Fönsterfunktionen ROW_NUMBER har många praktiska tillämpningar, långt utöver bara de uppenbara rankningsbehoven. För det mesta, när du beräknar radnummer, måste du beräkna dem baserat på någon ordning, och du anger önskad beställningsspecifikation i funktionens fönsterordningsklausul. Det finns dock fall där du behöver beräkna radnummer i ingen speciell ordning; med andra ord, baserat på icke-deterministisk ordning. Detta kan vara över hela frågeresultatet eller inom partitioner. Exempel inkluderar att tilldela unika värden till resultatrader, deduplicera data och returnera valfri rad per grupp.
Observera att att behöva tilldela radnummer baserat på icke-deterministisk ordning är annorlunda än att behöva tilldela dem baserat på slumpmässig ordning. Med den förra bryr du dig helt enkelt inte om i vilken ordning de tilldelas, och om upprepade körningar av frågan fortsätter att tilldela samma radnummer till samma rader eller inte. Med den sistnämnda förväntar du dig att upprepade avrättningar hela tiden ändrar vilka rader som tilldelas vilka radnummer. Den här artikeln utforskar olika tekniker för att beräkna radnummer med icke-deterministisk ordning. Förhoppningen är att hitta en teknik som är både pålitlig och optimal.
Särskilt tack till Paul White för tipset om konstant vikning, för runtime constant-tekniken och för att han alltid är en bra informationskälla!
När beställning är viktig
Jag börjar med fall där radnummerordningen spelar någon roll.
Jag kommer att använda en tabell som heter T1 i mina exempel. Använd följande kod för att skapa den här tabellen och fylla i den med exempeldata:
SET NOCOUNT ON; USE tempdb; DROP TABLE IF EXISTS dbo.T1; GO CREATE TABLE dbo.T1 ( id INT NOT NULL CONSTRAINT PK_T1 PRIMARY KEY, grp VARCHAR(10) NOT NULL, datacol INT NOT NULL ); INSERT INTO dbo.T1(id, grp, datacol) VALUES (11, 'A', 50), ( 3, 'B', 20), ( 5, 'A', 40), ( 7, 'B', 10), ( 2, 'A', 50);
Tänk på följande fråga (vi kallar den fråga 1):
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Här vill du att radnummer ska tilldelas inom varje grupp som identifieras av kolumnen grp, sorterad efter kolumnen datakol. När jag körde den här frågan på mitt system fick jag följande utdata:
id grp datacol n --- ---- -------- --- 5 A 40 1 2 A 50 2 11 A 50 3 7 B 10 1 3 B 20 2
Radnummer tilldelas här i en delvis deterministisk och delvis icke-deterministisk ordning. Vad jag menar med detta är att du har en försäkran om att inom samma partition kommer en rad med ett högre datacol-värde att få ett högre radnummervärde. Men eftersom datacol inte är unik inom grp-partitionen är ordningen för tilldelning av radnummer bland rader med samma grp- och datacol-värden obestämd. Så är fallet med raderna med id-värden 2 och 11. Båda har grp-värdet A och datacol-värdet 50. När jag körde den här frågan på mitt system för första gången fick raden med id 2 rad nummer 2 och rad med id 11 fick rad nummer 3. Strunt i sannolikheten för att detta händer i praktiken i SQL Server; om jag kör frågan igen, teoretiskt sett kan raden med id 2 tilldelas rad nummer 3 och raden med id 11 kan tilldelas rad nummer 2.
