Introduktion
En Eager Index Spool läser alla rader från sin underordnade operatör till en indexerad arbetstabell, innan den börjar returnera rader till sin överordnade operatör. I vissa avseenden är en ivrig indexrulle det ultimata förslaget om saknade index , men det rapporteras inte som sådant.
Kostnadsbedömning
Att infoga rader i ett indexerat arbetsbord är relativt billigt, men inte gratis. Optimeraren måste tänka på att arbetet sparar mer än det kostar. För att det ska fungera till spolens fördel måste planen beräknas förbruka rader från spolen mer än en gång. Annars kan den lika gärna hoppa över spolen och bara göra den underliggande operationen den gången.
- För att nås mer än en gång måste spolen visas på insidan av en kapslad loops join-operator.
- Varje iteration av slingan bör söka till ett speciellt indexspoolnyckelvärde som tillhandahålls av slingans yttre sida.
Det betyder att anslutningen måste vara en ansökan , inte en kapslad loop-anslutning . För skillnaden mellan de två, se min artikel Apply versus Nested Loops Join.
Anmärkningsvärda funktioner
Medan en ivrig indexspole bara kan visas på insidan av en kapslad slinga applicera , det är inte en "prestationsspole". En ivrig indexspole kan inte inaktiveras med spårningsflagga 8690 eller NO_PERFORMANCE_SPOOL frågetips.
Rader som infogas i indexrullen är normalt inte försorterade i indexnyckelordning, vilket kan resultera i indexsiddelning. Odokumenterad spårningsflagga 9260 kan användas för att generera en Sortering operatören före indexspolen för att undvika detta. Nackdelen är att den extra sorteringskostnaden kan avskräcka optimeraren från att över huvud taget välja spolalternativet.
SQL Server stöder inte parallella insättningar till ett b-trädindex. Det betyder att allt under en parallell ivrig indexspole löper på en enda tråd. Operatörerna under spolen är fortfarande (vilseledande) markerade med parallellitetsikonen. En tråd är vald att skriva till spolen. De andra trådarna väntar på EXECSYNC medan det är klart. När spoolen är fylld kan den läsas från med parallella trådar.
Indexspolar berättar inte för optimeraren att de stöder utdata ordnade efter spoolens indexnycklar. Om sorterad utdata från spolen krävs kan du se en onödig Sortering operatör. Ivriga indexspolar bör ofta ersättas av ett permanent index ändå, så detta är ett mindre bekymmer mycket av tiden.
Det finns fem optimeringsregler som kan generera en Eager Index Spool alternativ (känt internt som ett index on-the-fly ). Vi kommer att titta på tre av dessa i detalj för att förstå var ivriga indexspolar kommer ifrån.
SelToIndexOnTheFly
Detta är den vanligaste. Den matchar ett eller flera relationsval (a.k.a filter eller predikat) precis ovanför en dataåtkomstoperator. SelToIndexOnTheFly regeln ersätter predikaten med ett sökpredikat på en ivrig indexspole.
