Det finns mycket att tänka på när du designar en databas, och väldigt få av oss kan komma ihåg alla värdefulla tips och knep vi har lärt oss. Så låt oss ta en titt på några onlineresurser som innehåller databasdesigntips och bästa praxis. När vi går kommer jag att dela mina egna åsikter om de idéer som presenteras, baserat på min erfarenhet av databasdesign.
Uppenbarligen är den här artikeln inte en uttömmande lista, men jag har försökt granska och kommentera ett tvärsnitt av källor. Förhoppningsvis hittar du den information som bäst passar dina behov och mål.
Som en sidoanteckning blev jag förvånad över att finna att många artiklar relaterade till databasdesignpraxis hade väldigt få exempel; onlineresurserna som jag granskade för artikeln om fel och misstag hade en högre andel av dem. Denna brist är en nackdel, eftersom exempel är oerhört viktiga för att få fram poängen.
Databastips för erfarna designers
Låt oss först börja med källor som innehåller avancerade tips om databasdesign och bästa praxis. Dessa är för designers som redan arbetar med datamodellering och har varit det ett tag. Vissa artiklar är inriktade på en mer mellanliggande nivå, men om de diskuterar avancerade koncept har jag tagit med dem i den här listan.
Databasriktlinjer (RDBMS/SQL)
av Steve Djajasaputra | SOA, Java, mjukvaruutveckling – BlogSpot | 16 januari 2013
Den här artikeln från Mr. Djajasaputra är ganska imponerande:han listar många tips för schemat, index och vyer; han ger också en ganska detaljerad namnkonvention. Och hans tips fortsätter (och fortsätter). Bredden är imponerande, men det finns nästan inga exempel. Vissa av hans poänger kan anses diskuteras, men överlag är detta en mycket solid presentation.
I synnerhet blev jag imponerad av att han ger en exakt regel om att använda naturliga kontra artificiella (d.v.s. surrogat eller genererade) primärnycklar. Han håller detta snyggt och enkelt, och anger att vi ska föredra en naturlig nyckel eftersom den är meningsfull. Han ger också riktlinjer för bästa användning av en konstgjord nyckel – specifikt när den naturliga nyckeln inte är unik eller när du behöver ändra värdet på den naturliga nyckeln. Med hans egna ord:
Föredrar först att använda den naturliga nyckeln eftersom den är mer meningsfull och för att undvika dupliceringar (återanvänd befintlig kolumn). Men det finns fall när du behöver en konstgjord nyckel:när den naturliga nyckeln inte är unik (t.ex. namn) eller om du behöver ändra värdet.Eftersom hans lista med tips är så lång kan jag inte tänka mig att komma ihåg dem alla. Men varje avsnitt kan refereras till när du arbetar med databasdesign, prestanda, lagrade procedurer och versionshantering. Det finns också ett avsnitt om Oracle-specifika punkter som skulle vara användbart om du arbetar med eller planerar att stödja Oracle.
Sammantaget är detta en mycket värdefull och omfattande resurs.
9 tips för bättre databasdesign
av Jeffrey Edison | Vertabelo blogg | 22 september 2015
Jag kommer att ägna mig åt lite självreklam här.
Den här artikeln med 9 tips för bättre databasdesign är baserad på min erfarenhet som designer och arkitekt. Jag hittade också ytterligare insikter från att undersöka andras bästa metoder för databasdesign.
Min lista representerar några av huvudproblemen som kan hända när man arbetar med datamodeller. Jag organiserade tipsen i den ordning de inträffar under projektets livscykel (snarare än efter betydelse eller hur ofta de dyker upp) eftersom det skulle vara mest användbart, åtminstone enligt min uppfattning. Läsare kan följa denna checklista med bästa praxis genom ett projekts livscykel.
Från artikeln:
För att parafrasera Al Capone (eller John Van Buren, son till den 8:e amerikanska presidenten), "testa tidigt, testa ofta". På så sätt följer du den kontinuerliga integrationens väg. Att testa i ett tidigt utvecklingsskede sparar tid och pengar. Vid testning av databasen bör målet vara att simulera en produktionsmiljö:"A Day in the Life of the Database". Vilka volymer kan förväntas? Vilka användarinteraktioner är troliga? Handläggs gränsärendena?Genom att uppmärksamma dessa tips har jag funnit att databaser blir bättre designade och mer robusta. Även om ingen av dessa aktiviteter kommer att ta enormt lång tid, kan var och en ha en enorm inverkan på kvaliteten på din datamodell.
