Recovery Time Objective (RTO) är den tidsperiod inom vilken en tjänst måste återställas för att undvika oacceptabla konsekvenser. Genom att beräkna hur lång tid det kan ta att återställa från ett databasfel kan vi veta vilken förberedelsenivå som krävs. Om RTO är några minuter, krävs betydande investeringar i failover. En RTO på 36 timmar kräver en betydligt lägre investering. Det är här failover-automatisering kommer in.
I våra tidigare bloggar har vi diskuterat failover för MongoDB, MySQL/MariaDB/Percona, PostgreSQL eller TimeScaleDB. För att sammanfatta det, "Failover " är förmågan hos ett system att fortsätta fungera även om något fel inträffar. Det antyder att systemets funktioner antas av sekundära komponenter om de primära komponenterna misslyckas. Failover är en naturlig del av alla system med hög tillgänglighet, och i vissa fall , det måste till och med automatiseras. Manuella failovers tar alldeles för lång tid, men det finns fall där automatisering inte kommer att fungera bra - till exempel i händelse av en delad hjärna där databasreplikering är trasig och de två "halvorna" fortsätter att ta emot uppdateringar, effektivt leder till divergerande datamängder och inkonsekvens.
Vi har tidigare skrivit om de vägledande principerna bakom ClusterControls automatiska failover-procedurer. Om möjligt ger automatiserad failover effektivitet eftersom det möjliggör snabb återställning från fel. I den här bloggen kommer vi att titta på hur man uppnår automatisk failover i en master-slave (eller primär standby) replikeringskonfiguration med ClusterControl.
Teknikstackkrav
En stack kan sättas ihop från Open Source Software-komponenter, och det finns ett antal alternativ tillgängliga - vissa mer lämpliga än andra beroende på failover-egenskaper och även tillgänglig expertis för att hantera och underhålla lösningen. Hårdvara och nätverk är också viktiga aspekter.
Programvara
Det finns massor av tillgängliga alternativ i ekosystemet med öppen källkod som du kan använda för att implementera failover. För MySQL kan du dra fördel av MHA, MMM, Maxscale/MRM, mysqlfailover eller Orchestrator. Den här tidigare bloggen jämför MaxScale med MHA med Maxscale/MRM. PostgreSQL har repmgr, Patroni, PostgreSQL Automatic Failover (PAF), pglookout, pgPool-II eller stolon. Dessa olika högtillgänglighetsalternativ täcktes tidigare. MongoDB har replikuppsättningar med stöd för automatisk failover.
ClusterControl tillhandahåller automatisk failover-funktion för MySQL, MariaDB, PostgreSQL och MongoDB, som vi kommer att täcka längre ner. Värt att notera att den också har funktionalitet för att automatiskt återställa trasiga noder eller kluster.
Hårdvara
Automatisk failover utförs vanligtvis av en separat demonserver som är inställd på sin egen hårdvara - separat från databasnoderna. Den övervakar databasernas status och använder informationen för att fatta beslut om hur man ska reagera vid fel.
Varuservrar kan fungera bra, om inte servern övervakar ett stort antal instanser. Vanligtvis är systemkontroller och hälsoanalyser lätta när det gäller bearbetning. Men om du har ett stort antal noder att kontrollera, är stor CPU och minne ett måste, särskilt när kontroller måste stå i kö när den försöker pinga och samla in information från servrar. Noderna som övervakas och övervakas kan ibland stanna på grund av nätverksproblem, hög belastning, eller i värsta fall kan de vara nere på grund av ett maskinvarufel eller någon VM-värdkorruption. Så servern som kör hälso- och systemkontrollerna ska kunna motstå sådana stall, eftersom det är sannolikt att bearbetning av köer kan öka eftersom svar på var och en av de övervakade noderna kan ta tid tills det verifieras att det inte längre är tillgängligt eller en timeout har nåtts.
För molnbaserade miljöer finns det tjänster som erbjuder automatisk failover. Till exempel använder Amazon RDS DRBD för att replikera lagring till en standby-nod. Eller om du lagrar dina volymer i EBS, replikeras dessa i flera zoner.
Nätverk
Automatiserad failover-programvara förlitar sig ofta på agenter som är konfigurerade på databasnoderna. Agenten hämtar information lokalt från databasinstansen och skickar den till servern, närhelst den efterfrågas.
