[ Del 1 | Del 2 | Del 3 | Del 4 ]
Halloweenproblemet kan ha ett antal viktiga effekter på genomförandeplaner. I den här sista delen av serien tittar vi på de knep som optimeraren kan använda för att undvika Halloween-problemet när man sammanställer planer för frågor som lägger till, ändrar eller tar bort data.
Bakgrund
Under årens lopp har ett antal tillvägagångssätt prövats för att undvika Halloweenproblemet. En tidig teknik var att helt enkelt undvika att bygga utförandeplaner som innebar att läsa från och skriva till nycklar av samma index. Detta var inte särskilt framgångsrikt ur prestandasynpunkt, inte minst eftersom det ofta innebar att man skannade bastabellen istället för att använda ett selektivt icke-klustrat index för att lokalisera de rader som skulle ändras.
Ett andra tillvägagångssätt var att helt separera läs- och skrivfaserna för en uppdateringsfråga, genom att först lokalisera alla rader som kvalificerar sig för ändringen, lagra dem någonstans och först sedan börja utföra ändringarna. I SQL Server, denna helfasseparation uppnås genom att placera den nu välbekanta Eager Table Spoolen på ingångssidan av uppdateringsoperatören:
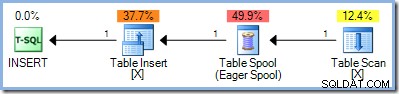
Spolen läser alla rader från dess indata och lagrar dem i en dold tempdb arbetsbord. Sidorna i denna arbetstabell kan finnas kvar i minnet, eller så kan de kräva fysiskt diskutrymme om uppsättningen rader är stor eller om servern är under minnespress.
Fullfasseparation kan vara mindre än idealiskt eftersom vi i allmänhet vill köra så mycket av planen som möjligt som en pipeline, där varje rad är färdigbearbetad innan vi går vidare till nästa. Pipelining har många fördelar, inklusive att undvika behovet av tillfällig lagring, och att endast röra varje rad en gång.
SQL Server Optimizer
SQL Server går mycket längre än de två tekniker som beskrivits hittills, även om den naturligtvis inkluderar båda som alternativ. SQL Server-frågeoptimeraren upptäcker frågor som kräver Halloween-skydd, bestämmer hur mycket skydd krävs och använder kostnadsbaserat analys för att hitta den billigaste metoden för att tillhandahålla det skyddet.
Det enklaste sättet att förstå denna aspekt av Halloween-problemet är att titta på några exempel. I de följande avsnitten är uppgiften att lägga till ett antal nummer till en befintlig tabell – men bara nummer som inte redan finns:
CREATE TABLE dbo.Test
(
pk integer NOT NULL,
CONSTRAINT PK_Test
PRIMARY KEY CLUSTERED (pk)
); 5 rader
Det första exemplet behandlar ett antal siffror från 1 till 5 inklusive:
INSERT dbo.Test (pk)
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 5
AND NOT EXISTS
(
SELECT NULL
FROM dbo.Test AS t
WHERE t.pk = Num.n
); Eftersom denna fråga läser från och skriver till nycklarna i samma index på testtabellen, kräver exekveringsplanen Halloween-skydd. I det här fallet använder optimeraren full fasseparation med en Eager Table Spool:
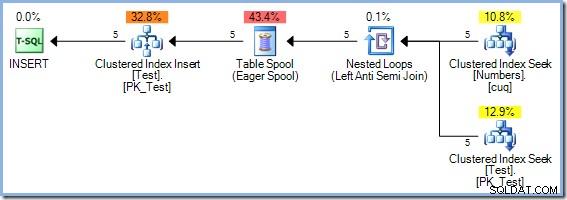
50 rader
Med fem rader nu i testtabellen kör vi samma fråga igen och ändrar WHERE klausul för att bearbeta siffrorna från 1 till och med 50 :
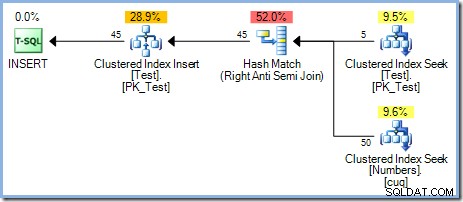
Den här planen ger korrekt skydd mot Halloween-problemet, men den har inte en Eager Table Spool. Optimeraren upptäcker att Hash Match join-operatören blockerar sin bygginmatning; alla rader läses in i en hashtabell innan operatören startar matchningsprocessen med hjälp av rader från sondens ingång. Som en konsekvens ger denna plan naturligtvis fasseparation (endast för testbordet) utan behov av en spole.
