Har du någonsin stött på en situation där du behöver hantera tillståndet för en enhet som förändras över tiden? Det finns många exempel där ute. Låt oss börja med en enkel sådan:slå samman kundregister.
Anta att vi slår samman listor över kunder från två olika källor. Vi kan ha något av följande tillstånd:Dubletter identifierade – Systemet har hittat två potentiellt duplicerade enheter; Bekräftade dubbletter – en användare validerar att de två enheterna verkligen är dubbletter; eller Bekräftad unik – användaren bestämmer att de två enheterna är unika. I någon av dessa situationer har användaren bara ett ja-nej-beslut att fatta.
Men hur är det med mer komplexa situationer? Finns det något sätt att definiera det faktiska arbetsflödet mellan stater? Läs vidare...
Hur saker lätt kan gå fel
Många organisationer behöver hantera jobbansökningar. I en enkel modell kan du ha en tabell som heter JOB_APPLICATION , och du kan spåra applikationens tillstånd med hjälp av en referensdatatabell som innehåller värden som dessa:
| Programstatus |
|---|
APPLICATION_RECEIVED |
APPLICATION_UNDER_REVIEW |
APPLICATION_REJECTED |
INVITED_TO_INTERVIEW |
INVITATION_DECLINED |
INVITATION_ACCEPTED |
INTERVIEW_PASSED |
INTERVIEW_FAILED |
REFERENCES_SOUGHT |
REFERENCES_ACCEPTABLE |
REFERENCES_UNACCEPTABLE |
JOB_OFFER_MADE |
JOB_OFFER_ACCEPTED |
JOB_OFFER_DECLINED |
APPLICATION_CLOSED |
Dessa värden kan väljas i valfri ordning när som helst. Det förlitar sig på slutanvändarna för att säkerställa att ett logiskt och korrekt urval görs i varje steg. Ingenting förbjuder en ologisk sekvens av tillstånd.
Låt oss till exempel säga att en ansökan har avslagits. Den nuvarande statusen skulle uppenbarligen vara APPLICATION_REJECTED . Det finns inget som kan göras på applikationsnivå för att hindra en oerfaren användare från att sedan välja INVITED_TO_INTERVIEW eller något annat ologiskt tillstånd.
Vad som behövs är något som vägleder användaren att välja nästa logiska tillstånd, något som definierar ett logiskt arbetsflöde .
Och vad händer om du har olika krav på olika typer av jobbansökningar? Till exempel kan vissa jobb kräva att den sökande gör ett lämplighetstest. Visst, du kan lägga till fler värden till listan för att täcka dessa, men det finns inget i den nuvarande designen som hindrar slutanvändaren från att göra ett felaktigt val för den aktuella typen av applikation. Verkligheten är att det finns olika arbetsflöden för olika sammanhang .
En annan punkt att tänka på:är de listade alternativen verkligen alla stater ? Eller är några faktiskt resultat ? Till exempel kan erbjudandet om ett jobb accepteras eller avslås av den sökande. Därför JOB_OFFER_MADE har verkligen två resultat:JOB_OFFER_ACCEPTED och JOB_OFFER_DECLINED .
Ett annat resultat kan vara att ett jobberbjudande dras tillbaka. Du kanske vill anteckna anledningen till att den drogs tillbaka med hjälp av ett kval. Om du bara lägger till dessa skäl till listan ovan, vägleder ingenting slutanvändaren att göra logiska val.
Så egentligen, ju mer komplexa tillstånden, resultaten och kvalificeringarna blir, desto mer behöver du definiera arbetsflödet av en process .
Organisera processer, tillstånd och resultat
Det är viktigt att förstå vad som händer med din data innan du försöker modellera den. Du kanske till en början är benägen att tro att det finns en strikt hierarki av typer här:
När vi tittar närmare på exemplet ovan ser vi att INVITED_TO_INTERVIEW och JOB_OFFER_MADE tillstånd delar samma möjliga resultat, nämligen ACCEPTED och DECLINED . Detta berättar för oss att det finns en många-till-många-relation mellan tillstånd och resultat. Detta är ofta sant för andra delstater, resultat och kvalificeringar.