När det gäller nätverkskrav, se till att du har bra bandbredd och en stabil nätverksanslutning. Kontroller måste göras ofta, och missade hjärtslag på grund av ett instabilt nätverk kan leda till att failover-programvaran (felaktigt) drar slutsatsen att en nod är nere.
ClusterControl kräver ingen agent installerad på databasnoderna, eftersom den kommer att SSH in i varje databasnod med jämna mellanrum och utföra ett antal kontroller.
Automatisk failover med ClusterControl
ClusterControl erbjuder möjligheten att utföra såväl manuella som automatiserade failovers. Låt oss se hur detta kan göras.
Failover i ClusterControl kan konfigureras att vara automatisk eller inte. Om du föredrar att ta hand om failover manuellt kan du inaktivera automatisk klusteråterställning. När du gör en manuell failover kan du gå till Kluster → Topologi i ClusterControl. Se skärmdumpen nedan:
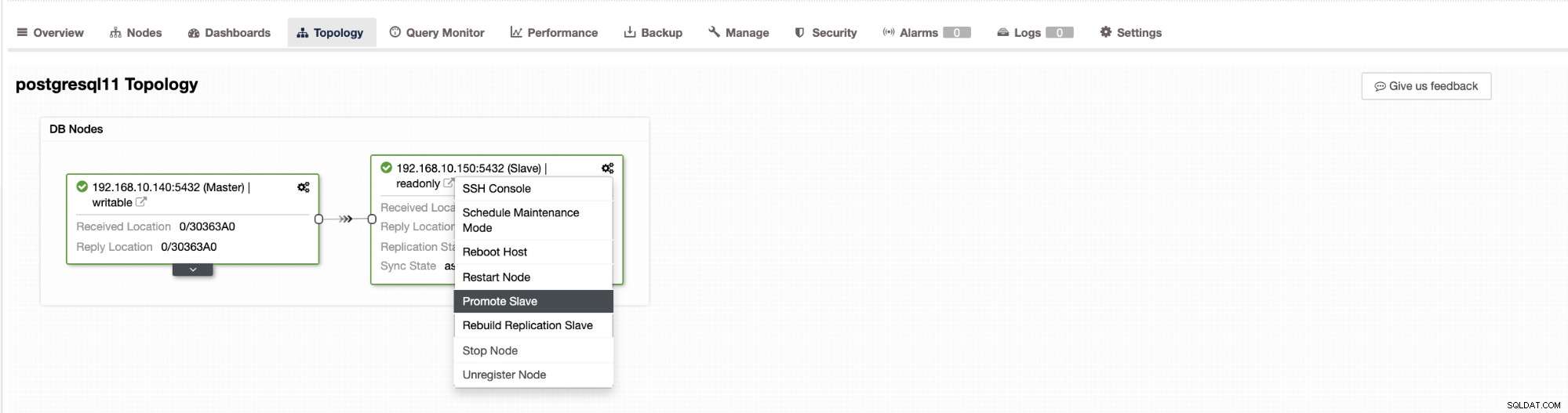
Som standard är klusteråterställning aktiverad och automatisk failover används. När du gör ändringar i användargränssnittet ändras körtidskonfigurationen. Om du vill att inställningen ska överleva en omstart av kontrollern, se till att du också gör ändringen i cmon-konfigurationen, dvs. /etc/cmon.d/cmon_

I MySQL/MariaDB/Percona-servern initieras automatisk failover av ClusterControl när den upptäcker att det inte finns någon värd med read_only flagga inaktiverad. Det kan hända eftersom master (som har read_only satt till 0) är inte tillgänglig eller så kan den utlösas av en användare eller någon extern programvara som ändrade denna flagga på mastern. Om du gör manuella ändringar av databasnoderna eller har programvara som kan krångla med skrivskyddsinställningarna, bör du inaktivera automatisk failover. ClusterControls automatiska failover görs endast en gång, därför kommer en misslyckad failover inte att följas igen av en efterföljande failover - inte förrän cmon har startat om.
För PostgreSQL kommer ClusterControl att välja den mest avancerade slaven och för detta ändamål använder pg_current_xlog_location (PostgreSQL 9+) eller pg_current_wal_lsn (PostgreSQL 10+) beroende på versionen av vår databas. ClusterControl utför också flera kontroller av failover-processen för att undvika några vanliga misstag. Ett exempel är att om vi lyckas återställa vår gamla misslyckade mästare kommer den att "inte " återinföras automatiskt till klustret, varken som en master eller som en slav. Vi måste göra det manuellt. Detta kommer att undvika möjligheten till dataförlust eller inkonsekvens i fallet att vår slav (som vi marknadsförde) blev försenad vid den tidpunkten av felet. Vi kanske också vill analysera problemet i detalj innan vi återinför det i replikeringsinställningarna, så vi skulle vilja bevara diagnostisk information.
