Kvaliteten på en utförandeplan är starkt beroende av noggrannheten hos det uppskattade antalet rader som matas ut av varje planoperatör. Om det uppskattade antalet rader är avsevärt snedställt från det faktiska antalet rader kan detta ha en betydande inverkan på kvaliteten på en frågas exekveringsplan. Dålig plankvalitet kan vara orsaken till överdriven I/O, uppblåst CPU, minnestryck, minskad genomströmning och minskad total samtidighet.
Med "plankvalitet" – jag pratar om att låta SQL Server generera en exekveringsplan som resulterar i fysiska operatörsval som återspeglar det aktuella tillståndet för data. Genom att fatta sådana beslut baserat på korrekt data finns det en större chans att frågan kommer att fungera korrekt. Kardinalitetsuppskattningsvärdena används som indata för operatörskostnad, och när värdena är för långt borta från verkligheten kan den negativa påverkan på genomförandeplanen bli uttalad. Dessa uppskattningar matas till de olika kostnadsmodellerna som är associerade med själva frågan, och dåliga raduppskattningar kan påverka en mängd olika beslut, inklusive indexval, sökning kontra skanningsoperationer, parallellt kontra seriellt exekvering, val av kopplingsalgoritm, inre vs. yttre fysisk koppling urval (t.ex. build kontra sond), spoolgenerering, bokmärkessökningar kontra fullständig klustrad eller heap-tabellåtkomst, ström- eller hashaggregaturval och om en dataändring använder en bred eller smal plan eller inte.
Som ett exempel, låt oss säga att du har följande SELECT fråga (med kreditdatabasen):
SELECT m.member_no, m.lastname, p.payment_no, p.payment_dt, p.payment_amt FROM dbo.member AS m INNER JOIN dbo.payment AS p ON m.member_no = p.member_no;
Baserat på frågelogiken, är följande planform vad du kan förvänta dig att se?
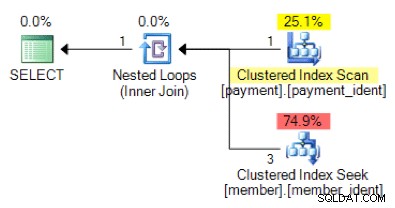
Och hur är det med den här alternativa planen, där vi istället för en kapslad loop har en hash-matchning?
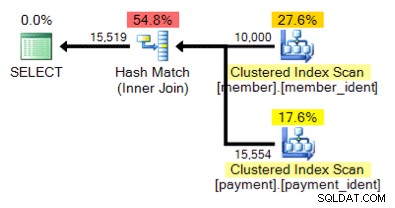
Det "rätta" svaret är beroende av några andra faktorer – men en viktig faktor är antalet rader i var och en av tabellerna. I vissa fall är den ena algoritmen för fysisk anslutning mer lämplig än den andra – och om de initiala antagandena om uppskattning av kardinalitet inte är korrekta kan din fråga använda ett icke-optimalt tillvägagångssätt.
Identifiering kardinalitetsberäkningsfrågor är relativt okomplicerade. Om du har en verklig utförandeplan kan du jämföra de uppskattade kontra faktiska radräkningsvärdena för operatörer och leta efter skevheter. SQL Sentry Plan Explorer förenklar den här uppgiften genom att låta dig se faktiska kontra beräknade rader för alla operatorer i en enda planträdsflik kontra att behöva hålla muspekaren över de individuella operatorerna i den grafiska planen:

Nu, skevheter resulterar inte alltid i planer av dålig kvalitet, men om du har prestandaproblem med en fråga och du ser sådana skevheter i planen, är detta ett område som då är värt att undersökas ytterligare.
Identifiering av kardinalitetsberäkningsproblem är relativt enkel, men lösningen är det ofta inte. Det finns ett antal grundorsaker till varför problem med uppskattning av kardinalitet kan uppstå, och jag ska täcka tio av de vanligaste orsakerna i det här inlägget.
Saknad eller inaktuell statistik
Av alla orsaker till problem med kardinalitetsuppskattningar är detta den som du hoppas att se, eftersom det ofta är lättast att ta itu med. I det här scenariot saknas din statistik antingen eller är inaktuell. Du kan ha databasalternativ för automatiskt skapande av statistik och uppdateringar inaktiverade, "ingen omberäknad" aktiverad för specifik statistik, eller ha tillräckligt stora tabeller för att dina automatiska statistikuppdateringar helt enkelt inte sker tillräckligt ofta.
Provproblem
Det kan vara så att precisionen i statistikhistogrammet är otillräcklig – till exempel om du har en mycket stor tabell med betydande och/eller frekventa dataskevningar. Du kan behöva ändra ditt urval från standarden eller om inte ens det hjälper – undersök med hjälp av separata tabeller, filtrerad statistik eller filtrerade index.
Dolda kolumnkorrelationer
Frågeoptimeraren förutsätter att kolumner i samma tabell är oberoende. Till exempel, om du har en stad och en delstatskolumn, kan vi intuitivt veta att dessa två kolumner är korrelerade, men SQL Server förstår inte detta om vi inte hjälper det med ett associerat index med flera kolumner eller med manuellt skapade multi-kolumner. kolumnstatistik. Utan att hjälpa optimeraren med korrelation kan selektiviteten hos dina predikat vara överdriven.
