värden i den verkliga datan förblir densamma i den ändrade datan. Till exempel, i verkliga data har du ett värde på 103785 hittat 12 gånger i tabellen. När du ändrar detta värde i den ändrade informationen måste det nya värdet finnas kvar 12 gånger i samma fält i tabellen.
3. Storleken och längden på värdena bör inte skilja sig nämnvärt i de ändrade uppgifterna. Till exempel ersätter du varje byte eller tecken med en pseudoslumpmässig byte eller tecken. Den initiala strängen förblir densamma i storlek och längd.
4. Samband i data får inte brytas efter ändringarna. Det gäller de externa nycklarna och alla andra fall där du hänvisar till de ändrade uppgifterna. Ändrade data måste förbli i samma relationer som de verkliga data var.
Implementering av skript för dataändringar
Låt oss nu granska det speciella fallet där data ändras för att avpersonalisera och dölja den hemliga informationen. Exemplet är rekryteringsdatabasen.
Exempeldatabasen innehåller följande personuppgifter som du behöver för att avpersonalisera:
- Efter- och förnamn;
- Födelsedatum;
- ID-kortets utfärdandedatum;
- Fjärråtkomstcertifikatet som bytesekvens;
- Serviceavgiften för CV-kampanj.
Först ska vi kontrollera enkla exempel för varje typ av ändrad data:
- Ändra datum och tid;
- Numerisk värdeändring;
- Ändra bytesekvenserna;
- Ändring av teckendata.
Ändring av datum och tid
Du kan få ett slumpmässigt datum och tid med följande skript:
DECLARE @dt DATETIME;
SET @dt = CAST(CAST(@StartDate AS FLOAT) + (CAST(@FinishDate AS FLOAT) - CAST(@StartDate AS FLOAT)) * RAND(CHECKSUM(NEWID())) AS DATETIME);
Här, @StartDate och @FinishDate är intervallets start- och slutvärden. De korrelerar för pseudoslumpgenereringen av datum och tid.
För att generera dessa data använder du systemfunktionerna RAND, CHECKSUM och NEWID.
UPDATE [dbo].[Employee]
SET [DocDate] = CAST(CAST(CAST(CAST([BirthDate] AS DATETIME) AS FLOAT) + (CAST(GETDATE() AS FLOAT) - CAST(CAST([BirthDate] AS DATETIME) AS FLOAT)) * RAND(CHECKSUM(NEWID())) AS DATETIME) AS DATE);
Fältet [DocDate] står för dokumentets utfärdandedatum. Vi ersätter det med ett pseudoslumpmässigt datum, med tanke på datumintervallen och deras begränsningar.
Den "nedre" gränsen är kandidatens födelsedatum. Den "övre" kanten är det aktuella datumet. Vi behöver inte tiden här, så omvandlingen av tid- och datumformat till det nödvändiga datumet kommer till slut. Du kan få pseudoslumpvärden för vilken del av datum och tid som helst på samma sätt.
Ändring av numerisk värde
Du kan få ett slumpmässigt heltal med hjälp av följande skript:
DECLARE @Int INT;
SET @Int = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS INT);
@MinVal och @MaxVal är start- och slutintervallets värden för genereringen av pseudoslumptal. Vi genererar den med hjälp av systemfunktionerna RAND, CHECKSUM och NEWID.
UPDATE [dbo].[Employee]
SET [CountRequest] = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS INT);
Fältet [CountRequest] står för antalet förfrågningar som företag gör för den här kandidatens CV.
På samma sätt kan du få pseudoslumpvärden för alla numeriska värden. Titta t.ex. på det slumpmässiga talet för generationen av decimaltyp (18,2):
DECLARE @Dec DECIMAL(18,2);
SET @Dec=CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS DECIMAL(18,2));
Således kan du uppdatera avgiften för CV-kampanjtjänsten på följande sätt:
UPDATE [dbo].[Employee]
SET [PaymentAmount] = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS DECIMAL(18,2));
Ändra bytesekvenserna
Du kan få en slumpmässig bytesekvens med följande skript:
DECLARE @res VARBINARY(MAX);
SET @res = CRYPT_GEN_RANDOM(@Length, CAST(NEWID() AS VARBINARY(16)));
@Längd står för sekvensens längd. Den definierar antalet byte som returneras. Här får @Length inte vara större än 16.
Generering sker med hjälp av systemfunktionerna CRYPT_GEN_RANDOM och NEWID.
Du kan till exempel uppdatera fjärråtkomstcertifikatet för varje kandidat på följande sätt:
UPDATE [dbo].[Employee]
SET [RemoteAccessCertificate] = CRYPT_GEN_RANDOM(CAST(LEN([RemoteAccessCertificate]) AS INT), CAST(NEWID() AS VARBINARY(16)));
Vi genererar en pseudoslumpmässig bytesekvens av samma längd som finns i fältet [RemoteAccessCertificate] vid tidpunkten för ändringen. Vi antar att bytesekvenslängden inte överstiger 16.
På liknande sätt kan vi skapa vår funktion som kommer att returnera pseudoslumpmässiga bytesekvenser av valfri längd. Det kommer att få resultaten av systemfunktionen CRYPT_GEN_RANDOM att fungera tillsammans med den enkla "+" additionsoperatorn. Men 16 byte brukar räcka i praktiken.
Låt oss göra en exempelfunktion som returnerar den pseudoslumpmässiga bytesekvensen av den bestämda längden, där det kommer att vara möjligt att ställa in längden på mer än 16 byte. Gör följande presentation för detta:
CREATE VIEW [test].[GetNewID]
AS
SELECT NEWID() AS [NewID];
GO
Vi behöver det för att undvika begränsningen som förbjuder oss att använda NEWID i funktionen.
På samma sätt skapar du nästa presentation för samma syfte:
CREATE VIEW [test].[GetRand]
AS
SELECT RAND(CHECKSUM((SELECT TOP(1) [NewID] FROM [test].[GetNewID]))) AS [Value];
GO
Skapa ytterligare en presentation:
CREATE VIEW [test].[GetRandVarbinary16]
AS
SELECT CRYPT_GEN_RANDOM(16, CAST((SELECT TOP(1) [NewID] FROM [test].[GetNewID]) AS VARBINARY(16))) AS [Value];
GO
Alla tre funktioners definitioner finns här. Och här är implementeringen av funktionen som returnerar en pseudoslumpmässig bytesekvens med den bestämda längden.
Först definierar vi om den nödvändiga funktionen finns. Om inte – vi skapar en stud först. I alla fall innebär koden att ändra funktionsdefinitionen på lämpligt sätt. I slutändan lägger vi till funktionens beskrivning via de utökade egenskaperna. Mer information om databasens dokumentation finns i den här artikeln.
