Tidsseriedatabaser, som namnet antyder, är designade för att lagra data som förändras med tiden. Detta kan vara vilken typ av data som helst som har samlats in över tid. Det kan vara mätvärden som samlats in från vissa system, och faktiskt är alla trendsystem exempel på tidsseriedata.
Vi har olika typer av tidsseriedatabaser, vilka ska vi använda?
I den här bloggen kommer vi att se vad som är de viktigaste skillnaderna mellan två av huvudalternativen, TimescaleDB och InfluxDB.
InfluxDB
InfluxDB har skapats av InfluxData. Det är en anpassad, öppen källkod, NoSQL-tidsseriedatabas skriven i Go. Datalagret tillhandahåller ett SQL-liknande språk för att fråga data, kallat InfluxQL, vilket gör det enkelt för utvecklarna att integrera i sina applikationer. Den har också ett nytt anpassat frågespråk som heter Flux, det här språket kan göra vissa uppgifter lättare, men det finns alltid en inlärningskurva när man använder ett anpassat frågespråk.
Det här är ett exempel på en Flux-fråga:
from(db:"testing")
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "cpu")
|> exponentialMovingAverage()I denna databas har varje mätning en tidsstämpel och en tillhörande uppsättning taggar och uppsättning fält. Fältet representerar de faktiska mätvärdena, medan taggen representerar metadata för att beskriva mätningarna. Fältdatatyperna är begränsade till flytningar, ints, strängar och booleaner och kan inte ändras utan att skriva om data. Taggvärdena indexeras. De representeras som strängar och kan inte uppdateras.
InfluxDB är ganska lätt att komma igång, eftersom du inte behöver oroa dig för att skapa scheman eller index. Den är dock ganska stel och begränsad, utan möjlighet att skapa ytterligare index, index på kontinuerliga fält, uppdatera metadata i efterhand, genomdriva datavalidering, etc.
Det är inte schemalöst. Det finns ett underliggande schema som skapas automatiskt från indata.
InfluxDB måste implementera från början flera verktyg för feltolerans, som replikering, hög tillgänglighet och säkerhetskopiering/återställning, och det är ansvarigt för dess tillförlitlighet på disken. Vi är begränsade till att använda dessa verktyg och många av dessa funktioner, som HA, är endast tillgängliga i företagsversionen.
InfluxDB-säkerhetskopieringsverktyget kan utföra en fullständig eller inkrementell säkerhetskopiering, och det kan användas för punkt-i-tid-återställning.
InfluxDB erbjuder också betydligt bättre komprimering på disk än PostgreSQL och TimescaleDB.
TimescaleDB
TimescaleDB är en tidsseriedatabas med öppen källkod optimerad för snabb inmatning och komplexa frågor som stöder fullständig SQL. Den är baserad på PostgreSQL och den erbjuder det bästa av NoSQL och relationsvärldar för tidsseriedata.
Detta är ett TimescaleDB-frågeexempel:
SELECT time,
exponential_moving_average(value, 0.5) OVER (ORDER BY time)
FROM testing
WHERE measurement = cpu and time > now() - '1 hour';TimescaleDB, som en PostgreSQL-tillägg, är en relationsdatabas. Detta gör det möjligt att ha en kort inlärningskurva för nya användare, och att ärva verktyg som pg_dump eller pg_backup för säkerhetskopiering och verktyg med hög tillgänglighet, vilket är en fördel framför andra tidsseriedatabaser. Den stöder också strömmande replikering som den primära metoden för replikering, som kan användas i en högtillgänglighetsinställning. När det gäller failover och säkerhetskopiering kan du automatisera denna process genom att använda ett externt system som ClusterControl.
I TimescaleDB registreras varje tidsseriemätning i sin egen rad, med ett tidsfält följt av valfritt antal andra fält, som kan vara flytningar, ints, strängar, booleaner, arrayer, JSON-blobbar, geospatiala dimensioner, datum/tid/ tidsstämplar, valutor, binär data och mer.
Du kan skapa index på vilket fält som helst (standardindex) eller flera fält (sammansatta index), eller på uttryck som funktioner, eller till och med begränsa ett index till en delmängd av rader (partiellt index). Vilket som helst av dessa fält kan användas som en främmande nyckel till sekundära tabeller, som sedan kan lagra ytterligare metadata.
På detta sätt måste du välja ett schema och bestämma vilka index du behöver för ditt system.
Prestanda
Om vi pratar om prestanda kan vi kolla in den fantastiska TimescaleDB jämförelsebloggen. Där har du en detaljerad jämförelse för prestanda mellan båda databaserna med diagram och mått. Låt oss se en del av den viktigaste informationen från den här bloggen.
