Ett vanligt scenario i många klient-serverapplikationer är att tillåta slutanvändaren att diktera sorteringsordningen för resultaten. Vissa människor vill se de billigaste föremålen först, andra vill se de nyaste föremålen först och andra vill se dem i alfabetisk ordning. Detta är en komplex sak att uppnå i Transact-SQL eftersom du inte bara kan säga:
SKAPA PROCEDUR dbo.SortOnSomeTable @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'AS BEGIN ... ORDER BY @SortColumn; -- eller ... BESTÄLL EFTER @SortColumn @SortDirection;ENDGO
Detta beror på att T-SQL inte tillåter variabler på dessa platser. Om du bara använder @SortColumn får du:
Msg 1008, Nivå 16, Tillstånd 1, Rad xVÄLJ-objektet som identifieras av ORDER BY-nummer 1 innehåller en variabel som en del av uttrycket som identifierar en kolumnposition. Variabler är endast tillåtna när man beställer efter ett uttryck som refererar till ett kolumnnamn.
(Och när felmeddelandet säger "ett uttryck som hänvisar till ett kolumnnamn", kanske du tycker att det är tvetydigt, och jag håller med. Men jag kan försäkra dig om att detta inte betyder att en variabel är ett lämpligt uttryck.)
Om du försöker lägga till @SortDirection är felmeddelandet lite mer ogenomskinligt:
Msg 102, Level 15, State 1, Line xFelaktig syntax nära '@SortDirection'.
Det finns några sätt att kringgå detta, och din första instinkt kan vara att använda dynamisk SQL, eller att introducera CASE-uttrycket. Men som med det mesta finns det komplikationer som kan tvinga dig in på en eller annan väg. Så vilken ska du använda? Låt oss undersöka hur dessa lösningar kan fungera och jämföra effekterna på prestanda för några olika tillvägagångssätt.
Exempeldata
Med hjälp av en katalogvy som vi alla förmodligen förstår ganska väl, sys.all_objects, skapade jag följande tabell baserad på en korskoppling, vilket begränsade tabellen till 100 000 rader (jag ville ha data som fyllde många sidor men det tog inte så lång tid att fråga och testa):
SKAPA DATABAS OrderBy;GOUSE OrderBy;GO SELECT TOP (100000) key_col =ROW_NUMBER() OVER (ORDER BY s1.[object_id]), -- en BIGINT med klustrade index s1.[object_id], -- en INT utan ett indexnamn =s1.name -- en NVARCHAR med ett stödjande index COLLATE SQL_Latin1_General_CP1_CI_AS, type_desc =s1.type_desc -- en NVARCHAR(60) utan ett index COLLATE SQL_Latin1_General_CP1_CI_AS, s1.index_modify_date_s1.index_modify_time sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2ORDER BY s1.[object_id];
(SAMMANSTÄLLNING-tricket beror på att många katalogvyer har olika kolumner med olika sorteringar, och detta säkerställer att de två kolumnerna matchar för syftet med denna demo.)
Sedan skapade jag ett typiskt klustrat/icke-klustrat indexpar som kan finnas i en sådan tabell, före optimering (jag kan inte använda object_id för nyckeln, eftersom korskopplingen skapar dubbletter):
SKAPA UNIKT CLUSTERED INDEX key_col PÅ dbo.sys_objects(key_col); SKAPA INDEX-namn PÅ dbo.sys_objects(name);
Användningsfall
Som nämnts ovan kanske användare vill se denna data sorterad på en mängd olika sätt, så låt oss beskriva några typiska användningsfall som vi vill stödja (och med support menar jag visa):
- Ordnad efter key_col stigande ** standard om användaren inte bryr sig
- Ordnad efter object_id (stigande/fallande)
- Sorterat efter namn (stigande/fallande)
- Ordnad efter type_desc (stigande/fallande)
- Ordnad efter modify_date (stigande/fallande)
Vi lämnar key_col-ordningen som standard eftersom den borde vara den mest effektiva om användaren inte har en preferens; eftersom key_col är ett godtyckligt surrogat som inte borde betyda något för användaren (och kanske inte ens exponeras för dem), finns det ingen anledning att tillåta omvänd sortering på den kolumnen.