Om du behöver tilldela radnummer baserat på en helt deterministisk ordning, vilket garanterar repeterbara resultat över körningar av frågan så länge som de underliggande data inte ändras, behöver du att kombinationen av element i fönsterpartitionerings- och ordningsklausulerna är unika. Detta skulle kunna uppnås i vårt fall genom att lägga till kolumn-id till fönsterordningsklausulen som en tiebreaker. OVER-satsen skulle då vara:
OVER (PARTITION BY grp ORDER BY datacol, id)
I vilket fall som helst, när man beräknar radnummer baserat på någon meningsfull ordningsspecifikation som i fråga 1, måste SQL Server bearbeta raderna ordnade genom kombinationen av fönsterpartitionering och beställningselement. Detta kan uppnås genom att antingen hämta data som förbeställts från ett index eller genom att sortera data. För närvarande finns det inget index på T1 för att stödja ROW_NUMBER-beräkningen i fråga 1, så SQL Server måste välja att sortera data. Detta kan ses i planen för fråga 1 som visas i figur 1.
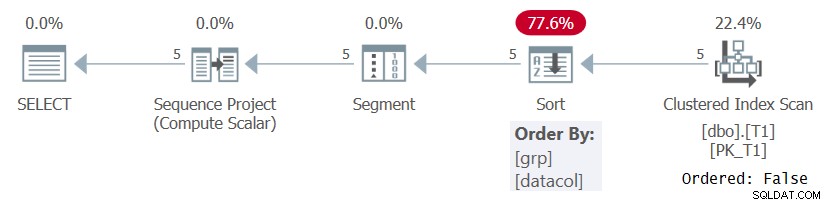 Figur 1:Planera för fråga 1 utan ett stödjande index
Figur 1:Planera för fråga 1 utan ett stödjande index
Lägg märke till att planen skannar data från det klustrade indexet med egenskapen Ordered:False. Detta innebär att skanningen inte behöver returnera raderna som sorterats av indexnyckeln. Det är fallet eftersom det klustrade indexet används här bara för att det råkar täcka frågan och inte på grund av dess nyckelordning. Planen tillämpar sedan en sortering, vilket resulterar i extra kostnad, N Log N-skalning och försenad svarstid. Segmentoperatorn producerar en flagga som indikerar om raden är den första i partitionen eller inte. Slutligen tilldelar sekvensprojektoperatören radnummer som börjar med 1 i varje partition.
Om du vill undvika behovet av sortering kan du förbereda ett täckande index med en nyckellista som är baserad på partitionerings- och beställningselementen, och en inkluderingslista som är baserad på täckelementen. Jag tycker om att tänka på det här indexet som ett POC-index (för partitionering , beställning och täckning ). Här är definitionen av POC som stöder vår fråga:
CREATE INDEX idx_grp_data_i_id ON dbo.T1(grp, datacol) INCLUDE(id);
Kör fråga 1 igen:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Planen för detta utförande visas i figur 2.
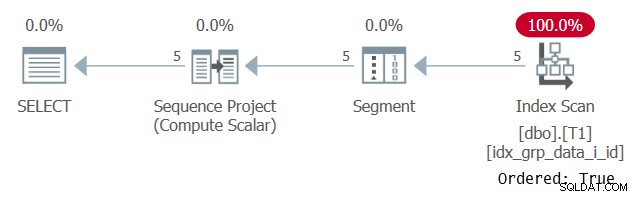 Figur 2:Planera för fråga 1 med ett POC-index
Figur 2:Planera för fråga 1 med ett POC-index
Observera att denna gång skannar planen POC-indexet med en Ordered:True-egenskap. Detta innebär att skanningen garanterar att raderna kommer att returneras i indexnyckelordning. Eftersom data hämtas förbeställt från indexet som fönsterfunktionen behöver, finns det inget behov av explicit sortering. Skalningen av denna plan är linjär och svarstiden är bra.
När ordningen inte spelar någon roll
Saker och ting blir lite knepiga när du behöver tilldela radnummer med en helt odeterministisk ordning. Det naturliga att vilja göra i ett sådant fall är att använda funktionen ROW_NUMBER utan att ange en fönsterordningssats. Låt oss först kontrollera om SQL-standarden tillåter detta. Här är den relevanta delen av standarden som definierar syntaxreglerna för fönsterfunktioner:
Syntaxregler...
