Min kollega Steve Wright (blogg | @SQL_Steve) frågade mig nyligen om ett konstigt resultat han såg. För att testa lite funktionalitet i vårt senaste verktyg, SQL Sentry Plan Explorer PRO, hade han tillverkat ett brett och stort bord och körde en mängd olika frågor mot den. I ett fall returnerade han mycket data, men STATISTICS IO visade att väldigt få läsningar ägde rum. Jag pingade några personer på #sqlhelp och eftersom det verkade som att ingen hade sett det här problemet tänkte jag att jag skulle blogga om det.
TL;DR-version
Kort sagt, var mycket medveten om att det finns vissa scenarier där du inte kan lita på STATISTICS IO för att berätta sanningen. I vissa fall (denna som involverar TOP och parallellism), kommer det att avsevärt underrapportera logiska läsningar. Detta kan få dig att tro att du har en mycket I/O-vänlig fråga när du inte har det. Det finns andra mer uppenbara fall – som när du har en massa I/O gömda genom att använda skalära användardefinierade funktioner. Vi tror att Plan Explorer gör dessa fall mer uppenbara; den här är dock lite knepigare.
Problemfrågan
Tabellen har 37 miljoner rader, upp till 250 byte per rad, cirka 1 miljon sidor och mycket låg fragmentering (0,42 % på nivå 0, 15 % på nivå 1 och 0 utöver det). Det finns inga beräknade kolumner, inga UDF:er i spel och inga index förutom en klustrad primärnyckel på den ledande INT kolumn. En enkel fråga som returnerar 500 000 rader, alla kolumner, med TOP och SELECT * :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029');
(Och ja, jag inser att jag bryter mot mina egna regler och använder SELECT * och TOP utan ORDER BY , men för enkelhetens skull gör jag mitt bästa för att minimera mitt inflytande på optimeraren.)
Resultat:
(500 000 rad(er) påverkas)Tabell 'OrderHistory'. Scan count 1, logiskt läser 23, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob läser framåt läser 0.
Vi returnerar 500 000 rader och det tar cirka 10 sekunder. Jag vet direkt att något är fel med det logiska läsnumret. Även om jag inte redan kände till de underliggande data, kan jag se från rutnätsresultaten i Management Studio att detta drar mer än 23 sidor med data, oavsett om de är från minnet eller cache, och detta bör återspeglas någonstans i STATISTICS IO . Tittar på planen...
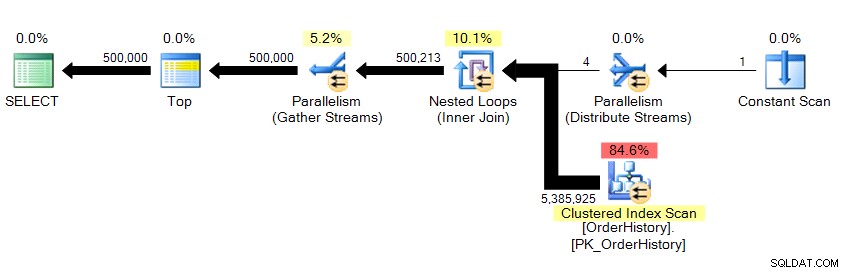
...vi ser att parallellism finns där, och att vi har skannat hela tabellen. Så hur är det möjligt att det bara finns 23 logiska läsningar?
Ännu en "identisk" fråga
En av mina första frågor till Steve var:"Vad händer om du eliminerar parallellism?" Så jag provade det. Jag tog den ursprungliga versionen av underfrågan och lade till MAXDOP 1 :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029') OPTION (MAXDOP 1);
Resultat och plan:
(500 000 rad(er) påverkas)Tabell 'OrderHistory'. Scan count 1, logiskt läser 149589, fysiskt läser 0, läs framåt läser 0, lob logiskt läser 0, lob fysisk läser 0, lob läser framåt läser 0.
