I den här artikeln fortsätter jag att utforska lösningar på utmaningen att matcha utbud och efterfrågan. Tack till Luca, Kamil Kosno, Daniel Brown, Brian Walker, Joe Obbish, Rainer Hoffmann, Paul White, Charlie, Ian och Peter Larsson för att du skickade dina lösningar.
Förra månaden behandlade jag lösningar baserade på en reviderad intervallkorsningsmetod jämfört med den klassiska. Den snabbaste av dessa lösningar kombinerade idéer från Kamil, Luca och Daniel. Det förenade två frågor med osammanhängande sargbara predikat. Det tog lösningen 1,34 sekunder att slutföra mot en ingång på 400 000 rader. Det är inte så illa med tanke på att lösningen baserad på den klassiska intervallkorsningsmetoden tog 931 sekunder att slutföra mot samma ingång. Minns också att Joe kom med en briljant lösning som bygger på den klassiska interval intersection-metoden men som optimerar matchningslogiken genom att bucketizing intervall baserat på den största intervalllängden. Med samma indata på 400 000 rader tog det Joes lösning 0,9 sekunder att slutföra. Det knepiga med den här lösningen är att dess prestanda försämras när den största intervalllängden ökar.
Den här månaden utforskar jag fascinerande lösningar som är snabbare än Kamil/Luca/Daniel Revised Intersections-lösningen och som är neutrala till intervalllängd. Lösningarna i den här artikeln skapades av Brian Walker, Ian, Peter Larsson, Paul White och mig.
Jag testade alla lösningar i den här artikeln mot indatatabellen för auktioner med 100 000, 200 000, 300 000 och 400 000 rader och med följande index:
-- Index för att stödja lösning SKAPA UNIKT INKLUSTERAT INDEX idx_Code_ID_i_Quantity PÅ dbo.Auctions(Code, ID) INCLUDE(Quantity); -- Aktivera batch-läge Window Aggregate SKAPA ICKE CLUSTERED COLUMNSTORE INDEX idx_cs PÅ dbo.Auctions(ID) WHERE ID =-1 AND ID =-2;
När jag beskriver logiken bakom lösningarna antar jag att auktionstabellen är fylld med följande små uppsättning exempeldata:
ID-kod Kvantitet----------- ---- ----------1 D 5,0000002 D 3,0000003 D 8,0000005 D 2,0000006 D 8,0000007 D 4,0000008 D 2,0000000 S0 00000000 S0 0 S0 00000000 S0 2,0000004000 S 2,0000005000 S 4,0000006000 S 3,0000007000 S 2,000000
Följande är det önskade resultatet för dessa exempeldata:
DemandID SupplyID TradeQuantity-----------------------------------------------------1 1000 5,0000002 1000 3,0000003 2000 6,0000003 3000 2,0000005 4000 2,0000006 5000 4,0000006 6000 3,0000006 7000 1,0000007 7000 1,000000
Brian Walkers lösning
Outer joins är ganska vanligt förekommande i SQL-frågelösningar, men överlägset när du använder dem använder du enkelsidiga. När jag undervisar om ytterskarvar får jag ofta frågor som frågar efter exempel för praktiska användningsfall av hela ytterskarvar, och det är inte så många. Brians lösning är ett vackert exempel på ett praktiskt användningsfall med fullständiga yttre skarvar.
Här är Brians fullständiga lösningskod:
SLIPTA TABELL OM FINNS #MyPairings; CREATE TABLE #MyPairings( DemandID INT NOT NULL, SupplyID INT NOT NULL, TradeQuantity DECIMAL(19,06) NOT NULL); MED D AS( SELECT A.ID, SUM(A.Quantity) OVER (PARTITION BY A.Code ORDER BY A.ID ROWS UNBOUNDED PRECEDING) SOM Kör FRÅN dbo.Auctions AS A WHERE A.Code ='D'),S AS( SELECT A.ID, SUM(A.Quantity) OVER (PARTITION BY A.Code ORDER BY A.ID ROWS UNBOUNDED PRECEDING) AS Running FROM dbo.Auctions AS A WHERE A.Code ='S'),W AS( VÄLJ D.ID SOM DemandID, S.ID SOM SupplyID, ISNULL(D.Running, S.Running) AS Running FROM D FULL JOIN S ON D.Running =S.Running),Z AS( VÄLJ FALL NÄR W.DemandID IS INTE NULL DÅ W.DemandID ANNARS MIN(W.DemandID) OVER (ORDNING EFTER W.RUNNING RADER MELLAN AKTUELL RADER OCH OBEGRÄNSAD FÖLJANDE) SLUTAR SOM DemandID, FALL NÄR W.SupplyID INTE ÄR NULL DÅ W.SupplyIDSupplyID MIN(W. 4 ings( DemandID, SupplyID, TradeQuantity ) VÄLJ Z.DemandID, Z.SupplyID, Z.Running - ISNULL(LAG(Z.Running) OVER (ORDER BY Z.Running), 0.0) SOM TradeQuantity FROM Z WHERE Z.DemandID INTE ÄR NULL OCH Z.SupplyID ÄR INTE NULL;
Jag reviderade Brians ursprungliga användning av härledda tabeller med CTE för tydlighetens skull.
