Inom informationsteknologins värld är automatisering ingen ny sak för de flesta av oss. Faktum är att de flesta organisationer använder det för olika ändamål beroende på deras arbetstyp och mål. Till exempel använder dataanalytiker automatisering för att generera rapporter, systemadministratörer använder automatisering för sina repetitiva uppgifter som att rensa diskutrymme och utvecklare använder automatisering för att automatisera sin utvecklingsprocess.
Nuförtiden finns det många automationsverktyg för IT tillgängliga och kan väljas, tack vare DevOps-eran. Vilket är det bästa verktyget? Svaret är ett förutsägbart "det beror på", eftersom det beror på vad vi försöker uppnå samt vår miljöinställning. Några av automationsverktygen är Terraform, Bolt, Chef, SaltStack och ett väldigt trendigt är Ansible. Ansible är en agentfri IT-motor utan öppen källkod som kan automatisera applikationsdistribution, konfigurationshantering och IT-orkestrering. Ansible grundades 2012 och har skrivits på det mest populära språket, Python. Den använder en spelbok för att implementera all automatisering, där alla konfigurationer är skrivna på ett läsbart språk, YAML.
I dagens inlägg kommer vi att lära oss hur man använder Ansible för att distribuera Postgresql-databas.
Vad gör Ansible speciellt?
Anledningen till att ansible används främst på grund av dess funktioner. Dessa funktioner är:
-
Vad som helst kan automatiseras genom att använda ett enkelt läsbart språk YAML
-
Ingen agent kommer att installeras på fjärrdatorn (agentlös arkitektur)
-
Konfigurationen kommer att skickas från din lokala dator till servern från din lokala dator (push-modell)
-
Utvecklad med Python (ett av de populära språken som används för närvarande) och många bibliotek kan väljas från
-
Samling av Ansible-moduler noggrant utvalda av Red Had Engineering Team
Så som Ansible fungerar
Innan Ansible kan köra några operativa uppgifter till fjärrvärdarna måste vi installera det i en värd som kommer att bli styrenhetsnoden. I den här kontrollernoden kommer vi att orkestrera alla uppgifter som vi skulle vilja göra i fjärrvärdarna, även kända som hanterade noder.
Kontrollnoden måste ha inventeringen av de hanterade noderna och Ansible-programvaran för att hantera den. De data som krävs för att användas av Ansible, som värdnamn eller IP-adress för hanterad nod, kommer att placeras i detta inventarium. Utan en ordentlig inventering kunde Ansible inte göra automatiseringen korrekt. Se här för att lära dig mer om inventering.
Ansible är agentlöst och använder SSH för att driva ändringarna, vilket innebär att vi inte behöver installera Ansible i alla noder, men alla hanterade noder måste ha python och alla nödvändiga pythonbibliotek installerade. Både kontrollnoden och hanterade noder måste ställas in som lösenordslösa. Det är värt att nämna att kopplingen mellan alla styrnoder och hanterade noder är bra och testade ordentligt.
För denna demo har jag tillhandahållit 4 Centos 8 virtuella datorer genom att använda vagrant. En kommer att fungera som en kontrollnod och de andra 2 virtuella datorerna kommer att fungera som databasnoder som ska distribueras. Vi går inte in på detaljer om hur man installerar Ansible i det här blogginlägget men om du skulle vilja se guiden, besök gärna denna länk. Observera att vi använder 3 noder för att ställa in en strömmande replikeringstopologi, med en primär och 2 standbynoder. Nuförtiden är många produktionsdatabaser i en högtillgänglighetsinställning och en konfiguration med tre noder är vanlig.