På en konceptuell nivå är det alltså detta som faktiskt händer med vår metadata:
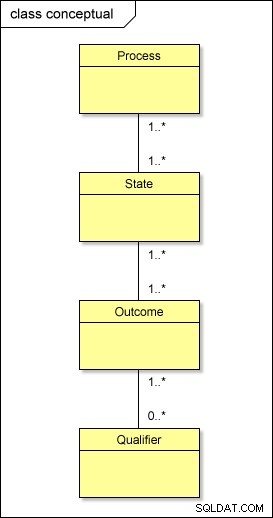
Om du skulle transformera den här modellen till den fysiska världen med standardmetoden skulle du ha tabeller som heter PROCESS , STATE , OUTCOME och QUALIFIER; du skulle också behöva ha mellanliggande tabeller mellan dem – PROCESS_STATE , STATE_OUTCOME och OUTCOME_QUALIFIER – för att lösa många-till-många-relationerna . Detta komplicerar designen.
Medan den logiska hierarkin av nivåer (process → tillstånd → resultat → kvalificering) måste bibehållas, finns det ett enklare sätt att fysiskt organisera vår metadata.
Arbetsflödesmönstret
Diagrammet nedan definierar huvudkomponenterna i en arbetsflödesdatabasmodell:
De gula tabellerna till vänster innehåller arbetsflödesmetadata och de blå tabellerna till höger innehåller affärsdata.
Det första att påpeka är att alla enheter kan hanteras utan att kräva större förändringar av denna modell. YOUR_ENTITIY_TO_MANAGE tabellen är den under arbetsflödeshantering. I vårt exempel skulle detta vara JOB_APPLICATION tabell.
Därefter behöver vi helt enkelt lägga till wf_state_type_process_id kolumn till vilken tabell vi vill hantera. Den här kolumnen pekar på den faktiska processen för arbetsflödet används för att hantera enheten. Det här är inte strikt en främmande nyckelkolumn, men den tillåter oss att snabbt fråga WORKFLOW_STATE_TYPE för rätt process. Tabellen som kommer att innehålla tillståndshistoriken är MANAGED_ENTITY_STATE . Återigen, du skulle välja ditt eget specifika tabellnamn här och ändra det för dina egna krav.
Metadata
De olika arbetsflödesnivåerna definieras i WORKFLOW_LEVEL_TYPE . Den här tabellen innehåller följande:
| Typnyckel | Beskrivning |
|---|---|
| PROCESS | Arbetsflödesprocess på hög nivå. |
| STATE | Ett tillstånd i processen. |
| RESULTAT | Hur en stat slutar, dess resultat. |
| QUALIFIER | En valfri, mer detaljerad kvalificering för ett resultat. |
WORKFLOW_STATE_TYPE och WORKFLOW_STATE_HIERARCHY bildar en klassisk styckliststruktur . Denna struktur, som är mycket beskrivande för en faktisk tillverkningsstyck, är ganska vanlig inom datamodellering. Det kan definiera hierarkier eller tillämpas på många rekursiva situationer. Vi kommer att använda det här för att definiera vår logiska hierarki av processer, tillstånd, resultat och valfria kvalificerare.
Innan vi kan definiera en hierarki måste vi definiera de enskilda komponenterna. Dessa är våra grundläggande byggstenar. Jag kommer bara att referera till dessa med TYPE_KEY (vilket är unikt) för korthetens skull. För vårt exempel har vi:
| Typ av arbetsflödesnivå | Workflow State Type.Type Key |
|---|---|
| RESULTAT | GODKÄND |
| RESULTAT | MISSLYCKADES |
| RESULTAT | ACCEPTERAT |
| RESULTAT | AVVISADE |
| RESULTAT | CANDIDATE_CANCELLED |
| RESULTAT | EMPLOYER_CANCELLED |
| RESULTAT | AVVISAD |
| RESULTAT | EMPLOYER_WITHDRAWN |
| RESULTAT | NO_SHOW |
| RESULTAT | ANhyrd |
| RESULTAT | NOT_HIRED |
| STATE | APPLICATION_RECEIVED |
| STATE | APPLICATION_REVIEW |
| STATE | INVITED_TO_INTERVIEW |
| STATE | INTERVJU |
| STATE | TEST_APTITUDE |
| STATE | SEEK_REFERENCES |
| STATE | MAKE_OFFER |
| STATE | APPLICATION_CLOSED |
| BEHANDLING | STANDARD_JOB_APPLICATION |
| BEHANDLING | TECHNICAL_JOB_APPLICATION |