CTE D beräknar löpande totala efterfråganskvantiteter i en resultatkolumn som kallas D.Running, och CTE S beräknar löpande totala utbudskvantiteter i en resultatkolumn som kallas S.Running. CTE W utför sedan en fullständig yttre koppling mellan D och S, matchar D.Running med S.Running, och returnerar den första icke-NULL bland D.Running och S.Running som W.Running. Här är resultatet du får om du frågar alla rader från W ordnade genom att köra:
DemandID SupplyID körs----------- ---------- ----------1 NULL 5,0000002 1000 8,000000NULL 2000 14,0000003 3000 16,0000005 4000 18,00000 NULL 5000 22,000000NULL 6000 25,0000006 NULL 26,000000NULL 7000 27,0000007 NULL 30,0000008 NULL 32,000000
Idén att använda en fullständig yttre sammanfogning baserat på ett predikat som jämför totalsummorna för efterfrågan och utbud är ett genidrag! De flesta rader i det här resultatet – de första 9 i vårt fall – representerar resultatparningar med lite extra beräkningar som saknas. Rader med efterföljande NULL-ID av något av dessa slag representerar poster som inte kan matchas. I vårt fall representerar de två sista raderna efterfrågeposter som inte kan matchas med utbudsposter. Så vad som återstår här är att beräkna efterfrågan-ID, utbuds-ID och handelskvantitet för resultatparningarna och att filtrera bort de poster som inte kan matchas.
Logiken som beräknar resultatet DemandID och SupplyID görs i CTE Z enligt följande (förutsatt ordning i W genom att köra):
- DemandID:om DemandID inte är NULL så DemandID, annars det lägsta DemandID som börjar med den aktuella raden
- SupplyID:om SupplyID inte är NULL så SupplyID, annars det lägsta SupplyID som börjar med den aktuella raden
Här är resultatet du får om du frågar Z och beställer raderna genom att köra:
DemandID SupplyID Kör----------- ---------- ----------1 1000 5,0000002 1000 8,0000003 2000 14,0000003 3000 16,0000005 4000 18,00000 22,0000006 6000 25,0000006 7000 26,0000007 7000 27,0000007 NULL 30,0000008 NULL 32,000000
Den yttre frågan filtrerar bort rader från Z som representerar poster av ett slag som inte kan matchas av poster av det andra slaget genom att säkerställa att både DemandID och SupplyID inte är NULL. Resultatparningarnas handelskvantitet beräknas som det aktuella löpande värdet minus det tidigare löpande värdet med hjälp av en LAG-funktion.
Här är vad som skrivs till #MyPairings-tabellen, vilket är det önskade resultatet:
DemandID SupplyID TradeQuantity-----------------------------------------------------1 1000 5,0000002 1000 3,0000003 2000 6,0000003 3000 2,0000005 4000 2,0000006 5000 4,0000006 6000 3,0000006 7000 1,0000007 7000 1,000000
Planen för denna lösning visas i figur 1.
