Hög tillgänglighet är ett krav för många system, oavsett vilken teknik du använder. Detta är särskilt viktigt för databaser, eftersom de lagrar data som applikationer förlitar sig på. Beroende på kraven finns det olika sätt att distribuera en High Availability-miljö för PostgreSQL, men det är alltid nödvändigt att använda ett kompletterande verktyg eftersom de inbyggda PostgreSQL-funktionerna inte räcker till.
I den här bloggen kommer vi att se hur man distribuerar Percona Distribution för PostgreSQL för hög tillgänglighet, och vilken typ av verktyg som krävs för att göra det.
Percona-distribution för PostgreSQL
Det är en samling verktyg som hjälper dig att hantera ditt PostgreSQL-databassystem. Den installerar PostgreSQL och kompletterar den med ett urval av tillägg som gör det möjligt att lösa viktiga praktiska uppgifter effektivt, inklusive:
- pg_repack :Den bygger om PostgreSQL-databasobjekt.
- pgaudit :Den tillhandahåller detaljerad sessions- eller objektgranskningsloggning via standardpostgreSQL-loggningsfunktionen.
- pgBackRest :Det är en säkerhetskopierings- och återställningslösning för PostgreSQL.
- Patroni :Det är en lösning med hög tillgänglighet för PostgreSQL.
- pg_stat_monitor :Den samlar in och aggregerar statistik för PostgreSQL och tillhandahåller histograminformation.
- En samling ytterligare PostgreSQL-bidragstillägg.
Hög tillgänglighet på PostgreSQL
Det finns olika arkitekturer för PostgreSQL hög tillgänglighet, men det vanligaste är att ha en Master-Slave-topologi (Primär-Standby). Den är baserad på en primär databas med en eller flera standbynoder. Dessa standby-databaser förblir synkroniserade (eller nästan synkroniserade) med den primära, beroende på om replikeringen är synkron eller asynkron. Om huvudservern misslyckas innehåller standby-läget nästan all data från huvudservern och kan snabbt omvandlas till den nya primära databasservern.
Men en master-slave-installation räcker inte för att effektivt säkerställa hög tillgänglighet, eftersom du också måste hantera fel. När ett fel upptäcks bör du kunna välja en standby-nod och failover till den med så kortare fördröjning som möjligt. PostgreSQL i sig inkluderar inte en automatisk failover-mekanism, så det kommer att kräva några anpassade skript eller tredjepartsverktyg för denna automatisering.
Efter en failover måste applikationen(erna) meddelas i enlighet med detta, så att de kan börja använda den nya primära noden. Du måste också utvärdera tillståndet för vår arkitektur efter en failover, eftersom du kan köra i en situation där du bara har den nya primära igång (dvs. du hade en primär och bara en standby-nod före problemet). I så fall måste du lägga till en ny standby-nod på något sätt för att återskapa master-slave-inställningen du ursprungligen hade för High Availability.
För att få det att fungera måste du ha olika verktyg/tjänster som hjälper dig med den här uppgiften.
Load Balancers
Lastbalanserare är verktyg som kan användas för att hantera trafiken från din applikation för att få ut det mesta av din databasarkitektur.
Det är inte bara användbart för att balansera belastningen på våra databaser, det hjälper också applikationer att omdirigeras till tillgängliga/friska noder och till och med ange portar med olika roller.
HAProxy är en lastbalanserare som distribuerar trafik från ett ursprung till en eller flera destinationer och kan definiera specifika regler och/eller protokoll för denna uppgift. Om någon av destinationerna slutar svara markeras den som offline och trafiken skickas till resten av de tillgängliga destinationerna.
Keelived är en tjänst som låter dig konfigurera en virtuell IP inom en aktiv/passiv grupp av servrar. Denna virtuella IP tilldelas en aktiv server. Om denna server misslyckas migreras IP:n automatiskt till den "Sekundära" passiva servern, vilket gör att den kan fortsätta arbeta med samma IP på ett transparent sätt för systemen.