5) Låt WNS vara
6) Om
a) Om
...
f) ROW_NUMBER() ÖVER WNS motsvarar
...
Lägg märke till att punkt 6 listar funktionerna
Så låt oss prova det och försöka beräkna radnummer utan fönsterordning i SQL Server:
SELECT id, grp, datacol, ROW_NUMBER() OVER() AS n FROM dbo.T1;
Detta försök resulterar i följande fel:
Msg 4112, Level 15, State 1, Line 53Funktionen 'ROW_NUMBER' måste ha en OVER-sats med ORDER BY.
Faktum är att om du kontrollerar SQL Servers dokumentation av ROW_NUMBER-funktionen hittar du följande text:
“order_by_clauseORDER BY-satsen bestämmer sekvensen i vilken raderna tilldelas sitt unika ROW_NUMBER inom en specificerad partition. Det krävs.”
Så tydligen är fönsterordningsklausulen obligatorisk för funktionen ROW_NUMBER i SQL Server. Så är det förresten också i Oracle.
Jag måste säga att jag inte är säker på att jag förstår resonemanget bakom detta krav. Kom ihåg att du tillåter att definiera radnummer baserat på en delvis icke-deterministisk ordning, som i fråga 1. Så varför inte tillåta odeterminism hela vägen? Kanske finns det någon anledning som jag inte tänker på. Om du kan komma på en sådan anledning, vänligen dela.
I vilket fall som helst kan du hävda att om du inte bryr dig om beställning, med tanke på att fönsterbeställningsklausulen är obligatorisk, kan du ange vilken beställning som helst. Problemet med detta tillvägagångssätt är att om du beställer efter någon kolumn från de efterfrågade tabellerna kan detta innebära en onödig prestationsstraff. När det inte finns något stödjande index på plats, betalar du för explicit sortering. När det finns ett stödjande index på plats, begränsar du lagringsmotorn till en indexorderskanningsstrategi (följer den indexlänkade listan). Du tillåter det inte mer flexibilitet som det vanligtvis har när ordning inte spelar någon roll när du väljer mellan en indexorderskanning och en allokeringsorderskanning (baserat på IAM-sidor).
En idé som är värd att pröva är att specificera en konstant, som 1, i fönsterordningssatsen. Om det stöds, hoppas du att optimeraren är smart nog att inse att alla rader har samma värde, så det finns ingen verklig ordningsrelevans och därför inget behov av att tvinga fram en sortering eller en indexordersökning. Här är en fråga som försöker detta tillvägagångssätt:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1) AS n FROM dbo.T1;
Tyvärr stöder inte SQL Server denna lösning. Det genererar följande fel:
Msg 5308, Level 16, State 1, Line 56Fönsterfunktioner, aggregat och NEXT VALUE FOR-funktioner stöder inte heltalsindex som ORDER BY-satsuttryck.
Uppenbarligen antar SQL Server att om du använder en heltalskonstant i fönsterordningssatsen, representerar den en ordinalposition för ett element i SELECT-listan, som när du anger ett heltal i presentationssatsen ORDER BY. Om så är fallet är ett annat alternativ som är värt att försöka ange en icke-heltalskonstant, som så:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 'No Order') AS n FROM dbo.T1;
Det visar sig att denna lösning inte stöds också. SQL Server genererar följande fel:
Msg 5309, Level 16, State 1, Line 65Windowed-funktioner, aggregat och NEXT VALUE FOR-funktioner stöder inte konstanter som ORDER BY-satsuttryck.
Uppenbarligen stöder inte fönsterordningsklausulen någon form av konstant.
Hittills har vi lärt oss följande om ROW_NUMBER-funktionens fönsterordningsrelevans i SQL Server:
- ORDER BY krävs.
- Kan inte sortera efter en heltalskonstant eftersom SQL Server tror att du försöker ange en ordningsposition i SELECT.
- Kan inte sortera efter någon form av konstant.
