Minneshantering i PostgreSQL är viktig för att förbättra databasserverns prestanda. PostgreSQL-konfigurationsfilen (postgres.conf) hanterar konfigurationen av databasservern. Den använder standardvärden för parametrarna, men vi kan ändra dessa värden för att bättre återspegla arbetsbelastning och driftsmiljö.
I den här bloggen kommer vi att täcka dessa minnesrelaterade parametrar. Men innan vi börjar, låt oss ta en titt på minnesarkitekturen i PostgreSQL.
Minnesarkitektur
Minne i PostgreSQL kan klassificeras i två kategorier:
- Lokalt minnesområde:Det tilldelas av varje backend-process för eget bruk.
- Delat minnesområde:Det används av alla processer på en PostgreSQL-server.
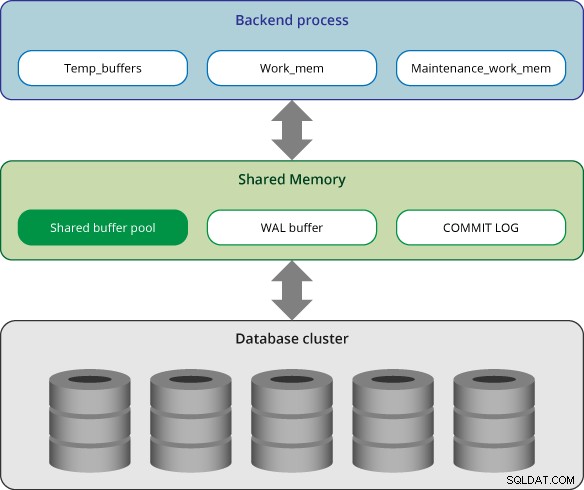
Lokalt minnesområde
I PostgreSQL allokerar varje backend-process lokalt minne för frågebehandling; varje område är uppdelat i delområden vars storlekar är antingen fasta eller varierande.
Underområdena är följande.
Work_mem
Exekutorn använder detta område för att sortera tupler efter ORDER BY och DISTINCT operationer. Den använder den också för att sammanfoga tabeller genom sammanfogning-join och hash-join-operationer.
Maintenance_work_mem
Denna parameter används för vissa typer av underhållsoperationer (VACUUM, REINDEX).
Temp_buffertar
Exekutorn använder detta område för att lagra temporära tabeller.
Delat minnesområde
Delat minnesområde tilldelas av PostgreSQL-servern när den startar. Dessa områden är uppdelade i flera delområden med fast storlek.
Delad buffertpool
PostgreSQL laddar sidor i tabeller och index från beständig lagring till en delad buffertpool och arbetar sedan direkt på dem.
WAL-buffert
PostgreSQL stöder WAL-mekanismen (Write ahead log) för att säkerställa att ingen data går förlorad efter ett serverfel. WAL-data är egentligen en transaktionslogg i PostgreSQL och WAL-buffert är ett buffringsområde för WAL-data innan det skrivs till en beständig lagring.
Bekräftelselogg
Bekräftelseloggen (CLOG) behåller tillstånden för alla transaktioner och är en del av samtidighetskontrollmekanismen. Bekräftelseloggen allokeras till det delade minnet och används under transaktionsbearbetningen.
PostgreSQL definierar följande fyra transaktionstillstånd.
- IN_PROGRESS
- ENGAGERAG
- AVBRUTEN
- SUB-ENGAGED
Justera PostgreSQL-minnesparametrar
Det finns några viktiga parametrar som rekommenderas för minneshantering i PostgreSQL. Du bör ta hänsyn till följande.
Delade_buffertar
Denna parameter anger mängden minne som används för delade minnesbuffertar. Parametern shared_buffers bestämmer hur mycket minne som är dedikerat till servern för cachning av data. Standardvärdet för shared_buffers är vanligtvis 128 megabyte (128 MB).
Standardvärdet för denna parameter är mycket lågt eftersom på vissa plattformar som äldre Solaris-versioner och SGI kräver stora värden invasiva åtgärder som att kompilera om kärnan. Även på moderna Linux-system kommer kärnan sannolikt inte att tillåta inställning av shared_buffers till över 32 MB utan att först justera kärninställningarna.
Mekanismen har ändrats i PostgreSQL 9.4 och senare, så kärninställningarna behöver inte justeras där.
Om det är hög belastning på databasservern kommer prestanda att förbättras om du ställer in ett högt värde.
Om du har en dedikerad DB-server med 1 GB eller mer RAM, är ett rimligt startvärde för shared_buffer-konfigurationsparametern 25 % av minnet i ditt system.
Standardvärde för shared_buffers =128 MB. Ändringen kräver omstart av PostgreSQL-servern.
Allmän rekommendation för att ställa in shared_buffers är följande.
- Under 2 GB minne, ställ in värdet för shared_buffers till 20 % av det totala systemminnet.