Nu kan vi börja definiera vår hierarki. Det är här vi tar våra byggstenar och definierar vår struktur. För varje stat definierar vi de möjliga resultaten. Faktum är att det är en regel för detta arbetsflödessystem att varje tillstånd måste avslutas med ett resultat:
| Föräldratyp – STATES | Barntyp – RESULTAT |
|---|---|
| APPLICATION_RECEIVED | ACCEPTERAT |
| APPLICATION_RECEIVED | AVVISAD |
| APPLICATION_REVIEW | GODKÄND |
| APPLICATION_REVIEW | MISSLYCKADES |
| INVITED_TO_INTERVIEW | ACCEPTERAT |
| INVITED_TO_INTERVIEW | AVVISADE |
| INTERVJU | GODKÄND |
| INTERVJU | MISSLYCKADES |
| INTERVJU | CANDIDATE_CANCELLED |
| INTERVJU | NO_SHOW |
| MAKE_OFFER | ACCEPTERAT |
| MAKE_OFFER | AVVISADE |
| SEEK_REFERENCES | GODKÄND |
| SEEK_REFERENCES | MISSLYCKADES |
| APPLICATION_CLOSED | ANhyrd |
| APPLICATION_CLOSED | NOT_HIRED |
| TEST_APTITUDE | GODKÄND |
| TEST_APTITUDE | MISSLYCKADES |
Våra processer är helt enkelt en uppsättning tillstånd som var och en existerar under en tidsperiod. I tabellen nedan presenteras de i en logisk ordning, men detta definierar inte den faktiska bearbetningsordningen.
| Föräldratyp – PROCESSER | Barntyp – STATES |
|---|---|
| STANDARD_JOB_APPLICATION | APPLICATION_RECEIVED |
| STANDARD_JOB_APPLICATION | APPLICATION_REVIEW |
| STANDARD_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| STANDARD_JOB_APPLICATION | INTERVJU |
| STANDARD_JOB_APPLICATION | MAKE_OFFER |
| STANDARD_JOB_APPLICATION | SEEK_REFERENCES |
| STANDARD_JOB_APPLICATION | APPLICATION_CLOSED |
| TECHNICAL_JOB_APPLICATION | APPLICATION_RECEIVED |
| TECHNICAL_JOB_APPLICATION | APPLICATION_REVIEW |
| TECHNICAL_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| TECHNICAL_JOB_APPLICATION | TEST_APTITUDE |
| TECHNICAL_JOB_APPLICATION | INTERVJU |
| TECHNICAL_JOB_APPLICATION | MAKE_OFFER |
| TECHNICAL_JOB_APPLICATION | SEEK_REFERENCES |
| TECHNICAL_JOB_APPLICATION | APPLICATION_CLOSED |
Det finns en viktig poäng att göra angående en BOM-hierarki. Precis som en fysisk stycklista definierar sammansättningar och underenheter ner till de minsta komponenterna, har vi ett liknande arrangemang i vår hierarki. Det betyder att vi får återanvända 'sammansättningar' och 'undersammansättningar'.
Som exempel:Både STANDARD_JOB_APPLICATION och TECHNICAL_JOB_APPLICATION processer har INTERVIEW tillstånd . I sin tur, INTERVIEW tillstånd har PASSED , FAILED , CANDIDATE_CANCELLED och NO_SHOW resultat definieras för det.
När du använder ett tillstånd i en process får du automatiskt dess underordnade resultat med det eftersom det redan är en sammansättning. Detta innebär att samma resultat finns för båda typerna av jobbansökningar vid INTERVIEW skede. Om du vill ha olika intervjuresultat för olika typer av jobbansökningar måste du definiera t.ex. TECHNICAL_INTERVIEW och STANDARD_INTERVIEW anger att var och en har sina egna specifika resultat.
I det här exemplet är den enda skillnaden mellan de två typerna av jobbansökningar att en teknisk jobbansökan innehåller ett lämplighetstest.
Innan du går
Del 1 av denna tvådelade artikel har introducerat arbetsflödesdatabasmönstret. Den har visat hur du kan integrera den för att hantera livscykeln för alla enheter i din databas.
Del 2 visar dig hur du definierar det faktiska arbetsflödet med hjälp av ytterligare konfigurationstabeller. Det är här användaren kommer att presenteras för tillåtna nästa steg. Vi kommer också att visa en teknik för att komma runt den strikta återanvändningen av "sammansättningar" och "undersammansättningar" i stycklistor.