För att implementera alla dessa saker kan du göra det manuellt, vilket kommer att innebära extra arbete och tidskrävande uppgifter, eller så kan du göra det från bara ett system med ClusterControl.
Låt oss se hur du importerar din befintliga Percona-distribution för PostgreSQL till ClusterControl, och sedan hur du konfigurerar en hög tillgänglighetsmiljö med HAProxy och Keepalved runt den här installationen från ett vänligt och lättanvänt gränssnitt.
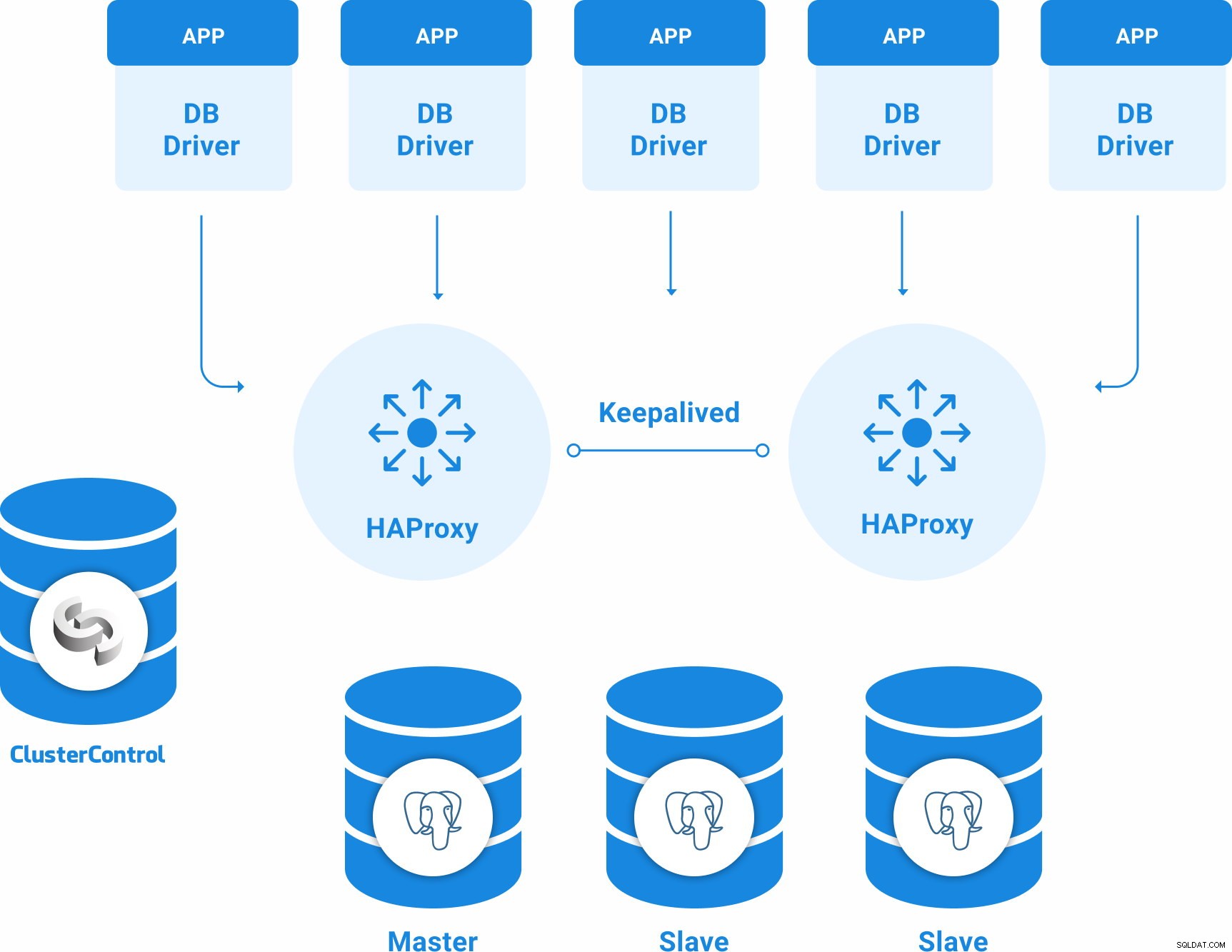
PostgreSQL-topologi för hög tillgänglighet
En grundläggande högtillgänglighetstopologi för PostgreSQL kan vara:
- 3 PostgreSQL 12-servrar (en primär och två standbynoder).