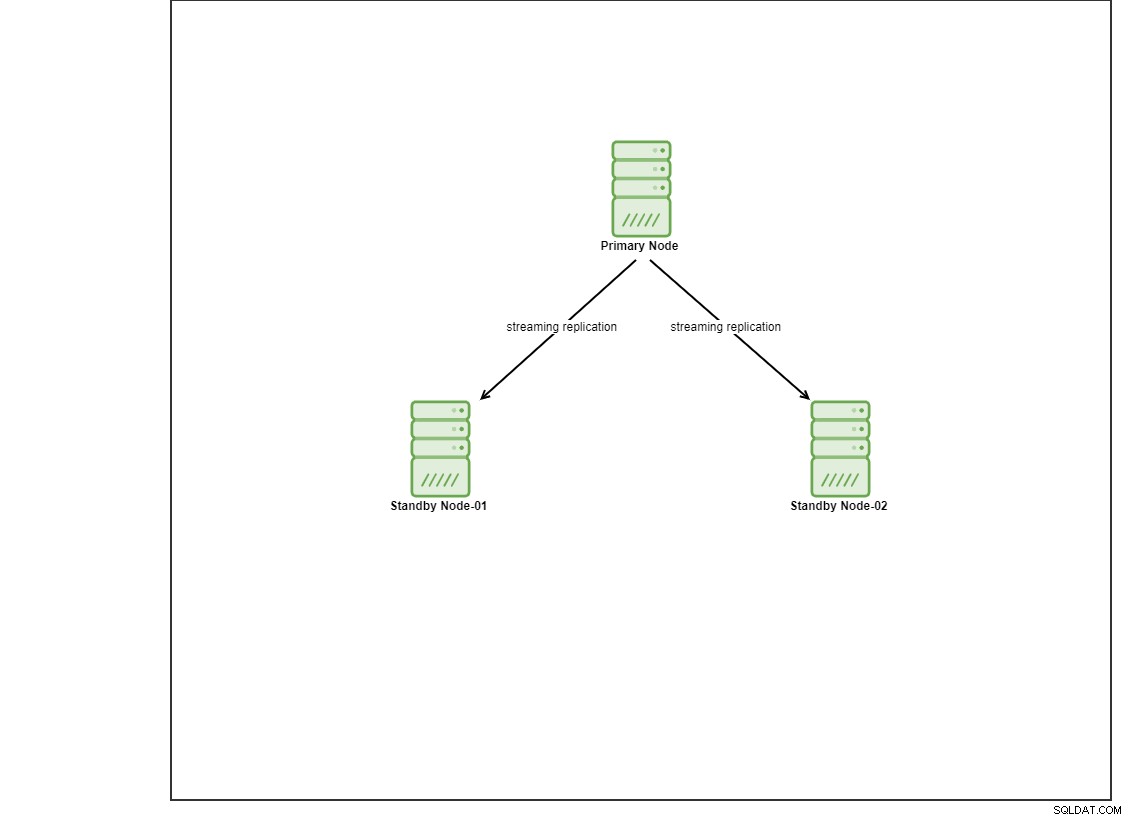
Installera PostgreSQL
Det finns flera sätt att installera PostgreSQL genom att använda Ansible. Idag kommer jag att använda Ansible-roller för att uppnå detta syfte. Ansible roller i ett nötskal är en uppsättning uppgifter för att konfigurera en värd för att tjäna ett visst syfte som att konfigurera en tjänst. Ansible-roller definieras med YAML-filer med en fördefinierad katalogstruktur som är tillgänglig för nedladdning från Ansible Galaxy-portalen.
Ansible Galaxy å andra sidan är ett arkiv för Ansible-roller som är tillgängliga att släppa direkt i dina Playbooks för att effektivisera dina automationsprojekt.
För denna demo har jag valt de roller som har underhållits av dudefellah. För att vi ska kunna använda den här rollen måste vi ladda ner och installera den till kontrollernoden. Uppgiften är ganska enkel och kan göras genom att köra följande kommando förutsatt att Ansible har installerats på din styrenhetsnod:
$ ansible-galaxy install dudefellah.postgresqlDu bör se följande resultat när rollen har installerats framgångsrikt i din kontrollernod:
$ ansible-galaxy install dudefellah.postgresql
- downloading role 'postgresql', owned by dudefellah
- downloading role from https://github.com/dudefellah/ansible-role-postgresql/archive/0.1.0.tar.gz
- extracting dudefellah.postgresql to /home/ansible/.ansible/roles/dudefellah.postgresql
- dudefellah.postgresql (0.1.0) was installed successfully
För att vi ska kunna installera PostgreSQL med den här rollen, finns det några steg som måste göras. Här kommer Ansible Playbook. Ansible Playbook är där vi kan skriva Ansible-kod eller en samling av de skript som vi skulle vilja köra på de hanterade noderna. Ansible Playbook använder YAML och består av en eller flera pjäser som körs i en viss ordning. Du kan definiera värdar såväl som en uppsättning uppgifter som du vill köra på den tilldelade värddatorn eller hanterade noder.