För att uppdatera fjärråtkomstcertifikatet för varje kandidat kan du göra enligt följande:
UPDATE [dbo].[Employee]
SET [RemoteAccessCertificate] = [test].[GetRandVarbinary](CAST(LEN([RemoteAccessCertificate]) AS INT));
Som du ser finns det inga begränsningar för bytesekvenslängden här.
Dataändring – teckendataändring
Här tar vi ett exempel för de engelska och ryska alfabeten, men du kan göra det för alla andra alfabet. Det enda villkoret är att dess tecken måste finnas i NCHAR-typerna.
Vi måste skapa en funktion som accepterar raden, ersätter varje tecken med ett pseudoslumpmässigt tecken och sedan sätter ihop resultatet och returnerar det.
Men vi måste först förstå vilka karaktärer vi behöver. För det kan vi köra följande skript:
DECLARE @tbl TABLE ([ValueInt] INT, [ValueNChar] NCHAR(1), [ValueChar] CHAR(1));
DECLARE @ind int=0;
DECLARE @count INT=65535;
WHILE(@count>=0)
BEGIN
INSERT INTO @tbl ([ValueInt], [ValueNChar], [ValueChar])
SELECT @ind, NCHAR(@ind), CHAR(@ind)
SET @ind+=1;
SET @count-=1;
END
SELECT *
INTO [test].[TblCharactersCode]
FROM @tbl;
Vi gör tabellen [test].[TblCharacterCode] som innehåller följande fält:
- ValueInt – tecknets numeriska värde;
- ValueNChar – tecknet av NCHAR-typ;
- ValueChar – tecknet av CHAR-typ.
Låt oss granska innehållet i den här tabellen. Vi behöver följande begäran:
SELECT [ValueInt]
,[ValueNChar]
,[ValueChar]
FROM [test].[TblCharactersCode];
Siffrorna ligger i intervallet 48 till 57:
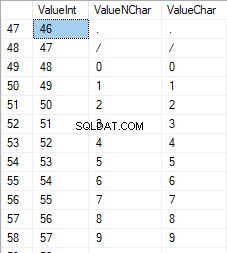
De latinska tecknen med versaler är i intervallet 65 till 90:
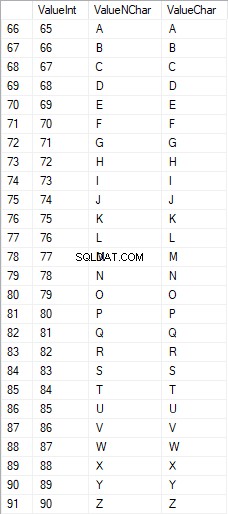
Latinska tecken i lägre vård är i intervallet 97 till 122:
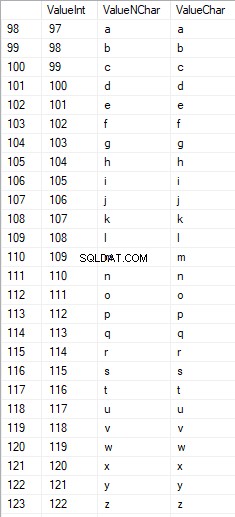
Ryska tecken med versaler är i intervallet 1040 till 1071:

Ryska tecken i gemener är i intervallet 1072 till 1103:


Och tecken i intervallet 58 till 64:

Vi väljer de nödvändiga tecknen och lägger in dem i tabellen [test].[SelectCharactersCode] på följande sätt:
SELECT
[ValueInt]
,[ValueNChar]
,[ValueChar]
,CASE
WHEN ([ValueInt] BETWEEN 48 AND 57) THEN 1
ELSE 0
END AS [IsNumeral]
,CASE
WHEN (([ValueInt] BETWEEN 65 AND 90) OR
([ValueInt] BETWEEN 1040 AND 1071)) THEN 1
ELSE 0
END AS [IsUpperCase]
,CASE
WHEN (([ValueInt] BETWEEN 65 AND 90) OR
([ValueInt] BETWEEN 97 AND 122)) THEN 1
ELSE 0
END AS [IsLatin]
,CASE
WHEN (([ValueInt] BETWEEN 1040 AND 1071) OR
([ValueInt] BETWEEN 1072 AND 1103)) THEN 1
ELSE 0
END AS [IsRus]
,CASE
WHEN (([ValueInt] BETWEEN 33 AND 47) OR
([ValueInt] BETWEEN 58 AND 64)) THEN 1
ELSE 0
END AS [IsExtra]
INTO [test].[SelectCharactersCode]
FROM [test].[TblCharactersCode]
WHERE ([ValueInt] BETWEEN 48 AND 57)
OR ([ValueInt] BETWEEN 65 AND 90)
OR ([ValueInt] BETWEEN 97 AND 122)
OR ([ValueInt] BETWEEN 1040 AND 1071)
OR ([ValueInt] BETWEEN 1072 AND 1103)
OR ([ValueInt] BETWEEN 33 AND 47)
OR ([ValueInt] BETWEEN 58 AND 64);
Låt oss nu undersöka innehållet i den här tabellen med hjälp av följande skript:
SELECT [ValueInt]
,[ValueNChar]
,[ValueChar]
,[IsNumeral]
,[IsUpperCase]
,[IsLatin]
,[IsRus]
,[IsExtra]
FROM [test].[SelectCharactersCode];
Vi får följande resultat:

På så sätt har vi [test].[SelectCharactersCode] tabell, där:
- ValueInt – tecknets numeriska värde
- ValueNChar – tecknet av NCHAR-typ
- ValueChar – tecknet av CHAR-typ
- Isnumeral – kriteriet för att ett tecken är en siffra
- IsUpperCase – kriteriet för ett tecken med versaler
- Islatin – kriteriet att ett tecken är ett latinskt tecken;
- IsRus – kriteriet att en karaktär är en rysk karaktär
- IsExtra – kriteriet att ett tecken är ett tilläggstecken
Nu kan vi få koden för att infoga de nödvändiga tecknen. Så här gör du till exempel för de latinska tecknen med gemener:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+''''+[ValueChar]+''''+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsUpperCase]=0
AND [IsLatin]=1;
Vi får följande resultat:

Det är samma sak för de ryska tecknen i gemener:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+COALESCE(''''+[ValueChar]+'''', 'NULL')+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsUpperCase]=0
AND [IsRus]=1;
Vi får följande resultat:

Det är samma sak för karaktärerna:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+''''+[ValueChar]+''''+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsNumeral]=1;
Resultatet är följande:

Så vi har koder för att infoga följande data separat:
- Latinska bokstäver med gemener.
- De ryska tecknen med gemener.
- Siffrorna.
Det fungerar för både NCHAR- och CHAR-typerna.
På samma sätt kan vi förbereda ett insättningsskript för vilken uppsättning tecken som helst. Dessutom kommer varje uppsättning att få sin egen tabuleringsfunktion.
