[ Del 1 | Del 2 | Del 3 | Del 4 ]
MERGE sats (introducerad i SQL Server 2008) låter oss utföra en blandning av INSERT , UPDATE och DELETE operationer med ett enda uttalande. Halloween-skyddsproblemen för MERGE är för det mesta en kombination av kraven för de enskilda operationerna, men det finns några viktiga skillnader och ett par intressanta optimeringar som bara gäller MERGE .
Undvika Halloween-problemet med MERGE
Vi börjar med att titta igen på exemplet Demo and Staging från del två:
CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
CREATE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey);
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
);
Som du kanske minns användes detta exempel för att visa att en INSERT kräver Halloween-skydd när infogningsmåltabellen också hänvisas till i SELECT del av frågan (EXISTS klausul i detta fall). Rätt beteende för INSERT uttalandet ovan är att försöka lägga till båda 1234 värden, och att följaktligen misslyckas med en PRIMARY KEY överträdelse. Utan fasseparation, INSERT skulle felaktigt lägga till ett värde, slutföra utan att ett fel skickas.
INSERT-exekveringsplanen
Koden ovan har en skillnad från den som används i del två; ett icke-klustrat index på Staging-tabellen har lagts till. INSERT genomförandeplan fortfarande kräver dock Halloween-skydd:
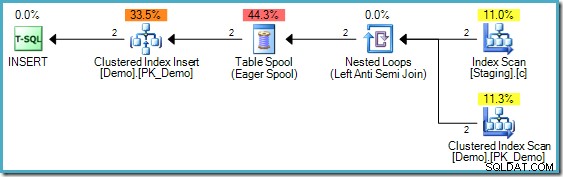
Utförandeplanen för MERGE
Prova nu samma logiska infogning som uttrycks med MERGE syntax:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED BY TARGET THEN
INSERT (SomeKey)
VALUES (s.SomeKey);
Om du inte är bekant med syntaxen är logiken där att jämföra rader i Staging- och Demo-tabellerna på SomeKey-värdet, och om ingen matchande rad hittas i måltabellen (Demo) infogar vi en ny rad. Detta har exakt samma semantik som föregående INSERT...WHERE NOT EXISTS kod såklart. Utförandeplanen är dock helt annorlunda:
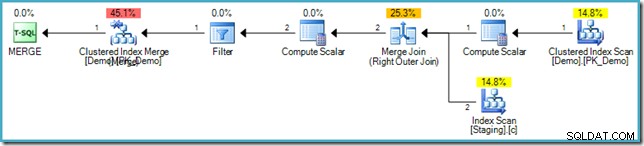
Lägg märke till bristen på en ivrig bordspole i denna plan. Trots det ger frågan fortfarande rätt felmeddelande. Det verkar som att SQL Server har hittat ett sätt att köra MERGE planera iterativt samtidigt som du respekterar den logiska fasseparationen som krävs av SQL-standarden.
Hålfyllningsoptimeringen
Under de rätta omständigheterna kan SQL Server-optimeraren känna igen att MERGE uttalandet är hålfyllande , vilket bara är ett annat sätt att säga att satsen bara lägger till rader där det finns ett befintligt gap i måltabellens nyckel.
För att denna optimering ska tillämpas måste värdena som används i WHEN NOT MATCHED BY TARGET klausul måste exakt matcha ON del av USING klausul. Måltabellen måste också ha en unik nyckel (ett krav som uppfylls av PRIMARY KEY i det aktuella fallet). Om dessa krav är uppfyllda visas MERGE uttalandet kräver inte skydd från Halloween-problemet.
Naturligtvis, MERGE uttalandet är logiskt varken mer eller mindre hålfyllning än originalet INSERT...WHERE NOT EXISTS syntax. Skillnaden är att optimeraren har fullständig kontroll över implementeringen av MERGE satsen, medan INSERT syntax skulle kräva att den resonerar om frågans bredare semantik. En människa kan lätt se att INSERT är också hålfyllande, men optimeraren tänker inte på saker och ting på samma sätt som vi gör.
För att illustrera den exakta matchningen krav som jag nämnde, överväg följande frågesyntax, som inte gör det dra nytta av optimeringen av hålfyllning. Resultatet är fullt Halloween-skydd som tillhandahålls av en ivrig bordspole:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey * 1);

Den enda skillnaden där är multiplikationen med ett i VALUES klausul – något som inte ändrar logiken i frågan, men som är tillräckligt för att förhindra att hålfyllningsoptimeringen tillämpas.