Alla uppgifter kommer att utföras som den möjliga användaren som loggat in. För att vi ska kunna utföra uppgifterna med en annan användare inklusive 'root', kan vi använda oss av bli. Låt oss ta en titt på pg-play.yml nedan:
$ cat pg-play.yml
- hosts: pgcluster
become: yes
vars_files:
- ./custom_var.yml
roles:
- role: dudefellah.postgresql
postgresql_version: 13Som du kan se har jag definierat värdarna som pgcluster och använder bli så att Ansible kör uppgifterna med sudo-privilegiet. Användare vagrant finns redan i sudoer-gruppen. Jag har också definierat rollen som jag installerade dudefellah.postgresql. pgcluster har definierats i hosts-filen som jag skapade. Om du undrar hur det ser ut kan du ta en titt nedan:
$ cat pghost
[pgcluster]
10.10.10.11 ansible_user=ansible
10.10.10.12 ansible_user=ansible
10.10.10.13 ansible_user=ansibleUtöver det har jag skapat en annan anpassad fil (custom_var.yml) där jag inkluderade all konfiguration och inställningar för PostgreSQL som jag skulle vilja implementera. Detaljerna för den anpassade filen är enligt nedan:
$ cat custom_var.yml
postgresql_conf:
listen_addresses: "*"
wal_level: replica
max_wal_senders: 10
max_replication_slots: 10
hot_standby: on
postgresql_users:
- name: replication
password: example@sqldat.com
privs: "ALL"
role_attr_flags: "SUPERUSER,REPLICATION"
postgresql_pg_hba_conf:
- { type: "local", database: "all", user: "all", method: "trust" }
- { type: "host", database: "all", user: "all", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "127.0.0.1/32", method: "md5" }För att köra installationen behöver vi bara köra följande kommando. Du kommer inte att kunna köra kommandot ansible-playbook utan playbook-filen som skapats (i mitt fall är det pg-play.yml).
$ ansible-playbook pg-play.yml -i pghostEfter att jag kört det här kommandot kommer det att köra några uppgifter som definieras av rollen och kommer att visa detta meddelande om kommandot kördes framgångsrikt:
PLAY [pgcluster] *************************************************************************************
TASK [Gathering Facts] *******************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Load platform variables] ***********************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Set up role-specific facts based on some inputs and the OS distribution] ***
included: /home/ansible/.ansible/roles/dudefellah.postgresql/tasks/role_facts.yml for 10.10.10.11, 10.10.10.12När ansiblen slutfört uppgifterna loggade jag in på slaven (n2), stoppade PostgreSQL-tjänsten, tog bort innehållet i datakatalogen (/var/lib/pgsql/13/data/) och kör följande kommando för att initiera säkerhetskopieringsuppgiften:
$ sudo -u postgres pg_basebackup -h 10.10.10.11 -D /var/lib/pgsql/13/data/ -U replication -P -v -R -X stream -C -S slaveslot1
10.10.10.11 is the IP address of the master. We can now verify the replication slot by logging into the master:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_replication_slots;
-[ RECORD 1 ]-------+-----------
slot_name | slaveslot1
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | t
active_pid | 63854
xmin |
catalog_xmin |
restart_lsn | 0/3000148
confirmed_flush_lsn |
wal_status | reserved
safe_wal_size |Vi kan också kontrollera statusen för replikeringen i vänteläge med följande kommando efter att vi startat tillbaka PostgreSQL-tjänsten:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_stat_wal_receiver;
-[ RECORD 1 ]---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
pid | 229552
status | streaming
receive_start_lsn | 0/3000000
receive_start_tli | 1
written_lsn | 0/3000148
flushed_lsn | 0/3000148
received_tli | 1
last_msg_send_time | 2021-05-09 14:10:00.29382+00
last_msg_receipt_time | 2021-05-09 14:09:59.954983+00
latest_end_lsn | 0/3000148
latest_end_time | 2021-05-09 13:53:28.209279+00
slot_name | slaveslot1
sender_host | 10.10.10.11
sender_port | 5432
conninfo | user=replication password=******** channel_binding=prefer dbname=replication host=10.10.10.11 port=5432 fallback_application_name=walreceiver sslmode=prefer sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=anySom du kan se finns det mycket arbete som måste göras för att vi ska kunna ställa in replikeringen för PostgreSQL även om vi har automatiserat några av uppgifterna. Låt oss se hur detta kan åstadkommas med ClusterControl.