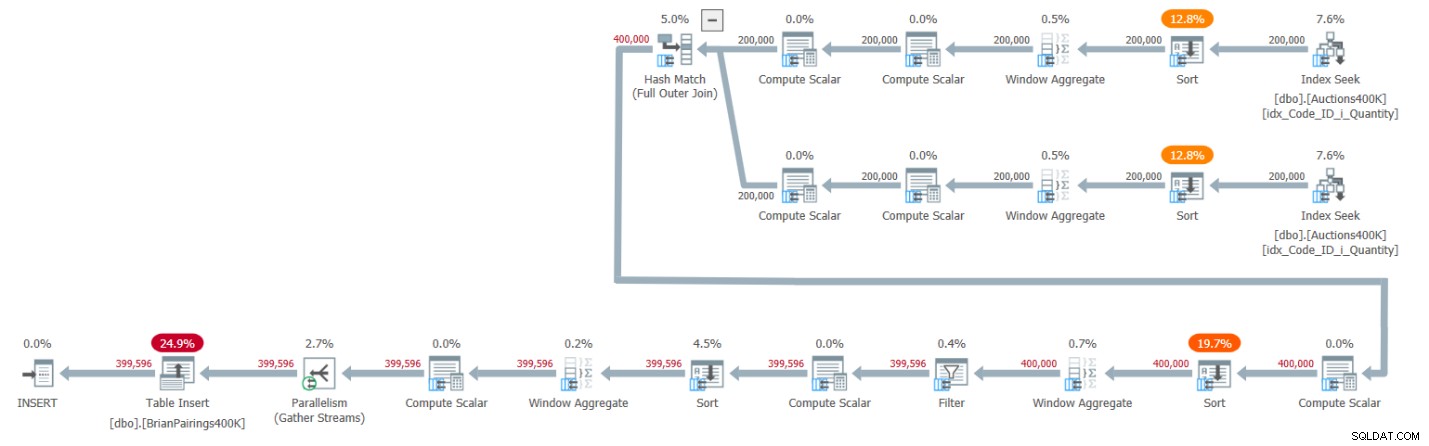 Figur 1:Frågeplan för Brians lösning
Figur 1:Frågeplan för Brians lösning
De två översta grenarna av planen beräknar löpande efterfråge- och utbudssummor med hjälp av en batch-mode Window Aggregate-operator, var och en efter att ha hämtat respektive poster från det stödjande indexet. Som jag förklarade i tidigare artiklar i serien, eftersom indexet redan har raderna ordnade som Window Aggregate-operatorerna behöver vara, skulle du tro att explicita sorteringsoperatorer inte borde krävas. Men SQL Server stöder för närvarande inte en effektiv kombination av parallell orderbevarande indexoperation före en parallell batch-mode Window Aggregate-operator, så som ett resultat går en explicit parallell sorteringsoperator före var och en av de parallella Window Aggregate-operatorerna.
Planen använder en hash-koppling i batchläge för att hantera den fullständiga yttre kopplingen. Planen använder också två extra batch-mode Window Aggregate-operatorer som föregås av explicita sorteringsoperatorer för att beräkna MIN- och LAG-fönsterfunktionerna.
Det är en ganska effektiv plan!
Här är körtiderna jag fick för den här lösningen mot indatastorlekar från 100K till 400K rader, i sekunder:
100K:0,368200K:0,845300K:1,255400K:1,315
Itziks lösning
Nästa lösning på utmaningen är ett av mina försök att lösa den. Här är den fullständiga lösningskoden:
SLIPTA TABELL OM FINNS #MyPairings; MED C1 AS( SELECT *, SUM(Quantity) OVER(PARTITION BY Code ORDER BY ID ROWS UNBOUNDED PRECEDING) AS SumQty FROM dbo.Auctions),C2 AS( SELECT *, SUM(Quantity * CASE Code WHEN 'D' THEN -1 NÄR 'S' SÅ 1 SLUTAR OVER(ORDER BY SumQuty, Code ROWS UNBOUNDED PRECEDING) AS StockLevel, LAG(SumQuty, 1, 0.0) OVER(ORDER BY SumQuty, Code) AS PrevSumQty, MAX(CASE WHEN Code ='D' THEN ID END) OVER(ORDER BY SumQty, Code ROWS UNBOUNDED PRECEDING) AS PrevDemandID, MAX(CASE WHEN Code ='S' THEN ID END) OVER(ORDER BY SumQty, Code ROWS UNBOUNDED PRECEDING) SOM PrevSupplyID, MIN(CASE WHEN) ='D' SEN ID SLUT) ÖVER(ORDNING EFTER SumQty, KodRADER MELLAN AKTUELL RADER OCH OBEGRÄNSAD FÖLJANDE) SOM NextDemandID, MIN(FALL NÄR Kod ='S' DÅ ID SLUTAR) ÖVER(ORDNING PER SumQty, KodRADER MELLAN AKTUELL RAD OCH OBEGRÄNSAD FÖLJANDE) SOM NextSupplyID FRÅN C1),C3 AS( SELECT *, CASE Code NÄR 'D ' THEN ID NÄR 'S' DÅ FALL NÄR LagerLevel> 0 DÅ NextDemandID ELSE PrevDemandID END END AS DemandID, CASE Code NÄR 'S' DÅ ID NÄR 'D' DÅ FALL NÄR StockLevel <=0 DÅ NextSupplyID ELSE PrevSupplyID END AS SumQty - PrevSumQty AS TradeQuantity FROM C2)SELECT DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM C3WHERE TradeQuantity> 0.0 OCH DemandID ÄR INTE NULL OCH SupplyID ÄR INTE NULL;
CTE C1 frågar auktionstabellen och använder en fönsterfunktion för att beräkna löpande totala efterfråge- och utbudskvantiteter och anropar resultatkolumnen SumQty.