Dessutom, om failover misslyckas, görs inga ytterligare försök (detta gäller både PostgreSQL och MySQL-baserade kluster), manuellt ingripande krävs för att analysera problemet och utföra motsvarande åtgärder. Detta för att undvika situationen där ClusterControl, som hanterar den automatiska failover, försöker främja nästa slav och nästa. Det kan finnas ett problem, och vi vill inte göra saken värre genom att försöka flera failovers.
ClusterControl erbjuder vitlistning och svartlistning av en uppsättning servrar som du vill delta i failover, eller utesluta som kandidat.
För kluster av MySQL-typ bygger ClusterControl en lista över slavar som kan befordras till master. För det mesta kommer det att innehålla alla slavar i topologin men användaren har ytterligare kontroll över det. Det finns två variabler du kan ställa in i cmon-konfigurationen:
replication_failover_whitelistoch
replication_failover_blacklistFör konfigurationsvariabeln replication_failover_whitelist innehåller den en lista över IP:er eller värdnamn för slavar som ska användas som potentiella masterkandidater. Om denna variabel är inställd kommer endast dessa värdar att beaktas. För variabel replication_failover_blacklist innehåller den en lista över värdar som aldrig kommer att betraktas som en masterkandidat. Du kan använda den för att lista slavar som används för säkerhetskopiering eller analytiska frågor. Om hårdvaran varierar mellan slavar, kanske du vill sätta här slavarna som använder långsammare hårdvara.
replication_failover_whitelist har företräde, vilket innebär att replication_failover_blacklist ignoreras om replication_failover_whitelist är inställd.
När listan över slavar som kan befordras till master är klar, börjar ClusterControl att jämföra deras tillstånd och letar efter den mest uppdaterade slaven. Här skiljer sig hanteringen av MariaDB och MySQL-baserade inställningar. För MariaDB-inställningar väljer ClusterControl en slav som har den lägsta replikeringsfördröjningen av alla tillgängliga slavar. För MySQL-inställningar väljer ClusterControl också en sådan slav, men sedan söker den efter ytterligare, saknade transaktioner som kunde ha utförts på några av de återstående slavarna. Om en sådan transaktion hittas, slavar ClusterControl masterkandidaten från den värden för att hämta alla saknade transaktioner. Du kan hoppa över den här processen och bara använda den mest avancerade slaven genom att ställa in variabeln replication_skip_apply_missing_txs i din CMON-konfiguration:
t.ex.
replication_skip_apply_missing_txs=1Se vår dokumentation här för mer information om variabler.
Varning är att du bara måste ställa in detta om du vet vad du gör, eftersom det kan finnas felaktiga transaktioner. Dessa kan göra att replikeringen går sönder, såväl som datainkonsekvens i klustret. Om den felaktiga transaktionen hände tidigare, kanske den inte längre är tillgänglig i binära loggar. I så fall kommer replikeringen att gå sönder eftersom slavar inte kommer att kunna hämta de saknade data. Därför kontrollerar ClusterControl som standard efter eventuella felaktiga transaktioner innan den befordrar en masterkandidat till att bli en master. Om ett sådant problem upptäcks, avbryts huvudomkopplaren och ClusterControl låter användaren åtgärda problemet manuellt.
Om du vill vara 100 % säker på att ClusterControl kommer att marknadsföra en ny master även om vissa problem upptäcks, kan du göra det med variabeln replication_stop_on_error. Se nedan:
t.ex.
replication_stop_on_error=0Ställ in denna variabel i din cmon-konfigurationsfil. Som nämnts tidigare kan det leda till problem med replikering eftersom slavar kan börja fråga efter en binär logghändelse som inte är tillgänglig längre. För att hantera sådana fall lade vi till experimentellt stöd för återuppbyggnad av slav. Om du ställer in variabeln
replication_auto_rebuild_slave=1i cmon-konfigurationen och om din slav är markerad som nere med följande fel i MySQL:
Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'ClusterControl kommer att försöka bygga om slaven med hjälp av data från mastern. En sådan inställning kanske inte alltid är lämplig eftersom ombyggnadsprocessen kommer att inducera en ökad belastning på mastern. Det kan också vara så att din datauppsättning är mycket stor och en vanlig ombyggnad inte är ett alternativ - det är därför detta beteende är inaktiverat som standard.