PostgreSQL-distribution med ClusterControl GUI
Nu när vi vet hur man distribuerar PostgreSQL med Ansible, låt oss se hur vi kan distribuera med ClusterControl. ClusterControl är en hanterings- och automatiseringsprogramvara för databaskluster inklusive MySQL, MariaDB, MongoDB samt TimescaleDB. Det hjälper till att distribuera, övervaka, hantera och skala ditt databaskluster. Det finns två sätt att distribuera databasen, i det här blogginlägget kommer vi att visa dig hur du distribuerar den med det grafiska användargränssnittet (GUI) förutsatt att du redan har ClusterControl installerat i din miljö.
Det första steget är att logga in på din ClusterControl och klicka på Deploy:
Du kommer att presenteras med skärmdumpen nedan för nästa steg i implementeringen , välj fliken PostgreSQL för att fortsätta:
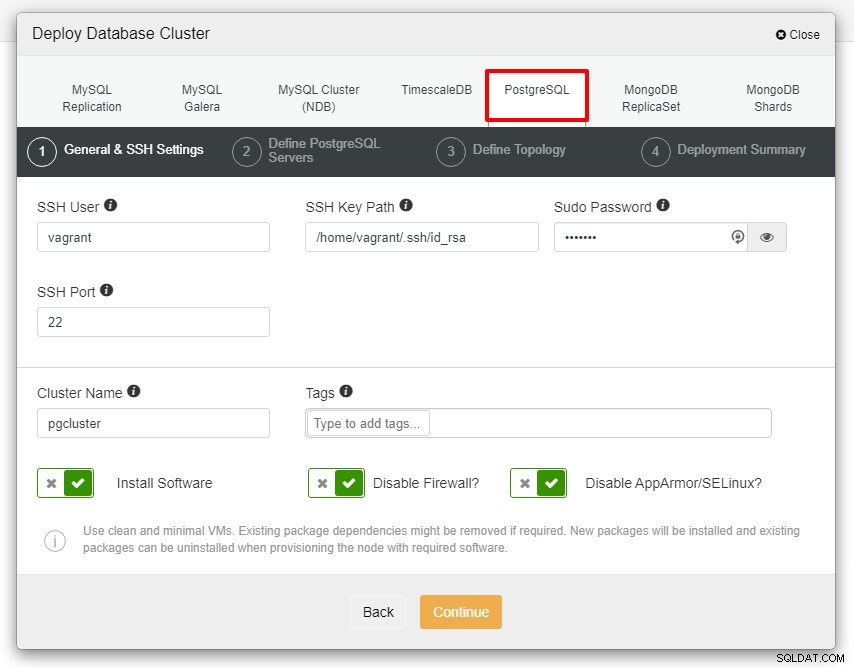
Innan vi går vidare vill jag påminna dig om att kopplingen mellan ClusterControl-noden och databasens noder måste vara lösenordslös. Innan vi implementerar är allt vi behöver göra att generera ssh-keygen från ClusterControl-noden och sedan kopiera den till alla noder. Fyll i inmatningen för SSH-användare, Sudo-lösenord samt klusternamn enligt dina krav och klicka på Fortsätt.
