I en uppsättning av fyra handledningar undersöker vi migrera en MySQL-databasinstans till en PostgreSQL-databas med hjälp av AWS Database Migration Service (DMS). I den första handledningen, "Migrera MySQL till PostgreSQL på AWS RDS, del 1", introducerade vi DMS och skapade en IAM-användare för DMS. I den andra handledningen, Migrera MySQL till PostgreSQL på AWS RDS, del 2, skapade vi instanser av MySQL och PostgreSQL på RDS och kopplade till de två instanserna. I den här fortsättningshandledningen ska vi skapa en DMS-migrering för att utföra migreringen. Denna handledning har följande avsnitt:
- Skapa en DMS-migrering
- Skapa en replikeringsinstans
- Skapa slutpunkter för migreringsuppgifter
- Skapa en migreringsuppgift
- Slutsats
Skapa en DMS-migrering
I det här avsnittet ska vi skapa en Database Migration Service (DMS) för att migrera MySQL-databasen till PostgreSQL-databasen. En DMS-migrering består av följande komponenter:
- Replikeringsinstans
- Databasslutpunkter
- Uppgift
Vi kommer att diskutera att skapa var och en av dessa i underavsnitt, men först måste du skapa en DMS-migrering. Navigera till DMS-instrumentpanelen och klicka på Skapa migrering , som visas i figur 1.
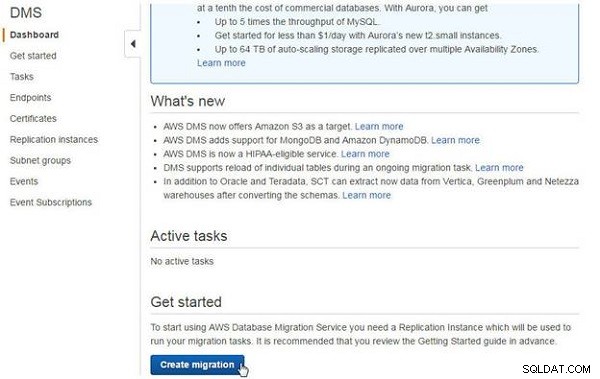
Figur 1: Skapa migrering
DMS-guiden startar. Klicka på Nästa, som visas i figur 2.
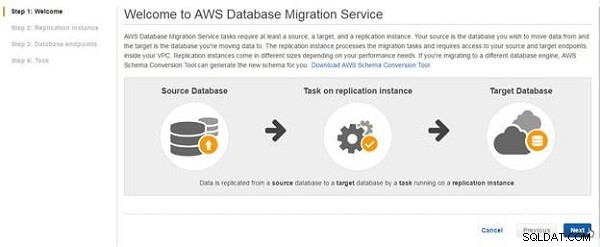
Figur 2: DMS-guiden
Skapa en replikeringsinstans
Konfigurera sedan en replikeringsinstans, som upprättar anslutningen mellan käll- och måldatabaserna, överför data och cachelagrar dataändringar som inträffar under den första dataladdningen. Ange en replikeringsinstans Namn och Beskrivning och välj en instansklass (standard är dms.t2.medium), som visas i figur 3. Välj en VPC och välj alternativet för att konfigurera hög tillgänglighet med Mult-Az; standardinställningen är inställd på "Nej". Välj alternativet Allmänt tillgängligt .
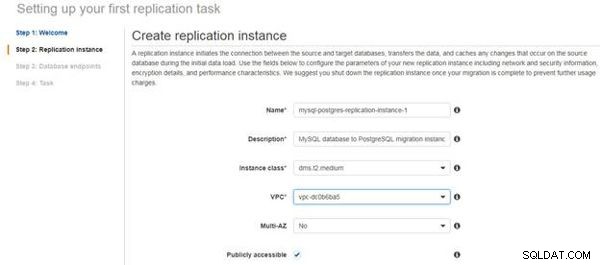
Figur 3: Konfigurera en replikeringsinstans
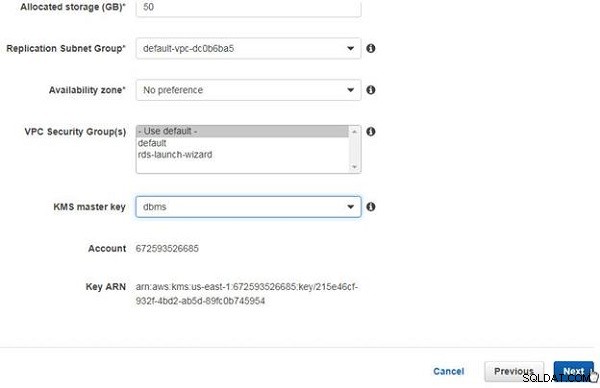
I Avancerat , behåll standardinställningarna för Tilldelat lagringsutrymme (50 GB), Replikeringsundernätsgrupp, Tillgänglighetszon (Ingen preferens) och VPC-säkerhetsgrupp (Använd standard), som visas i figur 4. Välj KMS-huvudnyckeln (dbms) som skapades tidigare i Ställa in miljön avsnitt.
