Jag har tidigare bloggat om varför jag inte älskar sp_updatestats. Jag hittade nyligen en annan anledning till att det inte är min vän. TL;DR:Den uppdaterar inte statistik om indexerade vyer. Nu påstår inte dokumentationen att det gör det, så det finns ingen bugg här. MSDN-dokumentationen säger tydligt:
Kör UPDATE STATISTICS mot alla användardefinierade och interna tabeller i den aktuella databasen.Men... hur många av er tänkte på era indexerade vyer och undrade om de har uppdaterats? Jag erkänner att jag inte gjorde det. Jag glömmer indexerade vyer, vilket är olyckligt eftersom de kan vara riktigt kraftfulla när de används på rätt sätt. De kan också vara en mardröm att reda ut när du felsöker, men jag tänker inte argumentera för deras användning idag. Jag vill bara att du ska vara medveten om att de inte uppdateras av sp_updatestats och se vilka alternativ du har.
Inställningar
Eftersom World Series precis avslutades kommer vi att använda baseballdatabasen för våra tester. Du kan ladda ner den från sidan SQLskills Resources. När den har återställts skapar vi en kopia av tabellen dbo.Players, som heter dbo.PlayerInfo, laddar in några tusen rader i den och skapar sedan en indexerad vy som förenar vår nya tabell med tabellen PitchingPost:
ANVÄND [BaseballData];GO SKAPA TABELL [dbo].[PlayerInfo]( [lahmanID] [int] INTE NULL, [playerID] [varchar](10) NULL DEFAULT (NULL), [managerID] [varchar]( 10) NULL DEFAULT (NULL), [hofID] [varchar](10) NULL DEFAULT (NULL), [birthYear] [int] NULL DEFAULT (NULL), [birthMonth] [int] NULL DEFAULT (NULL), [födelsedag] [int] NULL DEFAULT (NULL), [birthCountry] [varchar](50) NULL DEFAULT (NULL), [birthState] [varchar](2) NULL DEFAULT (NULL), [birthCity] [varchar](50) NULL DEFAULT (NULL), [deathYear] [int] NULL DEFAULT (NULL), [deathMonth] [int] NULL DEFAULT (NULL), [deathDay] [int] NULL DEFAULT (NULL), [deathCountry] [varchar](50) NULL DEFAULT (NULL), [deathState] [varchar](2) NULL DEFAULT (NULL), [deathCity] [varchar](50) NULL DEFAULT (NULL), [nameFirst] [varchar](50) NULL DEFAULT (NULL), [nameLast] [varchar](50) NULL DEFAULT (NULL), [nameNote] [varchar](255) NULL DEFAULT (NULL), [nameGiven] [varchar](255) NULL DEFAULT (NULL), [nameNick] [varchar ](255) NULL DEFAULT (NULL), [vikt] [int] NULL DEFAULT (NULL), [höjd] [int] NULL, [bats] [varchar](1) NULL DEFAULT (NULL), [kastar] [varchar](1) NULL DEFAULT (NULL), [debut] [varchar]( 10) NULL DEFAULT (NULL), [finalGame] [varchar](10) NULL DEFAULT (NULL), [college] [varchar](50) NULL DEFAULT (NULL), [lahman40ID] [varchar](9) NULL DEFAULT ( NULL), [lahman45ID] [varchar](9) NULL DEFAULT (NULL), [retroID] [varchar](9) NULL DEFAULT (NULL), [holtzID] [varchar](9) NULL DEFAULT (NULL), [bbrefID ] [varchar](9) NULL DEFAULT (NULL),PRIMÄRNYCKEL KLUSTERAD ([lahmanID] ASC) PÅ [PRIMÄR]) PÅ [PRIMÄR];GO SÄTT IN I [dbo].[PlayerInfo] ([lahmanID] ,[playerID] ,[managerID],[hofID],[födelseår],[födelsemånad],[födelsedag],[födelseland],[födelsestat],[födelsestad],[dödsår],[dödsmånad],[dödsdag] ,[,[dödsland] deathState], [deathCity] ,[nameFirst] ,[nameLast] ,[nameNote] ,[nameGiven] ,[nameNick] ,[vikt] ,[höjd] ,[fladdermöss] ,[kast] ,[debut] ,[slutspel] ,[college] ,[lahman40ID] ,[lahman45ID] ,[ retroID] ,[holtzID] ,[bbrefID]) SELECT [lahmanID] ,[spelare-ID],[managerID],[hofID],[födelseår],[födelsemånad],[födelsedag],[födelseland],[födelsestat] ,[födelsestad] ],[deathYear],[deathMonth],[deathDay],[deathCountry],[deathState],[deathCity],[nameFirst],[nameLast],[nameNote] ,[nameGiven] ,[nameNick] ,[weight] , [höjd] ,[fladdermöss] ,[kast] ,[debut] ,[slutspel] ,[högskola] ,[lahman40ID] ,[lahman45ID],[retroI D],[holtzID] ,[bbrefID]FRÅN [dbo].