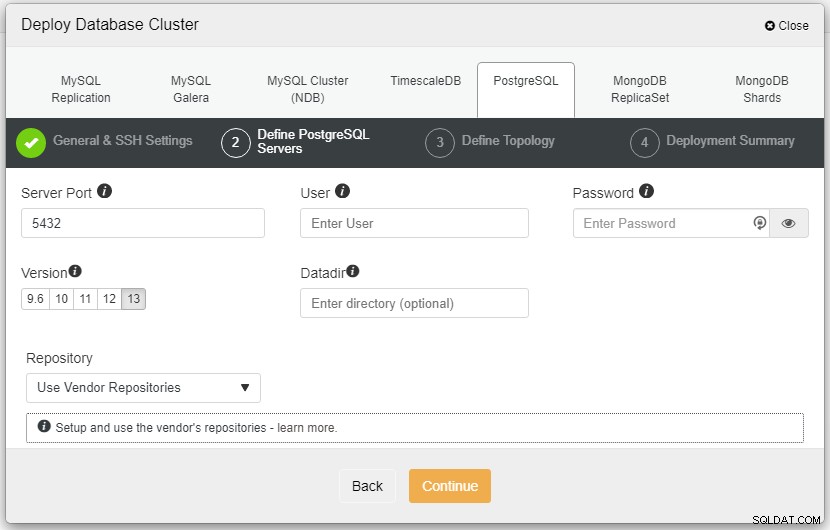
I skärmdumpen ovan måste du definiera serverporten (om du skulle vilja använda andra), användaren som du vill ha samt lösenordet och den version du vill ha att installera.
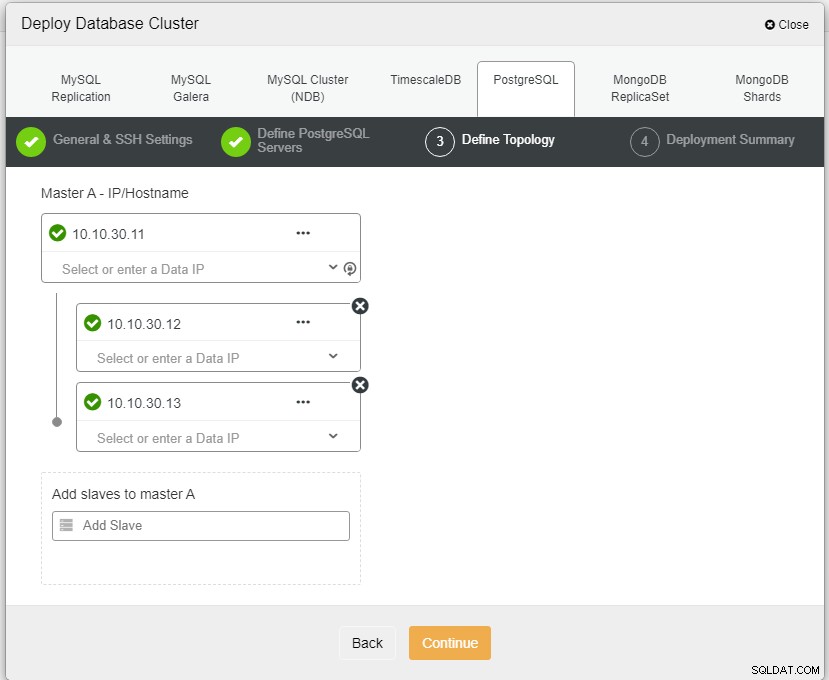
Här måste vi definiera servrarna antingen med värdnamnet eller IP-adressen, som i det här fallet 1 master och 2 slavar. Det sista steget är att välja replikeringsläge för vårt kluster.
