I del 1 av den här serien har vi framgångsrikt importerat SuiteCRM-databasstrukturen till vårt onlinedatabasmodelleringsverktyg. Det var då vi såg att modellen innehåller 201 tabeller utan relationer mellan dem. Vi fick ett vilt gäng bord som såg riktigt röriga ut. I den här artikeln kommer jag att visa dig hur du kan organisera en så stor modell.
Precis efter importen till Vertabelo ser SuiteCRM-databasmodellen ut som följer:
Modellen fungerar – men inte effektivt. Vi kommer att behöva modifiera den för att göra den riktigt användbar. Eftersom vi vill analysera SuiteCRM-databasen efter åtgärder utförs på dess GUI måste vi förstå tabelldefinitioner och relationerna mellan tabeller. Låt oss börja med att gruppera tabeller i ämnesområden och upprätta de viktigaste relationerna.
Vertabelo erbjuder tre huvudverktyg som hjälper dig att organisera stora diagram:
- Ämnesområden
- Tabell- och visningsgenvägar
- Referensgenvägar
Jag kommer att beskriva dem senare i den här artikeln, men du kan också lära dig mer genom att titta på den här videon.
Steg 1. Inaktivera automatisk generering av främmande nycklar
Först och främst inaktiverar vi den automatiska genereringen av främmande nycklar. Som standard genererar Vertabelo främmande nyckelattribut när vi drar relationer från en primär tabell till en refererad tabell. Detta brukar vara bra, men inte här. Vi har redan attribut som representerar främmande nycklar. Vad vi saknar är "riktiga" relationer mellan tabeller. För att stänga av det här alternativet klickar du på "Mitt konto" i toppmenyn och hitta "Personliga inställningar" avsnitt.
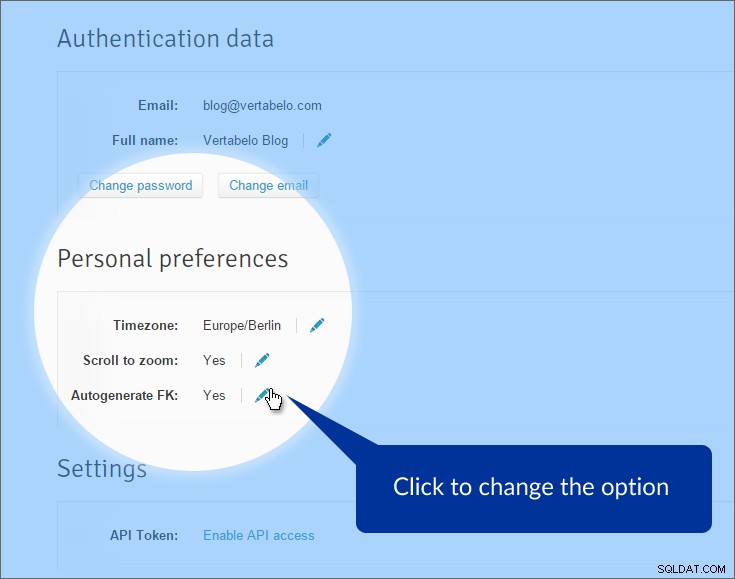
Alternativet är avstängt. När vi nu ritar en referenslinje mellan tabeller skapas linjen – men vi måste ange vilka attribut som används, både på den primära och främmande sidan.
