En enkel definition av medianen är:
Medianen är mittvärdet i en sorterad lista med talFör att förtydliga det lite kan vi hitta medianen för en lista med nummer med följande procedur:
- Sortera siffrorna (i stigande eller fallande ordning, det spelar ingen roll vilket).
- Mellersta numret (efter position) i den sorterade listan är medianen.
- Om det finns två "lika mellersta" tal är medianen medelvärdet av de två mittersta värdena.
Aaron Bertrand har tidigare prestandatestat flera sätt att beräkna medianen i SQL Server:
- Vad är det snabbaste sättet att beräkna medianen?
- Bästa tillvägagångssätt för grupperad median
Rob Farley lade nyligen till ett annat tillvägagångssätt som syftar till installationer före 2012:
- Medianer före SQL 2012
Den här artikeln introducerar en ny metod som använder en dynamisk markör.
2012 OFFSET-FETCH-metoden
Vi börjar med att titta på den bäst presterande implementeringen, skapad av Peter Larsson. Den använder SQL Server 2012 OFFSET tillägg till ORDER BY sats för att effektivt lokalisera en eller två mittrader som behövs för att beräkna medianen.
OFFSET Single Median
Aarons första artikel testade att beräkna en enda median över en tio miljoner radtabell:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
Peter Larssons lösning med OFFSET tillägget är:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Koden ovan hårdkodar resultatet av att räkna raderna i tabellen. Alla testade metoder för att beräkna medianen behöver denna räkning för att beräkna medianradnumren, så det är en konstant kostnad. Genom att lämna radräkningsoperationen utanför timingen undviks en möjlig källa till variation.
Utförandeplanen för OFFSET lösningen visas nedan:

Toppoperatören hoppar snabbt över de onödiga raderna och skickar bara en eller två rader som behövs för att beräkna medianen till Stream Aggregate. När den körs med en varm cache och exekveringsplansamling avstängd körs den här frågan i 910 ms i genomsnitt på min bärbara dator. Detta är en maskin med en Intel i7 740QM-processor som körs på 1,73 GHz med Turbo inaktiverad (för konsekvens).
OFFSET Grouped Median
Aarons andra artikel testade prestandan för att beräkna en median per grupp med hjälp av en försäljningstabell på en miljon rader med tiotusen poster för var och en av hundra säljare:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
Återigen, den bäst presterande lösningen använder OFFSET :
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK)
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Den viktiga delen av genomförandeplanen visas nedan:

Den översta raden i planen handlar om att hitta antalet grupprader för varje säljare. Den nedre raden använder samma planelement som för en grupps medianlösning för att beräkna medianen för varje säljare. När den körs med en varm cache och exekveringsplaner avstängda, körs denna fråga på 320 ms i genomsnitt på min bärbara dator.
Använda en dynamisk markör
Det kan verka galet att ens tänka på att använda en markör för att beräkna medianen. Transact SQL-markörer har ett (oftast välförtjänt) rykte om att vara långsamma och ineffektiva. Man tror också ofta att dynamiska markörer är den sämsta typen av markör. Dessa punkter är giltiga under vissa omständigheter, men inte alltid.
Transact SQL-markörer är begränsade till att bearbeta en enda rad åt gången, så de kan verkligen vara långsamma om många rader behöver hämtas och bearbetas. Så är dock inte fallet för medianberäkningen:allt vi behöver göra är att hitta och hämta de ena eller två mellanvärdena effektivt . En dynamisk markör är mycket lämplig för denna uppgift som vi ska se.
Dynamisk markör med en median
Den dynamiska markörlösningen för en enskild medianberäkning består av följande steg:
- Skapa en dynamisk rullningsbar markör över den ordnade listan med objekt.
- Beräkna positionen för den första medianraden.
- Placera om markören med
FETCH RELATIVE. - Bestämma om en andra rad behövs för att beräkna medianen.
- Om inte, returnera det enda medianvärdet omedelbart.
- Annars hämtar du det andra värdet med
FETCH NEXT. - Beräkna medelvärdet av de två värdena och avkastning.
