I mina inlägg i år har jag diskuterat knä-ryck-reaktionerna på olika väntetyper, och i det här inlägget kommer jag att fortsätta med temat väntestatistik och diskutera PAGEIOLATCH_XX vänta. Jag säger "vänta" men det finns verkligen flera typer av PAGEIOLATCH väntar, vilket jag har betecknat med XX på slutet. De vanligaste exemplen är:
PAGEIOLATCH_SH– (SH are) väntar på att en datafilsida ska tas från disken till buffertpoolen så att dess innehåll kan läsasPAGEIOLATCH_EXellerPAGEIOLATCH_UP– (EX clusive eller UP datum) väntar på att en datafilsida ska föras från disken till buffertpoolen så att dess innehåll kan ändras
Av dessa är den överlägset vanligaste typen PAGEIOLATCH_SH .
När denna väntetyp är den vanligaste på en server, är reaktionen att I/O-delsystemet måste ha ett problem och det är där utredningarna bör fokuseras.
Det första du ska göra är att jämföra PAGEIOLATCH_SH väntantal och varaktighet mot din baslinje. Om volymen av väntetider är mer eller mindre densamma, men varaktigheten av varje läsvänte har blivit mycket längre, skulle jag oroa mig för ett I/O-undersystemsproblem, som:
- En felkonfiguration/felfunktion på I/O-delsystemnivå
- Nätverkslatens
- En annan I/O-arbetsbelastning som orsakar konflikt med vår arbetsbelastning
- Konfiguration av replikering/spegling av synkront I/O-undersystem
Enligt min erfarenhet är mönstret ofta att antalet PAGEIOLATCH_SH väntetider har ökat avsevärt från baslinjen (normal) och väntetiden har också ökat (dvs tiden för en läs-I/O har ökat), eftersom det stora antalet läsningar överbelastas I/O-delsystemet. Detta är inte ett I/O-subsystemproblem – det här är SQL Server som driver fler I/O än det borde vara. Fokus måste nu växla till SQL Server för att identifiera orsaken till de extra I/O:erna.
Orsaker till stort antal lästa I/O
SQL Server har två typer av läsningar:logiska I/O och fysiska I/O. När Access Methods-delen av Storage Engine behöver komma åt en sida, ber den buffertpoolen om en pekare till sidan i minnet (kallas en logisk I/O) och buffertpoolen kontrollerar sin metadata för att se om den sidan är redan i minnet.
Om sidan finns i minnet ger buffertpoolen åtkomstmetoderna pekaren och I/O förblir en logisk I/O. Om sidan inte finns i minnet utfärdar buffertpoolen en "riktig" I/O (kallad fysisk I/O) och tråden måste vänta på att den ska slutföras – vilket medför en PAGEIOLATCH_XX vänta. När I/O är klar och pekaren är tillgänglig meddelas tråden och kan fortsätta att köras.
I en idealisk värld skulle hela din arbetsbelastning passa i minnet och så när buffertpoolen har "värmts upp" och håller hela arbetsbelastningen krävs inga fler läsningar, bara skrivningar av uppdaterad data. Det är dock inte en idealisk värld, och de flesta av er har inte den lyxen, så vissa läsningar är oundvikliga. Så länge antalet läsningar ligger runt ditt baslinjebelopp är det inga problem.
När ett stort antal läsningar plötsligt och oväntat krävs, är det ett tecken på att det finns en betydande förändring i antingen arbetsbelastningen, mängden buffertpoolminne som är tillgängligt för att lagra kopior av sidor i minnet eller bådadera.