Steg 2. Gruppera prefixerade tabeller med ämnesområden
Låt oss sedan gruppera några tabeller. Vi gör detta med hjälp av Ämnesområdet verktyg som låter associera tabeller baserat på utvalda kriterier. I vårt fall försöker vi identifiera tabeller som antingen är relaterade eller en del av samma process. Detta kommer att resultera i grupper som "Samtal", "Möte" och "Kampanjer".
Vi kan skapa ett ämnesområde genom att klicka på "Lägg till nytt område" ikonen i verktygslådan:
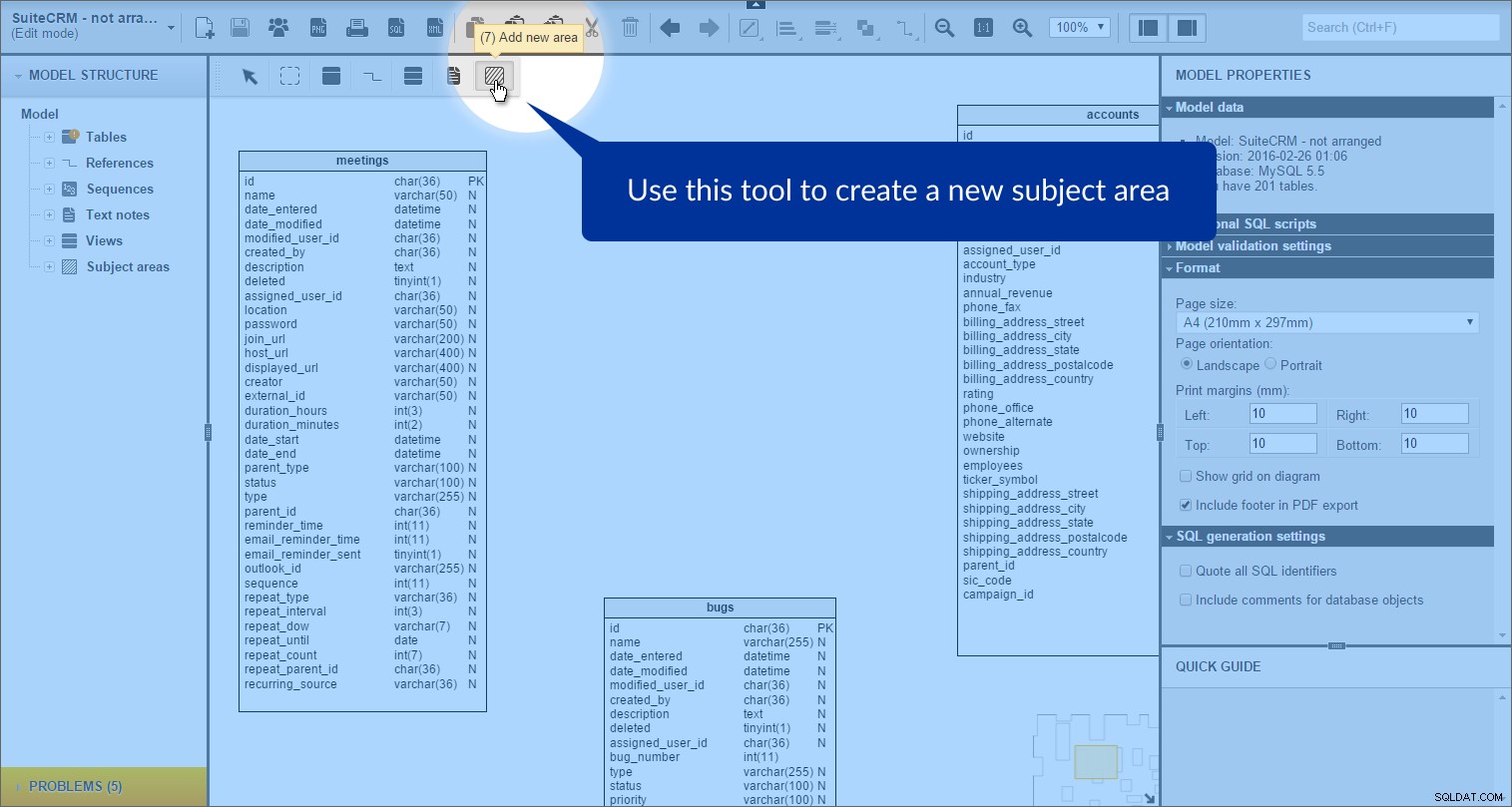
och sedan rita en rektangel på vår modell:
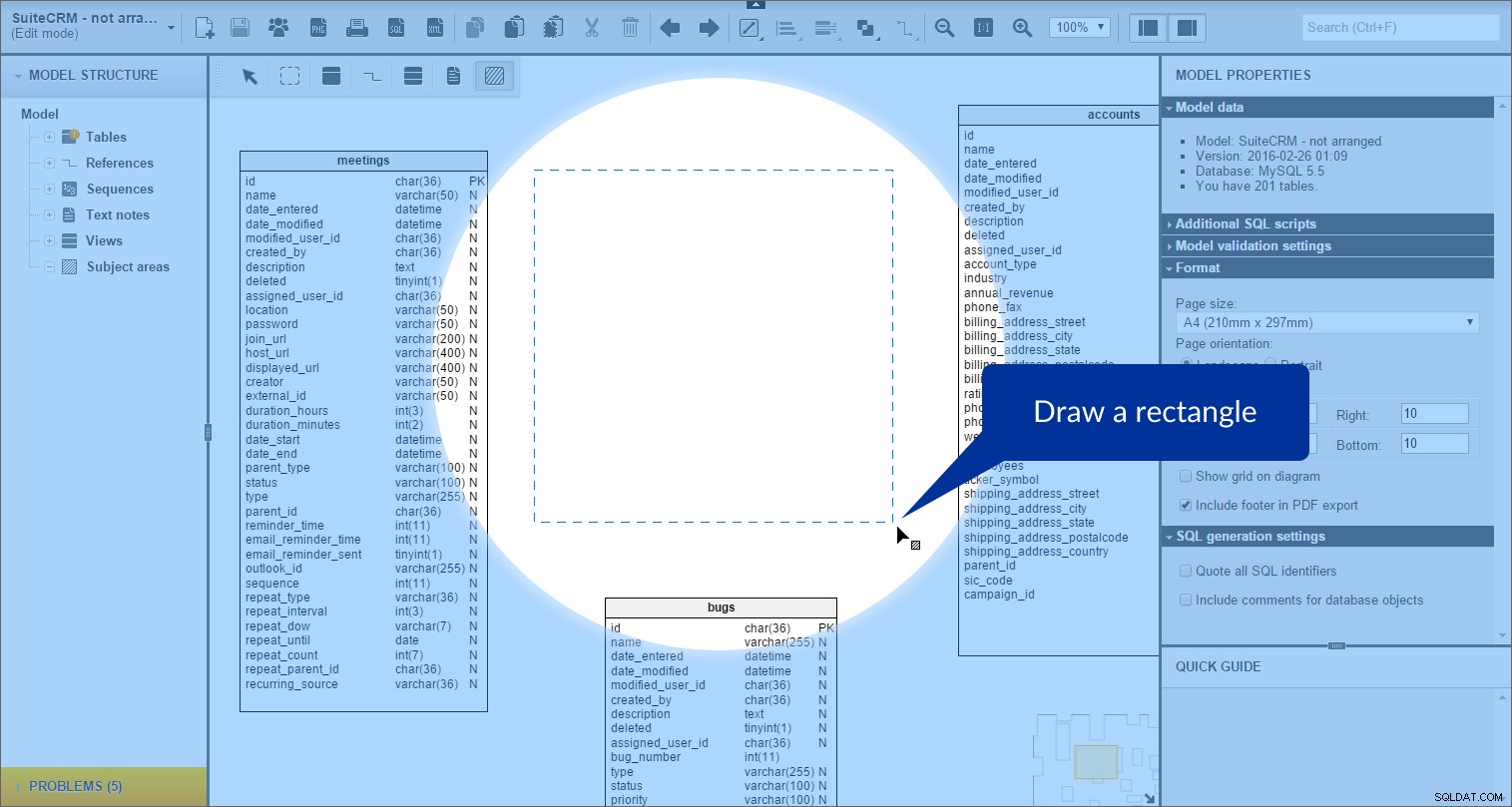
Ämnesområdet skapas. Vi kan se det i "Modellstruktur" panel till vänster:
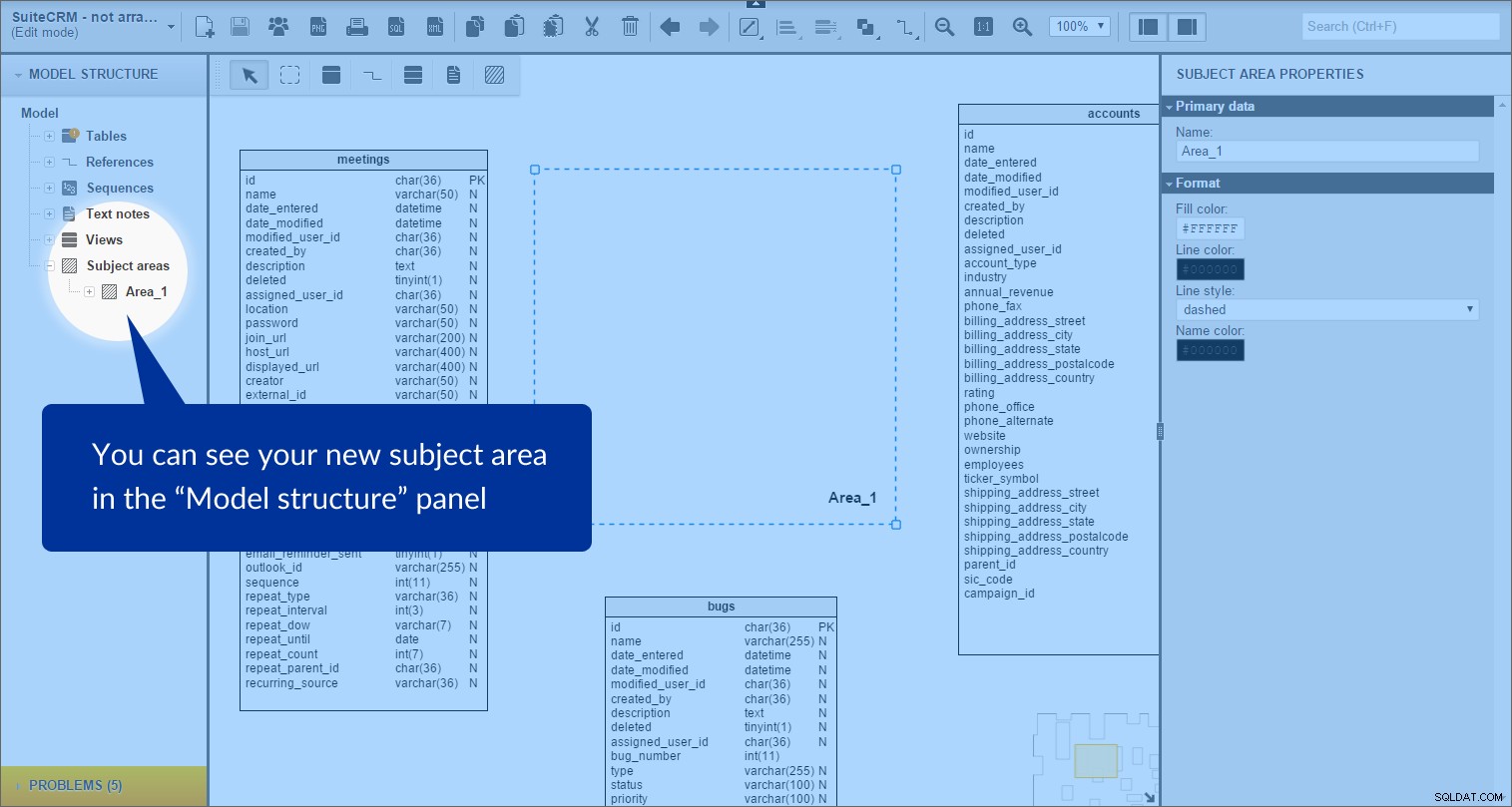
Varje ämnesområde innehåller en lista över alla objekt som finns innanför dess gränser; i det här fallet är det tabeller och referenstyper.