Jag hoppas att min lista med tips är användbar för mellanliggande och avancerade designers.
20 bästa metoder för databasdesign
av Cagdas Basaraner | Kodbalans – BlogSpot | 24 juli 2011
Mr. Basaraner presenterar en intressant lista med 20 bästa metoder för databasdesign. Jag hade föredragit om han hade grupperat några av dessa; till exempel kan de fyra första punkterna alla täckas under "Använd goda namnkonventioner".
Dessutom säger han att det är en bästa praxis att använda ett syntetiskt genererat (heltals) ID som primärnyckel för alla tabeller. I själva verket är detta fortfarande ett omdebatterat ämne, med argument för och emot. Några av hans bästa metoder är ganska generiska, som "För ... uppdragskritiker [sic] databassystem, använd katastrofåterställning och säkerhetstjänst ..." Jag håller inte med om denna punkt, men den är på mycket hög nivå.
På plussidan var den här artikeln en av de få som nämner användningen av ett ramverk för objektrelationell kartläggning (ORM). Vissa kommentatorer höll inte med om hur tipset formulerades, men åtminstone att använda ett ORM-ramverk nämns:
Använd ett ORM-ramverk (object relational mapping) (dvs Hibernate, iBatis ...) om applikationskoden är tillräckligt stor. Prestandaproblem för ORM-ramverk kan hanteras av detaljerade konfigurationsparametrar.Ändå kunde den här listan ha förbättrats. Den bör tydligt identifiera punkter som bara är specifika för en del databashanteringssystem (till exempel SQL Server). Exakt statistik om prestanda, heuristik eller vikten av att lägga tid på design snarare än på underhåll och omdesign skulle ha varit bra. Fler exempel behövdes också, men det är ett problem för de flesta av dessa artiklar.
Om du arbetar med SQL Server, överväger att använda ett ORM-ramverk eller behöver en punktlista med tips snarare än en lång och detaljerad artikel, då är den här artikeln för dig.
(Obs:den här artikeln dök också upp på flera andra webbplatser, inklusive CodeBuild, Java Code Geeks och DZone.)
Databasdesign Essentials. 10 saker du absolut behöver göra
av Michelle A. Poolet | SQL Server Pro | 1 mars 2011
En del av Ms. Poolets tips är ganska standard och kan hittas i många andra resurser, men det finns några ganska ovanliga punkter också. Bland hennes allmänna poänger främjar hon användningen av undertyper och supertyper (vilket jag starkt håller med om) eftersom detta speglar objektorienterad design och lätt kan förstås av utvecklare. Från hennes artikel:
Var inte rädd för att inkludera supertyp- och subtypenheter i din design i CDM och framåt. Undertyperna representerar klassificeringar eller kategorier av supertypen... Entiteter representeras som undertyper när det krävs mer än ett enda ord eller en fras för att kategorisera entiteten.
Om en kategori har ett eget liv, med separata attribut som beskriver hur kategorin ser ut och beter sig och separata relationer med andra entiteter, då är det dags att anropa supertyp/subtypstrukturen . Underlåtenhet att göra det kommer att hindra en fullständig förståelse av data och affärsregler som driver datainsamling.
Vissa av hennes kommentarer hänvisar specifikt till MS SQL Server även om kommentarerna faktiskt är allmänna frågor. En huvudpoäng som Ms. Poolet tar upp är mycket SQL Server-specifik:"Butikskod som rör en databas data som en lagrad procedur".
Detta är bra om du bara planerar att stödja ett enda databashanteringssystem, som SQL Server. Men för bärbara implementeringar skulle detta inte vara ett bra råd. Generellt designar jag för portabilitet till minst två ledningssystem med olika språkstöd för lagrade förfaranden. Därför skulle jag undvika denna praxis.