När vi väl har försäkrat oss om att det inte finns någon felaktig transaktion och vi är klara att gå, finns det fortfarande ett problem till som vi måste hantera på något sätt - det kan hända att alla slavar släpar efter befälhavaren.
Som du säkert vet fungerar replikering i MySQL på ett ganska enkelt sätt. Masterlagrar skriver i binära loggar. Slavens I/O-tråd ansluter till mastern och drar alla binära logghändelser som den saknas. Den lagrar dem sedan i form av reläloggar. SQL-tråden analyserar dem och tillämpar händelser. Slavfördröjning är ett tillstånd där SQL-tråd (eller trådar) inte kan hantera antalet händelser och inte kan tillämpa dem så snart de dras från mastern av I/O-tråden. En sådan situation kan inträffa oavsett vilken typ av replikering du använder. Även om du använder semi-synk replikering, kan det bara garantera att alla händelser från mastern lagras på en av slavarna i reläloggen. Det står inget om att tillämpa dessa händelser på en slav.
Problemet här är att om en slav befordras till master, kommer reläloggar att raderas. Om en slav släpar efter och inte har tillämpat alla transaktioner kommer den att förlora data - händelser som ännu inte tillämpats från reläloggar kommer att gå förlorade för alltid.
Det finns inget enhetligt sätt att lösa denna situation. ClusterControl ger användarna kontroll över hur det ska göras och bibehåller säkra standardinställningar. Det görs i cmon-konfiguration med följande inställning:
replication_failover_wait_to_apply_timeout=-1Som standard tar det värdet "-1", vilket betyder att failover inte kommer att ske omedelbart om en masterkandidat släpar efter, så den är inställd på att vänta för evigt om inte kandidaten har kommit ikapp. ClusterControl kommer att vänta på obestämd tid för att tillämpa alla saknade transaktioner från sina reläloggar. Detta är säkert, men om den mest uppdaterade slaven av någon anledning släpar efter hårt, kan failover ta timmar att slutföra. På andra sidan av spektrumet sätts det till "0" - det betyder att failover sker omedelbart, oavsett om masterkandidaten släpar efter eller inte. Du kan också gå medelvägen och ställa in det på något värde. Detta kommer att ställa in en tid i sekunder, till exempel 30 sekunder, så ställ in variabeln på,
replication_failover_wait_to_apply_timeout=30När den är inställd på> 0, väntar ClusterControl på att en masterkandidat ska tillämpa saknade transaktioner från sina reläloggar tills värdet uppnås (vilket är 30 sekunder i exemplet). Failover sker efter den definierade tiden eller när masterkandidaten kommer ikapp replikeringen, beroende på vad som inträffar först. Detta kan vara ett bra val om din applikation har specifika krav på driftstopp och du måste välja en ny master inom ett kort tidsfönster.
För mer information om hur ClusterControl fungerar med automatisk failover i PostgreSQL och MySQL, kolla in våra tidigare bloggar med titeln "Failover for PostgreSQL Replication 101" och "Automatic failover of MySQL Replication - New in ClusterControl 1.4".
Slutsats
Automatiserad failover är en värdefull funktion, särskilt för företag som kräver drift dygnet runt med minimal stilleståndstid. Verksamheten måste definiera hur mycket kontroll som ges upp till automatiseringsprocessen vid oplanerade avbrott. En lösning med hög tillgänglighet som ClusterControl erbjuder en anpassningsbar nivå av interaktion vid failover-bearbetning. För vissa organisationer kanske automatiserad failover inte är ett alternativ, även om användarinteraktionen under failover kan ta tid och påverka RTO. Antagandet är att det är för riskabelt om automatiserad failover inte fungerar korrekt eller, ännu värre, det resulterar i att data förstörs och delvis saknas (även om man kan hävda att en människa också kan göra katastrofala misstag som leder till liknande konsekvenser). De som föredrar att ha nära kontroll över sin databas kan välja att hoppa över automatisk failover och istället använda en manuell process. En sådan process tar längre tid, men den tillåter en erfaren administratör att bedöma systemets tillstånd och vidta korrigerande åtgärder baserat på vad som hände.