I någon av relationsdatabasernas motorer krävs det att man genererar en bästa möjliga plan som motsvarar utförandet av frågan med minst tid och resurser. I allmänhet genererar alla databaser planer i ett trädstrukturformat, där lövnoden för varje planträd kallas tabellavsökningsnod. Denna speciella nod i planen motsvarar algoritmen som ska användas för att hämta data från bastabellen.
Tänk till exempel på ett enkelt frågeexempel som SELECT * FROM TBL1, TBL2 där TBL2.ID>1000; och anta att planen som genereras är enligt nedan:
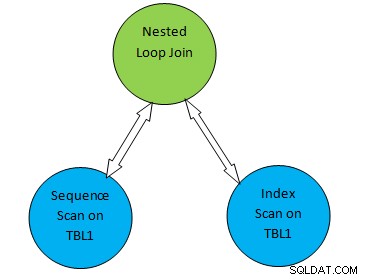
Så i ovanstående planträd, "Sekventiell skanning på TBL1" och " Index Scan on TBL2” motsvarar tabellskanningsmetoden på tabell TBL1 respektive TBL2. Så enligt denna plan kommer TBL1 att hämtas sekventiellt från motsvarande sidor och TBL2 kan nås med INDEX Scan.
Att välja rätt skanningsmetod som en del av planen är mycket viktigt när det gäller övergripande frågeprestanda.
Innan vi börjar med alla typer av skanningsmetoder som stöds av PostgreSQL, låt oss revidera några av de viktigaste nyckelpunkterna som kommer att användas ofta när vi går igenom bloggen.
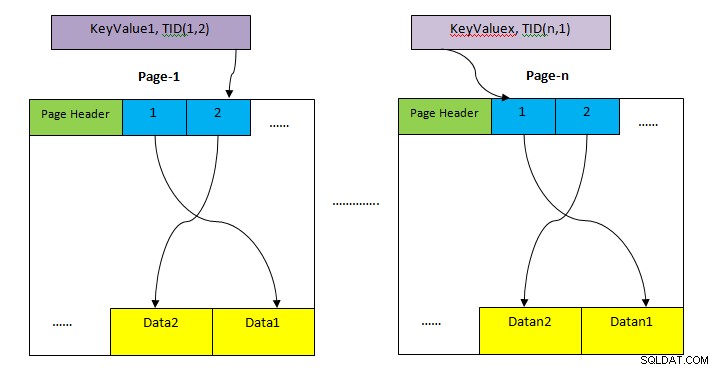
- HEAP: Förvaringsutrymme för förvaring av hela bordsraden. Detta är uppdelat i flera sidor (som visas i bilden ovan) och varje sidstorlek är som standard 8KB. På varje sida pekar varje objektpekare (t.ex. 1, 2, …) till data på sidan.
- Indexlagring: Denna lagring lagrar endast nyckelvärden, dvs kolumnvärden som ingår i index. Detta är också uppdelat i flera sidor och varje sidstorlek är som standard 8KB.
- Tuple Identifier (TID): TID är 6 bytes nummer som består av två delar. Den första delen är 4-byte sidnummer och återstående 2 byte tuppelindex inuti sidan. Kombinationen av dessa två siffror pekar unikt på lagringsplatsen för en viss tuppel.
För närvarande stöder PostgreSQL nedanstående skanningsmetoder med vilka all nödvändig data kan läsas från tabellen:
- Sekventiell genomsökning
- Indexsökning
- Endast indexsökning
- Bitmappsskanning
- TID-skanning
Var och en av dessa skanningsmetoder är lika användbara beroende på frågan och andra parametrar, t.ex. tabellkardinalitet, tabellselektivitet, disk I/O-kostnad, slumpmässig I/O-kostnad, sekvens I/O-kostnad, etc. Låt oss skapa en förinställd tabell och fylla på med några data, som kommer att användas ofta för att bättre förklara dessa skanningsmetoder .
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 1000000);
INSERT 0 1000000
postgres=# analyze;
ANALYZESå i det här exemplet infogas en miljon poster och sedan analyseras tabellen så att all statistik är uppdaterad.