Tillvägagångssätt som inte fungerar
Det vanligaste tillvägagångssättet jag ser när någon först börjar ta itu med det här problemet är att införa kontroll-av-flödeslogik i frågan. De förväntar sig att kunna göra detta:
SELECT key_col, [object_id], name, type_desc, modify_dateFROM dbo.sys_objectsORDER BY IF @SortColumn ='key_col' key_colIF @SortColumn ='object_id' [object_id]IF @SortColumn ='name' name...IF @SortDirection ='ASC' ASCELSE DESC;
Detta fungerar uppenbarligen inte. Därefter ser jag CASE introduceras felaktigt, med liknande syntax:
SELECT key_col, [object_id], name, type_desc, modify_dateFROM dbo.sys_objectsORDER BY CASE @SortColumn WHEN 'key_col' THEN key_col WHEN 'object_id' THEN [object_id] NÄR 'name' THEN name ... END CASE WHEN @SortDirection 'ASC' SEDAN ASC ELSE DESC END;
Detta är närmare, men det misslyckas av två skäl. En är att CASE är ett uttryck som returnerar exakt ett värde av en specifik datatyp; detta slår samman datatyper som är inkompatibla och kommer därför att bryta CASE-uttrycket. Den andra är att det inte finns något sätt att villkorligt tillämpa sorteringsriktningen på detta sätt utan att använda dynamisk SQL.
Tillvägagångssätt som fungerar
De tre primära tillvägagångssätten jag har sett är följande:
Gruppera kompatibla typer och vägbeskrivningar tillsammans
För att kunna använda CASE med ORDER BY måste det finnas ett distinkt uttryck för varje kombination av kompatibla typer och riktningar. I det här fallet skulle vi behöva använda något i stil med detta:
SKAPA PROCEDUR dbo.Sort_CaseExpanded @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'SOM BÖRJAN STÄLLA IN NOCOUNT ON; VÄLJ key_col, [object_id], name, type_desc, modify_date FRÅN dbo.sys_objects ORDER BY CASE WHEN @SortDirection ='ASC' SEN CASE @SortColumn NÄR 'key_col' DÅ key_col NÄR 'object_id' SEDAN [object_id' SEDAN [object_id' SÄNTA [object_id] END WHEN_ID] . SortDirection ='DESC' DÅ CASE @SortColumn NÄR 'key_col' DÅ key_col NÄR 'object_id' DÅ [object_id] END END DESC, CASE NÄR @SortDirection ='ASC' DÅ CASE @SortColumn NÄR 'namn' DÅ namn NÄR' 'typ type_desc END END, CASE WHEN @SortDirection ='DESC' DÅ CASE @SortColumn NÄR 'namn' DÅ namn NÄR 'type_desc' DÅ typ_desc END END DESC, CASE WHEN @SortColumn ='modify_date' OCH @SortDirection THEN ='ASCdate' , CASE NÄR @SortColumn ='modify_date' OCH @SortDirection ='DESC' DÅ modify_date END DESC;END
Du kan säga, wow, det är en ful bit kod, och jag håller med dig. Jag tror att det är anledningen till att många människor cachelagrar sina data i fronten och låter presentationsnivån hantera att jonglera runt den i olika ordningsföljder. :-)
Du kan kollapsa denna logik lite ytterligare genom att konvertera alla icke-strängtyper till strängar som kommer att sortera korrekt, t.ex.