CTE C2 frågar C1 och beräknar ett antal attribut med fönsterfunktioner baserade på SumQty och kodordning:
- Lagernivå:Aktuell lagernivå efter bearbetning av varje post. Detta beräknas genom att tilldela ett negativt tecken till efterfrågade kvantiteter och ett positivt tecken till leveranskvantiteter och summera dessa kvantiteter till och med den aktuella posten.
- PrevSumQty:Föregående rads SumQty-värde.
- PrevDemandID:Senaste icke-NULL begäran-ID.
- PrevSupplyID:Senaste icke-NULL-tillgångs-ID.
- NextDemandID:Nästa icke-NULL begäran-ID.
- NextSupplyID:Nästa icke-NULL-tillgångs-ID.
Här är innehållet i C2 sorterat efter SumQty och Code:
ID-kod Kvantitet SumQty Lagernivå PrevSumQuty PrevDemandID PrevSupplyID NextDemandID NextSupplyID----- ---- ---------- ---------- ---------- ----------- ------------ ------------ ------------ - ----------- 1 D 5.000000 5.000000 -5.000000 0.000000 1 NULL 1 10002 D 3.000000 8.000000 -8.0000 5.000000 2 NULL 2 10001000 S 8.0000 8.0000 0.0000. D 8.000000 16.000000 -2.000000 14.000000 3 2000 3 30003000 S 2.000000 16.000000 0.000000 16.000000 3 3000 5 30005 D 2.000000 18.000000 -2.000000 16.000000 5 3000 5 40004000 S 2.000000 18.000000 0.000000 18.000000 5 4000 6 40005000 S 4.000000 22.000000 4.000000 18.000000 5 5000 6 50006000 S 3.000000 25.000000 7.0000 22.0000 5 6000 6.006 D. 32,000000 -5,000000 30,000000 8 7000 8 NULL
CTE C3 frågar C2 och beräknar resultatparningarnas DemandID, SupplyID och TradeQuantity innan några överflödiga rader tas bort.
Resultatkolumnen C3.DemandID beräknas så här:
- Om den aktuella posten är en efterfrågan, returnera DemandID.
- Om den aktuella posten är en leveranspost och den aktuella lagernivån är positiv, returnera NextDemandID.
- Om den aktuella posten är en leveranspost och den aktuella lagernivån är icke-positiv, returnera PrevDemandID.
Resultatkolumnen C3.SupplyID beräknas så här:
- Om den aktuella posten är en leveranspost, returnera SupplyID.
- Om den aktuella posten är en efterfrågan och den aktuella lagernivån är icke-positiv, returnera NextSupplyID.
- Om den aktuella posten är en efterfrågepost och den aktuella lagernivån är positiv, returnera PrevSupplyID.
Resultatet TradeQuantity beräknas som den aktuella radens SumQty minus PrevSumQty.
Här är innehållet i kolumnerna som är relevanta för resultatet från C3:
DemandID SupplyID TradeQuantity-----------------------------------------------------1 1000 5,0000002 1000 3,0000002 1000 0,0000003 2000 6.0000003 3000 2.0000003 3000 0.0000005 4000 2.0000005 4000 0.0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.0000007 NULL 3.0000008 NULL 2.000000
Vad som återstår för den yttre frågan att göra är att filtrera bort överflödiga rader från C3. Dessa inkluderar två fall:
- När de löpande summorna för båda typerna är desamma, har leveransposten noll handelskvantitet. Kom ihåg att beställningen är baserad på SumQty och Code, så när de löpande summorna är desamma, visas efterfrågeposten före utbudsposten.
- Efterföljande poster av ett slag som inte kan matchas med poster av det andra slaget. Sådana poster representeras av rader i C3 där antingen DemandID är NULL eller SupplyID är NULL.
Planen för denna lösning visas i figur 2.