Infogningar
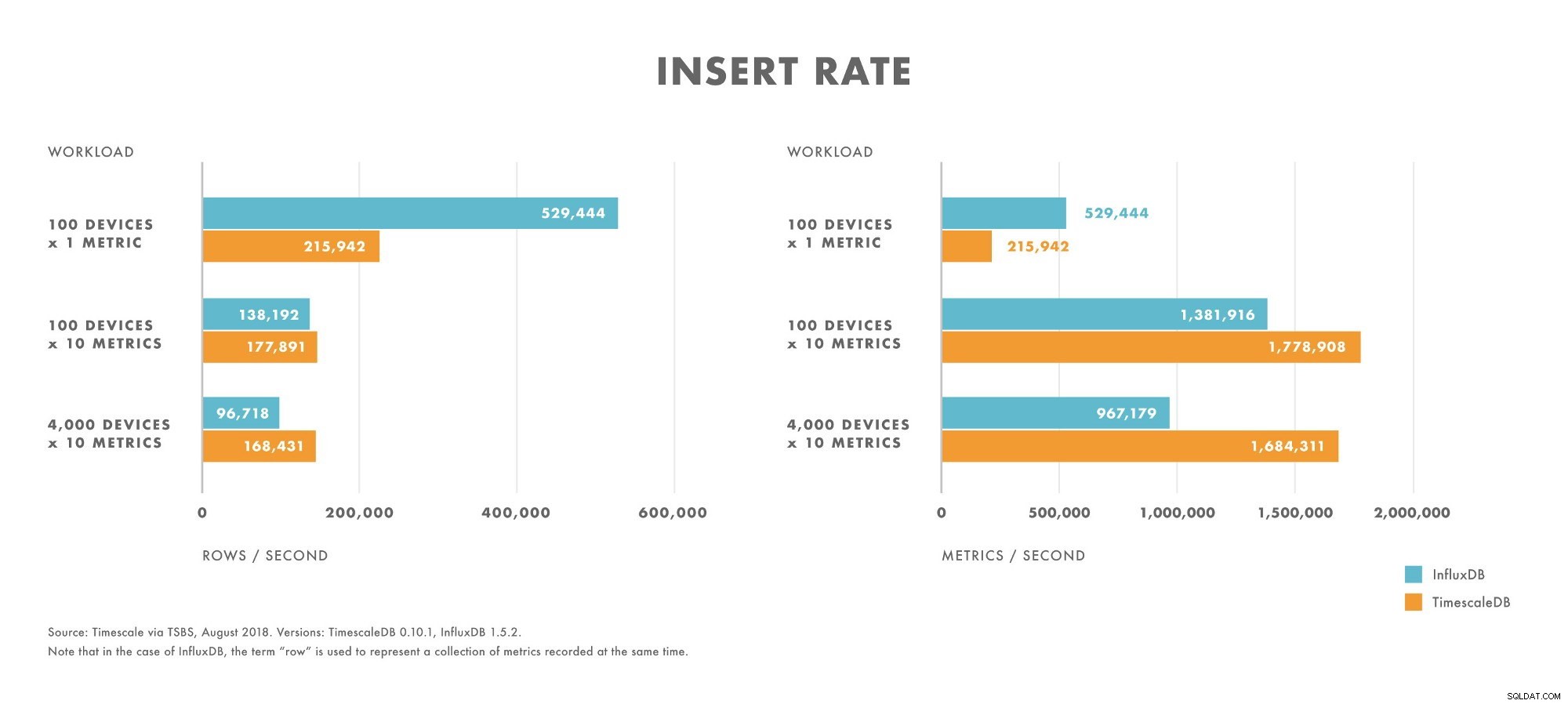
- För arbetsbelastningar med mycket låg kardinalitet (t.ex. 100 enheter) överträffar InfluxDB TimescaleDB.
- När kardinaliteten ökar sjunker prestandan för InfluxDB-insättningar snabbare än på TimescaleDB.
- För arbetsbelastningar med måttlig till hög kardinalitet (t.ex. 100 enheter som skickar 10 mätvärden), överträffar TimescaleDB InfluxDB.