Den här artikeln är mest användbar för personer som utvecklar för SQL Server och fokuserar på den amerikanska marknaden (snarare än ett internationellt system). Som amerikan som bor utomlands fann jag dock att några av hennes exempel är lite för "USA-centrerade". Till exempel kanske en icke-amerikan inte förstår vad en Zip+4 domän är och skulle därför inte ha någon förståelse för varför en denna domän ska ha en INTE NULL-egenskap.
För att illustrera detta gjorde jag en datamodell för båda amerikanska icke-amerikanska adresser. Vi antar att vår datamodell kan kräva att enheter är länkade till mer än en adress:till exempel en för fakturering, en för frakt. Den första adressen skulle vara associerad med en betalningsmetod; i det här fallet skulle adressen användas för att verifiera din rätt att godkänna den betalningen. Leveransadressen är naturligtvis där beställningen kommer att levereras.
Låt oss skapa en amerikansk adress som en del av en kundorderdatabasmodell. (Obs:detta är inte en komplett modell, utan ett exempel på lagring av produktbeställningar.)
Wise Coders Solutions rekommenderar att du definierar separata fält för husnummer och gatunamn och ställer in dessa fält som INTE NULL; detta skulle förbjuda alla adresser som inte har ett husnummer och ett gatunamn. Men hur är det med folk som använder postboxar? Deras adresser skrivs vanligtvis som "PO Box 123". Ska vi tvinga dem att ange PO Box-numret som husnummer och "Po Box" som gatunamn? Jag tror inte det.
Istället kommer vi att använda ett formulär med "Adressrad 1" och "Adressrad 2". Flera personer har argumenterat mot att använda siffror i fältnamn, men för mig är detta en ganska självklar lösning. Jag har också definierat maximala fältlängder (35 och 70 tecken) som är typiska för internationella betalningar.
Lägg märke till att USA och icke-amerikanska design båda har ett fält för regioner inom ett land, men den amerikanska designen kräver att en statförkortning med två tecken ingår. Observera också att den amerikanska designen inte tillåter adresser i andra länder.
Om du är orolig för den globala användningen av din databas måste du tänka globalt under designfasen. Är våra databaser förberedda för multinationell användning av våra applikationer?
Lärdomar från dålig datalagerdesign
av Michelle A. Poolet | SQL Server Pro | 15 juni 2009
Den här artikeln tar en titt på Data Warehouse (DWH) och några av dess design- och implementeringsproblem. Det finns ett litet fokus på SQL Server, men det är en ganska ortodox översikt av design för datalagring och affärsintelligens. Att ha buy-in och skapa användarvänliga gränssnitt kanske inte är de mest användbara tipsen, men jag håller inte med dem – jag tror helt enkelt inte att de är en del av DWH-designen.
Ms. Poolet säger att ETL-processen (extraher-transform-load) bör utföra datakvalitetskontroller och potentiellt "rena" data tills det finns en acceptabel standard för datakvalitet. Enligt min åsikt riskerar detta att skapa ett datalager som inte korrekt speglar informationen som extraherats från källsystemet. Datarensning bör utföras i källsystemen. ETL bör endast transformera data så att den kan laddas in i datalagret.
Positivt är att rekommendationen att återvinna eller skapa återanvändbara ETL-rutiner är mycket relevant. Dessutom håller jag med Poolet om skalbarhet. Hennes kommentarer om riskhantering och efterlevnad, särskilt Sarbanes-Oxley Act, verkar ganska specifika; Jag antar att dessa kommer från hennes verksamhetsområde.
Slutligen har hon en trevlig checklista med punkter som rör dimensioner, faktatabeller och schemaval under OLAP-design (online analytical processing). Dessa verkar vara mycket relevanta under designprocessen för databasen. Jag hade velat ha den här listan längre, med fler detaljer eller exempel, men jag var glad att dessa praktiska tips fanns med.