Slutsatsen är att du ska sortera efter uttryck som inte är konstanter. Självklart kan du beställa efter en kolumnlista från den/de efterfrågade tabellen/tabellerna. Men vi strävar efter att hitta en effektiv lösning där optimeraren kan inse att det inte finns någon beställningsrelevans.
Konstant vikning
Slutsatsen hittills är att du inte kan använda konstanter i ROW_NUMBER:s fönsterordningssats, men hur är det med uttryck baserade på konstanter, som i följande fråga:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+0) AS n FROM dbo.T1;
Detta försök faller dock offer för en process som kallas konstant vikning, som normalt har en positiv prestandapåverkan på frågor. Tanken bakom denna teknik är att förbättra frågeprestanda genom att vika ett uttryck baserat på konstanter till deras resultatkonstanter i ett tidigt skede av frågebehandlingen. Du kan hitta detaljer om vilka typer av uttryck som kan vikas konstant här. Vårt uttryck 1+0 viks till 1, vilket resulterar i samma fel som du fick när du angav konstanten 1 direkt:
Msg 5308, Level 16, State 1, Line 79Fönsterfunktioner, aggregat och NEXT VALUE FOR-funktioner stöder inte heltalsindex som ORDER BY-satsuttryck.
Du skulle möta en liknande situation när du försöker sammanfoga två bokstavliga teckensträngar, som så:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 'No' + ' Order') AS n FROM dbo.T1;
Du får samma felmeddelande som du fick när du angav den bokstavliga "Ingen beställning" direkt:
Msg 5309, Level 16, State 1, Line 55Fönsterfunktioner, aggregat och NEXT VALUE FOR-funktioner stöder inte konstanter som ORDER BY-satsuttryck.
Bizarro world – fel som förhindrar fel
Livet är fullt av överraskningar...
En sak som förhindrar konstant vikning är när uttrycket normalt skulle resultera i ett fel. Till exempel kan uttrycket 2147483646+1 vara konstantvikt eftersom det resulterar i ett giltigt INT-typat värde. Följaktligen misslyckas ett försök att köra följande fråga:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483646+1) AS n FROM dbo.T1;Msg 5308, Level 16, State 1, Line 109
Fönsterfunktioner, aggregat och NEXT VALUE FOR-funktioner stöder inte heltalsindex som ORDER BY-satsuttryck.
Uttrycket 2147483647+1 kan dock inte vikas konstant eftersom ett sådant försök skulle ha resulterat i ett INT-spillfel. Implikationen på beställning är ganska intressant. Prova följande fråga (vi kallar denna fråga 2):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483647+1) AS n FROM dbo.T1;
Konstigt nog körs den här frågan framgångsrikt! Vad som händer är att å ena sidan misslyckas SQL Server med att tillämpa konstant falsning, och därför är ordningen baserad på ett uttryck som inte är en enda konstant. Å andra sidan siffror optimeraren att ordningsvärdet är detsamma för alla rader, så den ignorerar ordningsuttrycket helt och hållet. Detta bekräftas när man undersöker planen för denna fråga som visas i figur 3.
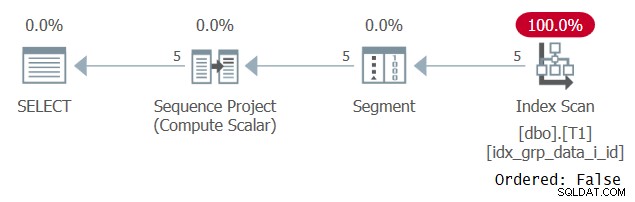 Figur 3:Plan för fråga 2
Figur 3:Plan för fråga 2
Observera att planen skannar något täckande index med en Ordered:False-egenskap. Detta var precis vårt prestationsmål.
På liknande sätt involverar följande fråga ett framgångsrikt konstant vikningsförsök och misslyckas därför:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/1) AS n FROM dbo.T1;Msg 5308, Level 16, State 1, Line 123
Fönsterfunktioner, aggregat och NEXT VALUE FOR-funktioner stöder inte heltalsindex som ORDER BY-satsuttryck.