För att vara enkel implementerar vi den gemensamma tabuleringsfunktionen som returnerar den nödvändiga datamängden för tidigare valda data på följande sätt:
SELECT
'SELECT ' + CAST([ValueInt] AS NVARCHAR(255)) + ' AS [ValueInt], '
+ '''' + [ValueNChar] + '''' + ' AS [ValueNChar], '
+ COALESCE('''' + [ValueChar] + '''', ‘NULL’) + ' AS [ValueChar], '
+ CAST([IsNumeral] AS NCHAR(1)) + ' AS [IsNumeral], ' +
+CAST([IsUpperCase] AS NCHAR(1)) + ' AS [IsUpperCase], ' +
+CAST([IsLatin] AS NCHAR(1)) + ' AS [IsLatin], ' +
+CAST([IsRus] AS NCHAR(1)) + ' AS [IsRus], ' +
+CAST([IsExtra] AS NCHAR(1)) + ' AS [IsExtra]' +
+' UNION ALL'
FROM [test].[SelectCharactersCode];
Slutresultatet är som följer:

Det färdiga skriptet är inkluderat i tabuleringsfunktionen [test].[GetSelectCharacters].
Det är viktigt att ta bort en extra UNION ALL i slutet av det genererade skriptet, och i [ValueInt]=39 måste vi ändra ”’ till ””:
SELECT 39 AS [ValueInt], '''' AS [ValueNChar], '''' AS [ValueChar], 0 AS [IsNumeral], 0 AS [IsUpperCase], 0 AS [IsLatin], 0 AS [IsRus], 1 AS [IsExtra] UNION ALLDenna tabuleringsfunktion returnerar följande uppsättning fält:
- Nummer – radnumret i den returnerade uppsättningen data;
- ValueInt – tecknets numeriska värde;
- ValueNChar – tecknet av NCHAR-typ;
- ValueChar – tecknet av CHAR-typ;
- Isnumeral – kriteriet för att tecknet är en siffra;
- IsUpperCase – kriteriet som definierar att tecknet är i versaler;
- Islatin – kriteriet som definierar att tecknet är ett latinskt tecken;
- IsRus – kriteriet som definierar att tecknet är ett ryskt tecken;
- IsExtra – kriteriet som definierar att karaktären är en extra.
För inmatningen har du följande parametrar:
- @IsNumeral – om det skulle returnera siffrorna;
- @IsUpperCase :
- 0 – den måste endast returnera gemener för bokstäver;
- 1 – den måste endast returnera versaler;
- NULL – den måste returnera bokstäver i alla fall.
- @IsLatin – den måste returnera de latinska tecknen
- @IsRus – den måste returnera de ryska tecknen
- @IsExtra – den måste returnera ytterligare tecken.
Alla flaggor används enligt det logiska ELLER. Om du till exempel behöver ha siffror och latinska tecken med gemener returnerade, anropar du tabuleringsfunktionen på följande sätt:
Vi får följande resultat:
declare
@IsNumeral BIT=1
,@IsUpperCase BIT=0
,@IsLatin BIT=1
,@IsRus BIT=0
,@IsExtra BIT=0;
SELECT *
FROM [test].[GetSelectCharacters](@IsNumeral, @IsUpperCase, @IsLatin, @IsRus, @IsExtra);
Vi får följande resultat:

Vi implementerar funktionen [test].[GetRandString] som kommer att ersätta raden med pseudoslumpmässiga tecken och behålla den ursprungliga stränglängden. Denna funktion måste inkludera möjligheten att endast använda de tecken som är siffror. Det kan till exempel vara användbart när du ändrar ID-kortets serie och nummer.
När vi implementerar funktionen [test].[GetRandString] får vi först den uppsättning tecken som krävs för att generera en pseudoslumprad rad med angiven längd i indataparametern @Length. Resten av parametrarna fungerar enligt beskrivningen ovan.
Sedan lägger vi den mottagna uppsättningen av data i tabuleringsvariabeln @tbl . Den här tabellen sparar fälten [ID] – ordernumret i den resulterande teckentabellen och [Värde] – karaktärens presentation i typen NCHAR.
Efter det, i en cykel, genererar den ett pseudoslumptal i intervallet 1 till kardinaliteten för @tbl-tecken som tagits emot tidigare. Vi lägger in detta nummer i [ID] för tabuleringsvariabeln @tbl för sökning. När sökningen returnerar raden tar vi tecknet [Value] och "limmar" det på den resulterande raden @res.
När cykelns arbete slutar, kommer den mottagna raden tillbaka via variabeln @res.
Du kan ändra både för- och efternamn på kandidaten på följande sätt:
UPDATE [dbo].[Employee]
SET [FirstName] = [test].[GetRandString](LEN([FirstName])),
[LastName] = [test].[GetRandString](LEN([LastName]));
Därför har vi undersökt funktionens implementering och dess användning för NCHAR- och NVARCHAR-typerna. Vi kan enkelt göra samma sak för CHAR- och VARCHAR-typerna.
Ibland måste vi dock generera en rad enligt teckenuppsättningen, inte de alfabetiska tecknen eller siffrorna. På detta sätt måste vi först använda följande multioperatorfunktion [test].[GetListCharacters].
Funktionen [test].[GetListCharacters] får de två följande parametrarna för indata:
- @str – själva teckenraden;
- @IsGroupUnique – den definierar om den behöver gruppera unika tecken på raden.
Med den rekursiva CTE omvandlas inmatningsraden @str till teckentabellen – @ListCharacters. Den tabellen innehåller följande fält:
- ID – beställningsnumret på raden i den resulterande teckentabellen;
- Tecken – presentationen av tecknet i NCHAR(1)
- Räkna – antalet teckens repetitioner på raden (det är alltid 1 om parametern @IsGroupUnique=0)
Låt oss ta två exempel på den här funktionens användning för att bättre förstå dess arbete:
- Omvandling av raden till listan över icke-unika tecken:
SELECT *
FROM [test].[GetListCharacters]('123456888 789 0000', 0);
Vi får resultatet:

Det här exemplet visar att raden omvandlas till listan med tecken "i befintligt skick" utan att den grupperas efter karaktärernas unika karaktär (fältet [Count] innehåller alltid 1).
- Omvandlingen av raden till listan med unika tecken
SELECT *
FROM [test].[GetListCharacters]('123456888 789 0000', 1);
Resultatet är följande:
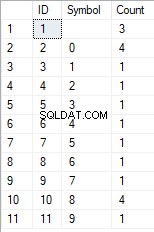
Det här exemplet visar att raden omvandlas till en lista över tecken grupperade efter deras unika karaktär. Fältet [Count] visar antalet fynd av varje tecken på inmatningsraden.
Baserat på multioperatorfunktionen [test].[GetListCharacters], skapar vi en skalär funktion [test].[GetRandString2].