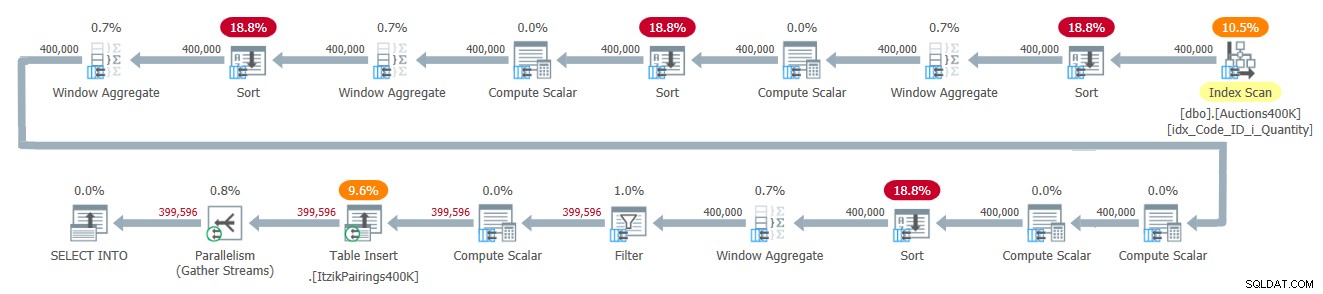 Figur 2:Frågaplan för Itziks lösning
Figur 2:Frågaplan för Itziks lösning
Planen tillämpar en passage över indata och använder fyra batch-mode Window Aggregate-operatorer för att hantera de olika fönsterberäkningarna. Alla Window Aggregate-operatorer föregås av explicita sorteringsoperatorer, även om endast två av dem är oundvikliga här. De andra två har att göra med den nuvarande implementeringen av den parallella batch-mode Window Aggregate-operatören, som inte kan förlita sig på en parallell orderbevarande indata. Ett enkelt sätt att se vilka sorteringsoperatorer som är på grund av detta är att tvinga fram en serieplan och se vilka sorteringsoperatorer som försvinner. När jag tvingar fram en serieplan med den här lösningen försvinner den första och tredje sorteringsoperatorn.
Här är körtiderna i sekunder som jag fick för den här lösningen:
100K:0,246200K:0,427300K:0,616400K:0,841>
Ians lösning
Ians lösning är kort och effektiv. Här är den fullständiga lösningskoden:
SLIPTA TABELL OM FINNS #MyPairings; MED A AS ( VÄLJ *, SUMMA (Quantity) ÖVER (PARTITION BY Code ORDER BY ID ROWS UNBOUNDED FÖREGÅENDE) SOM Kumulativ Kvantitet FRÅN dbo.Auctions), B AS ( VÄLJ Kumulativ Kvantitet, Kumulativ Kvantitet - LAG( Kumulativ Kvantitet, OVER1, ORDER 0) BY CumulativeQuantity) AS TradeQuantity, MAX(CASE WHEN Code ='D' THEN ID END) AS DemandID, MAX(CASE WHEN Code ='S' THEN ID END) AS SupplyID FRÅN A GROUP BY CumulativeQuantity, ID/ID -- falsk gruppering för att förbättra raduppskattning -- (radantal av auktioner istället för 2 rader)), C AS ( -- fyll i NULLs med nästa utbud / efterfrågan -- FIRST_VALUE(ID) IGNORERA NULLER ÖVER ... -- skulle vara bättre, men detta kommer att fungera eftersom ID:n är i CumulativeQuantity-ordning VÄLJ MIN(DemandID) OVER (ORDNING EFTER CumulativeQuantity RADER MELLAN AKTUELL RADER OCH OBEGRÄNSAD FÖLJANDE) SOM DemandID, MIN(SupplyID) OVER (ORDER BY CumulativeQ mängd RADER MELLAN AKTUELL RADER OCH OBEGRÄNSAD FÖLJANDE) SOM SupplyID, TradeQuantity FRÅN B)VÄLJ DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM CWHERE SupplyID IS NOT NULL -- trim ouppfyllda krav OCH DemandID ÄR INTE NULL; -- trimma oanvända tillbehör
Koden i CTE A frågar efter auktionstabellen och beräknar löpande totala efterfråge- och utbudskvantiteter med hjälp av en fönsterfunktion, som namnger resultatkolumnen CumulativeQuantity.
Koden i CTE B frågar CTE A och grupperar raderna efter CumulativeQuantity. Denna gruppering uppnår en liknande effekt som Brians yttre sammanfogning baserat på löpande efterfrågan och utbud. Ian lade också till dummyuttryckets ID/ID till grupperingsuppsättningen för att förbättra grupperingens ursprungliga kardinalitet under uppskattning. På min maskin resulterade detta också i att jag använde en parallell plan istället för en seriell.
I SELECT-listan beräknar koden DemandID och SupplyID genom att hämta ID:t för respektive posttyp i gruppen med hjälp av MAX-aggregatet och ett CASE-uttryck. Om ID:t inte finns i gruppen är resultatet NULL. Koden beräknar också en resultatkolumn som heter TradeQuantity som den nuvarande kumulativa kvantiteten minus den föregående, hämtad med hjälp av LAG-fönsterfunktionen.