Optimeraren valde en Hash Match-anslutningsplan framför Nested Loops-anslutningen som ses i 5-radsplanen av kostnadsbaserade skäl. Hash Match-planen med 50 rader har en beräknad total kostnad på 0,0347345 enheter. Vi kan tvinga fram planen för kapslade loopar som användes tidigare med en ledtråd för att se varför optimeraren inte valde kapslade loopar:
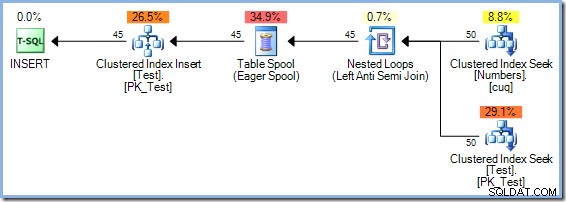
Den här planen har en beräknad kostnad på 0,0379063 enheter inklusive spolen, lite mer än Hash Match-planen.
500 rader
Med 50 rader nu i testtabellen utökar vi antalet siffror ytterligare till 500 :
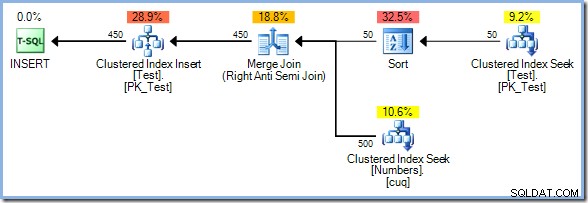
Den här gången väljer optimeraren en Merge Join, och återigen finns det ingen Eager Table Spool. Sorteringsoperatören tillhandahåller den nödvändiga fasseparationen i denna plan. Den förbrukar sin inmatning fullt ut innan den returnerar den första raden (sorteringen kan inte veta vilken rad som sorteras först förrän alla rader har setts). Optimeraren bestämde sig för att sortera 50 rader från testtabellen skulle vara billigare än eager-spooling 450 rader precis före uppdateringsoperatorn.
Sort plus Merge Join-planen har en uppskattad kostnad på 0,0362708 enheter. Planalternativen Hash Match och Nested Loops kommer ut på 0,0385677 enheter och 0,112433 enheter respektive.
Något konstigt med sorteringen
Om du har kört de här exemplen för dig själv kanske du har märkt något konstigt med det sista exemplet, särskilt om du tittade på Plan Explorer-verktygstipsen för testtabellen Seek and the Sorter:
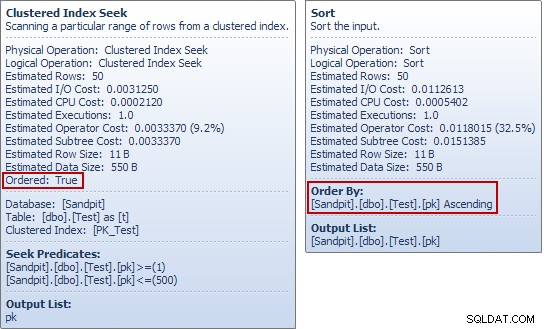
Sökningen producerar en beställd ström av pk värden, så vad är poängen med att sortera i samma kolumn direkt efteråt? För att svara på den (mycket rimliga) frågan börjar vi med att bara titta på SELECT del av INSERT fråga:
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 500
AND NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t
WHERE t.pk = Num.n
)
ORDER BY
Num.n;>
Den här frågan producerar exekveringsplanen nedan (med eller utan ORDER BY). Jag lade till för att ta itu med vissa tekniska invändningar du kan ha):
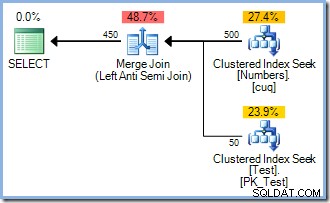
Lägg märke till bristen på en sorteringsoperator. Så varför gjorde INSERT planen inkluderar en sortera? Helt enkelt för att undvika Halloween-problemet. Optimeraren ansåg att utföra en redundant sortering (med sin inbyggda fasseparation) var det billigaste sättet att köra frågan och garantera korrekta resultat. Smart.