[Spelare]VAR [lahmanID] <=10000; SKAPA VISA [PlayerPostSeason]Med SCHEMABINDINGAS SELECT [p].[lahmanID], [p].[nameFirst], [p].[nameLast], [p].[debut], [p].[finalGame], [pp ].[yearID], [pp].[runda], [pp].[teamID], [pp].[W], [pp].[L], [pp].[G] FRÅN [dbo]. [PlayerInfo] [p] JOIN [dbo].[PitchingPost] [pp] PÅ [p].[playerID] =[pp].[playerID]; SKAPA UNIKT CLUSTERED INDEX [CI_PlayerPostSeason] PÅ [PlayerPostSeason] ([lahmanID], [yearID], [round]); SKAPA INKLUSTERAT INDEX [NCI_PlayerPostSeason_Name] PÅ [PlayerPostSeason] ([nameFirst], [nameLast]);
Om vi kontrollerar statistik för de klustrade och icke-klustrade indexen ser vi att de finns:
DBCC SHOW_STATISTICS ('PlayerPostSeason', CI_PlayerPostSeason) WITH STAT_HEADER;GODBCC SHOW_STATISTICS ('PlayerPostSeason', NCI_PlayerPostSeason_Name) WITH STAT_HEADER;GO
 Indexvisningsstatistik efter första skapandet
Indexvisningsstatistik efter första skapandet
Nu kommer vi att infoga fler rader i PlayerInfo:
INSERT INTO [dbo].[PlayerInfo] ([lahmanID] ,[playerID],[managerID] ,[hofID],[födelseår],[födelsemånad],[födelsedag],[födelseland],[födelsestat] ,[ födelsestad],[dödsår],[dödsmånad],[dödsdag],[dödsland],[dödsstat],[dödsstad],[namnFörsta],[namnLast],[namnAnteckning] ,[namnGiven],[namnNick] ,[vikt] ,[höjd] ,[fladdermöss] ,[kast] ,[debut] ,[slutspel] ,[college] ,[lahman40ID] ,[lahman45ID] ,[retroID] ,[holtzID] ,[bbrefID])VÄLJ [lahmanID] , [playerID] ,[managerID] ,[hofID],[födelseår],[födelsemånad],[födelsedag],[födelseland],[födelsestat],[födelsestad] ,[deathYear],[deathMonth],[deathDay] ,[deathCountry],[deathState],[deathCity],[nameFirst],[nameLast] ,[nameNote],[nameGiven],[nameNick] ,[weight] ,[ höjd] ,[fladdermöss],[kast] ,[debut] ,[slutspel] ,[college] ,[lahman40ID],[lahman45ID],[retroID] ,[holtzID],[bbrefID]FRÅN [dbo].[Spelare] WHERE [lahmanID]> 10000;
Och om vi kontrollerar sys.dm_db_stats_properties kan vi se radändringarna:
VÄLJ [sch].[namn] AS [Schema], [så].[namn] AS [ObjectName], [so].[typ] AS [ObjectType], [ss].[namn] AS [Statistics ], [sp].[last_updated] AS [StatsLastUpdated] , [sp].[rows] AS [RowsInTable] , [sp].[rows_sampled] AS [RowsSampled] , [sp].[modification_counter] AS [RowModifications]FROM [sys].[objects] [so]JOIN [sys].[stats] [ss] PÅ [so].[object_id] =[ss].[object_id]JOIN [sys].[schemas] [sch] ON [ so].[schema_id] =[sch].[schema_id]YTTRE APPLY [sys].[dm_db_stats_properties]([so].[object_id], [ss].[stats_id]) spWHERE [so].[name] =' PlayerPostSeason';
 Rader modifierade i den indexerade vyn, via sys.dm_db_stats_properties
Rader modifierade i den indexerade vyn, via sys.dm_db_stats_properties
Och bara för skojs skull, om vi kollar sys.sysindexes kan vi se ändringarna där också:
VÄLJ [så].[namn], [si].[namn], [si].[rowcnt], [si].[rowmodctr]FRÅN [sys].[sysindexes] [si]GÅ MED [sys] .[objekt] [så] PÅ [si].[id] =[så].[object_id]WHERE [så].[name] ='PlayerPostSeason';
 Rader modifierade i den indexerade vyn, via sys.sysindexes
Rader modifierade i den indexerade vyn, via sys.sysindexes
Nu är sys.sysindexes utfasad, men om du kommer ihåg från mitt tidigare inlägg så är det vad sp_updatestats använder för att se vad som har ändrats. Men... objektlistan för sys.indexes drivs av frågan mot sys.objects, som, om du kommer ihåg, filtrerar på användartabeller ('U') och interna tabeller ('IT'). Det inkluderar inte vyer ('V') i det filtret. Som sådan, när vi kör sp_updatestats och kontrollerar utdata (ingår inte för korthetens skull), nämns det inget om vår PlayerPostSeason-vy.