11 viktiga regler för databasdesign som jag följer
av Shivprasad Koirala | Kodprojekt | 25 februari 2014
Jag gillar verkligen de förnuftiga och tydliga råden i början av den här artikeln. Begrepp som "tänk på applikationens natur" och "bryt upp din data i logiska bitar" är perfekta. Dessa är viktiga hjälpmedel när du skapar din datamodell. Som herr Koirala säger:
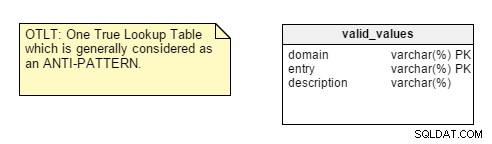
När du startar din databasdesign är det första du ska analysera typen av applikationen du designar för, är det Transaktionell eller Analytisk. Du kommer att hitta många utvecklare som som standard tillämpar normaliseringsregler utan att tänka på applikationens natur och sedan komma in på prestanda- och anpassningsproblem.Det finns dock ett par punkter som gör mig inte övertygad. Ta till exempel centralisering av Namn-Värde-par till en enda tabell. Denna One True Lookup Table-design (OTLT) är omdiskuterad, men den anses allmänt vara en dålig praxis eller åtminstone antimönster i designen. Jag ställer mig på anti-OTLT-gruppen; dessa tabeller introducerar många problem. Vi kan använda mjukvaruutvecklingsanalogin att använda en enda uppräkning för att representera alla möjliga värden för alla möjliga konstanter som en motsvarighet till denna praxis.
För att påminna dig, ser OTLT-tabellen vanligtvis ut ungefär så här, med poster från flera domäner in i samma tabell. Jag håller med anti-OTLT-gruppen; dessa tabeller introducerar många problem.
Dessutom verkar vissa punkter lite esoteriska, som "se efter data separerade av separatorer". Även om detta är en giltig poäng, är det inte en som jag brukar tänka på när jag skapar en ny datamodell.
Mr. Koirala har ett par OLAP-designartiklar som vanligtvis inte nämns i andra listor över bästa praxis. Hans inkludering av en dimension och faktadesign kan vara användbart, men det kan också vara farligt för nybörjardesigners.
Den här artikeln är intressant om du går från början till mer avancerad datamodellering. Det hjälper dig att överväga den analytiska kontra transaktionella karaktären hos dina framtida modeller.
Big Data:Fem enkla prestandatips för databasdesign
av Dave Beulke | davebeulke.com | 19 mars 2013

Mr. Beulkes artikel tittar på prestationsfokuserade designtips. Han visar hur man kontrollerar korrekt normalisering:varken för mycket eller för lite. (Övernormalisering kommer att ha en negativ inverkan på databasens prestanda.)
Att använda naturliga affärsnycklar snarare än genererade primärnycklar är ett bra råd när du vill undvika att översätta från en affärsnyckel till ett genererat rad-ID för varje databasåtkomst.
Att använda korrekta namnstandarder och kolumntyper är också ett bra råd. Poängen med överanvändning av nullbara kolumner är sund:att skapa alla kolumner som nullbara är ett misstag, men att definiera en kolumn som nullbar kan krävas för en viss affärsfunktion. Med författarens egna ord:
Är alla kolumner NULL-bara? Inom databaskolumnernas definitioner bör bra datadomäner, intervall och värden analyseras, utvärderas och prototyperas för affärsapplikationen. Att ha bra standardvärden, en begränsad omfattning av värden och alltid ett värde är bäst för prestanda och applikationslogik. NULL-kolumner är bara bra när data är okänd eller inte har ett värde ännu. Någons dödsdatumsdata är det klassiska exemplet på en NULLbar kolumn eftersom den är okänd om de inte redan är döda. Se till att din databasdesign representerar data som är känd och endast använder ett minimum av NULL-kolumner.Mr. Beulkes tips är alla mycket solida, även om de är något original. Jag skulle ha velat ha fler Big Data-objekt – det är trots allt rubriken på artikeln. Till sist upplevde jag att artikeln saknade både djup och bredd, och hade inga exempel för att förtydliga poängen. Men han ger värdefulla råd relaterade till normalisering och naturliga nycklar.