SKAPA PROCEDUR dbo.Sort_CaseCollapsed @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'SOM BÖRJAN STÄLLA IN NOCOUNT ON; VÄLJ key_col, [object_id], name, type_desc, modify_date FRÅN dbo.sys_objects ORDER BY CASE WHEN @SortDirection ='ASC' SEN CASE @SortColumn NÄR 'key_col' DÅ HÖGER('0000000000000)_col('000000)' + RTRIM(key), '12key' object_id' THEN RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0') + REPLICATE('0', 23) + RTRIM([objekt_id]), 24) NÄR 'namn' DÅ namn NÄR 'typ_desc' DÅ typ_desc NÄR 'modifiera_datum' DÅ KONVERTERA(CHAR(19), modifiera_datum, 120) END END, CASE WHEN @SortDirection ='DESC' DÅ CASE @SortColumn NÄR 'key_col' THEN RIGHT(' 000000000000' + RTRIM(nyckelkol), 12) WHEN 'object_id' THEN RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0') + REPLICATE('0', 23 ) + RTRIM([objekt_id]), 24) NÄR 'namn' DÅ namn NÄR 'typ_desc' DÅ typ_desc NÄR 'modifiera_datum' DÅ KONVERTERA(CHAR(19), modifiera_datum, 120) END END DESC;END Ändå är det en ganska ful röra, och du måste upprepa uttrycken två gånger för att hantera de olika sorteringsriktningarna. Jag skulle också misstänka att användning av OPTION RECOMPILE på den frågan skulle förhindra att du blir stungen av parametersniffning. Förutom i standardfallet är det inte som att majoriteten av arbetet som görs här kommer att vara kompilering.
Tillämpa en rangordning med fönsterfunktioner
Jag upptäckte detta snygga trick från AndriyM, även om det är mest användbart i fall där alla potentiella ordningskolumner är av kompatibla typer, annars är uttrycket som används för ROW_NUMBER() lika komplext. Det smartaste är att för att växla mellan stigande och fallande ordning, multiplicerar vi helt enkelt ROW_NUMBER() med 1 eller -1. Vi kan tillämpa det i den här situationen enligt följande:
SKAPA PROCEDUR dbo.Sort_RowNumber @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'AS BÖRJAN STÄLLA IN NOCOUNT ON;;WITH x AS ( SELECT key_col, [object_id], name, type_desc, modify_date, rn =ROW_NUMBER() OVER ( ORDER BY CASE @SortColumn NÄR 'key_col' DÅ HÖGER('000000000000' + RTRIM(key_WHEN), '12) object_id' THEN RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0') + REPLICATE('0', 23) + RTRIM([objekt_id]), 24) NÄR 'name' THEN name WHEN 'type_desc' THEN typ_desc WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120) END ) * CASE @SortDirection WHEN 'ASC' THEN 1 ELSE -1 END FROM key dbo.sys_objects_col ) SELECT , [object_id], name, type_desc, modify_date FROM x BESTÄLLNING AV rn;ENDGO Återigen kan OPTION RECOMPILE hjälpa till här. I vissa av dessa fall kanske du också märker att band hanteras olika av de olika planerna - när du beställer efter namn, till exempel, kommer du vanligtvis att se key_col komma igenom i stigande ordning inom varje uppsättning dubbletter av namn, men du kan också se värdena blandade ihop. För att ge ett mer förutsägbart beteende vid oavgjort, kan du alltid lägga till en ytterligare ORDER BY-klausul. Observera att om du skulle lägga till key_col till det första exemplet, måste du göra det till ett uttryck så att key_col inte listas i ORDER BY två gånger (du kan till exempel göra detta med key_col + 0).