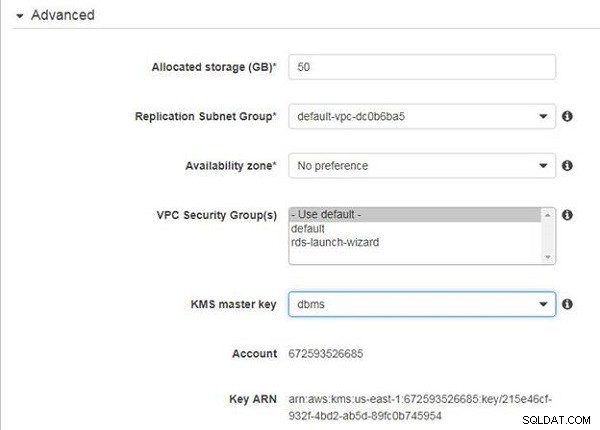
Figur 4: Konfigurera avancerade inställningar för replikeringsinstans
Klicka på Nästa, som visas i figur 5.
Figur 5: Nästa
Replikeringsinstansen börjar skapas, vilket visas av meddelandet i figur 6. Därefter måste käll- och måldatabasanslutningarna konfigureras, vilket vi ska utföra i nästa underavsnitt.
Figur 6: Replikeringsinstansen börjar skapas
Skapa slutpunkter för migreringsuppgifter
Replikeringsinstansen kan ta några minuter att skapas. Migreringsslutpunkterna kan läggas till medan replikeringsinstansen skapas. Välj Källmotorn som "mysql", som visas i figur 7.
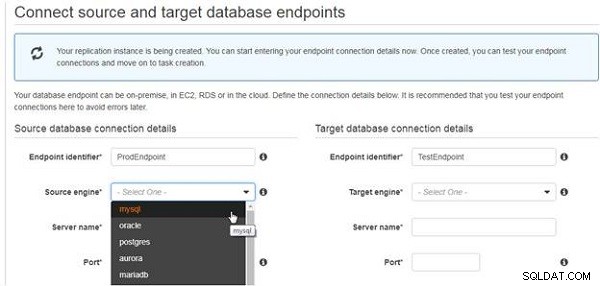
Figur 7: Väljer källmotor
Välj Målmotor som "postgres", som visas i figur 8.
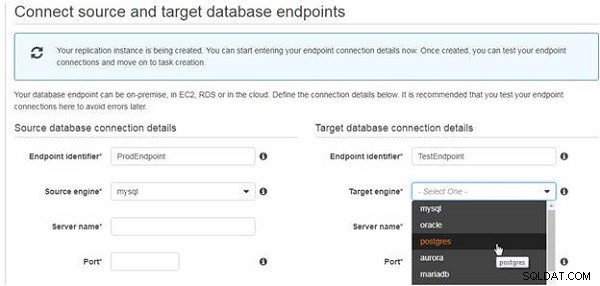
Figur 8: Välj målmotor
I Servernamn , ange Slutpunkt för RDS DB-instansen för databasen genom att ta bort :port ändelse. För en MySQL-databas är RDS Endpoint mysqldb.crbmlbxmp8qi.us-east-1.rds.amazonaws.com:3306 . Ange därför Servernamn som mysqldb.crbmlbxmp8qi.us-east-1.rds.amazonaws.com , som visas i figur 9. För en PostgreSQL-databas på RDS är slutpunkten postgresdb.crbmlbxmp8qi.us-east-1.rds.amazonaws.com:5432; ange därför Servernamn som postgresdb.crbmlbxmp8qi.us-east-1.rds.amazonaws.com . Ange porten separat för käll- och måldatabaserna:3306 för MySQL-databasen och 5432 för Postgres.