Läsfördröjning
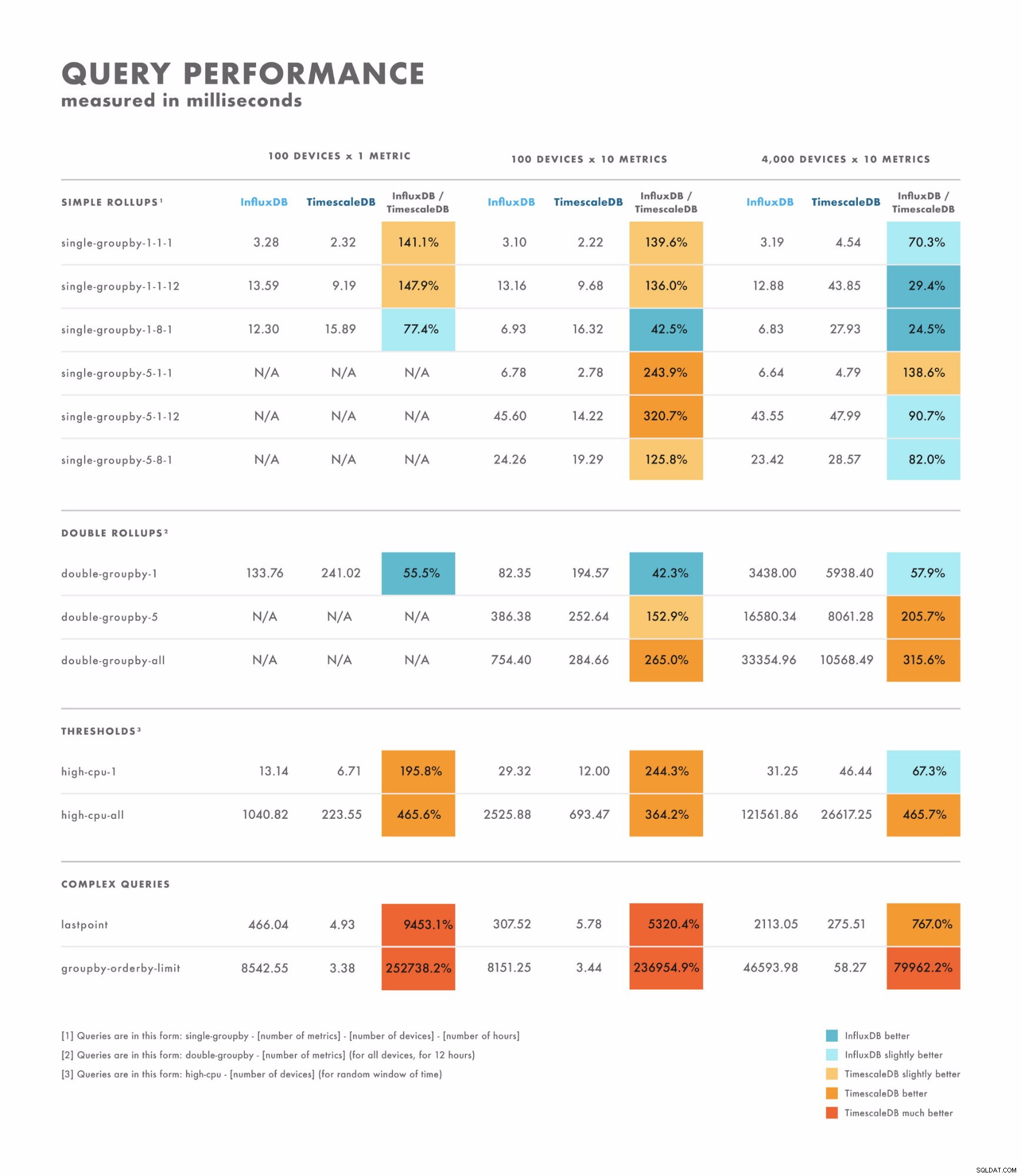
- För enkla frågor varierar resultaten ganska mycket:det finns några där en databas är klart bättre än den andra, medan andra beror på din datauppsättnings kardinalitet. Skillnaden här ligger ofta i intervallet ensiffriga till tvåsiffriga millisekunder.
- För komplexa frågor överträffar TimescaleDB avsevärt InfluxDB och stöder ett bredare utbud av frågetyper. Skillnaden här ligger ofta i intervallet sekunder till tiotals sekunder.
- Med det i åtanke är det bästa sättet att testa ordentligt att jämföra med de frågor du planerar att köra.
Stabilitetsproblem
- InfluxDB har stabilitets- och prestandaproblem vid höga (100K+) kardinaliteter.
Slutsats
Om din data passar in i InfluxDB-datamodellen, och du inte förväntar dig att förändras i framtiden, bör du överväga att använda InfluxDB eftersom denna modell är lättare att komma igång med, och som de flesta databaser som använder ett kolumnorienterat tillvägagångssätt, erbjuder bättre komprimering på disk än PostgreSQL och TimescaleDB.
Den relationella modellen är dock mer mångsidig och erbjuder mer funktionalitet, flexibilitet och kontroll än InfluxDB-modellen. Detta är särskilt viktigt när din applikation utvecklas. Och när du planerar ditt system bör du ta hänsyn till både dess nuvarande och framtida behov.
I den här bloggen kunde vi se en kort jämförelse mellan TimescaleDB och InfluxDB, och vi kan säga att TimescaleDB som en PostgreSQL-förlängning ser ganska mogen och funktionsrik ut eftersom den ärver mycket från PostgreSQL. Men du kan ta ditt eget beslut baserat på de för- och nackdelar som nämnts tidigare i den här bloggen, och se till att du jämför din egen arbetsbelastning. Lycka till i denna nya tidsseriedatabasvärld!