- 2 HAProxy Load Balancers.
- Behålls konfigurerad mellan belastningsutjämningsservrarna.
- 1 ClusterControl-server
Du kommer alltså att ha följande topologi:
Hur man installerar Percona Distribution för PostgreSQL
Låt oss börja med att installera Percona Distribution för PostgreSQL. För det här exemplet kommer vi att använda CentOS 7 och PostgreSQL 12.
Om du har ditt kluster installerat går du till nästa avsnitt för att importera din befintliga databas till ClusterControl.
Installera epel-release och percona-release
$ yum install epel-release
$ yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpmAktivera PostgreSQL 12-förrådet
$ percona-release setup ppg-12
* Disabling all Percona Repositories
* Enabling the Percona Distribution for PostgreSQL 12 repository
<*> All done!Installera serverpaketet
$ yum install percona-postgresql12-serverObservera att det här paketet inte kommer att installera alla Percona Distribution-komponenter. För att installera dessa komponenter använd lämpliga tillvalspaket som visas nedan:
$ yum install percona-pg_repack12
$ yum install percona-pgaudit
$ yum install percona-pgbackrest
$ yum install percona-patroni
$ yum install percona-pg-stat-monitor12
$ yum install percona-postgresql12-contribInitiera databasen
$ /usr/pgsql-12/bin/postgresql-12-setup initdb
Initializing database ... OKSe till att du har rätt konfiguration för att kunna konfigurera en PostgreSQL-replikering, liknande:
$ vi /var/lib/pgsql/12/data/postgresql.conf
listen_addresses = '*'
wal_level=logical
max_wal_senders = 16
wal_keep_segments = 32
hot_standby = onStarta sedan databastjänsten
$ systemctl start postgresql-12Nu, om du vill lägga till standbynoder, upprepa steg 1, 2 och 3 i alla noder som du vill lägga till i klustret. För dessa noder behöver du inte konfigurera något annat eftersom ClusterControl kommer att skapa motsvarande konfiguration.
Importera Percona Distribution för PostgreSQL i ClusterControl
Med ClusterControl kan du distribuera eller importera olika databasmotorer med öppen källkod från samma system, och endast SSH-åtkomst och en privilegierad användare krävs för att använda det.
Gå till avsnittet "Importera" och fyll i den information som krävs för din PostgreSQL-server.
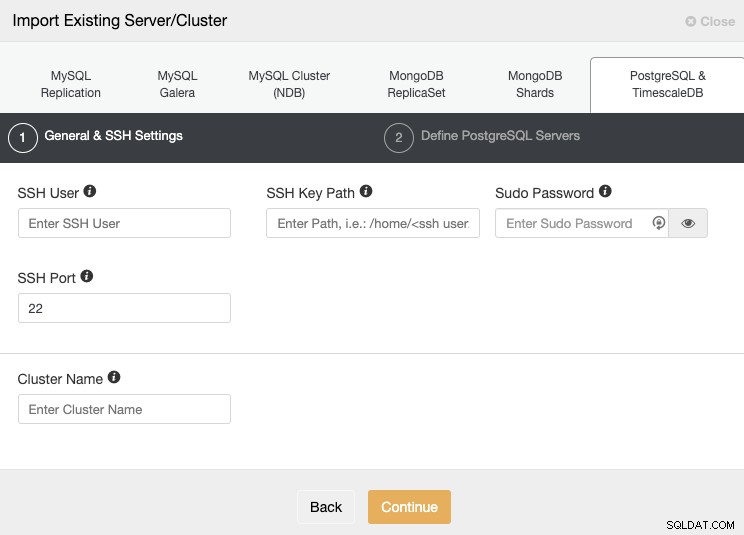
Du måste ange Användare, Nyckel eller Lösenord och port för att ansluta med SSH till dina servrar. Du behöver också ett namn för ditt nya kluster, annars kommer ClusterControl att tilldela ett generiskt namn åt dig.