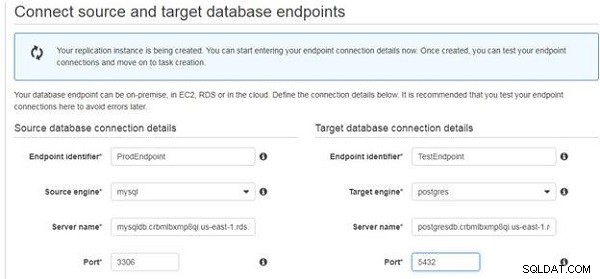
Figur 9: Ange servernamn och port för käll- och måldatabaser
Rulla ned för fler inställningar för slutpunktskonfiguration, som visas i figur 10. Välj SSL-läge som ingen för både käll- och måldatabaserna. Ange användarnamn och lösenord som konfigurerats när du skapar RDS DB-instanserna. Ange PostgreSQL-databasnamnet (postgresdb), även det som konfigurerats när du skapar RDS DB-instansen.
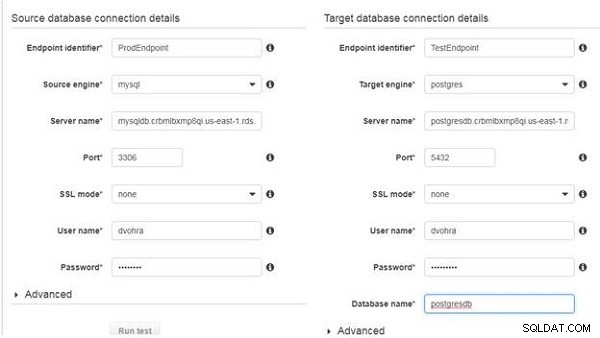
Figur 10: Ange SSL-läge, användarnamn, lösenord och SID eller databasnamn
I Avancerade inställningar kan extra anslutningsattribut som är tillgängliga för MySQL Database och PostgreSQL-databasen anges, men inga krävs för denna handledning. Välj KMS-huvudnyckeln (dbms) för både käll- och måldatabasen (se figur 11). För att testa DMS-slutpunkterna, Kör testet knappar finns, som visas i figur 11. Kör testet knappar är nedtonade eller inaktiverade tills replikeringsinstansen har skapats.
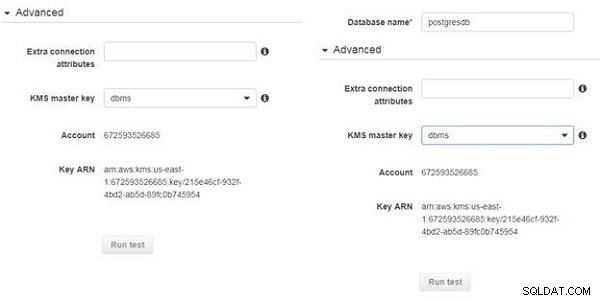
Figur 11: Konfigurera avancerade inställningar för DMS-ändpunkter
När replikeringsinstansen har skapats visas meddelandet "Replikeringsinstans skapad framgångsrikt", som visas i figur 12.

Figur 12: Replikeringsinstansen skapades framgångsrikt
Efter att replikeringsinstansen har skapats, Kör testet knapparna aktiveras. Klicka på Kör test , som visas i figur 13, för varje databas.
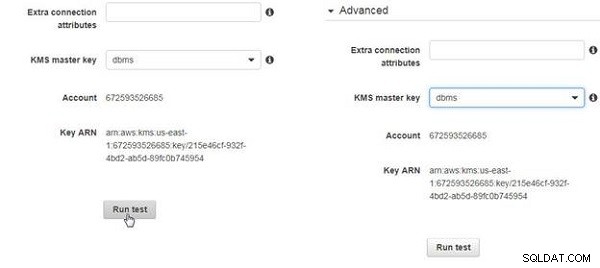
Figur 13: Kör test
Anslutningarna börjar testas, vilket indikeras av meddelandet "Testar slutpunktsanslutning" i figur 14.