Halloween-skyddsnivåer och egenskaper
SQL Server-optimeraren har specifika funktioner som gör att den kan resonera om nivån på Halloween Protection (HP) som krävs vid varje punkt i frågeplanen, och den detaljerade effekten varje operatör har. Dessa extra funktioner är inkorporerade i samma egenskapsramverk som optimeraren använder för att hålla reda på hundratals andra viktiga informationsbitar under sina sökaktiviteter.
Varje operatör har en obligatorisk HP-egendom och en levererad HP egendom. Den obligatoriska egenskapen indikerar den nivå av HP som behövs vid den punkten i trädet för korrekta resultat. Den levererade egenskapen återspeglar HP som tillhandahålls av den aktuella operatören och den kumulativa HP-effekter tillhandahålls av dess underträd.
Optimeraren innehåller logik för att avgöra hur varje fysisk operatör (till exempel en Compute Scalar) påverkar HP-nivån. Genom att utforska ett brett utbud av planalternativ och avvisa planer där den levererade HP är mindre än den erforderliga HP hos uppdateringsoperatören, har optimeraren ett flexibelt sätt att hitta korrekta, effektiva planer som inte alltid kräver en Eager Table Spool.
Planera ändringar för Halloween Protection
Vi såg optimeraren lägga till en redundant sortering för Halloween Protection i det tidigare sammanslagningsexemplet. Hur kan vi vara säkra på att detta är effektivare än en enkel Eager Table Spool? Och hur kan vi veta vilka funktioner i en uppdateringsplan som endast finns där för Halloween-skydd?
Båda frågorna kan besvaras (naturligtvis i en testmiljö) med odokumenterad spårningsflagga 8692 , vilket tvingar optimeraren att använda en Eager Table Spool för Halloween-skydd. Kom ihåg att Merge Join-planen med redundant sort hade en uppskattad kostnad på 0,0362708 magiska optimeringsenheter. Vi kan jämföra det med alternativet Eager Table Spool genom att kompilera om frågan med spårningsflagga 8692 aktiverad:
INSERT dbo.Test (pk)
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 500
AND NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t
WHERE t.pk = Num.n
)
OPTION (QUERYTRACEON 8692);
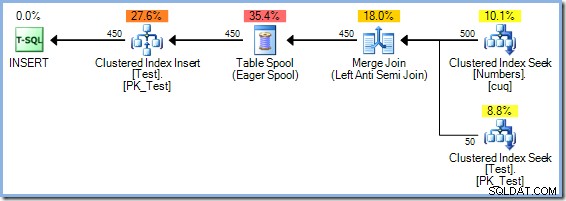
Eager Spool-planen har en uppskattad kostnad på 0,0378719 enheter (upp från 0,0362708 med den överflödiga sorten). Kostnadsskillnaderna som visas här är inte särskilt betydande på grund av uppgiftens triviala karaktär och radernas ringa storlek. Verkliga uppdateringsfrågor med komplexa träd och större radantal producerar ofta planer som är mycket effektivare tack vare SQL Server-optimerarens förmåga att tänka djupt om Halloween Protection.