Sekventiell skanning
Som namnet antyder görs en sekventiell skanning av en tabell genom att sekventiell skanna alla objektpekare på alla sidor i motsvarande tabeller. Så om det finns 100 sidor för en viss tabell och sedan det finns 1000 poster på varje sida, kommer den som en del av sekventiell genomsökning att hämta 100*1000 poster och kontrollera om den matchar enligt isoleringsnivån och även enligt predikatsatsen. Så även om endast en post väljs som en del av hela tabellskanningen, måste den skanna 100 000 poster för att hitta en kvalificerad post enligt villkoret.
I enlighet med tabellen och data ovan kommer följande fråga att resultera i en sekventiell genomsökning eftersom majoriteten av data väljs ut.
postgres=# explain SELECT * FROM demotable WHERE num < 21000;
QUERY PLAN
--------------------------------------------------------------------
Seq Scan on demotable (cost=0.00..17989.00 rows=1000000 width=15)
Filter: (num < '21000'::numeric)
(2 rows)OBS
Även utan att beräkna och jämföra plankostnaden är det nästan omöjligt att säga vilken typ av skanningar som kommer att användas. Men för att den sekventiella skanningen ska kunna användas bör åtminstone nedanstående kriterier matcha:
- Inget index tillgängligt på nyckel, som är en del av predikatet.
- Majoriteten av raderna hämtas som en del av SQL-frågan.
TIPS
Om endast ett fåtal % av raderna hämtas och predikatet finns i en (eller flera) kolumner, försök sedan att utvärdera prestanda med eller utan index.
Indexsökning
Till skillnad från sekventiell genomsökning, hämtar inte indexsökning alla poster sekventiellt. Snarare använder den olika datastruktur (beroende på typ av index) som motsvarar indexet som är involverat i frågan och lokalisera nödvändig data (enligt predikat) klausul med mycket minimala skanningar. Sedan pekar posten som hittas med hjälp av indexskanningen direkt till data i högområdet (som visas i bilden ovan), som sedan hämtas för att kontrollera synligheten enligt isoleringsnivån. Så det finns två steg för indexskanning:
- Hämta data från indexrelaterad datastruktur. Den returnerar TID för motsvarande data i heap.
- Då nås motsvarande högsida direkt för att få hela data. Detta ytterligare steg krävs av följande skäl:
- Frågan kan ha begärt att hämta kolumner fler än vad som är tillgängligt i motsvarande index.
- Synlighetsinformation underhålls inte tillsammans med indexdata. Så för att kunna kontrollera synligheten för data enligt isoleringsnivå måste den komma åt högdata.
Nu kan vi undra varför inte alltid använda Index Scan om det är så effektivt. Så som vi vet kommer allt med en viss kostnad. Här är kostnaden relaterad till vilken typ av I/O vi gör. I fallet med Index Scan är slumpmässig I/O involverad eftersom för varje post som hittas i indexlagring måste den hämta motsvarande data från HEAP-lagring medan i fallet med Sequential Scan är Sequence I/O inblandad vilket tar ungefär bara 25 % av slumpmässig I/O-timing.
Så Indexskanning bör endast väljas om den totala vinsten överträffar de omkostnader som uppstår på grund av slumpmässiga I/O-kostnader.
I enlighet med tabellen och data ovan kommer följande fråga att resultera i en indexsökning eftersom endast en post väljs. Så slumpmässig I/O är mindre och det går snabbt att söka efter motsvarande post.
postgres=# explain SELECT * FROM demotable WHERE num = 21000;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.42..8.44 rows=1 width=15)
Index Cond: (num = '21000'::numeric)
(2 rows)Endast indexsökning
Index Only Scan liknar Index Scan förutom det andra steget, dvs som namnet antyder skannar den bara indexdatastrukturen. Det finns ytterligare två förutsättningar för att välja Index Endast Scan jämför med Index Scan:
- Frågan ska bara hämta nyckelkolumner som är en del av indexet.
- Alla tupler (poster) på den valda högsidan ska vara synliga. Som diskuterats i föregående avsnitt bibehåller inte indexdatastrukturen synlighetsinformation, så för att endast välja data från index bör vi undvika att kontrollera om det finns synlighet och detta kan hända om all data på den sidan anses vara synlig.