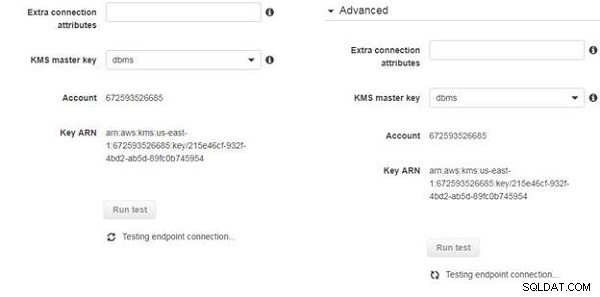
Figur 14: Testa ändpunktsanslutningar
Om slutpunktsanslutningarna har konfigurerats efter behov, bör meddelandet "Anslutning testad framgångsrikt" visas, som visas i figur 15. Klicka på Nästa.
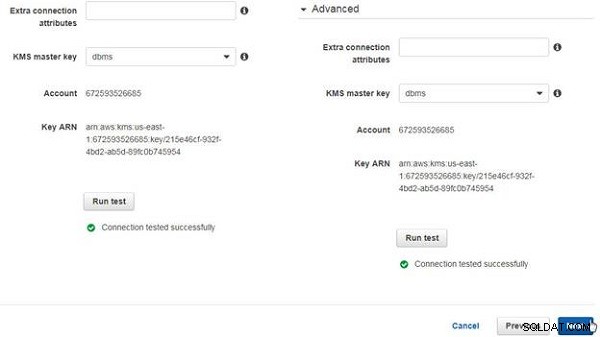
Figur 15: Anslutningen testades framgångsrikt
Skapa en migreringsuppgift
Efter att ha skapat en replikeringsinstans och databasslutpunkter ska vi skapa en migreringsuppgift för att ansluta till slutpunkterna och faktiskt överföra data. I Skapa uppgift guiden, ange ett uppgiftsnamn (en standard anges också) och lägg till en uppgiftsbeskrivning (se figur 16). Välj alternativet Starta uppgift vid skapa .
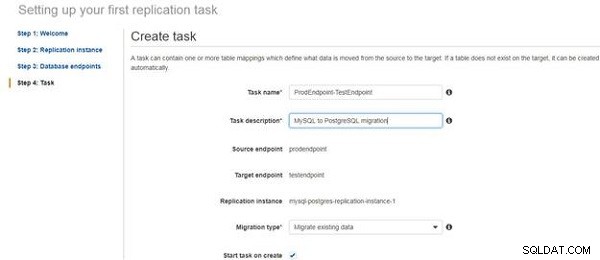
Figur 16: Skapa uppgiftsguide
Käll- och målslutpunkterna och replikeringsinstansen konfigurerades tidigare och kan inte ändras när en uppgift skapas. Välj en migreringstyp , som listar tre alternativ, som visas i figur 17.
- Migrera befintlig data :Migrerar befintliga scheman, tabeller och tabelldata som redan finns i källdatabasen, men migrerar inte efterföljande ändringar fortlöpande.
- Migrera befintlig data och replikera pågående ändringar :Migrerar befintliga scheman, tabeller och tabelldata som redan finns i källdatabasen och migrerar även efterföljande ändringar på löpande basis.
- Replicera endast dataändringar :Migrerar inte befintliga scheman, tabeller och data och migrerar endast dataändringarna.
Välj Migrera befintlig data alternativ, som visas i figur 17. För att migrera ändringar, vilket är vad de andra två alternativen tillhandahåller, måste den binära logglagringstiden på MySQL DB-instansen ökas till 24 timmar eller mer.