Definitionen av den nya skalära funktionen visar dess likhet med skalärfunktionen [test].[GetRandString]. Den enda skillnaden är att den använder multioperatorfunktionen [test].[GetListCharacters] istället för tabuleringsfunktionen [test].[GetSelectCharacters].
Låt oss här granska två exempel på den implementerade skalära funktionsanvändningen :
Vi genererar en pseudoslumprad rad på 12 tecken från inmatningsraden med tecken som inte är grupperade efter unikhet:
SELECT [test].[GetRandString2](12, '123456789!!!!!!!!0!!!', DEFAULT);Resultatet är:
64017!!5!!!7
Nyckelordet är DEFAULT. Den anger att standardvärdet anger parametern. Här är det noll (0).
Eller
Vi genererar en pseudoslumprad rad med 12 tecken långa från inmatningsraden med tecken grupperade efter unikhet:
SELECT [test].[GetRandString2](12, '123456789!!!!!!!!0!!!', 1);Resultatet är:
35792!428273
Implementering av det allmänna skriptet för datasanering och de hemliga dataändringarna
Vi har undersökt enkla exempel för varje typ av ändrad data:
- Ändra datum och tid;
- Ändra det numeriska värdet;
- Ändra bytesekvensen;
- Ändra karaktärernas data.
Dessa exempel uppfyller dock inte kriterierna 2 och 3 för dataändringsskripten:
- Kriterium 2 :selektiviteten för värden kommer inte att förändras nämnvärt i de ändrade data. Du kan inte använda NULL för tabellens fält. Istället måste du se till att samma verkliga datavärden förblir desamma i den ändrade datan. T.ex. om den verkliga datan innehåller värdet 103785 12 gånger i en tabells fält med förbehåll för ändringar, måste den modifierade informationen inkludera ett annat (ändrat) värde som finns 12 gånger i samma fält i tabellen.
- Kriterium 3 :längden och storleken på värden bör inte ändras nämnvärt i de ändrade data. Du byter till exempel ut varje tecken/byte med ett pseudoslumpmässigt tecken/byte.
Därför måste vi skapa ett skript som tar hänsyn till värdenas selektivitet i tabellens fält.
Låt oss ta en titt på vår databas för rekryteringstjänsten. Som vi ser finns personuppgifter endast i kandidattabellen [dbo].[Anställd].
Antag att tabellen innehåller följande fält:
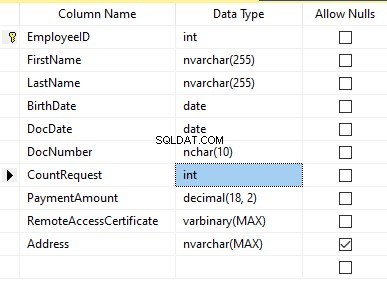
Beskrivningar:
- Förnamn – namn, rad NVARCHAR(255)
- Efternamn – efternamn, rad NVARCHAR(255)
- Födelsedatum – födelsedatum, DATUM
- Dokumentnummer – ID-kortsnumret med två siffror i början för passserien, och de följande sju siffrorna är dokumentets nummer. Mellan dem har vi ett bindestreck som NCHAR(10)-raden.
- DocDate – ID-kortets utfärdandedatum, DATUM
- CountRequest – antalet förfrågningar för den kandidaten under sökningen efter CV, heltal INT
- Betalningsbelopp – mottagen serviceavgift för CV-kampanj, decimaltalet (18,2)
- Remote AccessCertificate – fjärråtkomstcertifikatet, bytesekvens VARBINARY
- Adress – bostadsadressen eller registreringsadressen, rad NVARCHAR(MAX)
Sedan, för att behålla den initiala selektiviteten, måste vi implementera följande algoritm:
- Extrahera alla unika värden för varje fält och behåll resultaten i tillfälliga tabeller eller tabuleringsvariabler;
- Generera ett pseudoslumpmässigt värde för varje unikt värde. Detta pseudoslumpmässiga värde får inte skilja sig nämnvärt i längd och storlek från det ursprungliga värdet. Spara resultatet på samma plats där vi sparade punkt 1-resultaten. Varje nygenererat värde måste ha ett unikt aktuellt värde korrelerat.
- Ersätt alla värden i tabellen med nya värden från punkt 2.
I början avpersonifierar vi kandidaternas för- och efternamn. Vi antar att efter- och förnamnen alltid är närvarande och att de inte är mindre än två tecken långa i varje fält.
Först väljer vi unika namn. Sedan genererar den en pseudoslumpmässig rad för varje namn. Namnets längd förblir densamma; det första tecknet är med versaler och de andra tecknen med gemener. Vi använder den tidigare skapade skalärfunktionen [test].[GetRandString] för att generera en pseudoslumpmässig linje av den specifika längden enligt de definierade karaktärernas kriterier.
Sedan uppdaterar vi namnen i kandidattabellen enligt deras unika värden. Det är samma sak för efternamnen.
Vi avpersonaliserar fältet DocNumber. Det är ID-kortets (pass) nummer. De två första tecknen står för dokumentets serie, och de sista sju siffrorna är dokumentets nummer. Bindestrecket är mellan dem. Sedan utför vi saneringsoperationen.
Vi samlar in alla unika dokuments nummer och genererar en pseudoslumprad rad för var och en. Linjens format är 'XX-XXXXXXX', där X är siffran i intervallet 0 till 9. Här använder vi den tidigare skapade skalärfunktionen [test].[GetRandString] för att generera en pseudoslumpmässig linje av angiven längd enligt karaktärernas parametrar.
Därefter uppdateras [DocNumber]-fältet i kandidattabellen [dbo].[Anställd].
Vi avpersonaliserar DocDate-fältet (id-kortets utfärdandedatum) och BirthDate-fältet (kandidatens födelsedatum).
First, we select all the unique pairs made of “date of birth &date of the ID-card issue.” For each such pair, we create a pseudorandom date for the date of birth. The pseudorandom date of the ID-card issue is made according to that “date of birth” – the date of the document’s issue must not be earlier than the date of birth.
After that, these data are updated in the respective fields of the candidates’ table [dbo].[Employee].
And, we update the remaining fields of the table.
The CountRequest value stands for the number of requests made for that candidate by companies during the resume search.
The PaymentAmount is the final amount of the resume promotion service fee paid. We calculate these numbers similarly to the previous fields.
Note that it generates a pseudorandom integer for the first case and a pseudorandom decimal for the second case. In both cases, the pseudorandom number generation occurs in the range of “two times less than original” to “two times more than original.” The selectivity of values in the fields is not changed too much.
After that, it writes the values into the fields of the candidates’ table [dbo].[Employee].
Further, we collect unique values of the RemoteAccessCertificate field for the remote access certificate. We generate a pseudorandom byte sequence for each such value. The length of the sequence must be the same as the original. Here, we use the previously created [test].[GetRandVarbinary] scalar function to generate the pseudorandom byte sequence of the specified length.