10 bästa metoder för databasdesign
av Ann All | Företagsappar idag | 15 juli 2014
Ten Database Design Best Practices presenteras faktiskt som en serie bilder. Allt innehåller information från erfarna utvecklare, som Michael Blaha. Han uppmuntrar återanvändning av dina bästa metoder och mönster. Dessa är förstådda och beprövade och i det avseendet att föredra framför datamodeller som måste skapas från grunden. Från Ms. Alls artikel:
Till exempel bakåtkonstruerar jag ofta databaser – databaser för en applikation som ska ersättas såväl som databaser med relaterade applikationer. Dessa befintliga databaser har ofta ingen tillgänglig datamodell. Men en datamodell är implicit i databasschemat och kan åtminstone delvis extraheras med databasreverse engineering-tekniker. … Det finns beprövade datarepresentationer som ofta förekommer och som inte behöver återskapas från grunden.Det här är ett kort bildspel som designers av datamodeller snabbt kan skanna igenom och plocka fram de tips som passar dem. För mig är återanvändningstipset en av mina favoriter.
Bästa metoder för databas
av Cunningham &Cunningham, Inc.
Dessa bästa tillvägagångssätt började bra, men fick sedan några svåra problem. Jag är inte övertygad om att de råd som erbjuds alltid är på plats.
På den positiva sidan finns det mycket trevliga beskrivningar av kontroversiella "bästa metoder" som att alltid använda automatiskt genererade surrogatnycklar och använda eller undvika lagrade procedurer. Som ett exempel:
En tidigare författare skrev:"Undvik i allmänhet primärnycklar som har betydelse. Namn är inte unika, och många till synes unika identifierare som personnummer är det faktiskt inte, på grund av datatillförlitlighetsproblem i verkligheten." Kort sagt är detta en rekommendation att alltid ha en automatiskt genererad (typiskt numerisk) SurrogateKey istället för en domänbaserad LogicalKey. Detta är ett ganska klappat svar på en komplex fråga, även om det är ett som kommer att räcka i ett antal fall och åtminstone är att föredra framför att inte ha någon primärnyckel alls.(Författarens anmärkning:Jag har inte kunnat hitta denna "föregående författare" när jag sökte efter dessa två meningar på Google.)
Och en länk till en sammanfattningsartikel om huvudargumenten på varje sida av debatten om automatiska nycklar kontra domännycklar tillhandahålls.
Å andra sidan tyckte jag att tipsen om att "dela upp operativsystem, data och logga in på olika fysiska diskar" och "använda RAID" var lite svårbegripliga. Missförstå mig inte – det här är förmodligen ett bra råd under vissa omständigheter, men jag skulle inte inkludera det i min topp 20-lista.
Databasdesigntips
av Wise Coders
Det finns några unika och intressanta tips i den här samlingen, till exempel en rekommendation att avsluta transaktioner så snart som möjligt.
Jag håller dock inte helt med om alla designtips här. Till exempel:
Antag ett fält 'Status' med värdena 'Aktiv', 'Inaktiv' och 'Idle'. Du kan spara värdet som det fullständiga namnet, men det kan vara ineffektivt. Att lagra en uppräkning eller en char(1) med möjliga värden 'a', 'i', 'd', till exempel, kommer att använda mindre utrymme i databasen.Detta är minst sagt kontroversiellt - andra källor rekommenderar att man inte använder "hemliga koder" som denna. Använd istället en separat tabell för att lagra dessa statuskoder.
Dessutom är statistiken förknippad med prestationstips tveksam, och det finns inga exempel i artikeln.
Positivt är att detta är en trevlig kort lista med tips som bör vara tillgängliga för mellanliggande databasmodellerare.
Resurser för nybörjare databasdesigners
Låt oss nu undersöka några artiklar för dem som precis har börjat med databasdesign.
Grunderna i bra databasdesign i webbutveckling
av Kayla Knight | Onextrapixel.com | 17 mars 2011
Här blir vi lite mer avancerade, med råd som sträcker sig från funktionalitet till modelleringsverktyg.
Ms. Knight leder oss genom en introduktion till databasdesign. Hennes artikel är intressant eftersom den betonar databaser för webbutveckling. Trots det är hennes poäng ganska universella och kan appliceras på databasdesign i många situationer.