I SuiteCRM finns det många tabeller som delar ett gemensamt prefix. Så jag började gruppera de prefixerade tabellerna tillsammans. Ta en titt på "acl"-tabellerna som ett exempel. I panelen "Modelstruktur" hittade jag alla tabeller vars namn började med "acl_":
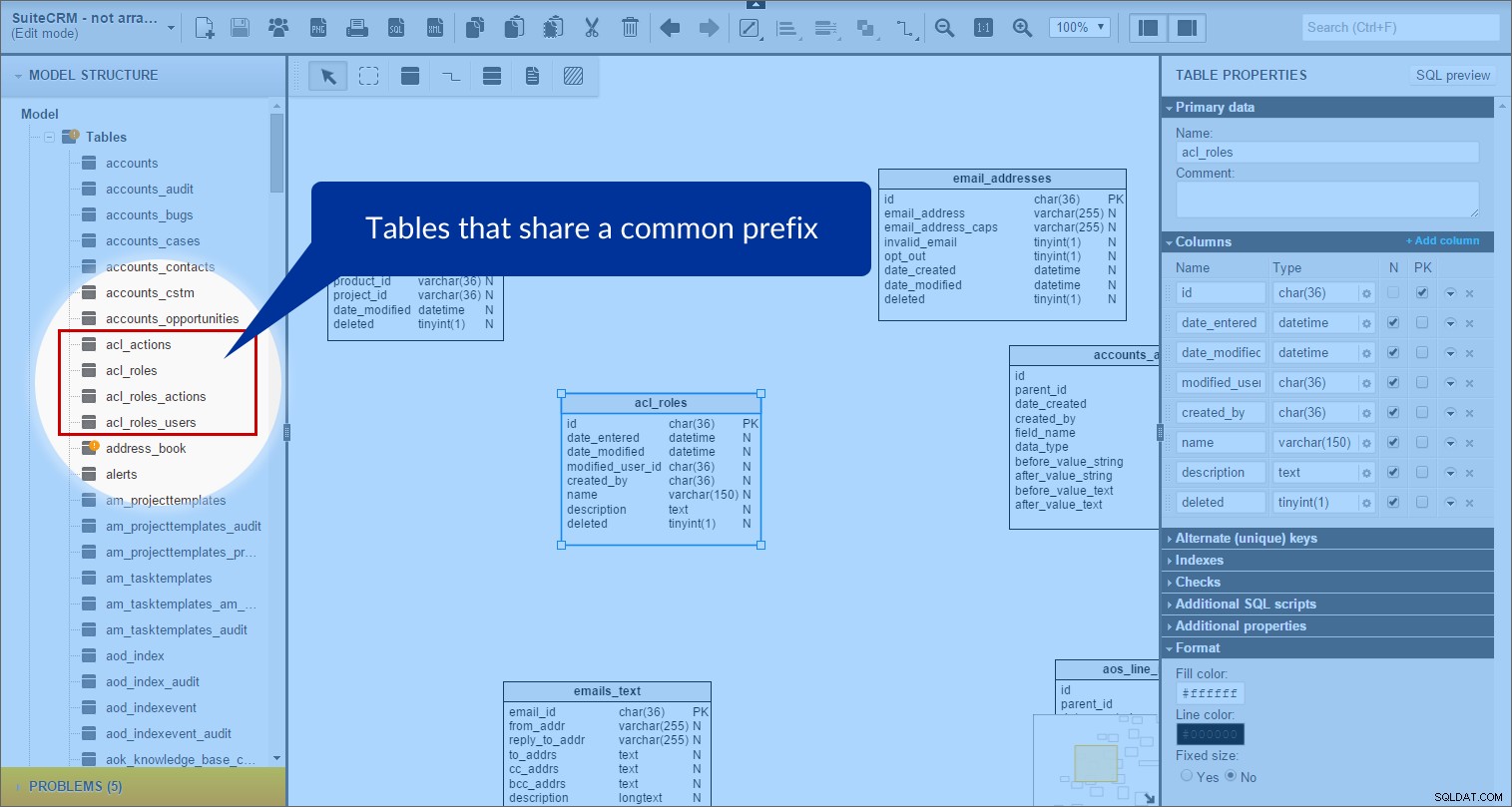
Sedan skapade jag ämnesområdet "acl" i modellen och drog in alla lämpliga tabeller i det. (För bättre synlighet ställer jag in bakgrundsfärgen till lila.)
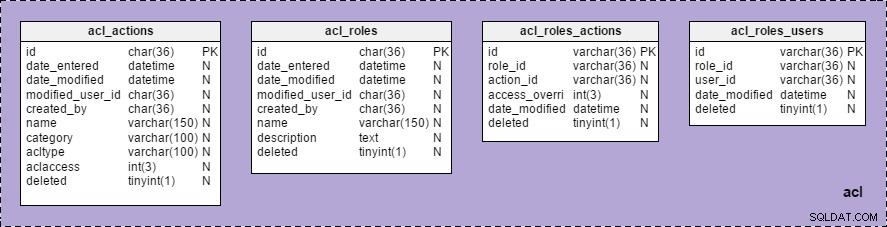
Nu kan vi nu se "acl"-gruppen, med en lista över alla tabeller som hör till den, under "Ämnesområden" i "Modellstruktur" :
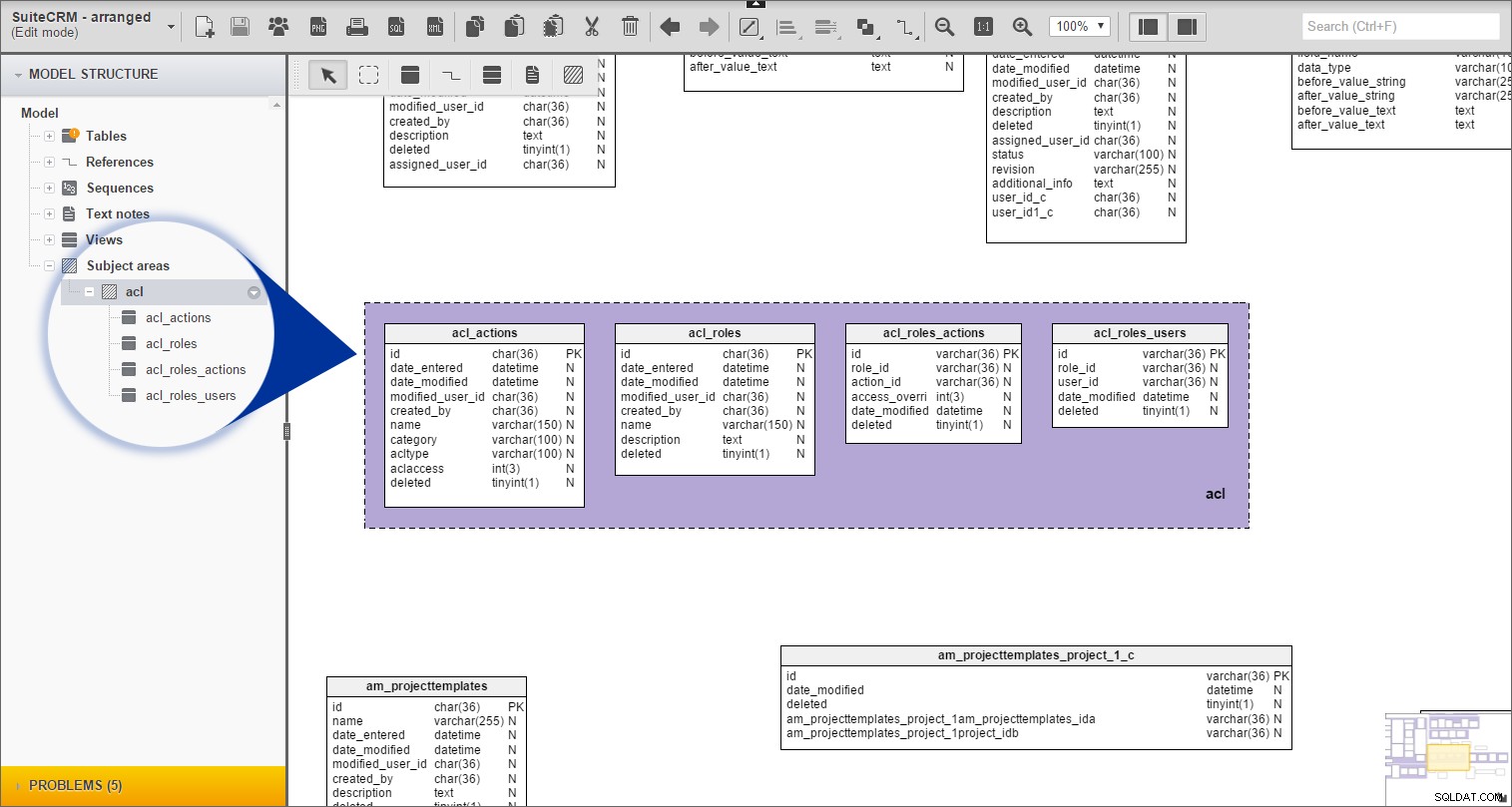
Jag upprepade samma procedur för alla återstående tabeller med prefix.