Följande fråga involverar ett misslyckat konstant vikningsförsök och lyckas därför, och genererar planen som visas tidigare i figur 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/0) AS n FROM dbo.T1;
Följande fråga involverar ett framgångsrikt konstant vikningsförsök (VARCHAR literal '1' konverteras implicit till INT 1, och sedan 1 + 1 viks till 2), och misslyckas därför:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+'1') AS n FROM dbo.T1;Msg 5308, Level 16, State 1, Line 134
Fönsterfunktioner, aggregat och NEXT VALUE FOR-funktioner stöder inte heltalsindex som ORDER BY-satsuttryck.
Följande fråga involverar ett misslyckat konstant vikningsförsök (kan inte konvertera 'A' till INT), och lyckas därför och genererar planen som visas tidigare i figur 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+'A') AS n FROM dbo.T1;
För att vara ärlig, även om den här bisarra tekniken uppnår vårt ursprungliga prestationsmål, kan jag inte säga att jag anser att den är säker och därför är jag inte så bekväm med att lita på den.
Körtidskonstanter baserade på funktioner
För att fortsätta sökandet efter en bra lösning för att beräkna radnummer med icke-deterministisk ordning, finns det några tekniker som verkar säkrare än den senaste udda lösningen:att använda körtidskonstanter baserade på funktioner, använda en underfråga baserad på en konstant, använda en aliasad kolumn baserad på en konstant och använder en variabel.
Som jag förklarar i T-SQL buggar, fallgropar och bästa praxis – determinism, de flesta funktioner i T-SQL utvärderas endast en gång per referens i frågan – inte en gång per rad. Detta är fallet även med de flesta icke-deterministiska funktioner som GETDATE och RAND. Det finns väldigt få undantag från denna regel, som funktionerna NEWID och CRYPT_GEN_RANDOM, som utvärderas en gång per rad. De flesta funktioner, som GETDATE, @@SPID och många andra, utvärderas en gång i början av frågan, och deras värden betraktas då som körtidskonstanter. En hänvisning till sådana funktioner viks inte konstant. Dessa egenskaper gör en körtidskonstant som är baserad på en funktion till ett bra val som fönsterbeställningselement, och det verkar faktiskt som att T-SQL stöder det. Samtidigt inser optimeraren att det i praktiken inte finns någon beställningsrelevans, vilket undviker onödiga prestationspåföljder.
Här är ett exempel med funktionen GETDATE:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY GETDATE()) AS n FROM dbo.T1;
Den här frågan får samma plan som visades tidigare i figur 3.
Här är ett annat exempel som använder @@SPID-funktionen (returgerar det aktuella sessions-ID):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @@SPID) AS n FROM dbo.T1;
Hur är det med funktionen PI? Försök med följande fråga:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY PI()) AS n FROM dbo.T1;
Den här misslyckas med följande fel:
Msg 5309, Level 16, State 1, Line 153Fönsterfunktioner, aggregat och NEXT VALUE FOR-funktioner stöder inte konstanter som ORDER BY-satsuttryck.
Funktioner som GETDATE och @@SPID omvärderas en gång per exekvering av planen, så de kan inte läggas ihop konstant. PI representerar alltid samma konstant och blir därför konstant vikt.
Som nämnts tidigare är det väldigt få funktioner som utvärderas en gång per rad, som NEWID och CRYPT_GEN_RANDOM. Detta gör dem till ett dåligt val som element för fönsterbeställning om du behöver icke-deterministisk ordning – inte att förväxla med slumpmässig ordning. Varför betala en onödig sortsstraff?
Här är ett exempel med funktionen NYHET:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY NEWID()) AS n FROM dbo.T1;
Planen för denna fråga visas i figur 4, vilket bekräftar att SQL Server lade till explicit sortering baserat på funktionens resultat.