Then recording into the respective field [RemoteAccessCertificate] of the [dbo].[Employee] candidates’ table takes place.
The last step is the collection of the unique addresses from the [Address] field. For each value, we generate a pseudorandom line of the same length as the original. Note that if it was NULL originally, it must be NULL in the generated field. It allows you to keep NULL and don’t replace it with an empty line. It minimizes the selectivity values’ mismatch in this field between the production database and the altered data.
We use the previously created [test].[GetRandString] scalar function to generate the pseudorandom line of the specified length according to the characters’ parameters defined.
It then records the data into the respective [Address] field of the candidates’ table [dbo].[Employee].
This way, we get the full script for depersonalization and altering of the confidential data.
Finally, we get the database with altered personal and confidential data. The algorithms we used make it impossible to restore the original data from the altered data. Also, the values’ selectivity, length, and size aren’t changed significantly. So, the three criteria for the personal and secret data altering scripts are ensured.
We won’t review the criterion 4 separately here. Our database contains all the data subject to change in one candidates’ table [dbo].[Employee]. The data conformity is needed within this table only. Thus, criterion 4 is also here. However, we need to remember this criterion 4 claiming that all interrelations must remain the same in the altered data.
We often see other conditions for personal and confidential data altering algorithms, but we won’t review them here. Besides, the four criteria described above are always present. In many cases, it is enough to estimate the functionality of the algorithm suitable to use it.
Now, we need to make a backup of the created database, check it by restoring on another instance, and transfer that copy into the necessary environment for development and testing. For this, we examine the full database backup creation.
Full database backup creation
We can make a database backup with construction BACKUP DATABASE as in our example.
Make a compressed full backup of the database JobEmplDB_Test. The checksum calculation takes place in the file E:\Backup\JobEmplDB_Test.bak. Further, we check the backup created.
Then, we check the backup created by restoring the database for it. Let’s examine the database restoring.
Restoring the database
You can restore the database with the help of RESTORE DATABASE construction in the following way:
USE [master]
RESTORE DATABASE [JobEmplDB_Test]
FROM DISK = N'E:\Backup\JobEmplDB_Test.bak' WITH FILE = 1,
MOVE N'JobEmplDB' TO N'E:\DBData\JobEmplDB.mdf',
MOVE N'JobEmplDB_log' TO N'F:\DBLog\JobEmplDB_log.ldf',
NOUNLOAD,
REPLACE,
STATS = 5;
GO
We restore the JobEmplDB_Test database of the E:\Backup\JobEmplDB_Test.bak backup. The files will be overwritten, and the data file will be transferred into the file E:\DBData\JobEmplDB.mdf , while the transactions log file will be moved into F:\DBLog\JobEmplDB_log.ldf .
After we successfully check how the database is restored from the backup, we forward the backup to the development and testing environments. It will be restored again with the same method as described above.
We’ve examined the first approach to the data populating into the database for testing and development. This approach implies copying and altering the data from the production database. Now, we’ll examine the second approach – the synthetic data generation.
Synthetic data generation
The General algorithm for the synthetic data generation is following:
- Make a new empty database or clear a previously created database by purging all data.
- Create or renew a scheme in the newly created database – the same as that of the production databases.
- Copy of renew guidelines and regulations from the production database and transfer them into the new database.
- Generate synthetic data into the necessary tables of the new database.
- Make a backup of a new database.
- Deliver and restore the new backup in the necessary environment.
We already have the JobEmplDB_Test database to practice, and we have reviewed the means of creating a schema in the new database. Let’s focus on the tasks that are specific to this approach.
Clean up the database with the data purge
To clear the database off all its data, we need to do the following:
- Keep the definitions of all external keys.
- Disable all limitations and triggers.
- Delete all external keys.
- Clear the tables using the TRUNCATE construction.
- Restore all the external keys deleted in point 3.
- Enable all the limitations disabled in point 2.
You can save the definitions of all external keys with the following script:
1. The external keys’ definitions are saved in the tabulation variable @tbl_create_FK
2. You can disable the limitations and triggers with the following script:
EXEC sp_MSforeachtable "ALTER TABLE ? NOCHECK CONSTRAINT ALL";
EXEC sp_MSforeachtable "ALTER TABLE ? DISABLE TRIGGER ALL";
To enable the limitations and triggers, you can use the following script:
EXEC sp_MSforeachtable "ALTER TABLE ? WITH CHECK CHECK CONSTRAINT ALL";
EXEC sp_MSforeachtable "ALTER TABLE ? ENABLE TRIGGER ALL";
Here, we use the saved procedure sp_MSforeachtable that applies the construction to all the database’s tables.
3. To delete external keys, use the special script. Here, we receive the information about the external keys through the INFORMATION_SCHEMA.TABLE_CONSTRAINTS system presentation. We delete external keys through the cursor, one by one, using the formed dynamic script T-SQL, transferring the request into the system saved procedure sp_executesql .
4. To clear the tables with the TRUNCATE construction, use the dedicated script. The script works in the same way as above, but it receives the data for tables, and then it clears the tables one by one through the cursor, using the TRUNCATE construction.
5. Restoring the external keys is possible with the below script (earlier, we saved the external keys’ definitions in the tabulation variable @tbl_create_FK):
DECLARE @tsql NVARCHAR(4000);
DECLARE FK_Create CURSOR LOCAL FOR SELECT
[Script]
FROM @tbl_create_FK;
OPEN FK_Create;
FETCH NEXT FROM FK_Create INTO @tsql;
WHILE (@@fetch_status = 0)
BEGIN
EXEC sp_executesql @tsql = @tsql;
FETCH NEXT FROM FK_Create INTO @tsql;
END
CLOSE FK_Create;
DEALLOCATE FK_Create;
The script works in the same way as the two other scripts we mentioned above. But it restores the external keys’ definitions through the cursor, one for each iteration.
A particular case of data purging in the database is the current script. To get this output, we need the below construction in the scripts:
EXEC sp_executesql @tsql = @tsql;Before this construction, or instead of it, we need to write the generated construction output. It is necessary to call it manually or via the dynamic T-SQL query. We do it via the system saved procedure sp_executesql.
Instead of the below code fragment in all cases:
WHILE (@@fetch_status = 0)
BEGIN
EXEC sp_executesql @tsql = @tsql;
...
We write:
WHILE (@@fetch_status = 0)
BEGIN
PRINT @tsql;
EXEC sp_executesql @tsql = @tsql;
...
Or:
WHILE (@@fetch_status = 0)
BEGIN
PRINT @tsql;
...
The first case implies both the output of constructions and their execution. The second case if for the output only – it is helpful for the scripts’ debugging.
Thus, we get the general database cleaning script.