Lägg märke till hur nära den listan återspeglar det enkla förfarandet för att hitta medianen som anges i början av den här artikeln. En komplett Transact SQL-kodimplementering visas nedan:
-- Dynamic cursor
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE
@RowCount bigint, -- Total row count
@Row bigint, -- Median row number
@Amount1 integer, -- First amount
@Amount2 integer, -- Second amount
@Median float; -- Calculated median
SET @RowCount = 10000000;
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
DECLARE Median CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
O.val
FROM dbo.obj AS O
ORDER BY
O.val;
OPEN Median;
-- Calculate the position of the first median row
SET @Row = (@RowCount + 1) / 2;
-- Move to the row
FETCH RELATIVE @Row
FROM Median
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value we have
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Median
INTO @Amount2;
-- Calculate the median value from the two values
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
SELECT Median = @Median;
SELECT DynamicCur = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Exekveringsplanen för FETCH RELATIVE uttalande visar att den dynamiska markören effektivt flyttar om till den första raden som krävs för medianberäkningen:
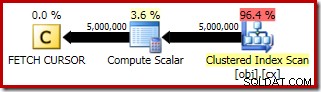
Planen för FETCH NEXT (endast krävs om det finns en andra mittrad, som i dessa tester) är en enkel radhämtning från markörens sparade position:
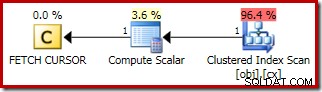
Fördelarna med att använda en dynamisk markör här är:
- Den undviker att korsa hela uppsättningen (läsningen slutar efter att medianraderna har hittats); och
- Ingen tillfällig kopia av data görs i tempdb , som det skulle vara för en statisk eller tangentuppsättningsmarkör.
Observera att vi inte kan ange en FAST_FORWARD markören här (överlåter valet av en statisk-liknande eller dynamisk-liknande plan till optimeraren) eftersom markören måste vara rullbar för att stödja FETCH RELATIVE . Dynamisk är det optimala valet här ändå.
När den körs med en varm cache och exekveringsplansamling avstängd körs denna fråga i 930 ms i genomsnitt på min testmaskin. Detta är lite långsammare än 910 ms för OFFSET lösning, men den dynamiska markören är betydligt snabbare än de andra metoderna som Aaron och Rob testade, och den kräver inte SQL Server 2012 (eller senare).
Jag kommer inte att upprepa testa de andra metoderna före 2012 här, men som ett exempel på storleken på prestandagapet tar följande radnumreringslösning 1550 ms i genomsnitt (70 % långsammare):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK)
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT RowNumber = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());

Grupperad median för dynamisk markörtest
Det är enkelt att utöka den dynamiska markörlösningen med en median till att beräkna grupperade medianer. För konsekvensens skull kommer jag att använda kapslade markörer (ja, verkligen):
- Öppna en statisk markör över säljarna och antal rader.
- Beräkna medianen för varje person med en ny dynamisk markör varje gång.
- Spara varje resultat till en tabellvariabel allt eftersom.
Koden visas nedan:
-- Timing
DECLARE @s datetime2 = SYSUTCDATETIME();
-- Holds results
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
-- Variables
DECLARE
@SalesPerson integer, -- Current sales person
@RowCount bigint, -- Current row count
@Row bigint, -- Median row number
@Amount1 float, -- First amount
@Amount2 float, -- Second amount
@Median float; -- Calculated median
-- Row counts per sales person
DECLARE SalesPersonCounts
CURSOR
LOCAL
FORWARD_ONLY
STATIC
READ_ONLY
FOR
SELECT
SalesPerson,
COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
ORDER BY SalesPerson;
OPEN SalesPersonCounts;
-- First person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
WHILE @@FETCH_STATUS = 0
BEGIN
-- Records for the current person
-- Note dynamic cursor
DECLARE Person CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
S.Amount
FROM dbo.Sales AS S
WHERE
S.SalesPerson = @SalesPerson
ORDER BY
S.Amount;
OPEN Person;
-- Calculate median row 1
SET @Row = (@RowCount + 1) / 2;
-- Move to median row 1
FETCH RELATIVE @Row
FROM Person
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Person
INTO @Amount2;
-- Calculate the median value
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
-- Add the result row
INSERT @Result (SalesPerson, Median)
VALUES (@SalesPerson, @Median);
-- Finished with the person cursor
CLOSE Person;
DEALLOCATE Person;
-- Next person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
END;
---- Results
--SELECT
-- R.SalesPerson,
-- R.Median
--FROM @Result AS R;
-- Tidy up
CLOSE SalesPersonCounts;
DEALLOCATE SalesPersonCounts;
-- Show elapsed time
SELECT NestedCur = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Den yttre markören är medvetet statisk eftersom alla rader i den uppsättningen kommer att beröras (en dynamisk markör är inte tillgänglig på grund av grupperingsoperationen i den underliggande frågan). Det finns inget särskilt nytt eller intressant att se i utförandeplanerna den här gången.