 Figur 4:Plan för fråga 3
Figur 4:Plan för fråga 3
Om du vill att radnumren ska tilldelas i slumpmässig ordning, är det för all del den teknik du vill använda. Du behöver bara vara medveten om att det medför sorteringskostnaden.
Använda en underfråga
Du kan också använda en underfråga baserad på en konstant som fönsterordningsuttryck (t.ex. ORDER BY (SELECT 'No Order')). Också med den här lösningen inser SQL Servers optimerare att det inte finns någon beställningsrelevans och kräver därför inte en onödig sortering eller begränsar lagringsmotorns val till de som måste garantera ordning. Testa att köra följande fråga som ett exempel:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 'No Order')) AS n FROM dbo.T1;
Du får samma plan som tidigare i figur 3.
En av de stora fördelarna med denna teknik är att du kan sätta din egen personliga touch. Kanske gillar du verkligen NULL:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM dbo.T1;
Kanske gillar du verkligen ett visst antal:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 42)) AS n FROM dbo.T1;
Kanske vill du skicka ett meddelande till någon:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 'Lilach, will you marry me?')) AS n FROM dbo.T1;
Du förstår poängen.
Görbart, men besvärligt
Det finns ett par tekniker som fungerar, men som är lite besvärliga. En är att definiera ett kolumnalias för ett uttryck baserat på en konstant, och sedan använda det kolumnaliaset som fönsterbeställningselement. Du kan göra detta antingen med ett tabelluttryck eller med CROSS APPLY-operatorn och en tabellvärdekonstruktor. Här är ett exempel för det senare:
SELECT id, grp, datacol,
ROW_NUMBER() OVER(ORDER BY [I'm a bit ugly]) AS n
FROM dbo.T1 CROSS APPLY ( VALUES('No Order') ) AS A([I'm a bit ugly]); Du får samma plan som tidigare i figur 3.
Ett annat alternativ är att använda en variabel som fönsterbeställningselement:
DECLARE @ImABitUglyToo AS INT = NULL; SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @ImABitUglyToo) AS n FROM dbo.T1;
Denna fråga får också planen som visas tidigare i figur 3.
Vad händer om jag använder min egen UDF?
Du kanske tror att att använda din egen UDF som returnerar en konstant kan vara ett bra val som fönsterbeställningselement när du vill ha odeterministisk ordning, men det är det inte. Betrakta följande UDF-definition som ett exempel:
DROP FUNCTION IF EXISTS dbo.YouWillRegretThis; GO CREATE FUNCTION dbo.YouWillRegretThis() RETURNS INT AS BEGIN RETURN NULL END; GO
Försök att använda UDF som fönsterordningsklausul, som så (vi kallar denna fråga 4):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY dbo.YouWillRegretThis()) AS n FROM dbo.T1;
Före SQL Server 2019 (eller parallell kompatibilitetsnivå <150) utvärderas användardefinierade funktioner per rad. Även om de returnerar en konstant, blir de inte infogade. Följaktligen kan du å ena sidan använda en sådan UDF som fönsterbeställningselement, men å andra sidan resulterar detta i en sorteringsstraff. Detta bekräftas genom att undersöka planen för denna fråga, som visas i figur 5.
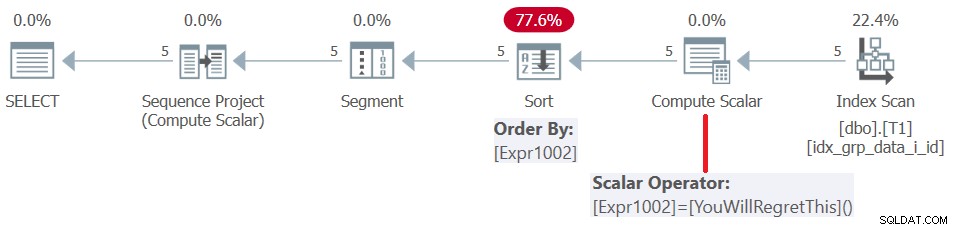 Figur 5:Plan för fråga 4
Figur 5:Plan för fråga 4
Från och med SQL Server 2019, under kompatibilitetsnivå>=150, infogas sådana användardefinierade funktioner, vilket för det mesta är bra, men i vårt fall resulterar i ett fel:
Msg 5309, Level 16, State 1, Line 217Windowed-funktioner, aggregat och NEXT VALUE FOR-funktioner stöder inte konstanter som ORDER BY-satsuttryck.