Copy guidelines and references from the production database to the new one
Here you can use the T-SQL scripts. Our example database of the recruitment service includes 5 guidelines:
- [dbo].[Company] – companies
- [dbo].[Skill] – skills
- [dbo].[Position] – positions (occupation)
- [dbo].[Project] – projects
- [dbo].[ProjectSkill] – project and skills’ correlations
The “skills” table [dbo].[Skill] serves to show how to make a script for the data insertion from the production database into the test database.
We form the following script:
SELECT 'SELECT '+CAST([SkillID] AS NVARCHAR(255))+' AS [SkillID], '+''''+[SkillName]+''''+' AS [SkillName] UNION ALL'
FROM [dbo].[Skill]
ORDER BY [SkillID];
We execute it in a copy of the production database that is usually available in read-only mode. It is a replica of the production database.
Resultatet är:
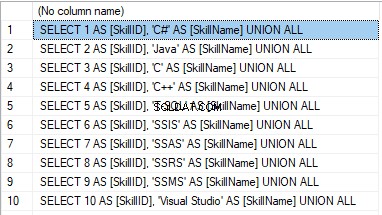
Now, wrap the result up into the script for the data adding as here. We have a script for the skills’ guideline compilation. The scripts for other guidelines are made in the same way.
However, it is much easier to copy the guidelines’ data through the data export and import in SSMS. Or, you can use the data import and export wizard.
Generate synthetic data
We’ve determined the pseudorandom values’ generation for lines, numbers, and byte sequences. It took place when we examined the implementation of the data sanitization and the confidential data altering algorithms for approach 1. Those implemented functions and scripts are also used for the synthetic data generation.
The recruitment service database requires us to fill the synthetic data in two tables only:
- [dbo].[Employee] – candidates
- [dbo].[JobHistory] – a candidate’s work history (experience), the resume itself
We can fill the candidates’ table [dbo].[Employee] with synthetic data using this script.
At the beginning of the script, we set the following parameters:
- @count – the number of lines to be generated
- @LengthFirstName – the name’s length
- @LengthLastName – the last name’s length
- @StartBirthDate – the lower limit of the date for the date of birth
- @FinishBirthDate – the upper limit of the date for the date of birth
- @StartCountRequest – the lower limit for the field [CountRequest]
- @FinishCountRequest – the upper limit for the field [CountRequest]
- @StartPaymentAmount – the lower limit for the field [PaymentAmount]
- @FinishPaymentAmount – the upper limit for the field [PaymentAmount]
- @LengthRemoteAccessCertificate – the byte sequence’s length for the certificate
- @LengthAddress – the length for the field [Address]
- @count_get_unique_DocNumber – the number of attempts to generate the unique document’s number [DocNumber]
The script complies with the uniqueness of the [DocNumber] field’s value.
Now, let’s fill the [dbo].[JobHistory] table with synthetic data as follows.
The start date of work [StartDate] is later than the issuing date of the candidate’s document [DocDate]. The end date of work [FinishDate] is later than the start date of work [StartDate].
It is important to note that the current script is simplified, as it does not deal with parameters of the generated data selectivity configuration.
Make a full database backup
We can make a database backup with the construction BACKUP DATABASE, using our script.
We create a full compressed backup of the database JobEmplDB_Test. The checksum is calculated into the file E:\Backup\JobEmplDB_Test.bak. It also ensures further testing of the backup.
Let’s check the backup by restoring the database from it. We need to examine the database restoring then.
Restore the database
You can restore the database with the help of the RESTORE DATABASE construction, as shown below:
USE [master]
RESTORE DATABASE [JobEmplDB_Test]
FROM DISK = N'E:\Backup\JobEmplDB_Test.bak' WITH FILE = 1,
MOVE N'JobEmplDB' TO N'E:\DBData\JobEmplDB.mdf',
MOVE N'JobEmplDB_log' TO N'F:\DBLog\JobEmplDB_log.ldf',
NOUNLOAD,
REPLACE,
STATS = 5;
GO
We restore the database JobEmplDB_Test from the backup E:\Backup\JobEmplDB_Test.bak. The files are overwritten, and the data file is transferred to the file E:\DBData\JobEmplDB.mdf. The transaction log file is transferred to file F:\DBLog\JobEmplDB_log.ldf.
After checking the database restoring from the backup successfully, we transfer the backup to the necessary environments. It will be used for testing and development, and further deployment through the database restoring, as described above.
This way, we’ve examined the second approach to filling the database in with data for testing and development purposes. It is the synthetic data generation approach.
Data generation tools (for external resources)
When we have a job to fill in the database with data for testing and development purposes, it can be much faster and easier with the help of specialized tools. Let’s review the most popular and powerful data generation tools and explore their practical usage.
Full list of tools
DATPROF
IRI RowGen
Data Generator for SQL Server
Redgate SQL Data Generator
DTM Data Generator
Datanamic Data Generator MultiDB
Now, let’s examine one of these tools more precisely.
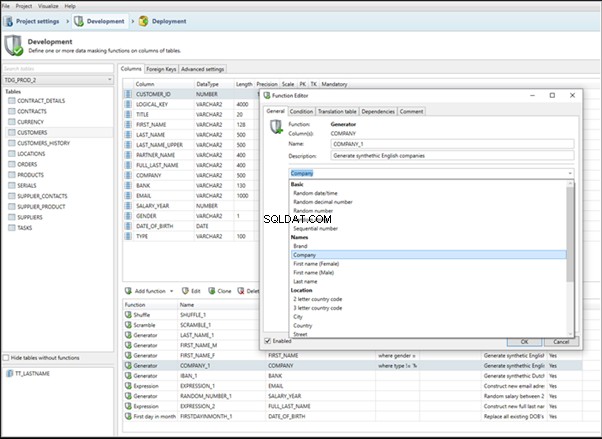
An overview of the employees’ generation by the Data Generator for SQL Server
The Data Generator for SQL Server utility is embedded in SSMS, and also it is a part of dbForge Studio. We reviewed this utility here. Let’s now examine how it works for synthetic data generation. As examples, we use the [dbo].[Employee] and the [dbo].[JobHistory] tables.
This generator can quickly generate first and last names of candidates for the [FirstName] and [LastName] fields respectively:
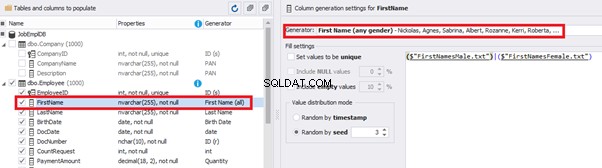
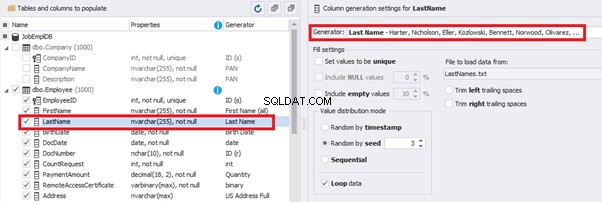
Note that FirstName requires choosing the “First Name” value in the “Generator” section. For LastName, you need to select the “Last Name” value from the “Generator” section.