Därför, om du har indexerade vyer och du litar på sp_updatestats för att uppdatera din statistik, uppdateras inte din visningsstatistik. Jag skulle dock gissa att de flesta av er har alternativet Auto Update Statistics aktiverat för era databaser. Detta är bra, för med det här alternativet uppdateras visningsstatistiken om den har blivit ogiltig. Vi vet att vi har gjort över 2000 ändringar av indexen på PlayerPostSeason. Om vi frågar efter ett förnamn som är selektivt, bör vår frågeplan använda NCI_PlayerPostSeason_Name-indexet, och eftersom statistiken är inaktuell bör den uppdateras. Låt oss kontrollera:
VÄLJ *FRÅN [PlayerPostSeason]WHERE [nameFirst] ='Madison';GO
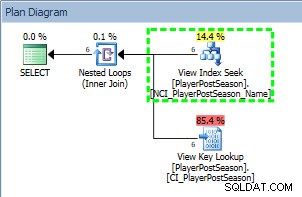 Frågeplan från SELECT mot icke-klustrade index
Frågeplan från SELECT mot icke-klustrade index
Vi kan se i planen att det icke-klustrade indexet NCI_PlayerPostSeason_Name användes, och om vi kontrollerar statistik:
 Statistik efter automatisk uppdatering
Statistik efter automatisk uppdatering
Visst har statistiken för det icke-klustrade indexet uppdaterats. Men vi vill naturligtvis inte förlita oss på automatisk uppdatering för att hantera statistik, vi vill vara proaktiva. Vi har två alternativ:
- Underhållsuppgift
- Anpassat skript
Underhållsuppgiften för uppdatering av statistik gör uppdatera visningsstatistik. Detta kallas inte specifikt någonstans i användargränssnittet, men om vi skapar en underhållsplan med uppgiften uppdateringsstatistik och kör den uppdateras statistiken för den indexerade vyn. Nackdelen med att uppdatera statistikunderhållsuppgiften är att det är en slägghammare. Den uppdaterar alla statistik, oavsett om det behövs (det är nästan lika illa som sp_updatestats). Jag föredrar ett anpassat skript, där SQL Server bara uppdaterar det som har ändrats. Om du inte är sugen på att rulla ditt eget manus kan du använda Ola Hallengrens manus. Det är vanligt att uppdatera statistik som en del av dina indexombyggnader och omorganiseringar. Till exempel, med Olas skript i SQL Agent-jobbet skulle du ha:
sqlcmd -E -S $(ESCAPE_SQUOTE(SRVR)) -d master -Q "EXECUTE [dbo].[IndexOptimize] @Databases ='BaseballData', @FragmentationLow =NULL, @FragmentationMedium ='INDEX_REORGANIZEH_igREBULDEXH, @FRAgmentation ='BaseballData' ', @FragmentationLevel1 =5, @FragmentationLevel2 =30, @UpdateStatistics ='ALLA', @OnlyModifiedStatistics ='Y', @LogToTable ='Y'" –bMed det här alternativet, om statistiken har ändrats, kommer den att uppdateras, och om vi markerar den lagrade proceduren [dbo].[IndexOptimize] kan vi se var Ola söker efter ändringar:
-- Har uppgifterna i statistiken ändrats sedan statistiken senast uppdaterades? OM @CurrentStatisticsID INTE ÄR NULL OCH @UpdateStatistics INTE ÄR NULL OCH @OnlyModifiedStatistics ='Y' BÖRJA SET @CurrentCommand10 ='' OM @LockTimeout INTE ÄR NULL SET @CurrentCommand10 ='SET LOCK_TIMEOUT ' + CAST(@nock0) + '; ' IF (@Version>=10.504000 OCH @Version <11) ELLER @Version>=11.03000 BEGIN SET @CurrentCommand10 =@CurrentCommand10 + 'USE ' + QUOTENAME(@CurrentDatabaseName) + '; IF EXISTS(SELECT * FROM sys.dm_db_stats_properties (@ParamObjectID, @ParamStatisticsID) WHERE modification_counter> 0) BEGIN SET @ParamStatisticsModified =1 END' END ELSE BEGIN SET @CurrentCommand10 ='TEIST0(+'SELECTUcommando VALD) @CurrentDatabaseName) + '.sys.sysindexes sysindexes WHERE sysindexes.[id] =@ParamObjectID AND sysindexes.[indid] =@ParamStatisticsID AND sysindexes.[rowmodctr] <> 0) BEGIN SET @ParamStatisticsModified' END pre.>För versioner som stöder sys.dm_db_stats_properties DMF, kontrollerar Ola den för eventuell statistik som har ändrats, och för versioner som inte stöder den nya sys.dm_db_stats_properties DMF kontrolleras systemtabellen sys.sysindexes. Mitt enda klagomål här är att skriptet beter sig på samma sätt som sp_updatestats:om minst en rad har ändrats kommer statistiken att uppdateras.