Här är innehållet i B:
CumulativeQuantity TradeQuantity DemandId SupplyId------------------------- -------------------- ---------- - -------- 5.000000 5.000000 1 NULL 8.000000 3.000000 2 100014.000000 6.000000 NULL 200016.000000 2.000000 3 300018.000000 2.000000 5 400022.000000 4.000000 NULL 500025.000000 3.000000 NULL 600026.000000 1.000000 6 NULL27.000000 1.000000 NULL 700030.000000 3.000000 7 NULL32.000000 2.000000 8 NULL
Koden i CTE C frågar sedan CTE B och fyller i NULL efterfråge- och utbuds-ID med nästa icke-NULL efterfråge- och utbuds-ID, med hjälp av MIN-fönsterfunktionen med ramen RADER MELLAN AKTUELL RADER OCH OBEGRÄNSAD FÖLJANDE.
Här är innehållet i C:
DemandID SupplyID TradeQuantity ---------- ---------- --------------1 1000 5,000000 2 1000 3,000000 3 2000 6,000000 3 3000 2,000000 5 4000 2,000000 6 5000 4,000000 6 6000 3,000000 6 7000 1,000000 7 7000 1,000000 7 NULL 3,000000 20preDet sista steget som hanteras av den yttre frågan mot C är att ta bort poster av ett slag som inte kan matchas med poster av det andra slaget. Det görs genom att filtrera bort rader där antingen SupplyID är NULL eller DemandID är NULL.
Planen för denna lösning visas i figur 3.
Figur 3:Frågeplan för Ians lösning
Denna plan utför en skanning av indata och använder tre parallella batch-mode fönsteraggregatoperatorer för att beräkna de olika fönsterfunktionerna, alla föregås av parallella sorteringsoperatorer. Två av dessa är oundvikliga som du kan verifiera genom att tvinga fram en serieplan. Planen använder också en Hash Aggregate-operatör för att hantera grupperingen och aggregeringen i CTE B.
Här är körtiderna i sekunder som jag fick för den här lösningen:
100K:0,214200K:0,363300K:0,546400K:0,701
Peter Larssons lösning
Peter Larssons lösning är otroligt kort, söt och mycket effektiv. Här är Peters fullständiga lösningskod:
SLIPTA TABELL OM FINNS #MyPairings; WITH cteSource(ID, Code, RunningQuantity)AS( SELECT ID, Code, SUM(Quantity) OVER (PARTITION BY Code ORDER BY ID) AS RunningQuantity FROM dbo.Auctions)SELECT DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM (VÄLJ MIN(CASE WHEN) Kod ='D' SEN ID ANNAT 2147483648 SLUT) ÖVER (ORDER EFTER RunningQuantity, Kod RADER MELLAN AKTUELL RADER OCH OBEGRÄNSAD FÖLJANDE) SOM DemandID, MIN(FALL NÄR Kod ='S' DÅ ID ANNAT 214748368ORning) Kod RADER MELLAN AKTUELL RADER OCH OBEGRÄNSAD FÖLJANDE) AS SupplyID, RunningQuantity - COALESCE(LAG(RunningQuantity) OVER (ORDER BY RunningQuantity, Code), 0.0) AS TradeQuantity FROM cteSource ) AS dWHERE DemandID 48. SupplyANDQuantity <47487 .47487 .47487 48ID 47487 .61ID 36487 .CTE cteSource frågar efter auktionstabellen och använder en fönsterfunktion för att beräkna löpande totala efterfrågan och utbudskvantiteter, anropar resultatkolumnen RunningQuantity.
Koden som definierar den härledda tabellen d frågar efter cteSource och beräknar resultatparningarnas DemandID, SupplyID och TradeQuantity innan några överflödiga rader tas bort. Alla fönsterfunktioner som används i dessa beräkningar är baserade på RunningQuantity och Code ordering.
Resultatkolumnen d.DemandID beräknas som det lägsta behovs-ID som börjar med det aktuella eller 2147483648 om inget hittas.
Resultatkolumnen d.SupplyID beräknas som lägsta leverans-ID som börjar med det aktuella eller 2147483648 om inget hittas.
Resultatet TradeQuantity beräknas som den aktuella radens RunningQuantity-värde minus föregående rads RunningQuantity-värde.
Här är innehållet i d:
DemandID SupplyID TradeQuantity--------- ------------------ --------------------1 1000 5,0000002 1000 3,0000003 1000 0,0000003 2000 6,0000003 3000 2.0000005 3000 0.0000005 4000 2.0000006 4000 0.0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.0000007 2147483648 3.0000008 2147483648 2.00000000Vad som återstår för den yttre frågan att göra är att filtrera bort överflödiga rader från d. Det är fall där handelskvantiteten är noll, eller poster av ett slag som inte kan matchas med poster från det andra slaget (med ID 2147483648).
Planen för denna lösning visas i figur 4.