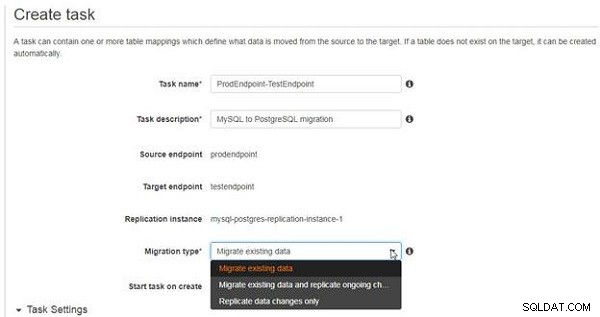
Figur 17: Välja Migreringstyp som Migrera befintliga data
Konfigurera sedan Uppgiftsinställningar . Läget för förberedelse av måltabell inställningen gäller tabellerna i måldatabasen och ger tre alternativ:
- Gör ingenting :Data och metadata för måltabellerna ändras inte
- Släpp tabeller på målet :De befintliga tabellerna, om några, tas bort och nya tabeller skapas
- Trunkera :Tabeller trunkeras, vilket innebär att tabelldata raderas men tabellens metadata inte ändras. Inkludera LOB-kolumner i replikering inställningen gäller för LOB-datatypkolumnerna i källdatabasen och ger tre alternativ:
- Inkludera inte LOB-kolumner :LOB-kolumner exkluderas från migreringen
- Fullständigt LOB-läge :Migrerar kompletta LOB oavsett storlek; LOB:er migreras i bitar, vilket kan sakta ner migreringsprocessen
- Begränsat LOB-läge :Trunkera LOB till den storlek som anges i max LOB-storlek (kb)
Välj läge för förberedelse av måltabell som Gör ingenting, som visas i figur 18. Välj Inkludera LOB-kolumner i replikering som Begränsat LOB-läge och ange Max LOB-storlek som 32 kb (standard). Välj Aktivera loggning alternativ.
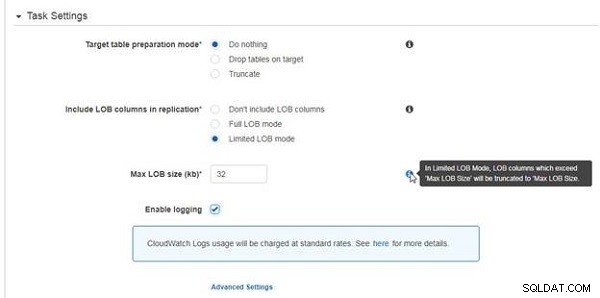
Figur 18: Uppgiftsinställningar
Lägg sedan till urvalsregler och omvandlingsregler i Tabellmappningar , som visas i figur 19. Tabellmappningar kan läggas till med hjälp av Guided användargränssnitt eller som JSON . Det guidade användargränssnittet rekommenderas. Minst en urvalsregel måste läggas till och omvandlingsregler är valfria. Urvalsregler tillämpas, medan val av scheman, tabeller och kolumner från källdatabasen och omvandlingsregler tillämpas innan scheman, tabeller och kolumner migreras till måldatabasen.
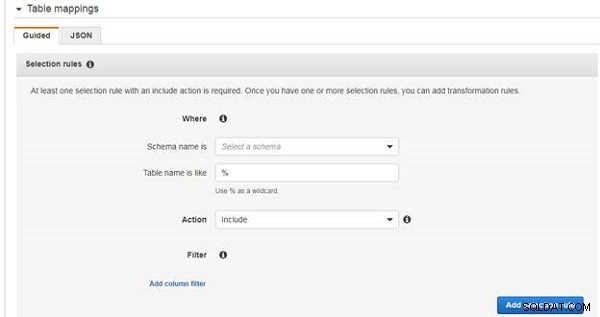
Figur 19: Tabellmappningar
Schemat kan väljas från Schemanamnet är rullgardinsmenyn eller, om ingen finns i listan, välj Ange ett schema och ange ett schema i Schemanamnet är som fält. Åtgärden rullgardinsmenyn visar två alternativ:Inkludera och Uteslut . Alternativet Inkludera inkluderar de val som gjorts för scheman och tabeller och alternativet Exkludera exkluderar scheman och tabeller. Exkluderingarna behandlas efter Inkluderar. Alla scheman måste inte väljas och inte alla tabeller från ett schema måste väljas.
Vi ska lägga till följande urvalsregel:
- Inkludera alla scheman och alla tabeller från källdatabasen
För urvalsregeln väljer du Ange ett schema och ange Schemanamn är som % , som väljer alla scheman i källdatabasen, som visas i figur 20. Ange Tabellnamnet är som som % , som väljer alla tabeller i de valda scheman. Välj Åtgärd som Inkludera .
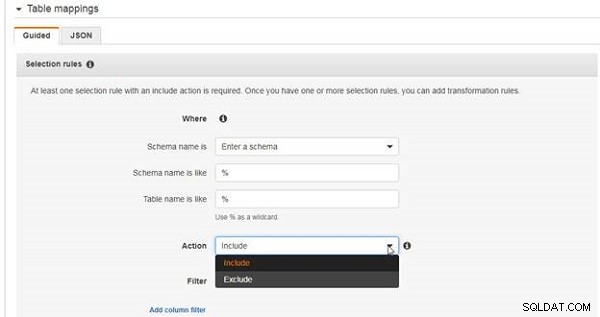
Figur 20: Konfigurera en urvalsregel
Klicka på Lägg till urvalsregel (se figur 21).