Hålfyllning med kapslade slingor
I det föregående exemplet valde optimeraren att slå samman tabellerna med hjälp av en sammanfogning. Hålfyllningsoptimeringen kan även tillämpas där en Nested Loops-join väljs, men detta kräver en extra unikhetsgaranti på källtabellen och en indexsökning på insidan av sammanfogningen. För att se detta i praktiken kan vi rensa bort befintliga iscensättningsdata, lägga till unikhet till det icke-klustrade indexet och prova MERGE igen:
-- Remove existing duplicate rows
TRUNCATE TABLE dbo.Staging;
-- Convert index to unique
CREATE UNIQUE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey)
WITH (DROP_EXISTING = ON);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(5678);
-- Hole-filling merge
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey); Den resulterande exekveringsplanen använder återigen hålfyllningsoptimeringen för att undvika Halloween-skydd, med hjälp av en kapslad slinganslutning och en innersidasökning i måltabellen:
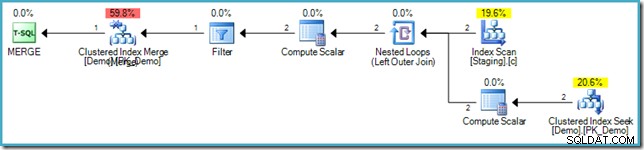
Undvika onödiga indexövergångar
Där hålfyllningsoptimeringen gäller kan motorn även tillämpa en ytterligare optimering. Den kan komma ihåg den aktuella indexpositionen medan den läser måltabellen (bearbetar en rad i taget, kom ihåg) och återanvänd den informationen när du utför infogningen, istället för att söka ner i b-trädet för att hitta infogningsplatsen. Resonemanget är att den aktuella läspositionen med stor sannolikhet är på samma sida där den nya raden ska infogas. Att kontrollera att raden faktiskt hör hemma på den här sidan går mycket snabbt, eftersom det innebär att endast kontrollera de lägsta och högsta nycklarna som för närvarande är lagrade där.
Kombinationen av att eliminera Eager Table Spool och spara en indexnavigering per rad kan ge en betydande fördel i OLTP-arbetsbelastningar, förutsatt att exekveringsplanen hämtas från cachen. Sammanställningskostnaden för MERGE satser är ganska högre än för INSERT , UPDATE och DELETE , så planera återanvändning är en viktig faktor. Det är också bra att se till att sidorna har tillräckligt med ledigt utrymme för att rymma nya rader och undvika siddelning. Detta uppnås vanligtvis genom normalt indexunderhåll och tilldelning av en lämplig FILLFACTOR .
Jag nämner OLTP-arbetsbelastningar, som vanligtvis innehåller ett stort antal relativt små ändringar, eftersom MERGE optimeringar kanske inte är ett bra val där ett stort antal rader bearbetas per sats. Andra optimeringar som minimalt loggade INSERTs kan för närvarande inte kombineras med hålfyllning. Som alltid bör prestandaegenskaperna jämföras för att säkerställa att de förväntade fördelarna realiseras.
Hålfyllningsoptimeringen för MERGE inlägg kan kombineras med uppdateringar och borttagningar med ytterligare MERGE klausuler; varje dataändringsoperation bedöms separat för Halloween-problemet.
Undviker att gå med
Den slutliga optimeringen vi kommer att titta på kan tillämpas där MERGE satsen innehåller uppdaterings- och borttagningsoperationer samt ett hålfyllningsinlägg, och måltabellen har ett unikt klustrat index. Följande exempel visar en vanlig MERGE mönster där omatchade rader infogas och matchande rader uppdateras eller tas bort beroende på ett ytterligare villkor:
CREATE TABLE #T
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_T
PRIMARY KEY (col1)
);
CREATE TABLE #S
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_S
PRIMARY KEY (col1)
);
INSERT #T
(col1, col2)
VALUES
(1, 50),
(3, 90);
INSERT #S
(col1, col2)
VALUES
(1, 40),
(2, 80),
(3, 90);
MERGE uttalande som krävs för att göra alla nödvändiga ändringar är anmärkningsvärt kompakt:
MERGE #T AS t USING #S AS s ON t.col1 = s.col1 WHEN NOT MATCHED THEN INSERT VALUES (s.col1, s.col2) WHEN MATCHED AND t.col2 - s.col2 = 0 THEN DELETE WHEN MATCHED THEN UPDATE SET t.col2 -= s.col2;
Utförandeplanen är ganska överraskande:

Inget Halloween-skydd, ingen koppling mellan käll- och måltabellerna, och det är inte ofta du ser en Clustered Index Insert-operator följt av en Clustered Index Merge till samma tabell. Detta är ytterligare en optimering riktad mot OLTP-arbetsbelastningar med hög återanvändningsplan och lämplig indexering.
Tanken är att läsa en rad från källtabellen och omedelbart försöka infoga den i målet. Om en nyckelöverträdelse uppstår, undertrycks felet, infogningsoperatören matar ut den motstridiga raden den hittade, och den raden bearbetas sedan för en uppdatering eller borttagning med operatören Merge plan som vanligt.
Om den ursprungliga infogningen lyckas (utan en nyckelöverträdelse) fortsätter behandlingen med nästa rad från källan (operatorn Merge bearbetar endast uppdateringar och borttagningar). Denna optimering gynnar främst MERGE frågor där de flesta källrader resulterar i en infogning. Återigen, noggrann benchmarking krävs för att säkerställa att prestanda är bättre än att använda separata uttalanden.
Sammanfattning
MERGE statement ger flera unika optimeringsmöjligheter. Under de rätta omständigheterna kan det undvika behovet av att lägga till explicit Halloween-skydd jämfört med en motsvarande INSERT operation, eller kanske till och med en kombination av INSERT , UPDATE och DELETE uttalanden. Ytterligare MERGE -specifika optimeringar kan undvika indexb-trädet som vanligtvis behövs för att lokalisera infogningspositionen för en ny rad, och kan också undvika behovet av att sammanfoga käll- och måltabellerna helt.
I den sista delen av den här serien kommer vi att titta på hur frågeoptimeraren resonerar kring behovet av Halloween-skydd, och identifiera några fler knep den kan använda för att undvika behovet av att lägga till Eager Table Spools till exekveringsplaner som ändrar data.
[ Del 1 | Del 2 | Del 3 | Del 4 ]