Figur 4:Frågeplan för Peters lösning
Precis som Ians plan, bygger Peters plan på en genomsökning av indata och använder tre parallella batch-mode fönsteraggregatoperatorer för att beräkna de olika fönsterfunktionerna, alla föregås av parallella sorteringsoperatorer. Två av dessa är oundvikliga som du kan verifiera genom att tvinga fram en serieplan. I Peters plan finns det inget behov av en grupperad aggregatoperatör som i Ians plan.
Peters kritiska insikt som möjliggjorde en så kort lösning var insikten att för en relevant post av någon av slagen, kommer matchande ID av det andra slaget alltid att dyka upp senare (baserat på RunningQuantity och Code ordering). Efter att ha sett Peters lösning kändes det verkligen som att jag överkomplicerade saker i min!
Här är körtiderna i sekunder jag fick för den här lösningen:
100K:0,197200K:0,412300K:0,558400K:0,696
Paul Whites lösning
Vår sista lösning skapades av Paul White. Här är den fullständiga lösningskoden:
SLIPTA TABELL OM FINNS #MyPairings; SKAPA TABELL #MyPairings( DemandID heltal INTE NULL, SupplyID heltal NOT NULL, TradeQuantity decimal(19, 6) NOT NULL);GO INSERT #MyPairings WITH (TABLOCK)( DemandID, SupplyID, TradeQuantity)SELECT Q3.DemandID, Q3.SupplyID, Q3.SupplyID Q3.TradeQuantityFROM ( VÄLJ Q2.DemandID, Q2.SupplyID, TradeQuantity =-- Intervallöverlappning FALL NÄR Q2.Code ='S' DÅ FALL NÄR Q2.CumDemand>=Q2.IntEnd SÅ Q2.IntLength NÄR Q2.CumDemand> Q2. IntStart THEN Q2.CumDemand - Q2.IntStart ELSE 0.0 SLUT NÄR Q2.Code ='D' THEN CASE NÄR Q2.CumSupply>=Q2.IntEnd DÅ Q2.IntLength NÄR Q2.CumSupply> Q2.IntStart - Q2.Cumn THEN. IntStart ELSE 0.0 END END FRÅN ( VÄLJ Q1.Code, Q1.IntStart, Q1.IntEnd, Q1.IntLength, DemandID =MAX(IIF(Q1.Code ='D', Q1.ID, 0)) ÖVER ( BESTÄLLNING EFTER Q1.IntStart, Q1.ID RADER OBEGRÄNSADE PRECEDING), SupplyID =MAX(IIF(Q1.Code ='S', Q1.ID, 0)) OVER (ORDNING EFTER Q1.IntStart, Q1.ID RADER OBEGRÄNSAD FÖREGÅENDE), CumSupply =SUM(IIF(Q1.Code ='S', Q1.IntLength, 0)) ÖVER (ORDNING EFTER Q1.IntStart, Q1.ID RADER OBEGRÄNSAD FÖREGÅENDE), CumDemand =SUM(IIF(Q1.Code ='D', Q1.IntLength, 0)) ÖVER ( BESTÄLL EFTER Q1.IntStart, Q1.ID RADER OBEGRÄNSAD FÖREGÅENDE) FRÅN ( -- Begärintervall VÄLJ A.ID, A.Code, IntStart =SUM(A.Quantity) ÖVER (ORDNING EFTER A.ID-RADER OBEGRÄNSAD FÖREGÅENDE) - A. Kvantitet, IntEnd =SUM(A.Quantity) ÖVER (ORDER BY A.ID ROWS UNBOUNDED PRECEDING), IntLength =A.Quantity FROM dbo.Auctions AS A WHERE A.Code ='D' UNION ALL -- Leveransintervall VÄLJ A.ID, A.Code, IntStart =SUM(A.Quantity) ÖVER (ORDER BY A.ID ROWS UNBOUNDED PRECEDING) - A.Quantity, IntEnd =SUM(A.Quantity) OVER (ORDER BY A.ID ROWS UNBOUNDED PRECEDING), IntLength =A.Quantity FROM dbo.Auctions AS A WHERE A.Code ='S' ) AS Q1 ) AS Q2) AS Q3WHERE Q3.TradeQuantity> 0;Koden som definierar den härledda tabellen Q1 använder två separata frågor för att beräkna efterfråge- och utbudsintervall baserat på löpande summor och förenar de två. För varje intervall beräknar koden dess start (IntStart), slutet (IntEnd) och längden (IntLength). Här är innehållet i Q1 sorterat efter IntStart och ID:
ID-kod IntStart IntEnd IntLength----- ---- ---------- ---------- ----------1 D 0,000000 5.000000 5.0000001000 S 0.000000 8.000000 8.0000002 D 5.000000 8.000000 3.0000003 D 8.000000 16.000000 8.0000002000 S 8.000000 14.000000 6.0000003000 S 14.000000 16.000000 2.0000005 D 16.000000 18.000000 2.0000004000 S 16.000000 18.000000 2.0000006 D 18.000000 26.000000 8.0000005000 S 18.000000 22.000000 4.0000006000 S 22.000000 25.000000 3.0000007000 S 25.000000 27.000000 2.0000007 D 26.000000 30.000000 4.0000008 D 30,000000 32,000000 2,000000Koden som definierar den härledda tabellen Q2 frågar Q1 och beräknar resultatkolumner som kallas DemandID, SupplyID, CumSupply och CumDemand. Alla fönsterfunktioner som används av den här koden är baserade på IntStart- och ID-ordning och ramen ROWS UNBOUNDED PRECEDING (alla rader upp till nuvarande).