Här är några möjliga grundorsaker (inte en uttömmande lista):
- Externt Windows-minnestryck på SQL Server som gör att minneshanteraren minskar storleken på buffertpoolen
- Planera cache-uppblåsning som gör att extra minne kan lånas från buffertpoolen
- En frågeplan som gör en tabell-/klustrad indexsökning (istället för en indexsökning) på grund av:
- en ökad arbetsbelastningsvolym
- ett parametersniffningsproblem
- ett obligatoriskt icke-klustrat index som har tagits bort eller ändrats
- en implicit konvertering
Ett mönster att leta efter som skulle tyda på att en tabell/klustrad indexsökning är orsaken är att även se ett stort antal CXPACKET väntar tillsammans med PAGEIOLATCH_SH väntar. Detta är ett vanligt mönster som indikerar att stora, parallella tabell-/klustrade indexsökningar förekommer.
I alla fall kan du titta på vilken frågeplan som orsakar PAGEIOLATCH_SH väntar med sys.dm_os_waiting_tasks och andra DMV:er, och du kan få kod för att göra det i mitt blogginlägg här. Om du har ett övervakningsverktyg från tredje part tillgängligt kan det kanske hjälpa dig att identifiera den skyldige utan att bli smutsig på händerna.
Exempel på arbetsflöde med SQL Sentry och Plan Explorer
I ett enkelt (uppenbarligen konstruerat) exempel, låt oss anta att jag är på ett klientsystem som använder SQL Sentrys verktygssvit och ser en topp i I/O-väntningar i instrumentpanelsvyn av SQL Sentry, som visas nedan:
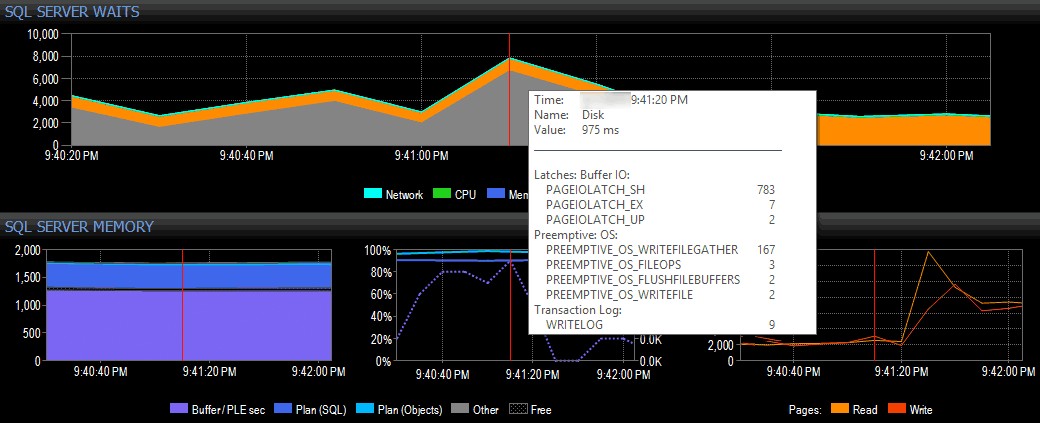
Att se en topp i I/O väntar i SQL Sentry