Steg 3:Ordna de återstående borden.
Samma tabell två gånger i diagrammet? Tabellgenvägar!
Det finns cirka 80 tabeller med prefix. Efter att ha grupperat dem stod jag kvar med cirka 120 "vilda" bord. Dessa är meningsfulla:de lagrar information om användare, kunder, samtal, möten och andra CRM-grejer. Det är mycket information som ska vara fri, så låt oss sortera dessa tabeller.
Den funktion som jag tyckte var mest användbar för att arrangera dessa tabeller kallas tabellgenvägar . Ibland vill du använda samma tabell mer än en gång i en modell. (Varför? För att platta till modellen och undvika överlappning.) Vi kan enkelt göra detta genom att använda "Kopiera" och "Klistra in som genväg" knappar.
Välj bara tabellen som du vill skapa en genväg för och klicka på "Kopiera" i det övre verktygsfältet (eller tryck på Ctrl + C ):
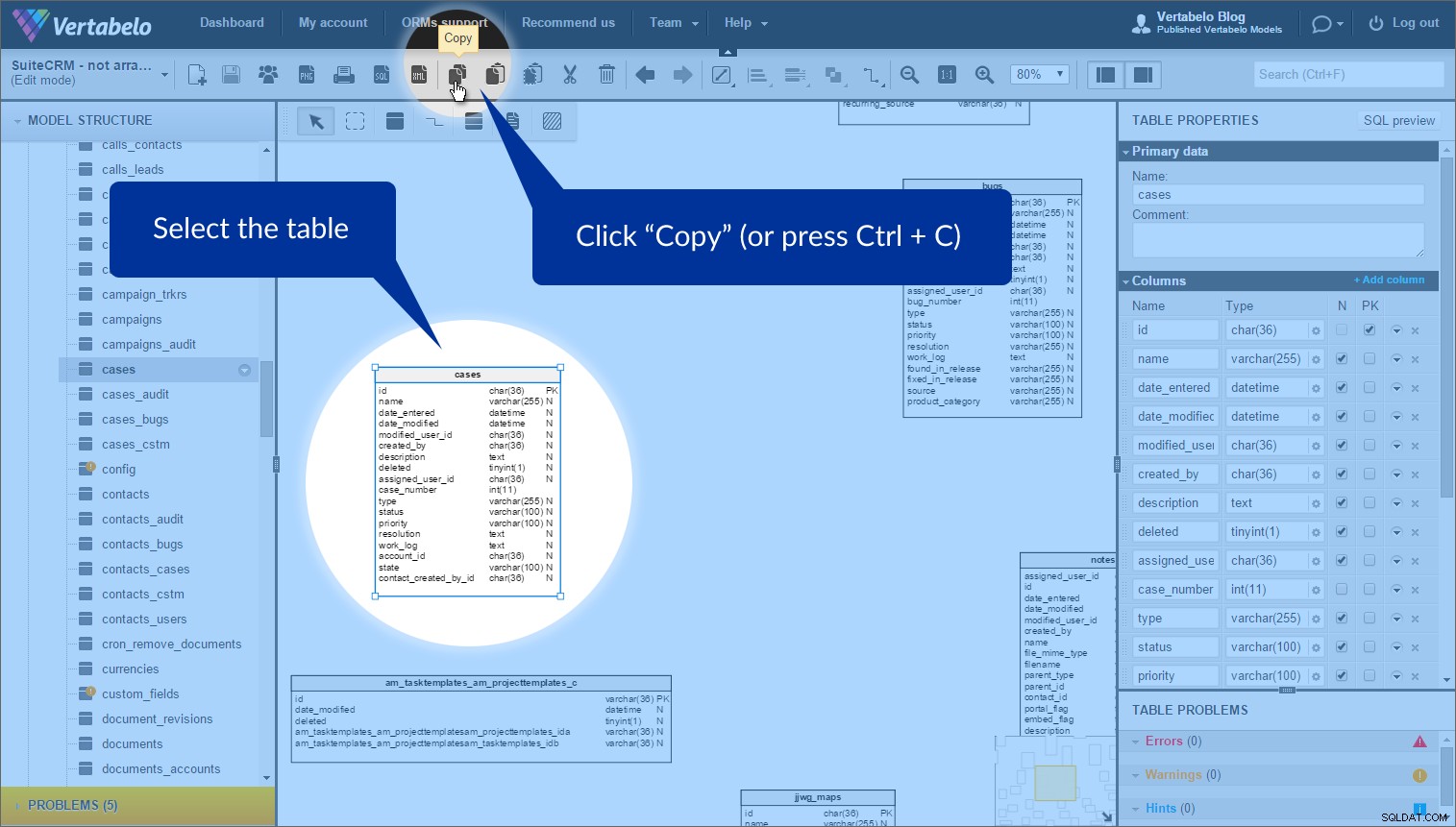
För att skapa en genväg klickar du på "Klistra in som genväg" (eller tryck på Ctrl + K ). Därefter visas en ny tabell med en prickad kontur:
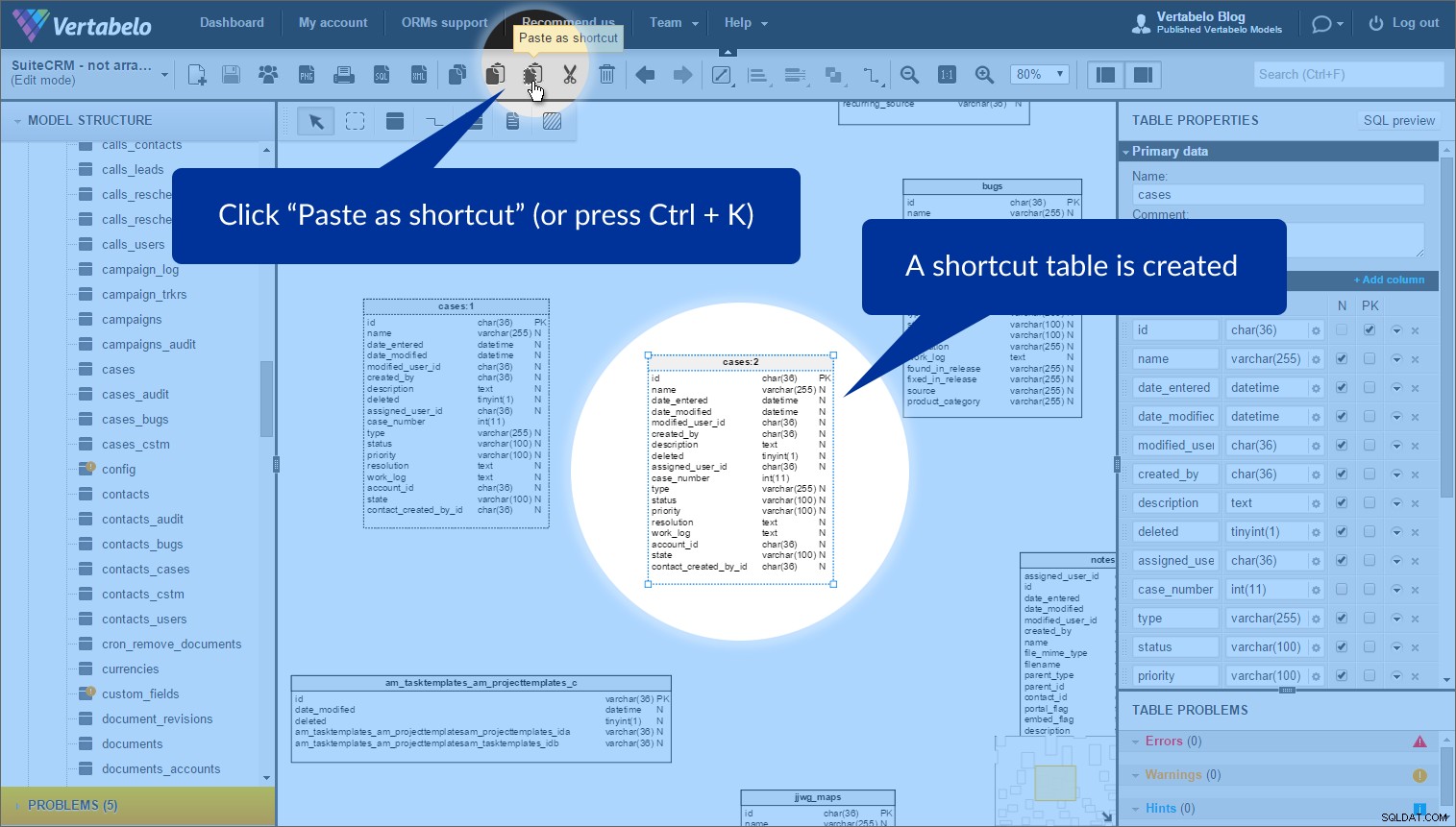
Detta är inte en kopia av tabellen, men en annan instans av den ursprungliga tabellen. Vi kan placera den var som helst i vår modell. Jag använde instanser av samma tabell i olika ämnesområden för att undvika överlappande referenser. Det är värt att nämna att varje tabellinstans har ett tilldelat ämnesområdesnamn (bredvid namnet) medan det är inom ämnesområdet.