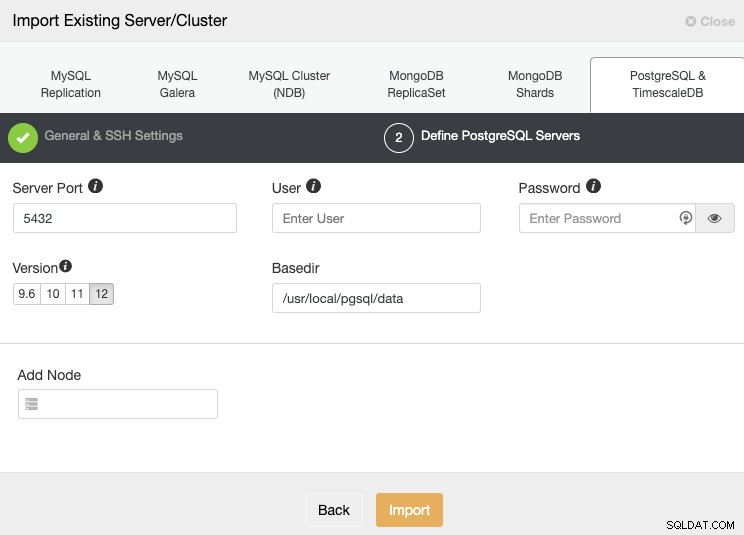
När du har ställt in SSH-åtkomstinformationen måste du definiera databasuppgifterna, version, basedir och IP-adressen eller värdnamnet för varje databasnod.
Om du inte har konfigurerat replikeringen ännu behöver du bara lägga till IP-adressen eller värdnamnet för den primära noden, eftersom vi kommer att visa dig hur du lägger till resten av noderna senare.
Se till att du får den gröna bocken när du anger värdnamnet eller IP-adressen, vilket indikerar att ClusterControl kan kommunicera med noden. Klicka sedan på knappen Importera och vänta tills ClusterControl slutför sitt jobb. Du kan övervaka processen i ClusterControl Activity Section. När det är klart kommer du att se det nya klustret på ClusterControls huvudskärm. För att lägga till en ny replik, gå till klusteråtgärderna och välj alternativet "Lägg till replikeringsslav".