Andra alternativ utan spool
Att placera en blockerande operatör optimalt inom en plan är inte den enda strategin som är öppen för optimeraren för att minimera kostnaderna för att tillhandahålla skydd mot Halloween-problemet. Det kan också resonera om intervallet av värden som bearbetas, vilket följande exempel visar:
CREATE TABLE #Test
(
pk integer IDENTITY PRIMARY KEY,
some_value integer
);
CREATE INDEX i ON #Test (some_value);
-- Pretend the table has lots of data in it
UPDATE STATISTICS #Test
WITH ROWCOUNT = 123456, PAGECOUNT = 1234;
UPDATE #Test
SET some_value = 10
WHERE some_value = 5; Utförandeplanen visar inget behov av Halloween-skydd, trots att vi läser från och uppdaterar nycklarna till ett gemensamt index:
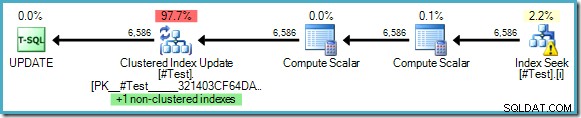
Optimeraren kan se att en ändring av "some_value" från 5 till 10 aldrig kan leda till att en uppdaterad rad ses en andra gång av Index Seek (som bara letar efter rader där some_value är 5). Detta resonemang är endast möjligt när bokstavliga värden används i frågan, eller där frågan anger OPTION (RECOMPILE) , vilket gör att optimeraren kan sniffa parametrarnas värden för en engångsexekveringsplan.
Även med bokstavliga värden i frågan, kan optimeraren förhindras från att tillämpa denna logik om databasalternativet FORCED PARAMETERIZATION är ON . I så fall ersätts de bokstavliga värdena i frågan med parametrar, och optimeraren kan inte längre vara säker på att Halloween Protection inte krävs (eller inte kommer att krävas när planen återanvänds med olika parametervärden):

Om du undrar vad som händer om FORCED PARAMETERIZATION är aktiverat och frågan anger OPTION (RECOMPILE) , svaret är att optimeraren sammanställer en plan för de sniffade värdena och så kan tillämpa optimeringen. Som alltid med OPTION (RECOMPILE) , är frågeplanen med specifikt värde inte cachelagrad för återanvändning.
Överst
Det här sista exemplet visar hur Top operatör kan ta bort behovet av Halloween-skydd:
UPDATE TOP (1) t SET some_value += 1 FROM #Test AS t WHERE some_value <= 10;

Inget skydd krävs eftersom vi bara uppdaterar en rad. Det uppdaterade värdet kan inte påträffas av Indexsökningen, eftersom bearbetningspipelinen stannar så snart den första raden uppdateras. Återigen, denna optimering kan endast tillämpas om ett konstant bokstavligt värde används i TOP , eller om en variabel som returnerar värdet '1' sniffas med OPTION (RECOMPILE) .
Om vi ändrar TOP (1) i frågan till en TOP (2) , väljer optimeraren en Clustered Index Scan istället för Index Seek:

Vi uppdaterar inte nycklarna för det klustrade indexet, så denna plan kräver inte Halloween-skydd. Framtvinga användningen av det icke-klustrade indexet med en ledtråd i TOP (2) fråga gör kostnaden för skyddet uppenbar:

Optimeraren uppskattade att Clustered Index Scan skulle vara billigare än denna plan (med dess extra Halloween-skydd).
Odds och slut
Det finns ett par andra punkter jag vill göra om Halloween Protection som inte har hittat en naturlig plats i serien tidigare. Den första är frågan om Halloween-skydd när en radversionsisoleringsnivå används.
Radversionering
SQL Server tillhandahåller två isoleringsnivåer, READ COMMITTED SNAPSHOT och SNAPSHOT ISOLATION som använder ett versionslager i tempdb för att ge en konsekvent vy av databasen på uttalande- eller transaktionsnivå. SQL Server skulle kunna undvika Halloween-skydd helt under dessa isoleringsnivåer, eftersom versionslagret kan tillhandahålla data som inte påverkas av eventuella ändringar som den körande satsen kan ha gjort hittills. Denna idé är för närvarande inte implementerad i en släppt version av SQL Server, även om Microsoft har lämnat in ett patent som beskriver hur detta skulle fungera, så kanske en framtida version kommer att införliva denna teknik.