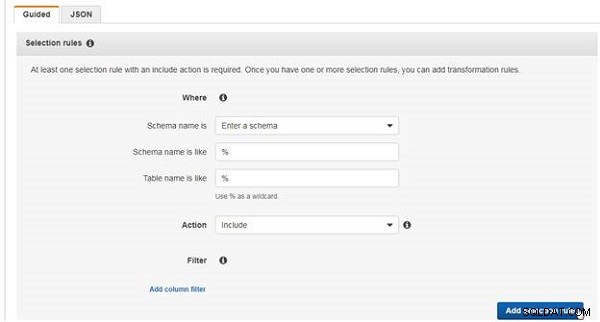
Figur 21: Lägga till en urvalsregel
En urvalsregel läggs till, som visas i figur 22. När uppgiften skapas, visas en IAM-roll dms-cloudwatch-logs-role skapas för att ge DMS åtkomst till CloudWatch.
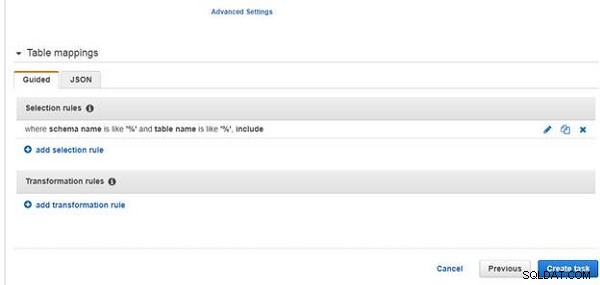
Figur 22: Urvalsregel har lagts till
Lägg sedan till en transformationsregel. För detta klickar du på lägg till omvandlingsregel länk, som visas i figur 23.
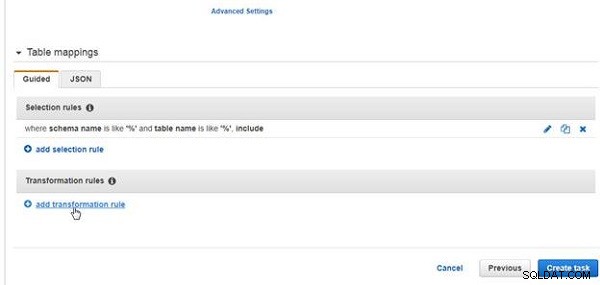
Figur 23: Lägg till omvandlingsregel
En omvandlingsregel har inställningar för målet . Regeln har tre alternativ, som visas i figur 24.
- Schema
- Tabell
- Kolumn
Var anger en delmängd av objekten som valts av urvalsreglerna. Åtgärden är transformationen som ska tillämpas och följande alternativ är tillgängliga:
- Byt namn på (tillgängligt för schema- och tabellobjekt)
- Ta bort kolumn (tillgänglig för kolumner)
- Gör gemener (tillgängligt för scheman, tabeller och kolumner)
- Gör versaler (tillgängligt för scheman, tabeller och kolumner)
- Lägg till prefix (tillgängligt för scheman, tabeller och kolumner)
- Ta bort prefix (tillgängligt för scheman, tabeller och kolumner)
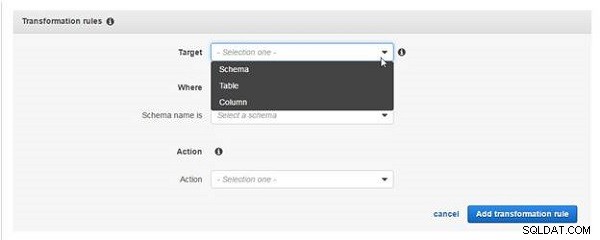
Figur 24: Inställningar för transformationsregler
PostgreSQL använder gemener i scheman, tabeller och kolumner. Vi ska lägga till tre omvandlingsregler:
- Gör alla scheman med små bokstäver
- Gör alla tabeller med små bokstäver
- Gör alla kolumner gemener
Om du vill lägga till den första av dessa omvandlingsregler väljer du Mål som Schema som visas i figur 25. Ange Schemanamnet är som % . Välj Åtgärd som Gör gemener och klicka på Lägg till omvandlingsregel .