Demo
Ett AdventureWorks exempel på en databas visas nedan:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%';
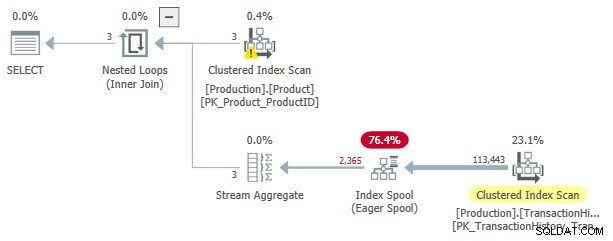
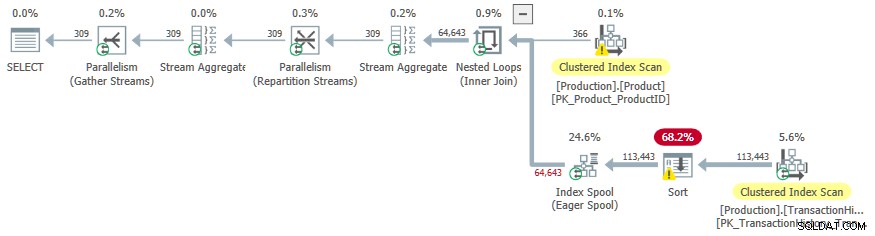
Denna genomförandeplan har en uppskattad kostnad på 3,0881 enheter. Några intressanta platser:
- The Nested Loops Inner Join operatör är en apply , med
ProductIDochSafetyStockLevelfrånProducttabell som yttre referenser . - På den första iterationen av appliceringen, Ivrig Index Spool är helt ifylld från Clustered Index Scan i
TransactionHistorytabell. - Spolens arbetstabell har ett klustrat index inskrivet på
(ProductID, Quantity). - Rader som matchar predikaten
TH.ProductID = P.ProductIDochTH.Quantity < P.SafetyStockLevelbesvaras av spolen med hjälp av dess index. Detta gäller för varje iteration av appliceringen, inklusive den första. TransactionHistorytabellen skannas bara en gång.
Sorterad indata till spoolen
Det är möjligt att framtvinga sorterad input till den ivriga indexspolen, men detta påverkar den uppskattade kostnaden, som noterades i inledningen. För exemplet ovan ger aktivering av flaggan för odokumenterad spårning en plan utan en spole:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%'
OPTION (QUERYTRACEON 9260);
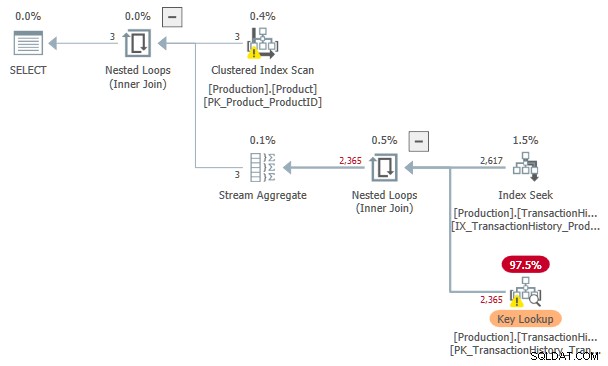
Den beräknade kostnaden för denna Indexsökning och Nyckelsökning planen är 3,11631 enheter. Detta är mer än kostnaden för planen med enbart en indexspole, men mindre än planen med en indexspole och sorterad indata.
För att se en plan med sorterad input till spolen måste vi öka det förväntade antalet loop-iterationer. Detta ger spolen en chans att betala tillbaka den extra kostnaden för Sorteringen . Ett sätt att utöka antalet förväntade rader från Product tabellen är att göra Name predikat mindre restriktivt:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'[A-P]%'
OPTION (QUERYTRACEON 9260); Detta ger oss en exekveringsplan med sorterad input till spoolen:
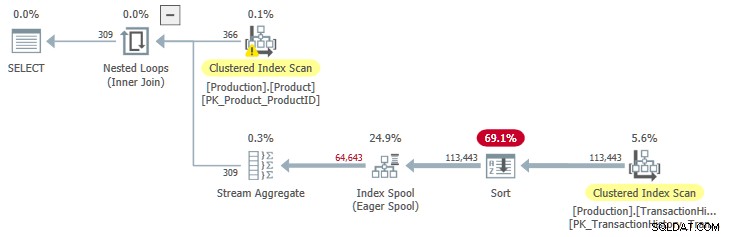
JoinToIndexOnTheFly
Denna regel omvandlar en inre koppling till en ansöka , med en ivrig indexspole på insidan. Minst ett av sammanfogningspredikaten måste vara en olikhet för att denna regel ska matchas.
Detta är en mycket mer specialiserad regel än SelToIndexOnTheFly , men tanken är ungefär densamma. I det här fallet associeras urvalet (predikatet) som omvandlas till en indexspoolsökning med kopplingen. Omvandlingen från gå med till applicera gör att sammanfogningspredikatet kan flyttas från själva sammanfogningen till insidan av appliceringen.