Ett bra exempel på hur detta fungerar är users tabell. Den finns i "Användare och konton", "Roller", "Dokument" och andra ämnesområden. Vi kommer att se detta senare i modellen.
Jag använder tabellgenvägar i stor utsträckning när jag skapar ämnesområden med etablerade relationer mellan tabeller. För att se hur detta fungerar, titta på ämnesområdet "Möjligheter" som beskrivs nedan. Lägg märke till att alla tabeller inom det ämnesområdet namnges enligt denna regel:{tabellnamn} :{ämnesområdesnamn} .
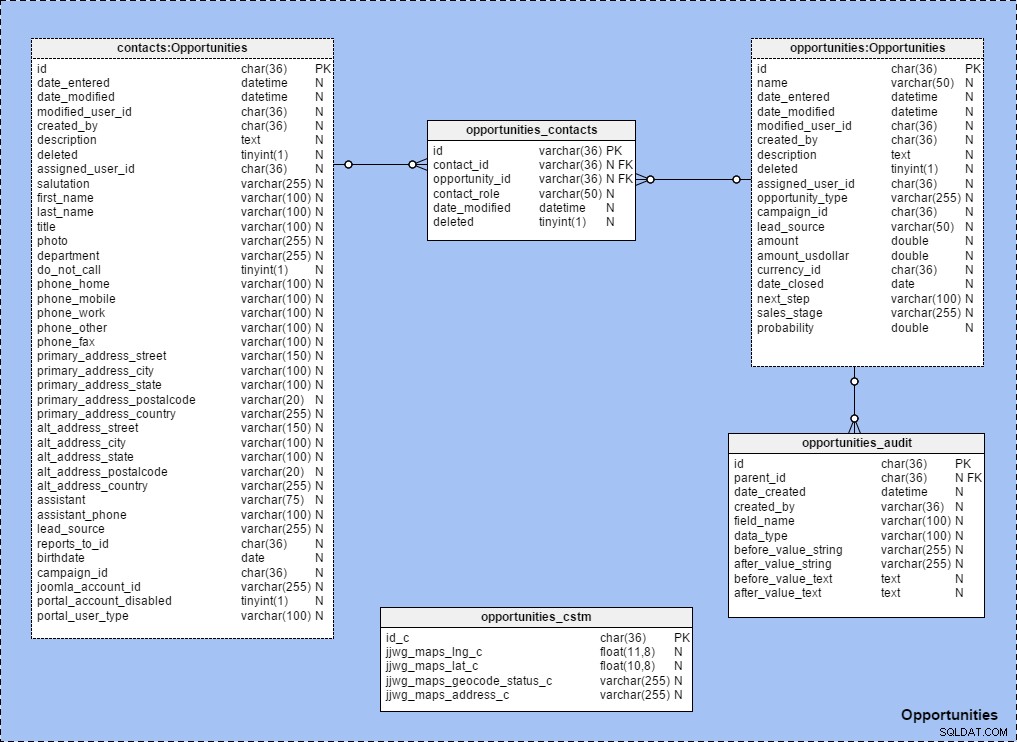
När vi utökar {ämnesområdets namn} i panelen "Modelstruktur" kan vi tydligt se att den innehåller tabeller och referenser:
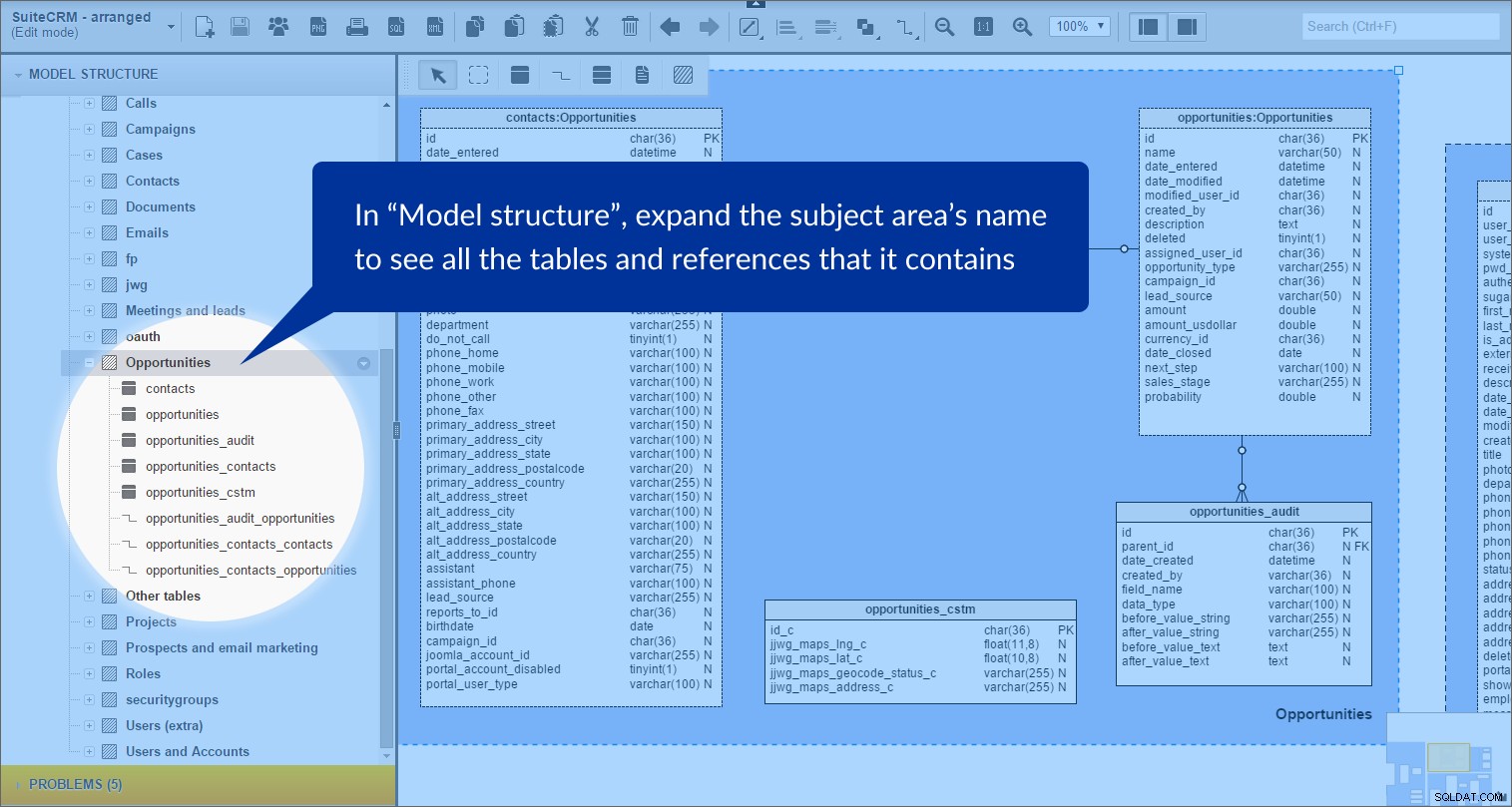
Jag gjorde detta för följande ämnesområden:"Samtal", "Ärenden", "Kampanj", "Kontakter", "Dokument", "Möte och potentiella kunder", "oauth", "Projekt", "Prospekt och e-postmarknadsföring", "Roller" och "Användare och konton". Alla dessa områden delar en ljusblå bakgrund.
De återstående tabellerna är grupperade baserat på deras namn och förmodade betydelse:"E-postmeddelanden", "Användare (extra)" och "Övriga tabeller". Dessa grupper har sin bakgrundsfärg inställd på ljusröd.
När du dubbelklickar på ett tabellnamn i navigeringsträdet, zoomar vyn till den tabellen i modellen och väljer den. När du zoomar in genom att rulla på mushjulet, zoomar vyn i muspekarens riktning.Den arrangerade modellen
Jag använde de tidigare beskrivna alternativen för att platta till modellen så mycket som möjligt samtidigt som jag grupperade tabeller logiskt. Resultatet är 26 ämnesområden, varav vissa endast innehåller tabeller medan andra har tabeller och relationer. Låt oss ta en snabb genomgång av varje kategori:
Ämnesområden som innehåller tabeller och relationer:
"Samtal", "Kampanjer", "Ärenden", "Kontakter", "Dokument", "Möten och potentiella kunder", "Möjligheter", "Projekt", "Prospekt och e-postmarknadsföring", "Roller", "Användare och konton"
Alla relationer är satta som icke-obligatoriska. Detta behåller informationen om att dessa tabeller är relaterade och via vilka attribut(er).
Ämnesområden som endast innehåller tabeller:
“acl”, “am”, “aod”, “aok”, “aop”, “aor”, “aos”, “aow”, “E-post”, “fp”, “jwg”, “oauth”, “security_groups ”, ”Användare extra”
Detta betyder inte att relationer inte existerar här; de betonas helt enkelt inte.