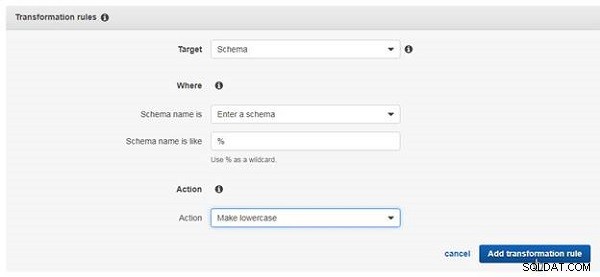
Figur 25: Lägga till en transformationsregel
En transformationsregel läggs till (se figur 26). Om du vill lägga till ytterligare en omvandlingsregel klickar du på lägg till omvandlingsregel länk igen.
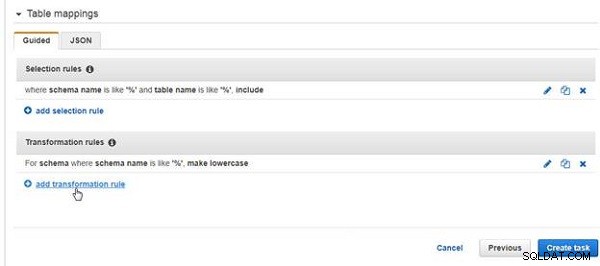
Figur 26: Transformationsregel har lagts till
Välj Mål som tabell , som visas i figur 27. Ange Schemanamnet är som % . Välj Tabellnamnet är som % . Välj Åtgärd som Gör gemener och klicka på Lägg till omvandlingsregel .
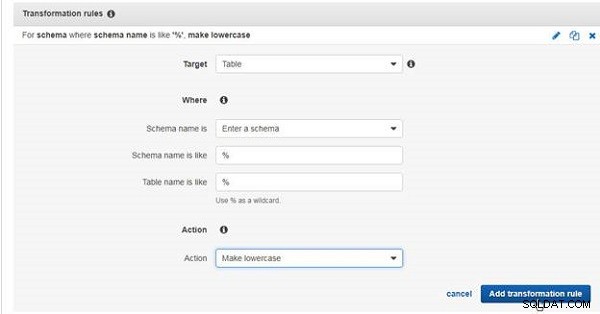
Figur 27: Lägga till en transformationsregel för att byta namn på en tabell
Välj Mål som kolumn , som visas i figur 28. Ange Schemanamnet är som % . Välj Tabellnamnet är som % . Välj Kolumnnamnet är som % . Välj Åtgärd som Gör gemener och klicka på Lägg till omvandlingsregel .
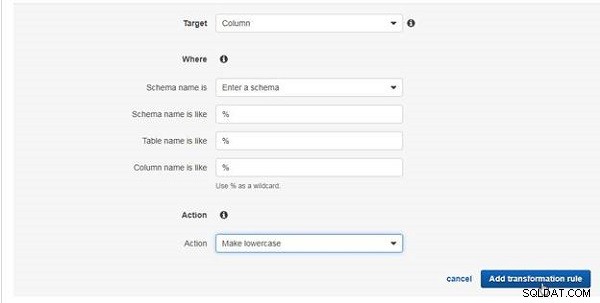
Figur 28: Lägger till en omvandlingsregel för att göra kolumnnamn med små bokstäver
De tre urvalsreglerna och en tillagd transformationsregel visas i figur 29. När uppgiften körs tillämpas urvalsreglerna före transformationsreglerna. För avancerade inställningar klickar du på Avancerade inställningar , som visas i figur 29.
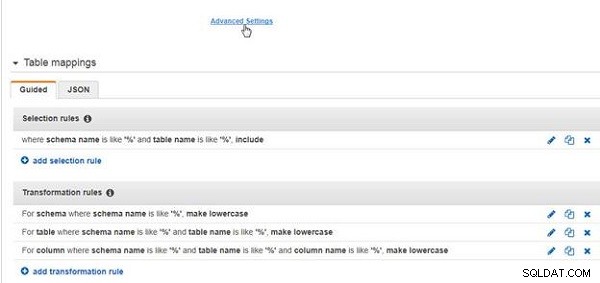
Figur 29: Urvalsregler och transformationsregler
I Avancerade inställningar , välj Kontrollera tabellinställningar och ange Skapa kontrolltabell i mål med hjälp av schema som offentliga , som visas i figur 30, och klicka på Klar.