Artikeln börjar med att be oss tänka brett om funktionalitet, inte bara databasen:
Tänk utanför databasen. Försök att tänka på vad webbplatsen kommer att behöva göra. Till exempel, om en medlemswebbplats behövs, kan den första instinkten vara att börja tänka på all data som varje användare behöver lagra. Glöm det, det är till senare. Skriv hellre ner att användare och deras information kommer att behöva lagras i databasen, och vad mer? Vad kommer dessa medlemmar att behöva göra på webbplatsen? Kommer de att göra inlägg, ladda upp filer eller foton eller skicka meddelanden? Då behöver databasen en plats för filer/foton, inlägg och meddelanden.Därifrån tar Ms. Knight läsaren in i databasdesignverktyg och stegen som ingår i processen. Hennes artikel ger exempel och länkar till andra resurser.
Jag tror att den här artikeln skulle vara en bra introduktion för nybörjare databasdesigners, och den borde fungera bra med Geek Girl's serie.
Utforska databasdesigntips
av Doug Lowe | För dummies
Mr. Lowes "Dummies"-lista är en bred serie av grundläggande designtips. Du kan hitta många av dessa på andra ställen, men det är användbart att ha dem på ett ställe. Du kommer inte hitta något unikt eller mycket kontroversiellt, förutom en rekommendation att använda lagrade procedurer. Jag ifrågasätter alltid detta starka uttalande, eftersom jag är mycket oroad över datamodellportabilitet för flera DBM-system.
Här är ett av Mr. Lowes sunt förnuftstips:
Undvik fält med namn som CustomerType, där fältets värde är en av flera konstanter som inte är definierade någon annanstans i databasen, som R för Retail eller W for Wholesale. Du kanske bara har dessa två typer av kunder idag, men applikationens behov kan ändras i framtiden, vilket kräver en tredje kundtyp.Dessa rekommendationer är mest lämpliga när du arbetar med SQL Server.
Fem enkla tips för databasdesign
av Lamont Adams | TechRepublic | 25 juni 2001
Nyckelordet för denna resurs är "enkelt". Du kan hitta denna information, med mer förklaringar och exempel, i andra artiklar.
Men herr Adams råd att "ta bort användarens nycklar" är en intressant punkt som sällan nämns på andra ställen. Han fortsätter:
När du bestämmer vilket eller vilka fält som ska användas som nycklar i en tabell, överväg alltid de fält som användarna kommer att redigera. Det är vanligtvis en dålig idé att välja ett användarredigerbart fält som nyckel.Mr. Adams mening är att du bör överväga användarens potentiella krav på att redigera fält när du bestämmer vilka fält som ska användas som nycklar. Jag hade velat ha mer förklaring angående alternativ, som syntetiska/genererade nycklar, men konceptet är bra.
Jag höll inte med om den sista punkten. Han rekommenderar en "fudge-faktor" för varje bord du designar:
Inte mycket är värre än att upptäcka, eller bli informerad, om att din "färdiga" databas saknar ett fält för en viktig bit av information. På ett företag jag arbetade för var detta en så vanlig händelse att vi började hänvisa till "databaser fryser" som "databasslask."I mitt sinne är detta i princip "att lägga till ett par extra textfält till slutet." Detta tycks motsäga några av Adams andra tips, särskilt de som gäller att förstå affärsbehov och använda meningsfulla namn. Dessa extra fudge-fält skulle bara kallas något som "extra1" eller "extra2". Vad är deras affärsbehov? Och hur är dessa meningsfulla namn? Även om jag gillar de flesta av hans designtips, är den här "fudge-faktorn" inget jag håller fast vid.
Databasdesign:hedersomnämnanden
Uppenbarligen finns det andra artiklar som beskriver databasdesigntips och bästa praxis. Du kan hitta ytterligare material i följande länkar:
Relationell databasdesign:A Best Practices Primer | av Digital Ethos | 24 december 2012
Bästa metoder för design av databasschema (nybörjare) | av Jim Murphy | 28 mars 2011
IT Best Practices:Databasdesign | av University of Nebraska–Lincoln
Resurser för onlinedatabasdesign:vart skulle du gå?
Som nämnts är denna lista definitivt inte avsedd att vara en uttömmande granskning av varje databasdesignartikel på Internet. Snarare har vi identifierat flera artiklar som vi tycker är användbara eller som har ett särskilt fokus som du kan ha nytta av.
Rekommendera gärna ytterligare artiklar.