It is important to note that the generator automatically determines which generation type it needs to apply to every field. The settings above were set by the generator itself, without manual correction.
You can configure distribution of values for the date of birth [BirthDate]:
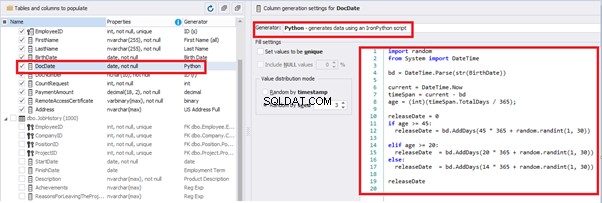
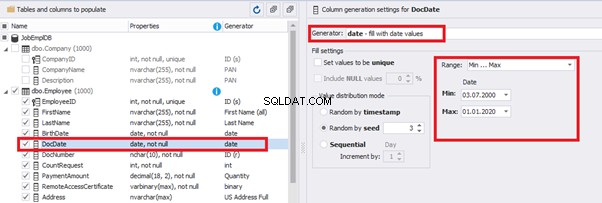
Set the distribution for the document’s date of issue [DocDate] through the Phyton generator using the below script:
import random
from System import DateTime
# receive the value from the Birthday field
bd = DateTime.Parse(str(BirthDate))
# receive the current date
current = DateTime.Now
# calculate the age in years
timeSpan = current - bd
age = (int)(timeSpan.TotalDays / 365);
# passport’s date of issue
releaseDate = 0
if age >= 45:
releaseDate = bd.AddDays(45 * 365 + random.randint(1, 30))
# randomize the issue during the month
elif age >= 20:
releaseDate = bd.AddDays(20 * 365 + random.randint(1, 30))
# randomize the issue during the month
else:
releaseDate = bd.AddDays(14 * 365 + random.randint(1, 30))
# randomize the issue during the month
releaseDateThis way, the [DocDate] configuration will look as follows:
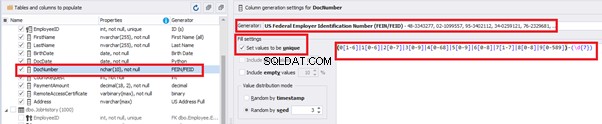
For the document’s number [DocNumber], we can select the necessary type of unique data generation, and edit the generated data format, if needed:
E.g., instead of the format
(0[1-6]|1[0-6]|2[0-7]|3[0-9]|4[0-68]|5[0-9]|6[0-8]|7[1-7]|8[0-8]|9[0-589])-(\d{7})We can set the following format:
(\d{2})-(\d{7})This format means that the line will be generated in format XX-XXXXXXX (X – is a digit in the range of 0 to 9).
We set up the generator for [CountRequest] and [PaymentAmount] fields in the same way, according to the generated data type:
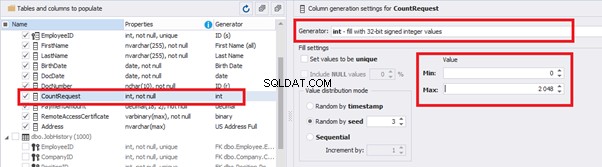
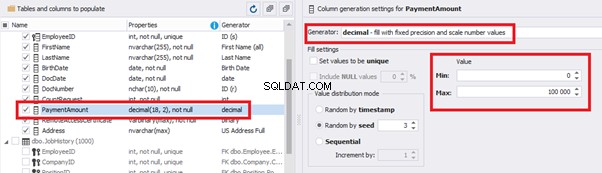
In the first case, we set the values’ range of 0 to 2048 for [CountRequest]. In the second case, it is the range of 0 to 100000 for [PaymentAmount].
We configure generation for [RemoteAccessCertificate] and [Address] fields in the same way:
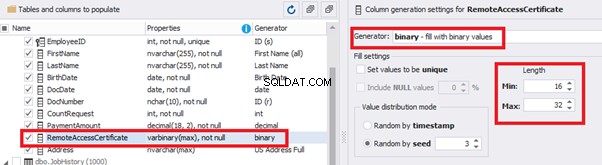
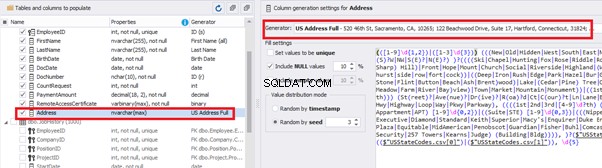
In the first case, we limit the byte sequence [RemoteAccessCertificate] with the range of lengths of 16 to 32. In the second case, we select values for [Address] as real addresses. It makes the generated values looking like the real ones.
This way, we’ve configured the synthetic data generation settings for the candidates’ table [dbo].[Employee]. Let’s now set up the synthetic data generation for the [dbo].[JobHistory] table.
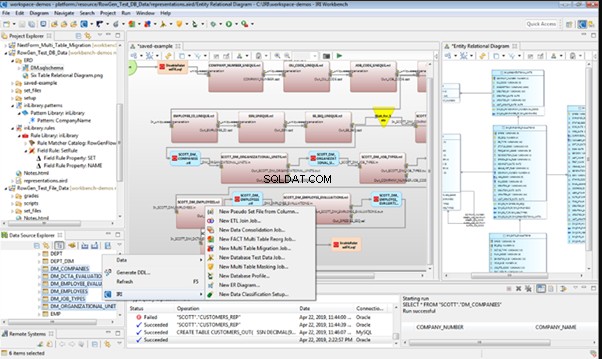
We set it to take the data for the [EmployeeID] field from the candidates’ table [dbo].[Employee] in the following way:
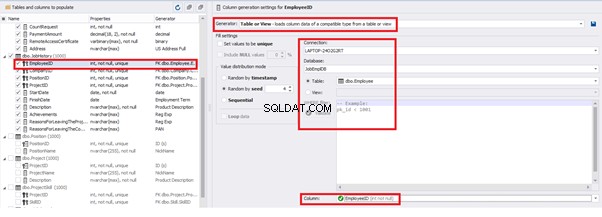
We select the generator’s type from the table or presentation. We then define the sample of MS SQL Server, the database, and the table to take the data from. We can also configure filters in the “WHERE filter” section, and select the [EmployeeID] field.
Here we suppose that we generate the “employees” first, and then we generate the data for the [dbo].[JobHistory] table, basing on the filled [dbo].[Employee] reference.