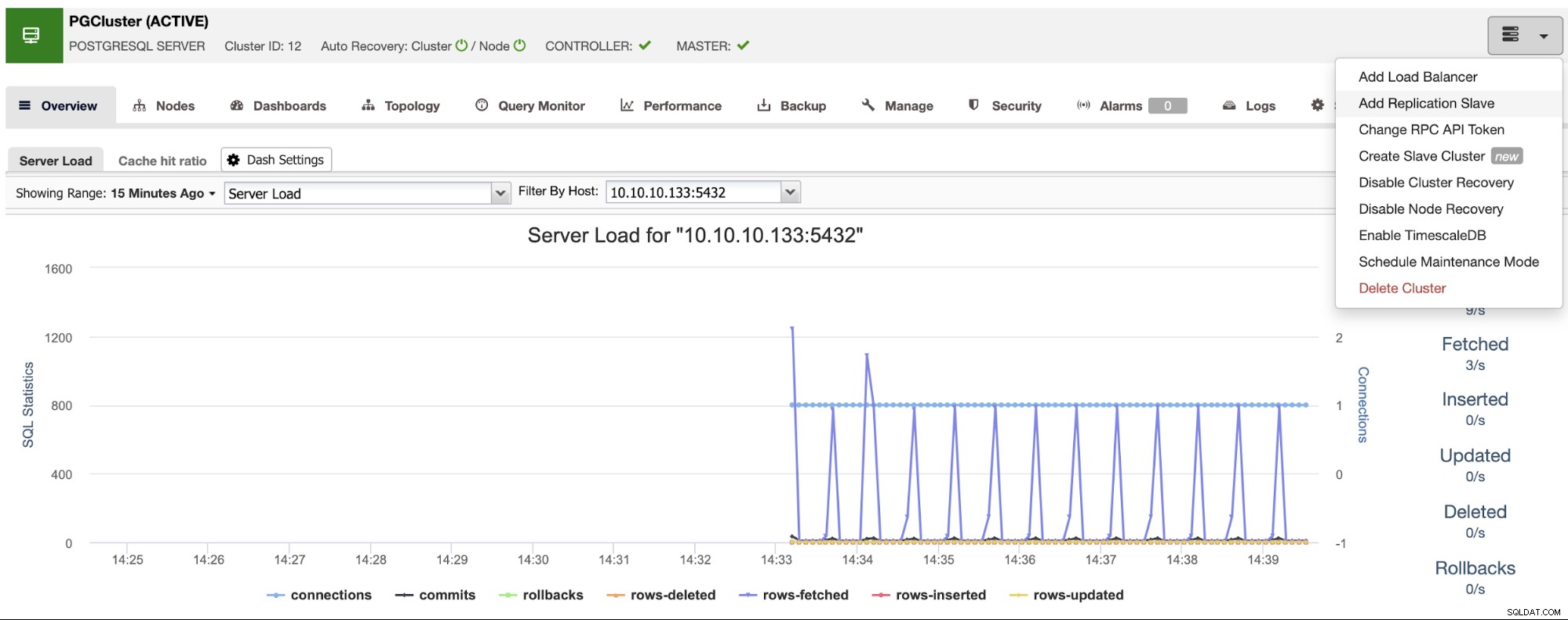
Om du följde de föregående stegen kommer du att ha Percona Distribution för PostgreSQL installerat i alla standbynoder, så du måste inaktivera "Installera PostgreSQL-programvara" i det här avsnittet.
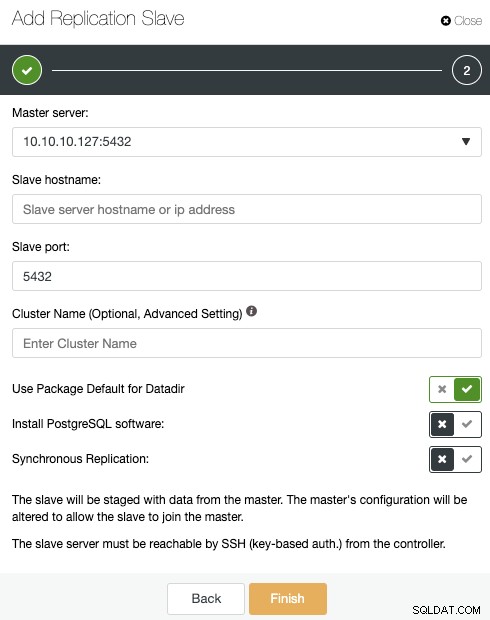
På detta sätt kommer ClusterControl att använda de installerade Percona Distribution för PostgreSQL-paket istället för att installera de officiella PostgreSQL-paketen.
När du är klar med detta kommer du att se alla noder i klustret och statusen för dem alla i översiktsavsnittet.