Högar och vidarebefordrade poster
Om du är bekant med insidan av heapstrukturer, kanske du undrar om ett speciellt Halloween-problem kan uppstå när vidarebefordrade poster genereras i en heap-tabell. Om detta är nytt för dig kommer en heappost att vidarebefordras om en befintlig rad uppdateras så att den inte längre får plats på den ursprungliga datasidan. Motorn lämnar efter sig en vidarebefordran och flyttar den utökade posten till en annan sida.
Ett problem kan uppstå om en plan som innehåller en heap-skanning uppdaterar en post så att den vidarebefordras. Högskanningen kan stöta på raden igen när skanningspositionen når sidan med den vidarebefordrade posten. I SQL Server undviks detta problem eftersom Storage Engine garanterar att alltid följa vidarebefordranpekare omedelbart. Om skanningen stöter på en post som har vidarebefordrats ignoreras den. Med detta skydd på plats behöver frågeoptimeraren inte oroa sig för det här scenariot.
SCHEMABINDING och T-SQL skalära funktioner
Det finns väldigt få tillfällen då det är en bra idé att använda en T-SQL skalär funktion, men om du måste använda en så bör du vara medveten om en viktig effekt det kan ha angående Halloween Protection. Såvida inte en skalär funktion deklareras med SCHEMABINDING alternativet, antar SQL Server att funktionen kommer åt tabeller. För att illustrera, överväg den enkla T-SQL skalära funktionen nedan:
CREATE FUNCTION dbo.ReturnInput
(
@value integer
)
RETURNS integer
AS
BEGIN
RETURN @value;
END;
Denna funktion kommer inte åt några tabeller; i själva verket gör den ingenting förutom att returnera parametervärdet som skickas till den. Titta nu på följande INSERT fråga:
DECLARE @T AS TABLE (ProductID integer PRIMARY KEY); INSERT @T (ProductID) SELECT p.ProductID FROM AdventureWorks2012.Production.Product AS p;
Utförandeplanen är precis som vi kan förvänta oss, utan att det behövs något Halloween-skydd:
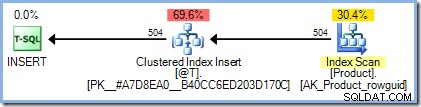
Att lägga till vår gör-ingenting-funktion har dock en dramatisk effekt:
DECLARE @T AS TABLE (ProductID integer PRIMARY KEY); INSERT @T (ProductID) SELECT dbo.ReturnInput(p.ProductID) FROM AdventureWorks2012.Production.Product AS p;

Utförandeplanen inkluderar nu en Eager Table Spool för Halloween-skydd. SQL Server antar att funktionen kommer åt data, vilket kan inkludera läsning från produkttabellen igen. Som du kanske minns, en INSERT plan som innehåller en referens till måltabellen på lässidan av planen kräver fullt Halloween-skydd, och så vitt optimeraren vet kan det vara fallet här.
Lägger till SCHEMABINDING alternativet till funktionsdefinitionen innebär att SQL Server undersöker funktionens kropp för att avgöra vilka tabeller den har åtkomst till. Den hittar ingen sådan åtkomst och lägger därför inte till något Halloween-skydd:
ALTER FUNCTION dbo.ReturnInput
(
@value integer
)
RETURNS integer
WITH SCHEMABINDING
AS
BEGIN
RETURN @value;
END;
GO
DECLARE @T AS TABLE (ProductID int PRIMARY KEY);
INSERT @T (ProductID)
SELECT p.ProductID
FROM AdventureWorks2012.Production.Product AS p;
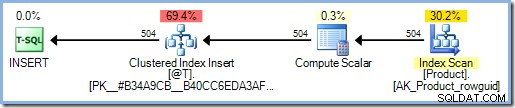
Det här problemet med T-SQL skalära funktioner påverkar alla uppdateringsfrågor – INSERT , UPDATE , DELETE , och MERGE . Att veta när du stöter på det här problemet försvåras eftersom onödigt Halloween-skydd inte alltid kommer att dyka upp som en extra Eager Table Spool, och skalära funktionsanrop kan till exempel vara dolda i vyer eller beräknade kolumndefinitioner.
[ Del 1 | Del 2 | Del 3 | Del 4 ]