However, if we need to generate the data for both [dbo].[Employee] and [dbo].[JobHistory] at the same time, we need to select “Foreign Key (manually assigned) – references a column from the parent table,” referring to the [dbo].[Employee].[EmployeeID] column:
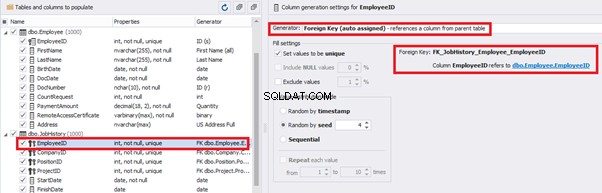
Similarly, we set up the data generation for the following fields.
[CompanyID] – from [dbo].[Company], the “companies” table:
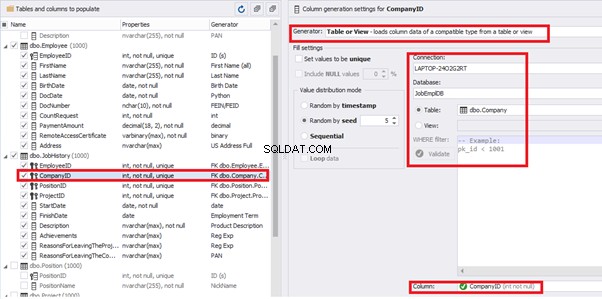
[PositionID] – from the table of positions [dbo].[Position]:
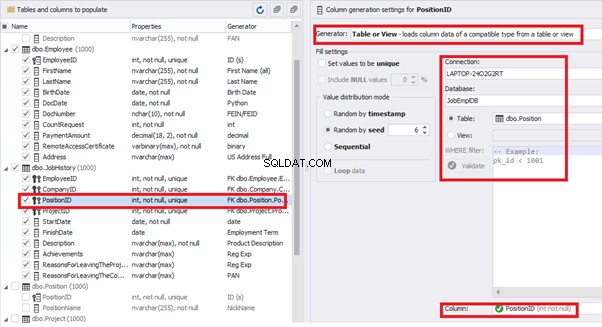
[ProjectID] – from the table of projects [dbo].[Project]:
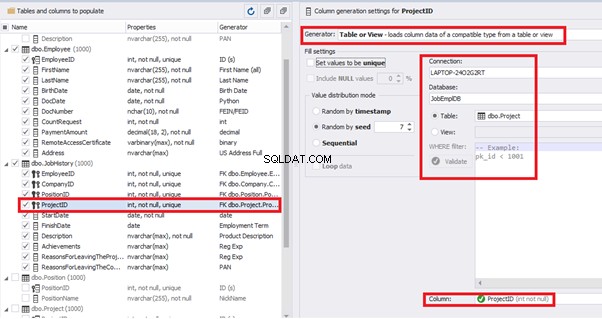
The tool cannot link the columns from different tables and shift them in some way. However, the generator can shift the date within one table – the “date” generator – fill with date values with Range – Offset from the column. Also, it can use data from a different table, but without any transformation (Table or View, SQL query, Foreign key generators).
That’s why we resolve the dates’ problem (BirthDate
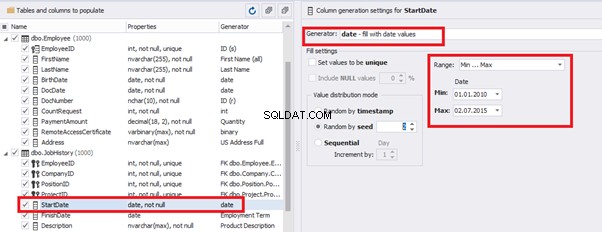
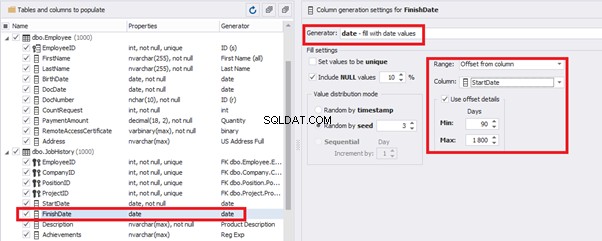
E.g., we limit the BirthDate with the 40-50 years’ interval. Then, we restrict the DocDate with 20-40 years’ interval. The StartDate is, respectively, limited with 25-35 years’ interval, and we set up the FinishDate with the offset from StartDate.
We set up the date of birth:
Set up the date of the document’s issue
Then, the StartDate will match the age from 35 to 45:
The simple offset generator sets FinishDate:
The result is, a person has worked for three months till the current date.
Also, to configure the date of the working end, we can use a small Python script:
This way, we receive the below configuration for the dates of work end [FinishDate] data generation:
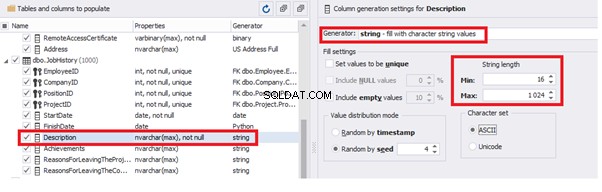
Similarly, we fill in the rest of fields. We set the generator type – string, and set the range for generated lines’ lengths:
Also, you can save the data generation project as dgen-file consisting of:
We can save all these settings:it is enough to keep the project’s file and work with the database further, using that file:
There is also the possibility to both save the new generators from scratch and save the custom settings in a new generator:
Thus, we’ve configured the synthetic data generation settings used for the jobs’ history table [dbo].[JobHistory].
We have examined two approaches to filling the data in the database for testing and development:
We’ve defied the objects for each approach and each script implementation. These objects are here. We’ve also provided scripts for changing the data from the production database and synthetic data generation. An example is the database of recruitment services. In the end, we’ve examined popular data generation tools and explored one of these tools in detail.
SQL SERVER – How to Disable and Enable All Constraint for Table and Database 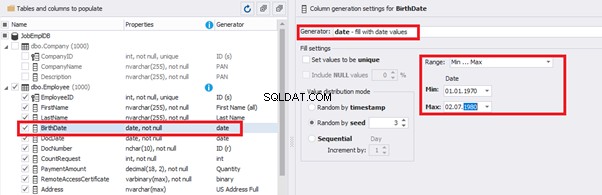
import random
from System import DateTime
bd = DateTime.Parse(str(StartDate))
releaseDate = bd.AddDays(random.randint(1, 30))
releaseDate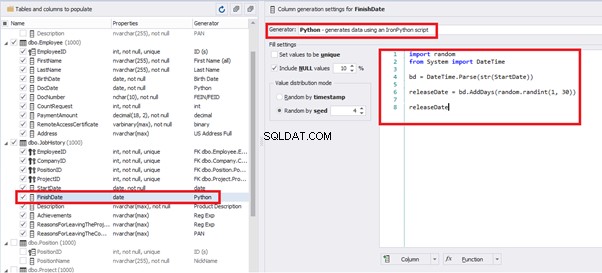
Slutsats
Referenser
Microsoft TechNet Wiki
Top 10 Best Test Data Generation Tools In 2020
SQL Server Documentation