Om du inte gillar att skriva din egen kod för att hantera statistik, skulle jag rekommendera att du håller dig till Olas skript. Men om du vill rikta in dina uppdateringar lite mer, rekommenderar jag att du använder sys.dm_db_stats_properties. Denna DMF är endast tillgänglig för SQL Server 2008R2 SP2 och högre, och SQL Server 2012 SP1 och högre, så om du har en lägre version måste du använda sys.indexes. Men för er som har tillgång till sys.dm_db_stats_properties, här är en fråga för att komma igång:
VÄLJ [sch].[namn] AS [Schema], [så].[namn] AS [ObjectName], [so].[typ] AS [ObjectType], [ss].[namn] AS [Statistics ], [sp].[last_updated] AS [StatsLastUpdated] , [sp].[rows] AS [RowsInTable] , [sp].[rows_sampled] AS [RowsSampled] , CAST(100 * [sp].[rows_sampled] / [sp].[rader] AS DECIMAL (18, 2)) AS [PercentSampled], [sp].[modification_counter] AS [RowModifications] , CAST(100 * [sp].[modification_counter] / [sp].[rader] ] SOM DECIMAL(18, 2)) SOM [PercentChange]FRÅN [sys].[objects] SOM [so]INNER JOIN [sys].[stats] AS [ss] PÅ [so].[object_id] =[ss] .[object_id]INNER JOIN [sys].[schemas] AS [sch] PÅ [so].[schema_id] =[sch].[schema_id]YTTRE APPLY [sys].[dm_db_stats_properties]([so].[object_id] , [ss].[stats_id]) SOM [sp]WHERE [så].[typ] IN ('U','V')AND ((CAST(100 * [sp].[modifieringsräknare] / [sp]. [rader] SOM DECIMAL(18,2))>=10,0))ORDER BY CAST(100 * [sp].[modifieringsräknare] / [sp].[rader] SOM DECIMAL(18, 2)) DESC;Observera att med sys.objects filtrerar vi på tabeller och vyer; du kan ändra detta till att inkludera systemtabeller. Du kan sedan ändra predikatet för att bara hämta rader baserat på procentandelen rader som ändrats, eller kanske en kombination av modifieringsprocent och antal rader (för tabeller med miljoner eller miljarder rader kan den procentandelen vara lägre än för små tabeller).
Sammanfattning
Hemmeddelandet här är ganska tydligt:jag rekommenderar inte att du använder sp_updatestats för att hantera statistik. Statistiken uppdateras när en eller flera rader har ändrats (vilket är en extremt låg tröskel för att uppdatera statistik) och statistik för indexerade vyer är inte uppdaterad. Detta är inte en heltäckande och effektiv metod för att hantera statistik ... och uppgiften att uppdatera statistik i en underhållsplan är inte mycket bättre. Den uppdaterar den indexerade vystatistiken, men den uppdaterar varje statistik, oavsett ändringar. Ett anpassat skript är verkligen rätt väg att gå, men förstå att Ola Hallengrens script, om du uppdaterar baserat på modifiering, också uppdateras när bara raden har modifierats (men det får åtminstone de indexerade vyerna). I slutändan, för bästa kontroll, se efter att rulla ditt eget skript för att hantera statistik. Jag har gett dig grundfrågan för att börja. Om du kan spärra av ett par timmar för att öva på att skriva T-SQL och sedan testa det, har du ett fungerande anpassat skript redo för dina databaser innan semestern börjar.