Demo
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN);
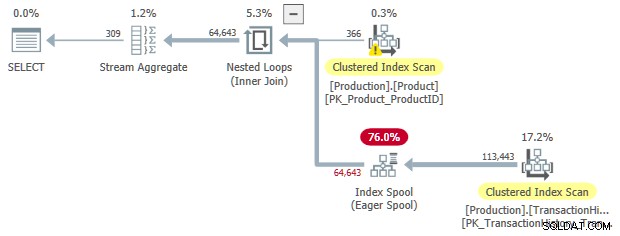
Som tidigare kan vi begära sorterad input till spoolen:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN, QUERYTRACEON 9260);
Den här gången har den extra kostnaden för sortering uppmuntrat optimeraren att välja en parallell plan.
En ovälkommen bieffekt är Sortera operatör spill till tempdb . Det totala minnesanslaget som är tillgängligt för sortering är tillräckligt, men det är jämnt fördelat mellan parallella trådar (som vanligt). Som nämnts i inledningen stöder inte SQL Server parallella infogningar till ett b-trädindex, så operatorerna under den ivriga indexspolen körs på en enda tråd. Den här enstaka tråden får bara en bråkdel av minnesanslaget, så Sortera spill till tempdb .
Denna bieffekt är kanske en anledning till att spårningsflaggan är odokumenterad och inte stöds.
SelSTVFToIdxOnFly
Den här regeln gör samma sak som SelToIndexOnTheFly , men för en strömningstabellvärderad funktion (sTVF) radkälla. Dessa sTVF:er används i stor utsträckning internt för att implementera DMV:er och DMF:er bland annat. De visas i moderna utförandeplaner som Table Valued Function operatorer (ursprungligen som fjärrtabellskanningar ).
Tidigare kunde många av dessa sTVF:er inte acceptera korrelerade parametrar från en apply. De kunde acceptera bokstaver, variabler och modulparametrar, bara inte tillämpa yttre referenser. Det finns fortfarande varningar om detta i dokumentationen, men de är något inaktuella nu.
Hur som helst, poängen är att det ibland inte är möjligt för SQL Server att klara en apply yttre referens som en parameter till en sTVF. I den situationen kan det vara vettigt att materialisera en del av sTVF-resultatet i en ivrig indexspole. Den nuvarande regeln ger den förmågan.
Demo
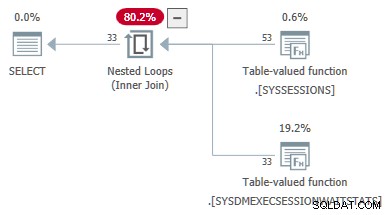
Nästa kodexempel visar en DMV-fråga som framgångsrikt konverterats från en koppling till en apply . Ytre referenser skickas som parametrar till den andra DMV:
-- Transformed to an apply
-- Outer reference passed as a parameter
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id = DES.session_id
OPTION (FORCE ORDER);
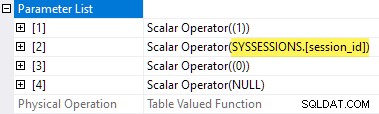
Planegenskaperna för väntestatistiken TVF visar ingångsparametrarna. Det andra parametervärdet tillhandahålls som en yttre referens från sessionerna DMV:
Det är synd att sys.dm_exec_session_wait_stats är en vy, inte en funktion, eftersom det hindrar oss från att skriva en ansöka direkt.