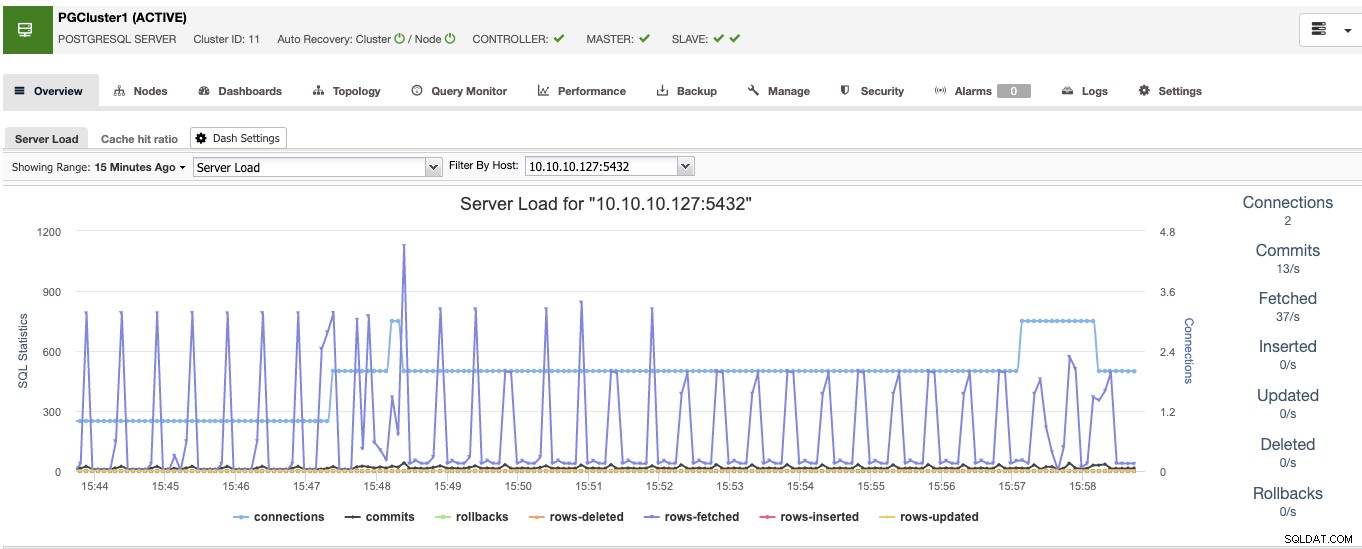
Nu har du databassidan redo, låt oss se hur du slutför High Tillgänglighetsmiljö genom att lägga till resten av verktygen med ClusterControl.
Load Balancer Deployment
För att utföra en distribution av lastbalanserare, välj alternativet "Lägg till lastbalanserare" i klusteråtgärder och fyll i den efterfrågade informationen. 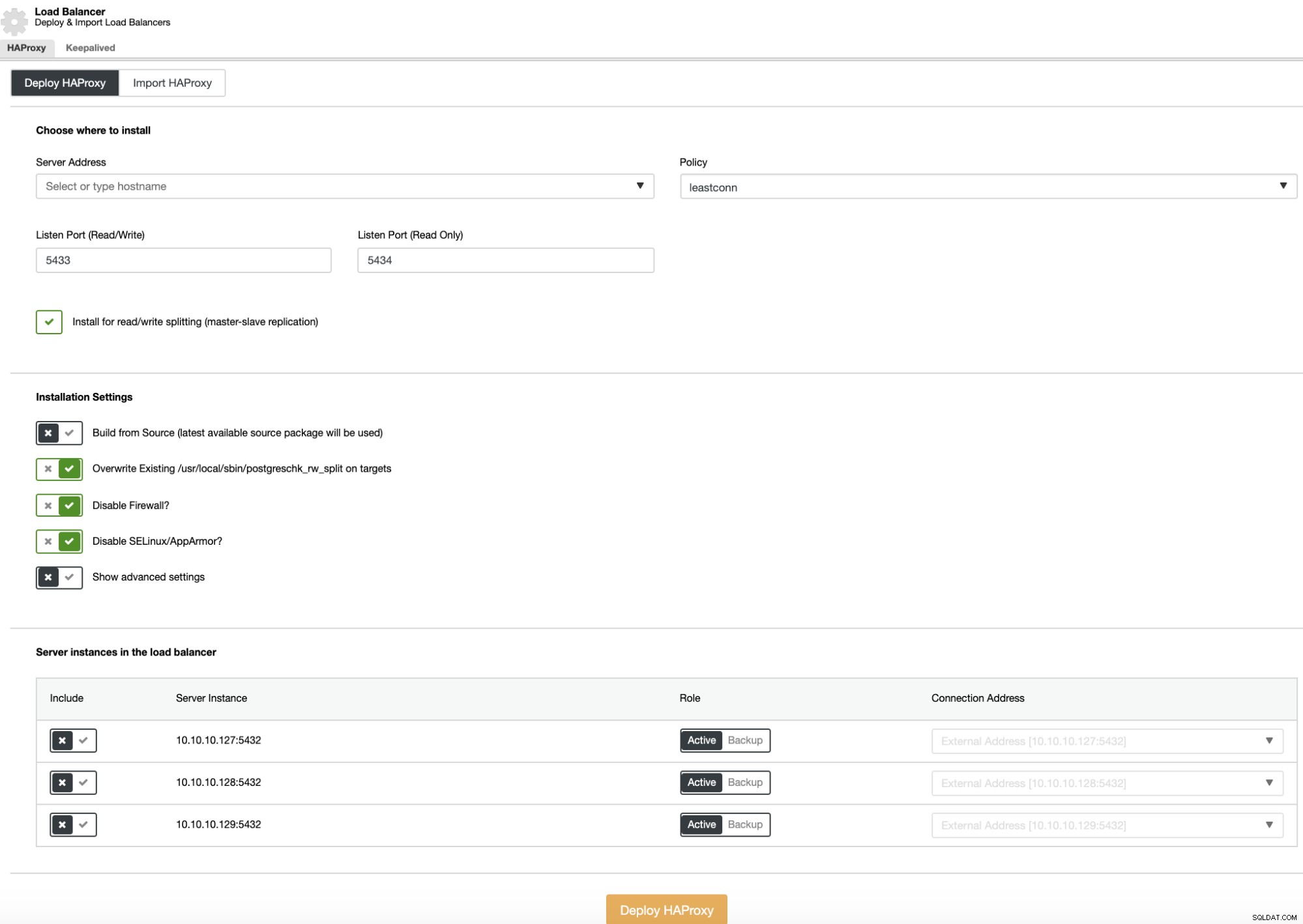
Du behöver bara lägga till IP-adress eller värdnamn, port, policy och de noder som du ska lägga till i lastbalanseringskonfigurationen.
Keelived Deployment
För att utföra en Keepalived-distribution, välj klustret, gå till klusteråtgärder, välj "Lägg till lastbalanserare" och gå sedan till avsnittet "Keelived".