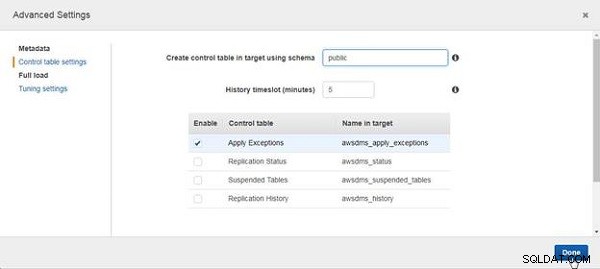
Figur 30: Ställa in kontrolltabellschema i mål
Den avancerade inställningen läggs till (se figur 31).
Figur 31: Avancerad inställning
När du har konfigurerat uppgiften klickar du på Skapa uppgift , som visas i figur 32, för att skapa uppgiften.
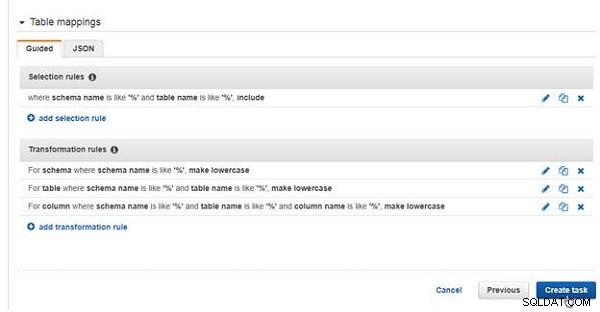
Figur 32: Skapa uppgift
En migreringsuppgift skapas, som visas i figur 33. Till en början är aktivitetens status "Skapar".
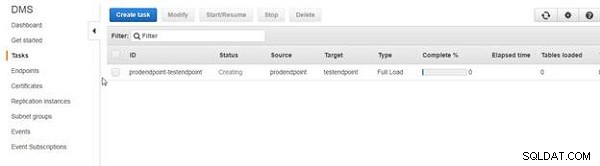
Figur 33: Migreringsuppgift
En uppgift kan ha en av de statusar som diskuteras i Tabell 1.
| Status | Beskrivning |
| Skapar | Uppgiften skapas. |
| Klart | Uppgiften är redo att startas och köras. Följer vanligtvis statusen "Skapar". |
| Startar | Uppgiften startar, under vilken tid uppgiften ansluter till replikeringsinstansen och databasens slutpunkter. Regler för urval och omvandling tillämpas. |
| Kör | Uppgiften körs, vilket innebär att uppgiften migrerar databasen. |
| Inläsningen slutförd | Uppgiften har slutfört laddningen (migreringen) av databasen. |
| Mislyckades | Uppgiften misslyckades. |
| Fel | Ett fel har inträffat under migreringen. Vissa av schemana och tabellerna kan ha migrerats framgångsrikt men minst ett schema eller en tabell har misslyckats med att migrera. |
| Ändra | Uppgiften ändras, vanligtvis efter att en användare har ändrat uppgiften. |
| Stoppar | Uppgiften stoppas, vilket vanligtvis sker efter att användaren har valt att stoppa en uppgift. |
| Stoppad | Uppgiften stoppas, vilket kan bero på att en användare har stoppat en uppgift eller på att en migreringstyp av Migrera befintliga data och replikera pågående ändringar används och uppgiften har slutfört den initiala laddningen . |
| Ta bort | Uppgiften tas bort, vilket beror på att användaren har tagit bort uppgiften. |
Tabell 1: Uppgiftsstatusar
Två IAM-roller, en för CloudWatch och den andra för VPC, skapas, som visas i figur 34.

Figur 34: IAM-roller för DMS
Slutsats
I den här tredje handledningen om att migrera en MySQL-databasinstans på RDS till en Postgres-databasinstans på RDS skapade vi en DMS-migrering inklusive replikeringsinstans, migreringsslutpunkter och migreringsuppgift. I den fjärde handledningen kommer vi att diskutera att köra DMS-migreringen för att utföra migreringen och utvärdera resultaten.