Nedan är ett exempel på två korrelerade predikat:
SELECT lastname, firstname FROM dbo.member WHERE city = 'Minneapolis' AND state_prov - 'MN';
Jag råkar veta att 10 % av våra 10 000 rader member tabell kvalificerar sig för denna kombination, men frågeoptimeraren gissar att det är 1 % av de 10 000 raderna:
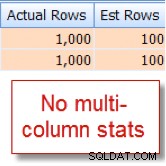
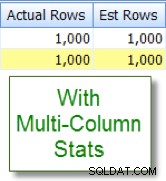
Kontra nu detta med den lämpliga uppskattningen som jag ser efter att ha lagt till statistik med flera kolumner:
Jämförelser av kolumner inom tabell
Kardinalitetsuppskattningsproblem kan uppstå när man jämför kolumner i samma tabell. Detta är ett känt problem. Om du måste göra det kan du förbättra kardinalitetsuppskattningarna av kolumnjämförelserna genom att använda beräknade kolumner istället eller genom att skriva om frågan för att använda självkopplingar eller vanliga tabelluttryck.
Tabellvariabel användning
Använder du tabellvariabler mycket? Tabellvariabler visar en kardinalitetsuppskattning på "1" – vilket för bara ett litet antal rader kanske inte är ett problem, men för stora eller flyktiga resultatuppsättningar kan det avsevärt påverka frågeplanens kvalitet. Nedan finns en skärmdump av en operatörs uppskattning av 1 rad kontra de faktiska 1 600 000 raderna från @charge tabellvariabel:

Om detta är din grundorsak, skulle du vara klokt att utforska alternativ som tillfälliga tabeller och eller permanenta tabeller där så är möjligt.
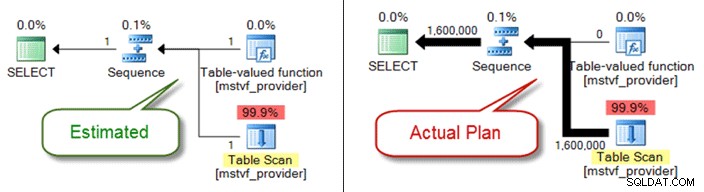
Scalar och MSTV UDF
I likhet med tabellvariabler är flersatstabellvärderade och skalära funktioner en svart låda ur ett kardinalitetsuppskattningsperspektiv. Om du stöter på problem med plankvaliteten på grund av dem, överväg inline-tabellfunktioner som ett alternativ – eller till och med dra ut funktionsreferensen helt och bara hänvisa till objekt direkt.
Nedan visas en uppskattad kontra faktisk plan när du använder en tabellvärderad funktion med flera uttalanden:
Problem med datatyp
Implicita datatypproblem i samband med sök- och anslutningsvillkor kan orsaka problem med uppskattning av kardinalitet. De kan också i smyg äta upp resurser på servernivå (CPU, I/O, minne), så det är viktigt att ta itu med dem när det är möjligt.
Komplexa predikat
Du har förmodligen sett det här mönstret tidigare – en fråga med en WHERE klausul som har varje tabellkolumnreferens insvept i olika funktioner, sammanlänkningsoperationer, matematiska operationer och mer. Och även om inte all funktionsomslutning utesluter korrekta kardinalitetsuppskattningar (som för LOWER , UPPER och GETDATE ) det finns många sätt att begrava ditt predikat till den grad att frågeoptimeraren inte längre kan göra korrekta uppskattningar.
Frågekomplexitet
I likhet med begravda predikat, är dina frågor utomordentligt komplexa? Jag inser att "komplex" är en subjektiv term, och din bedömning kan variera, men de flesta kan hålla med om att kapsling av vyer i vyer i vyer som refererar till överlappande tabeller sannolikt inte är optimalt - särskilt när det kombineras med 10+ tabellkopplingar, funktionsreferenser och begravda predikat. Även om frågeoptimeraren gör ett beundransvärt jobb, är den inte magisk, och om du har betydande skevheter, kan frågekomplexitet (schweizisk arméknivsfrågor) verkligen göra det näst intill omöjligt att härleda exakta raduppskattningar för operatörer.
Distribuerade frågor
Använder du distribuerade frågor med länkade servrar och du ser betydande problem med uppskattning av kardinalitet? Om så är fallet, se till att kontrollera behörigheterna som är associerade med den länkade serverprincipen som används för att komma åt data. Utan minsta db_ddladmin fast databasroll för det länkade serverkontot, denna brist på synlighet för fjärrstatistik på grund av otillräckliga behörigheter kan vara källan till dina kardinalitetsuppskattningsproblem.
Och det finns andra...
Det finns andra anledningar till att uppskattningar av kardinalitet kan vara skeva, men jag tror att jag har täckt de vanligaste. Nyckelpunkten är att vara uppmärksam på skevningarna i samband med kända, dåligt presterande frågor. Anta inte att planen skapades baserat på exakta radräkningsförhållanden. Om dessa siffror är sneda måste du försöka felsöka detta först.