Det intressanta är prestandan. Trots den upprepade skapandet och deallokeringen av den inre dynamiska markören, presterar denna lösning riktigt bra på testdatauppsättningen. Med en varm cache och exekveringsplaner avstängda slutförs markörskriptet på 330 ms i genomsnitt på min testmaskin. Detta är återigen lite långsammare än 320 ms registreras med OFFSET grupperad median, men den slår de andra standardlösningarna som listas i Aarons och Robs artiklar med stor marginal.
Återigen, som ett exempel på prestandagapet till andra metoder som inte kommer från 2012, körs följande radnumreringslösning i 485 ms i genomsnitt på min testrigg (50 % sämre):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median numeric(38, 6) NOT NULL
);
INSERT @Result
SELECT
S.SalesPerson,
CA.Median
FROM
(
SELECT
SalesPerson,
NumRows = COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
) AS S
CROSS APPLY
(
SELECT AVG(1.0 * SQ1.Amount) FROM
(
SELECT
S2.Amount,
rn = ROW_NUMBER() OVER (
ORDER BY S2.Amount)
FROM dbo.Sales AS S2 WITH (PAGLOCK)
WHERE
S2.SalesPerson = S.SalesPerson
) AS SQ1
WHERE
SQ1.rn BETWEEN (S.NumRows + 1)/2 AND (S.NumRows + 2)/2
) AS CA (Median);
SELECT RowNumber = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());

Resultatsammanfattning
I det enkla mediantestet körde den dynamiska markören i 930 ms mot 910 ms för OFFSET metod.
I det grupperade mediantestet körde den kapslade markören i 330 ms mot 320 ms för OFFSET .
I båda fallen var markörmetoden betydligt snabbare än den andra icke-OFFSET metoder. Om du behöver beräkna en enskild eller grupperad median på en före-2012 instans, kan en dynamisk markör eller kapslad markör verkligen vara det optimala valet.
Kall cacheprestanda
Vissa av er kanske undrar över prestanda för kall cache. Kör följande före varje test:
CHECKPOINT; DBCC DROPCLEANBUFFERS;
Det här är resultaten för det enda mediantestet:
OFFSET metod:940 ms
Dynamisk markör:955 ms
För den grupperade medianen:
OFFSET metod:380 ms
Kapslade markörer:385 ms
Sluta tankar
De dynamiska markörlösningarna är verkligen betydligt snabbare än icke-OFFSET metoder för både enstaka och grupperade medianer, åtminstone med dessa exempeldatauppsättningar. Jag valde medvetet att återanvända Aarons testdata så att datamängderna inte var avsiktligt sneda mot den dynamiska markören. Det kanske vara andra datadistributioner där den dynamiska markören inte är ett bra alternativ. Ändå visar det att det fortfarande finns tillfällen då en markör kan vara en snabb och effektiv lösning på rätt sorts problem. Även dynamiska och kapslade markörer.
Örnögda läsare kan ha lagt märke till PAGLOCK ledtråd i OFFSET grupperat mediantest. Detta krävs för bästa prestanda, av skäl som jag kommer att ta upp i min nästa artikel. Utan det förlorar 2012-lösningen faktiskt till den kapslade markören med en anständig marginal (590ms mot 330 ms ).