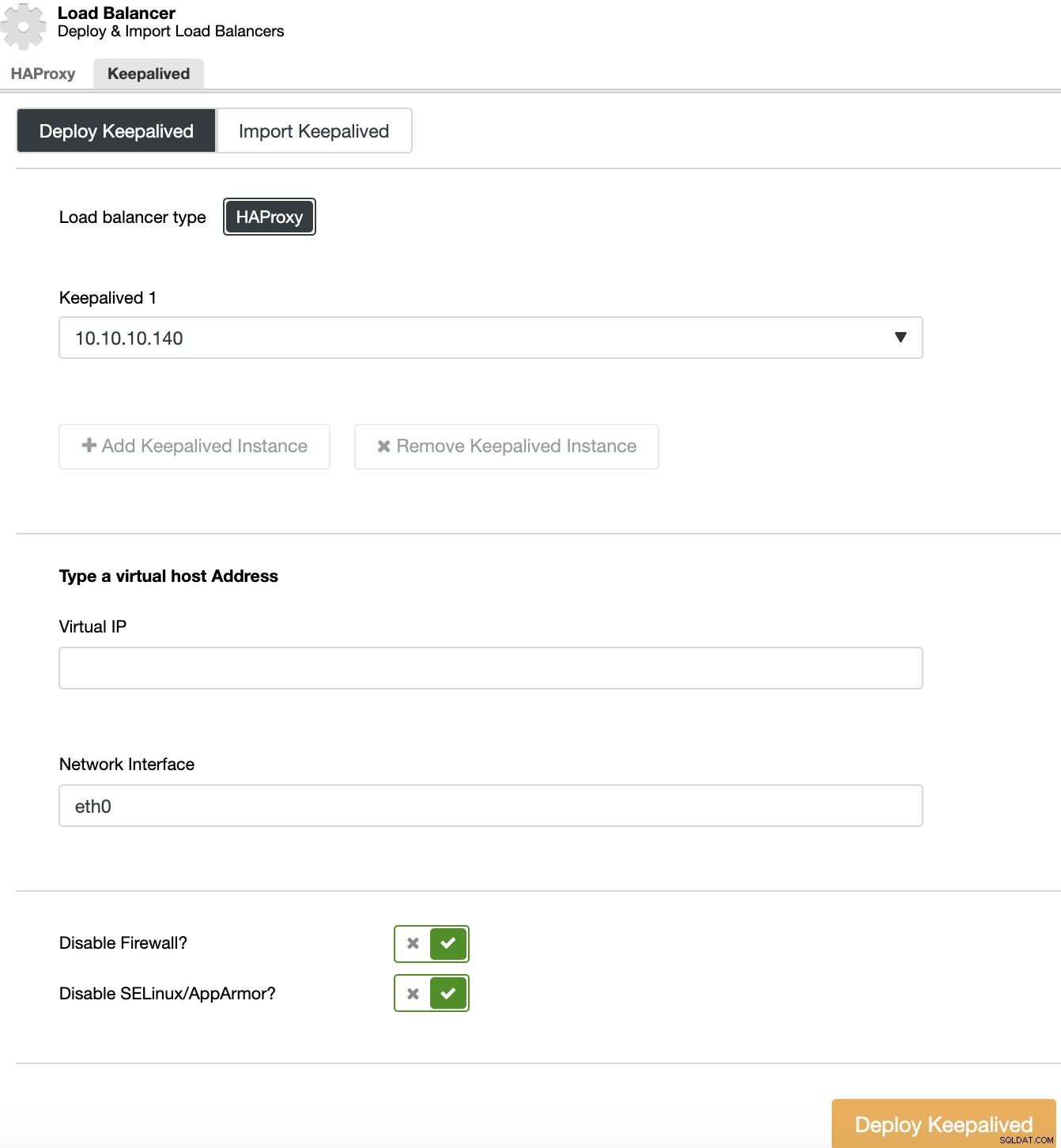
För din högtillgänglighetsmiljö måste du välja lastbalanseringsservrarna och den virtuella IP-adressen som du måste använda för att komma åt ditt kluster. Keepalved konfigurerar denna virtuella IP i den aktiva lastbalanseraren och migrerar den från en lastbalanserare till en annan i händelse av fel, så att din installation kan fortsätta att fungera normalt.
Slutsats
Eftersom du inte kan distribuera Percona Distribution för PostgreSQL direkt från ClusterControl ännu, i den här bloggen visade vi dig hur du kan hantera det med ClusterControl, och hur du lägger till olika verktyg som HAProxy och Keepalved för att ha en hög tillgänglighetsmiljö på plats på ett enkelt sätt.