Så att använda en UDF baserad på en konstant som fönsterbeställningselement tvingar antingen fram en sortering eller ett fel beroende på vilken version av SQL Server du använder och din databaskompatibilitetsnivå. Kort sagt, gör inte det här.
Partitionerade radnummer med icke-deterministisk ordning
Ett vanligt användningsfall för partitionerade radnummer baserat på icke-deterministisk ordning är att returnera valfri rad per grupp. Med tanke på att det per definition existerar ett partitioneringselement i detta scenario, skulle du kunna tro att en säker teknik i ett sådant fall skulle vara att använda fönsterpartitioneringselementet också som fönsterbeställningselement. Som ett första steg beräknar du radnummer så här:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n FROM dbo.T1;
Planen för denna fråga visas i figur 6.
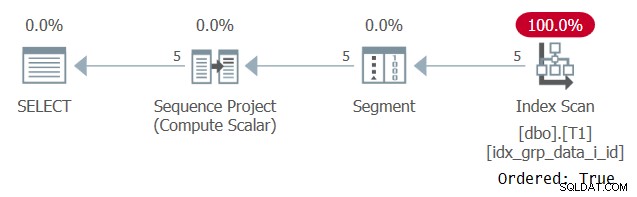 Figur 6:Plan för fråga 5
Figur 6:Plan för fråga 5
Anledningen till att vårt stödjande index skannas med en Ordered:True-egenskap beror på att SQL Server behöver bearbeta varje partitions rader som en enda enhet. Så är fallet före filtrering. Om du bara filtrerar en rad per partition har du både orderbaserade och hashbaserade algoritmer som alternativ.
Det andra steget är att placera frågan med radnummerberäkningen i ett tabelluttryck, och i den yttre frågan filtrera raden med radnummer 1 i varje partition, så här:
WITH C AS
(
SELECT id, grp, datacol,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n
FROM dbo.T1
)
SELECT id, grp, datacol
FROM C
WHERE n = 1; Teoretiskt sett ska denna teknik vara säker, men Paul White hittade en bugg som visar att med den här metoden kan du få attribut från olika källrader i den returnerade resultatraden per partition. Att använda en körtidskonstant baserad på en funktion eller en underfråga baserad på en konstant som beställningselement verkar vara säkert även med detta scenario, så se till att du använder en lösning som följande istället:
WITH C AS
(
SELECT id, grp, datacol,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY (SELECT 'No Order')) AS n
FROM dbo.T1
)
SELECT id, grp, datacol
FROM C
WHERE n = 1; Ingen får passera denna väg utan min tillåtelse
Att försöka beräkna radnummer baserat på icke-deterministisk ordning är ett vanligt behov. Det skulle ha varit trevligt om T-SQL helt enkelt gjort fönsterordningsklausulen valfri för funktionen ROW_NUMBER, men det gör den inte. Om inte, skulle det ha varit trevligt om det åtminstone tillät att använda en konstant som beställningselement, men det är inte heller ett alternativ som stöds. Men om du frågar snällt, i form av en underfråga baserad på en konstant eller en körtidskonstant baserad på en funktion, tillåter SQL Server det. Det här är de två alternativen som jag är mest bekväm med. Jag känner mig inte riktigt bekväm med de konstiga felaktiga uttrycken som verkar fungera så jag kan inte rekommendera det här alternativet.