Dynamisk SQL
Många människor har reservationer mot dynamisk SQL – det är omöjligt att läsa, det är en grogrund för SQL-injektion, det leder till plan cache-bloat, det motverkar syftet med att använda lagrade procedurer... Vissa av dessa är helt enkelt osanna, och några av dem är lätta att mildra. Jag har lagt till en del validering här som lika gärna kan läggas till någon av ovanstående procedurer:
SKAPA PROCEDUR dbo.Sort_DynamicSQL @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'SOM BÖRJAN STÄLLA IN NOCOUNT ON; -- avvisa alla ogiltiga sorteringsanvisningar:IF UPPER(@SortDirection) NOT IN ('ASC','DESC') BEGIN RAISERROR('Ogiltig parameter för @SortDirection:%s', 11, 1, @SortDirection); RETUR -1; END -- avvisa alla oväntade kolumnnamn:IF LOWER(@SortColumn) NOT IN (N'key_col', N'object_id', N'name', N'type_desc', N'modify_date') BEGIN RAISERROR('Ogiltig parameter för @SortColumn:%s', 11, 1, @SortColumn); RETUR -1; END SET @SortColumn =QUOTENAME(@SortColumn); DEKLARERA @sql NVARCHAR(MAX); SET @sql =N'SELECT key_col, [object_id], name, type_desc, modify_date FRÅN dbo.sys_objects ORDER BY ' + @SortColumn + ' ' + @SortDirection + ';'; EXEC sp_executesql @sql;END Prestandajämförelser
Jag skapade en omslagslagrad procedur för varje procedur ovan, så att jag enkelt kunde testa alla scenarier. De fyra omslagsprocedurerna ser ut så här, med procedurens namn som naturligtvis varierar:
SKAPA PROCEDUR dbo.Test_Sort_CaseExpandedASBEGIN STÄLL IN NOCOUNT PÅ; EXEC dbo.Sort_CaseExpanded; -- standard EXEC dbo.Sort_CaseExpanded N'name', 'ASC'; EXEC dbo.Sort_CaseExpanded N'name', 'DESC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'ASC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'DESC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'ASC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'DESC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'ASC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'DESC';END
Och sedan med hjälp av SQL Sentry Plan Explorer genererade jag faktiska exekveringsplaner (och mätvärdena för att följa med dem) med följande frågor och upprepade processen 10 gånger för att summera total varaktighet:
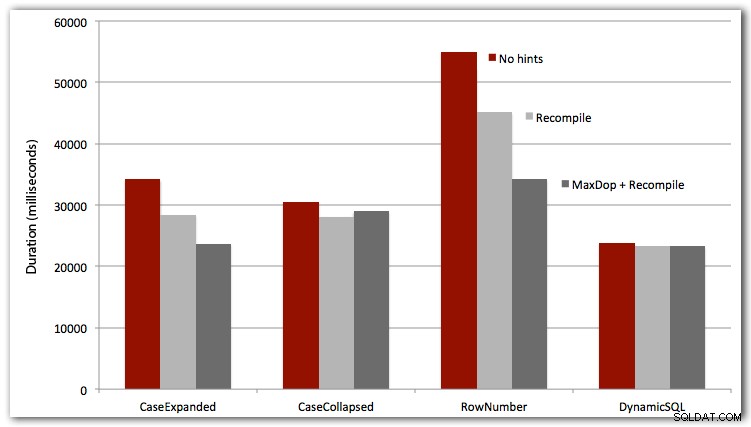
DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;EXEC dbo.Test_Sort_CaseExpanded;--EXEC dbo.Test_Sort_CaseCollapsed;--EXEC dbo.Test_Sort_RowNumber;--EXEC dbo.Test_Sort_Dyna;Jag testade också de tre första fallen med OPTION RECOMPILE (gör inte så mycket mening för det dynamiska SQL-fallet, eftersom vi vet att det kommer att bli en ny plan varje gång), och alla fyra fallen med MAXDOP 1 för att eliminera parallellisminterferens. Här är resultaten:
Slutsats
För direkt prestanda vinner dynamisk SQL varje gång (men bara med en liten marginal på denna datamängd). ROW_NUMBER()-metoden, även om den var smart, var förloraren i varje test (förlåt AndriyM).
Det blir ännu roligare när du vill introducera en WHERE-klausul, strunt i personsökning. Dessa tre är som den perfekta stormen för att introducera komplexitet till vad som börjar som en enkel sökfråga. Ju fler permutationer din fråga har, desto mer sannolikt kommer du att vilja kasta läsbarheten ut genom fönstret och använda dynamisk SQL i kombination med inställningen "optimera för ad hoc-arbetsbelastningar" för att minimera effekten av engångsplaner i din plancache.