Följande fråga kommer att resultera i en endast indexsökning. Även om den här frågan är nästan lika när det gäller att välja antal poster men eftersom endast nyckelfält (dvs. "num") väljs, kommer den att välja Index Endast Scan.
postgres=# explain SELECT num FROM demotable WHERE num = 21000;
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..8.44 rows=1 Width=11)
Index Cond: (num = '21000'::numeric)
(2 rows)Bitmappsskanning
Bitmappsskanning är en blandning av indexskanning och sekventiell skanning. Den försöker lösa nackdelen med Index scan men behåller fortfarande sin fulla fördel. Som diskuterats ovan för varje data som finns i indexdatastrukturen, måste den hitta motsvarande data på högsidan. Så alternativt måste den hämta indexsida en gång och sedan följt av heap-sida, vilket orsakar mycket slumpmässig I/O. Så bitmappsskanningsmetoden utnyttjar fördelen med indexskanning utan slumpmässig I/O. Detta fungerar på två nivåer enligt nedan:
- Bitmap Index Scan:Först hämtar den all indexdata från indexdatastrukturen och skapar en bitmap över alla TID. För enkel förståelse kan du överväga att den här bitmappen innehåller en hash av alla sidor (hashad baserat på sidnummer) och varje sidpost innehåller en matris med all offset på sidan.
- Bitmap Heap Scan:Som namnet antyder läser den igenom bitmapp av sidor och skannar sedan data från heap som motsvarar lagrad sida och offset. I slutet kontrollerar den för synlighet och predikat etc och returnerar tupeln baserat på resultatet av alla dessa kontroller.
Frågan nedan kommer att resultera i bitmappssökning eftersom den inte väljer väldigt få poster (dvs. för mycket för indexskanning) och samtidigt inte väljer ett stort antal poster (dvs. för lite för en sekventiell sökning) skanna).
postgres=# explain SELECT * FROM demotable WHERE num < 210;
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on demotable (cost=5883.50..14035.53 rows=213042 width=15)
Recheck Cond: (num < '210'::numeric)
-> Bitmap Index Scan on demoidx (cost=0.00..5830.24 rows=213042 width=0)
Index Cond: (num < '210'::numeric)
(4 rows)Tänk nu på nedanstående fråga, som väljer samma antal poster men bara nyckelfält (dvs. endast indexkolumner). Eftersom den endast väljer nyckel, behöver den inte hänvisa till högsidor för andra delar av data och därför är det ingen slumpmässig I/O involverad. Så den här frågan kommer att välja Index Endast Scan istället för Bitmap Scan.
postgres=# explain SELECT num FROM demotable WHERE num < 210;
QUERY PLAN
---------------------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..7784.87 rows=208254 width=11)
Index Cond: (num < '210'::numeric)
(2 rows)TID-skanning
TID, som nämnts ovan, är 6 byte nummer som består av 4-byte sidnummer och återstående 2 byte tuppelindex inuti sidan. TID-skanning är en mycket specifik typ av skanning i PostgreSQL och väljs endast om det finns TID i frågepredikatet. Överväg nedanstående fråga som visar TID-skanningen:
postgres=# select ctid from demotable where id=21000;
ctid
----------
(115,42)
(1 row)
postgres=# explain select * from demotable where ctid='(115,42)';
QUERY PLAN
----------------------------------------------------------
Tid Scan on demotable (cost=0.00..4.01 rows=1 width=15)
TID Cond: (ctid = '(115,42)'::tid)
(2 rows)Så här i predikatet, istället för att ge ett exakt värde på kolumnen som villkor, tillhandahålls TID. Detta är något som liknar ROWID-baserad sökning i Oracle.
Bonus
Alla skanningsmetoder är flitigt använda och kända. Dessa skanningsmetoder är också tillgängliga i nästan alla relationsdatabaser. Men det finns en annan skanningsmetod som nyligen diskuterats i PostgreSQL-gemenskapen och som nyligen lagts till i andra relationsdatabaser. Det kallas "Loose IndexScan" i MySQL, "Index Skip Scan" i Oracle och "Jump Scan" i DB2.
Denna skanningsmetod används för ett specifikt scenario där ett distinkt värde på ledande nyckelkolumn i B-Tree-index är vald. Som en del av denna skanning undviker den att korsa alla lika nyckelkolumnvärden istället för att bara gå igenom det första unika värdet och sedan hoppa till nästa stora.
Detta arbete pågår fortfarande i PostgreSQL med det preliminära namnet "Index Skip Scan" och vi kan förvänta oss att se detta i en framtida release.