- Under 32 GB minne, ställ in värdet för shared_buffers till 25 % av det totala systemminnet.
- Över 32 GB minne, ställ in värdet för shared_buffers till 8 GB
Work_mem
Den här parametern anger mängden minne som ska användas av interna sorteringsoperationer och hashtabeller innan skrivning till temporära diskfiler. Om många komplexa sorteringar händer och du har tillräckligt med minne, kan en ökning av parametern work_mem göra det möjligt för PostgreSQL att göra större sorteringar i minnet, vilket kommer att vara snabbare än diskbaserade motsvarigheter.
Observera att för en komplex fråga kan många sorterings- eller hashoperationer köras parallellt. Varje operation tillåts använda så mycket minne som detta värde anger innan den börjar skriva data till de temporära filerna. Det finns en möjlighet att flera sessioner kan göra sådana operationer samtidigt. Därför kan det totala minnet som används vara många gånger värdet av parametern work_mem.
Kom ihåg det när du väljer rätt värde. Sorteringsoperationer används för ORDER BY, DISTINCT och merge joins. Hash-tabeller används i hash-kopplingar, hashbaserad bearbetning av IN-underfrågor och hashbaserad aggregering.
Parametern log_temp_files kan användas för att logga sortering, hash och temporära filer, vilket kan vara användbart för att ta reda på om sorteringar spills till disk istället för att passa in i minnet. Du kan kontrollera sorteringen som spills till disk med EXPLAIN ANALYZE-planer. Till exempel, i utgången av EXPLAIN ANALYZE, om du ser raden som:"Sorteringsmetod:extern sammanfogningsdisk:7528kB ”, skulle ett work_mem på minst 8 MB behålla mellanliggande data i minnet och förbättra frågesvarstiden.
Standardvärdet för work_mem =4MB.
Allmän rekommendation för att ställa in work_mem är följande.
- Börja med lågt värde:32–64 MB
- Leta sedan efter "temporary file"-rader i loggar
- Ställ in på 2-3 gånger den största temporära filen
underhåll _work_mem
Denna parameter specificerar den maximala mängden minne som används av underhållsoperationer som VACUUM, CREATE INDEX och ALTER TABLE ADD FOREIGN KEY. Eftersom endast en av dessa operationer kan utföras åt gången av en databassession och en PostgreSQL-installation inte har många av dem som körs samtidigt, är det säkert att ställa in värdet på maintenance_work_mem betydligt större än work_mem.
Att ställa in det högre värdet kan förbättra prestandan för dammsugning och återställning av databasdumpar.
Det är nödvändigt att komma ihåg att när autovacuum körs kan detta minne tilldelas upp till autovacuum_max_workers gånger, så var försiktig så att du inte ställer in standardvärdet för högt.
Standardvärdet för maintenance_work_mem =64MB.
Allmän rekommendation för att ställa in maintenance_work_mem är följande.
- Ställ in värdet på 10 % av systemminnet, upp till 1 GB
- Du kanske kan ställa in den ännu högre om du har problem med VAKUUM
Effective_cache_size
Effective_cache_size bör ställas in på en uppskattning av hur mycket minne som är tillgängligt för diskcache av operativsystemet och i själva databasen. Detta är en riktlinje för hur mycket minne du förväntar dig att vara tillgängligt i operativsystemet och PostgreSQL buffertcacher, inte en tilldelning.
PostgreSQL-frågeplaneraren använder detta värde för att ta reda på om planerna den överväger skulle förväntas passa i RAM eller inte. Om det är inställt för lågt kan det hända att index inte används för att köra frågor som du förväntar dig. Eftersom de flesta Unix-system är ganska aggressiva vid cachning, kommer minst 50 % av det tillgängliga RAM-minnet på en dedikerad databasserver att vara full av cachad data.
Allmän rekommendation för effective_cache_size är följande.
- Ställ in värdet på mängden tillgänglig filsystemcache
- Om du inte vet, ställ in värdet på 50 % av det totala systemminnet
Standardvärdet för effective_cache_size =4 GB.
Temp_buffertar
Den här parametern anger det maximala antalet temporära buffertar som används av varje databassession. Sessionens lokala buffertar används endast för åtkomst till temporära tabeller. Inställningen av denna parameter kan ändras inom individuella sessioner men endast före den första användningen av tillfälliga tabeller inom sessionen.
PostgreSQL-databasen använder detta minnesområde för att hålla de temporära tabellerna för varje session, dessa kommer att rensas när anslutningen stängs.
Standardvärdet för temp_buffer =8MB.
Slutsats
Att förstå minnesarkitekturen och ställa in lämpliga parametrar är viktigt för att förbättra prestandan. Detta är särskilt nödvändigt för system med hög arbetsbelastning. För mer generella tips om prestandajusteringar, vänligen gå igenom detta prestationsfusk för PostgreSQL.