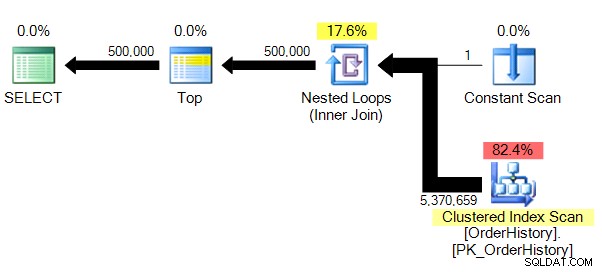
Vi har en lite mindre komplex plan, och utan parallellism (av uppenbara skäl), STATISTICS IO visar oss mycket mer trovärdiga siffror för logiska läsräkningar.
Vad är sanningen?
Det är inte svårt att se att en av dessa frågor inte talar hela sanningen. Medan STATISTICS IO kanske inte berättar hela historien, kanske spår kommer. Om vi hämtar runtime-statistik genom att generera en verklig exekveringsplan i Plan Explorer, ser vi att den magiska låglästa frågan i själva verket drar data från minnet eller disken, och inte från ett moln av magiskt pixie-damm. Faktum är att den har *fler* läsningar än den andra versionen:

Så det är tydligt att läsningar sker, de visas bara inte korrekt i STATISTICS IO utdata.
Vad är problemet?
Nåväl, jag ska vara helt ärlig:jag vet inte, förutom det faktum att parallellitet definitivt spelar en roll, och det verkar vara något slags rastillstånd. STATISTICS IO (och eftersom det är där vi får data visar vår Tabell I/O-flik) ett mycket missvisande antal läsningar. Det är tydligt att frågan returnerar all data vi letar efter, och det är tydligt från spårningsresultaten att den använder läsningar och inte osmos för att göra det. Jag frågade Paul White (blogg | @SQL_Kiwi) om det och han föreslog att endast en del av I/O-talen före tråden ingår i summan (och håller med om att detta är ett fel).
Om du vill prova det här hemma behöver du bara AdventureWorks (detta bör repro mot 2008, 2008 R2 och 2012 versioner), och följande fråga:
SET STATISTICS IO ON; DBCC SETCPUWEIGHT(1000) WITH NO_INFOMSGS; GO SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101'); SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101') OPTION (MAXDOP 1); DBCC SETCPUWEIGHT(1) WITH NO_INFOMSGS;
(Observera att SETCPUWEIGHT används endast för att få parallellism. För mer information, se Paul Whites blogginlägg om Plan Costing.)
Resultat:
Tabell 'SalesOrderHeader'. Scan count 1, logiskt läser 4, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob read-ahead läser 0.Tabell 'SalesOrderHeader'. Scan count 1, logiskt läser 333, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob läser framåt läser 0.
Paul påpekade en ännu enklare repro:
SET STATISTICS IO ON; GO SELECT TOP (15000) * FROM Production.TransactionHistory WHERE TransactionDate < (SELECT '20080101') OPTION (QUERYTRACEON 8649, MAXDOP 4); SELECT TOP (15000) * FROM Production.TransactionHistory AS th WHERE TransactionDate < (SELECT '20080101');
Resultat:
Tabell 'Transaktionshistorik'. Scan count 1, logiskt läser 5, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob read-ahead läser 0.Tabell 'TransactionHistory'. Scan count 1, logiskt läser 110, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob läser framåt läser 0.
Så det verkar som att vi enkelt kan reproducera detta efter behag med en TOP operatör och en tillräckligt låg DOP. Jag har registrerat ett fel:
- STATISTIK IO underrapporterar logiska läsningar för parallella planer
Och Paul har lämnat in två andra något relaterade fel som involverar parallellism, den första som ett resultat av vårt samtal:
- Kardinalitetsuppskattningsfel med pushat predikat vid en uppslagning [ relaterat blogginlägg ]
- Dålig prestanda med parallellism och topp [ relaterat blogginlägg ]
(För nostalgiker, här är sex andra parallellitetsfel som jag påpekade för några år sedan.)
Vad är lektionen?
Var försiktig med att lita på en enda källa. Om du bara tittar på STATISTICS IO efter att ha ändrat en fråga som denna kan du bli frestad att fokusera på den mirakulösa minskningen av antalet läsningar istället för ökningen av varaktigheten. Då kan du klappa dig själv på axeln, lämna jobbet tidigt och njuta av din helg, och tro att du just har haft en enorm inverkan på din fråga. När naturligtvis ingenting kunde vara längre från sanningen.