DemandID är det maximala efterfråge-ID upp till den aktuella raden, eller 0 om inget finns.
SupplyID är det maximala leverans-ID upp till den aktuella raden, eller 0 om inget finns.
CumSupply är de kumulativa leveranskvantiteterna (tillförselintervalllängder) upp till den aktuella raden.
CumDemand är de kumulativa efterfrågekvantiteterna (efterfrågeintervalllängder) upp till den aktuella raden.
Här är innehållet i Q2:
Kod IntStart IntEnd IntLength DemandID SupplyID CumSupply CumDemand---- ---------- ---------- ---------- ----- ---- ---------- ---------- ----------D 0,000000 5,000000 5,000000 1 0 0,000000 5,000000S 0,000000 8,000000 8,000000 1 1000 0,000 0,00 D 5.000000 8.000000 3.000000 2 1000 8.000000 8.000000D 8.000000 16.000000 8.000000 3 1000 8.000000 16.000000S 8.000000 14.000000 6.000000 3 2000 14.000000 16.000000S 14.000000 16.000000 2.000000 3 3000 16.000000 16.000000D 16.000000 18.000000 2.000000 5 3000 16.000000 18.000000S 16.000000 18.000000 2.000000 5 4000 18.000000 18.000000D 18.000000 26.000000 8,000000 6 4000 18,000000 26,000000S 18,000000 22,000000 4,000000 6 5000 22,000000 26,000000S 00,000000S 00 00 00 00 00 00 00 00 25.000000 26.000000S 25.000000 27.000000 2.000000 6 7000 27.000000 26.000000D 26.000000 30.000000 4.000000 7 7000 27.000000 30.000000D 30.000000 32.000000 2.000000 8 7000 27.000000 32.000000Q2 already has the final result pairings’ correct DemandID and SupplyID values. The code defining the derived table Q3 queries Q2 and computes the result pairings’ TradeQuantity values as the overlapping segments of the demand and supply intervals. Finally, the outer query against Q3 filters only the relevant pairings where TradeQuantity is positive.
The plan for this solution is shown in Figure 5.
Figure 5:Query plan for Paul’s solution
The top two branches of the plan are responsible for computing the demand and supply intervals. Both rely on Index Seek operators to get the relevant rows based on index order, and then use parallel batch-mode Window Aggregate operators, preceded by Sort operators that theoretically could have been avoided. The plan concatenates the two inputs, sorts the rows by IntStart and ID to support the subsequent remaining Window Aggregate operator. Only this Sort operator is unavoidable in this plan. The rest of the plan handles the needed scalar computations and the final filter. That’s a very efficient plan!
Here are the run times in seconds I got for this solution:
100K:0.187200K:0.331300K:0.369400K:0.425These numbers are pretty impressive!
Performance Comparison
Figure 6 has a performance comparison between all solutions covered in this article.
Figure 6:Performance comparison
At this point, we can add the fastest solutions I covered in previous articles. Those are Joe’s and Kamil/Luca/Daniel’s solutions. The complete comparison is shown in Figure 7.
Figure 7:Performance comparison including earlier solutions
These are all impressively fast solutions, with the fastest being Paul’s and Peter’s.
Slutsats
When I originally introduced Peter’s puzzle, I showed a straightforward cursor-based solution that took 11.81 seconds to complete against a 400K-row input. The challenge was to come up with an efficient set-based solution. It’s so inspiring to see all the solutions people sent. I always learn so much from such puzzles both from my own attempts and by analyzing others’ solutions. It’s impressive to see several sub-second solutions, with Paul’s being less than half a second!
It's great to have multiple efficient techniques to handle such a classic need of matching supply with demand. Well done everyone!
[ Jump to:Original challenge | Solutions:Part 1 | Part 2 | Part 3 ]