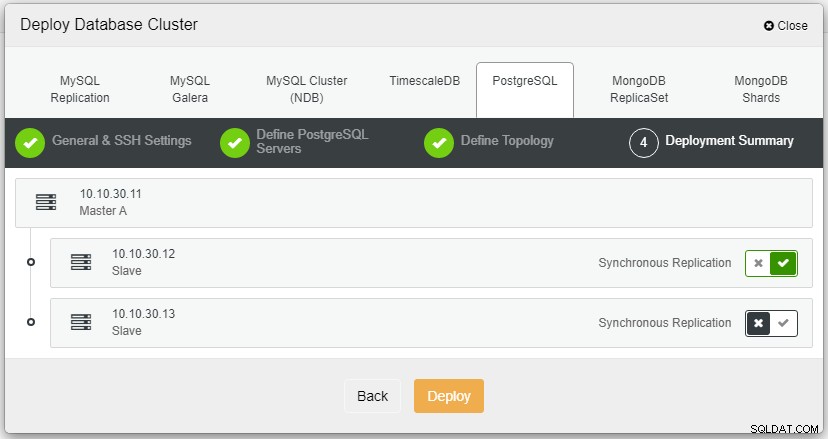
När du klickar på Distribuera startar implementeringsprocessen och vi kan övervaka framstegen på fliken Aktivitet.
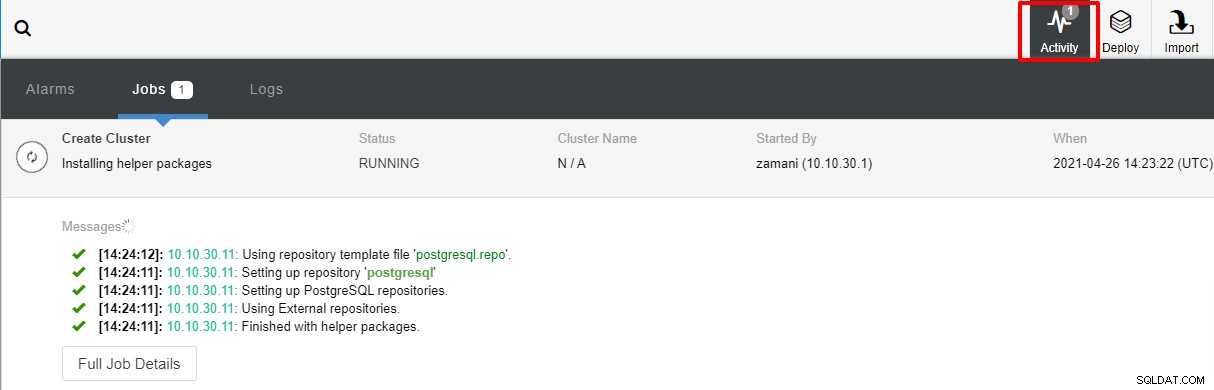
Implementeringen tar normalt ett par minuter, prestandan beror mest på nätverket och serverns specifikationer.

Nu när vi har PostgreSQL installerat med ClusterControl.
PostgreSQL-distribution med ClusterControl CLI
Det andra alternativa sättet att distribuera PostgreSQL är att använda CLI. förutsatt att vi redan har konfigurerat den lösenordslösa anslutningen, kan vi bara köra följande kommando och låta det avslutas.
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.50.11?master;10.10.50.12?slave;10.10.50.13?slave" --provider-version=13 --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logDu bör se meddelandet nedan när processen har slutförts framgångsrikt och kan logga in på ClusterControl-webben för att verifiera:
...
Saving cluster configuration.
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.Slutsats
Som du kan se finns det några sätt att distribuera PostgreSQL. I det här blogginlägget har vi lärt oss hur man distribuerar det genom att använda Ansible och att använda vår ClusterControl. Båda sätten är lätta att följa och kan uppnås med en minimal inlärningskurva. Med ClusterControl kan strömmande replikeringsinställningen kompletteras med HAProxy, VIP och PGBouncer för att lägga till anslutningsfel, virtuell IP och anslutningspooling till konfigurationen.
Observera att distribution bara är en aspekt av en produktionsdatabasmiljö. Att hålla det igång, automatisera failovers, återställa trasiga noder och andra aspekter som övervakning, varning, säkerhetskopiering är viktigt.
Förhoppningsvis kommer det här blogginlägget att vara till nytta för några av er och ge en idé om hur man automatiserar PostgreSQL-distributioner.