Ämnesområdet "Andra tabeller" är för tabeller som inte riktigt passar in i en specifik grupp.
Hur ser modellen ut?
Den omarrangerade modellen ser ut så här:
Uppenbarligen har en namnkonvention använts. Här är en översikt över de riktlinjer vi följde:
- Tabellnamn är oftast plural:
users,contracts,folders,roles,tasks. Vissa tabellnamn är singular, till exempelproject. - Primärnyckeln i de flesta tabeller kallas helt enkelt
idoch är av typen char(36). - När en en-till-många-relation uppstår, heter den främmande nyckeln vanligtvis
parent_id. (Exempel:contacts_audit.parent_idär en referens tillcontacts.id.) - I många-till-många-relationer, "
parent_id" kan inte användas som namn för flera kolumner. Istället används ett singulart tabellnamn med suffixet "_id". (Exempel:contacts_bugs.bug_idär referens tillbug.id.) - Det finns situationer när samma kolumn används som en främmande nyckel för flera tabeller. (Exempel:
calls.parent_idrefereras till id-kolumnen i var och en av följande tabeller:accounts,bugs,cases,contacts,leads,tasks,opportunities and prospects. Jag har inte kontrollerat värdena i databasen, men min gissning skulle vara att det inte finns samma nyckelvärden i dessa tabeller. Eftersom alla är av typen char(36), används förmodligen någon kombination av tabellnamn och autoinkrement. Vi kommer att kontrollera det i kommande artiklar.) - Vi använder samma namn för kolumner som har samma betydelse i olika tabeller. (Exempel:
modified_user_id,created_byochassigned_user_idfinns i många tabeller i modellen. Alla hänvisas tillusers.id.)
Vad är nästa steg?
I de kommande artiklarna kommer vi att använda SuiteCRM GUI och hålla ett öga på de förändringar som detta orsakar i databasen. Med den informationen kommer vi att försöka göra ändringar i modellen, omorganisera ämnesområden och skapa kopplingar där det behövs. Vi kommer också att leta efter andra SuiteCRM-specifika regler, till exempel hur primärnycklar genereras.
Att hantera stora databasdiagram är aldrig ett lätt jobb. Som att bygga en bra grund för ett hem, kommer att lägga mer tid på grunderna nu ge fördelar senare. Om vi vill analysera modeller som den bakom SuiteCRM, att analysera innan vi har organiserat modellstrukturen och definierat tabellrelationer är att göra det på Sisyphus-stil.