Jag bestämmer mig för att undersöka det genom att högerklicka på ett valt tidsintervall runt tiden för spiken och sedan hoppa över till den översta SQL-vyn, som kommer att visa mig de dyraste frågorna som har körts:
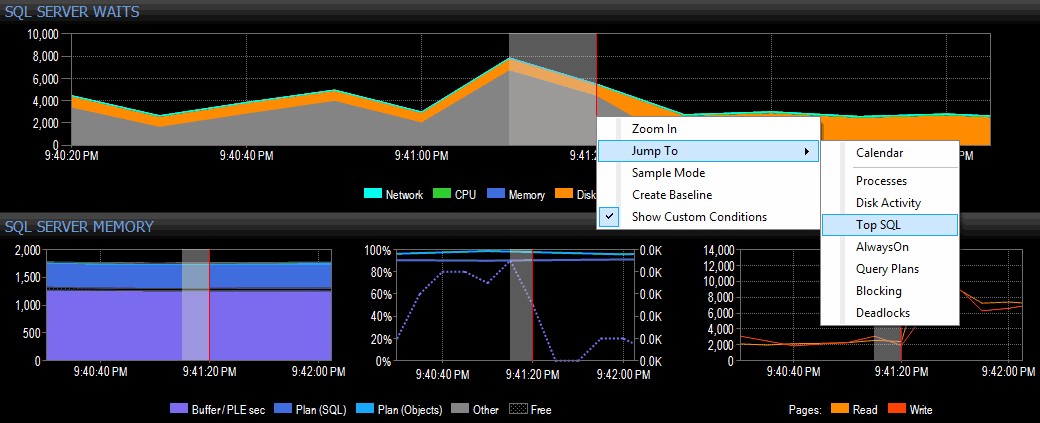
Markera ett tidsintervall och navigera till Top SQL
I den här vyn kan jag se vilka långa eller höga I/O-frågor som kördes när spiken inträffade, och sedan välja att gå in på deras frågeplaner (i det här fallet finns det bara en långvarig fråga, som gick i nästan en minut):
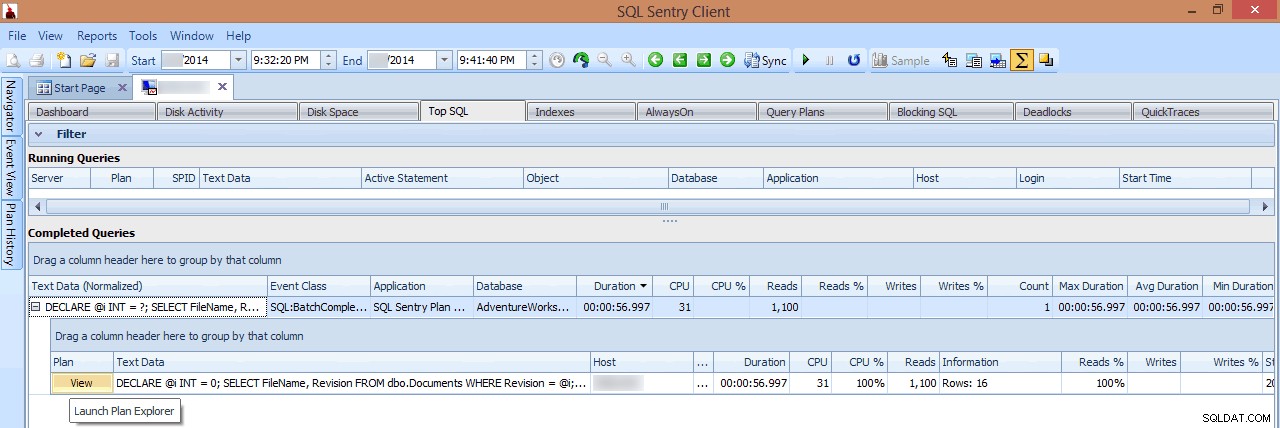
Granska en långvarig fråga i Top SQL
Om jag tittar på planen i SQL Sentry-klienten eller öppnar den i SQL Sentry Plan Explorer, ser jag omedelbart flera problem. Antalet läsningar som krävs för att returnera 7 rader verkar alldeles för högt, deltat mellan beräknade och faktiska rader är stort, och planen visar att en indexskanning sker där jag skulle ha förväntat mig en sökning:
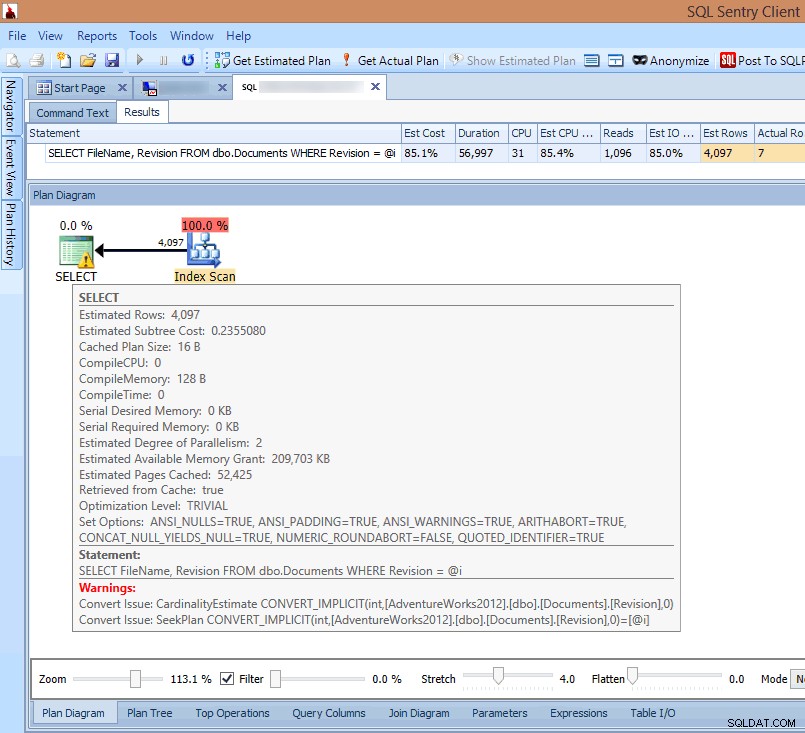
Se implicita konverteringsvarningar i frågeplanen
Orsaken till allt detta markeras i varningen på SELECT operator:Det är en implicit omvandling!
Implicita omvandlingar är ett lömskt problem som orsakas av en oöverensstämmelse mellan sökpredikatets datatyp och datatypen för den kolumn som genomsöks, eller att en beräkning utförs på tabellkolumnen snarare än sökpredikatet. I båda fallen kan SQL Server inte använda en indexsökning i tabellkolumnen och måste använda en skanning istället.
Detta kan dyka upp i till synes oskyldig kod, och ett vanligt exempel är att använda en datumberäkning. Om du har en tabell som lagrar kundernas ålder och du vill göra en beräkning för att se hur många som är 21 år eller äldre idag, kan du skriva kod så här:
WHERE DATEADD (YEAR, 21, [MyTable].[BirthDate]) <= @today;
Med den här koden ligger beräkningen i tabellkolumnen och därför kan en indexsökning inte användas, vilket resulterar i ett osökbart uttryck (tekniskt känt som ett icke-SARG-bart uttryck) och en tabell/klustrad indexsökning. Detta kan lösas genom att flytta beräkningen till andra sidan av operatorn:
WHERE [MyTable].[BirthDate] <= DATEADD (YEAR, -21, @today);
När det gäller när en grundläggande kolumnjämförelse kräver en datatypskonvertering som kan orsaka en implicit konvertering, skrev min kollega Jonathan Kehayias ett utmärkt blogginlägg som jämför varje kombination av datatyper och noterar när en implicit konvertering kommer att krävas.
Sammanfattning
Gå inte i fällan att tro att överdriven PAGEIOLATCH_XX väntetider orsakas av I/O-delsystemet. Enligt min erfarenhet orsakas de vanligtvis av något som har med SQL Server att göra och det var där jag skulle börja felsöka.
När det gäller allmän väntestatistik kan du hitta mer information om hur du använder dem för prestandafelsökning i:
- Min SQLskills blogginläggsserie, som börjar med Vänta statistik, eller snälla berätta för mig var det gör ont
- Mina väntetyper och låsklasser-bibliotek här
- Min Pluralsight onlinekurs SQL Server:Prestandafelsökning med hjälp av väntastatistik
- SQL Sentry
I nästa artikel i serien kommer jag att diskutera en annan väntetyp som är en vanlig orsak till knä-rycks reaktioner. Tills dess, glad felsökning!