Omskrivningen nedan är tillräckligt för att besegra den interna konverteringen:
-- Rewrite to avoid TVF parameter trickery
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id >= DES.session_id
AND DESWS.session_id <= DES.session_id
OPTION (FORCE ORDER);
Med session_id predikat som nu inte används som parametrar, SelSTVFToIdxOnFly regeln är gratis att konvertera dem till en ivrig indexspole:
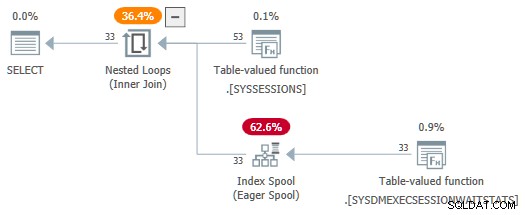
Jag vill inte ge dig intrycket av att det behövs knepiga omskrivningar för att få en ivrig indexspole över en DMV-källa – det gör bara en enklare demo. Om du råkar stöta på en fråga med DMV-anslutningar som producerar en plan med en ivrig spole, vet du åtminstone hur den kom dit.
Du kan inte skapa index på DMV, så du kan behöva använda en hash eller merge join om exekveringsplanen inte fungerar tillräckligt bra.
Rekursiva CTE
De återstående två reglerna är SelIterToIdxOnFly och JoinIterToIdxOnFly . De är direkta motsvarigheter till SelToIndexOnTheFly och JoinToIndexOnTheFly för rekursiva CTE-datakällor. Dessa är extremt sällsynta enligt min erfarenhet, så jag kommer inte att tillhandahålla demos för dem. (Bara så att Iter en del av regelnamnet är vettigt:Det kommer från det faktum att SQL Server implementerar svansrekursion som kapslad iteration.)
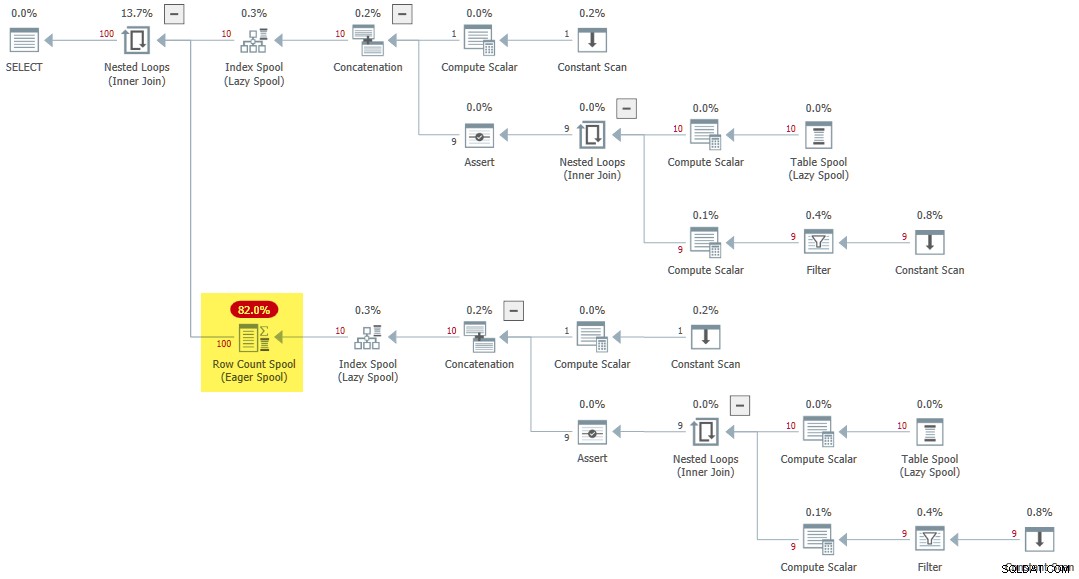
När en rekursiv CTE refereras flera gånger på insidan av en tillämpas en annan regel (SpoolOnIterator ) kan cachelagra resultatet av CTE:
WITH R AS
(
SELECT 1 AS n
UNION ALL
SELECT R.n + 1
FROM R
WHERE R.n < 10
)
SELECT
R1.n
FROM R AS R1
CROSS JOIN R AS R2; Utförandeplanen innehåller en sällsynt Eager Row Count Spool :
Slutliga tankar
Ivriga indexspolar är ofta ett tecken på att ett användbart permanent index saknas i databasschemat. Detta är inte alltid fallet, som exemplen på funktionsvärden för streamingtabeller visar.