Nuförtiden är Docker det vanligaste verktyget för att skapa, distribuera och köra applikationer med hjälp av behållare. Det tillåter oss att paketera en applikation med alla delar den behöver, såsom bibliotek och andra beroenden, och skicka ut allt som ett paket. Det kan betraktas som en virtuell maskin, men istället för att skapa ett helt virtuellt operativsystem tillåter Docker applikationer att använda samma Linux-kärna som systemet de körs på och kräver bara att applikationer skickas med saker som inte redan körs på värddatorn. Detta ger en betydande prestandaökning och minskar storleken på applikationen.
När det gäller Docker Images kommer de med en fördefinierad OS-version och paketen installeras på ett sätt som bestämts av personen som skapade bilden. Det är möjligt att du vill använda ett annat operativsystem eller att du kanske vill installera paketen på ett annat sätt. I dessa fall bör du använda en ren OS Docker Image och installera programvaran från början.
Replikering är en vanlig funktion i en databasmiljö, så efter att ha implementerat TimescaleDB Docker Images, om du vill konfigurera en replikeringsinställning, måste du göra det manuellt från behållaren, genom att använda en Docker-fil eller till och med ett skript. Den här uppgiften kan vara komplex om du inte har Docker-kunskap.
I den här bloggen kommer vi att se hur vi kan distribuera TimescaleDB via Docker genom att använda en TimescaleDB Docker Image, och sedan kommer vi att se hur man installerar den från början genom att använda en CentOS Docker Image och ClusterControl.
Hur man distribuerar TimescaleDB med en Docker Image
Låt oss först se hur du distribuerar TimescaleDB genom att använda en Docker Image tillgänglig på Docker Hub.
$ docker search timescaledb
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
timescale/timescaledb An open-source time-series database optimize… 52Vi tar det första resultatet. Så vi måste dra den här bilden:
$ docker pull timescale/timescaledbOch kör nodbehållarna som mappar en lokal port till databasporten i behållaren:
$ docker run -d --name timescaledb1 -p 7551:5432 timescale/timescaledb
$ docker run -d --name timescaledb2 -p 7552:5432 timescale/timescaledbEfter att ha kört dessa kommandon bör du skapa denna Docker-miljö:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6d3bfc75fe39 timescale/timescaledb "docker-entrypoint.s…" 15 minutes ago Up 15 minutes 0.0.0.0:7552->5432/tcp timescaledb2
748d5167041f timescale/timescaledb "docker-entrypoint.s…" 16 minutes ago Up 16 minutes 0.0.0.0:7551->5432/tcp timescaledb1Nu kan du komma åt varje nod med följande kommandon:
$ docker exec -ti [db-container] bash
$ su postgres
$ psql
psql (9.6.13)
Type "help" for help.
postgres=#Som du kan se innehåller denna Docker-bild en TimescaleDB 9.6-version som standard, och den är installerad på Alpine Linux v3.9. Du kan använda en annan TimescaleDB-version genom att ändra taggen:
$ docker pull timescale/timescaledb:latest-pg11Sedan kan du skapa en databasanvändare, ändra konfigurationen enligt dina krav eller konfigurera replikering mellan noderna manuellt.
Hur man distribuerar TimescaleDB med ClusterControl
Låt oss nu se hur man distribuerar TimescaleDB med Docker genom att använda en CentOS Docker Image (centos) och en ClusterControl Docker Image (severalnines/clustercontrol).
Först kommer vi att distribuera en ClusterControl Docker Container med den senaste versionen, så vi måste dra fleranines/clustercontrol Docker Image.
$ docker pull severalnines/clustercontrolSedan kör vi ClusterControl-behållaren och publicerar port 5000 för att komma åt den.
$ docker run -d --name clustercontrol -p 5000:80 severalnines/clustercontrolNu kan vi öppna ClusterControl UI på https://[Docker_Host]:5000/clustercontrol och skapa en standardadminanvändare och ett lösenord.
CentOS Official Docker Image kommer utan SSH-tjänst, så vi installerar den och tillåter anslutning från ClusterControl-noden med lösenordslös genom att använda en SSH-nyckel.
$ docker search centos
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
centos The official build of CentOS. 5378 [OK]Så vi tar fram CentOS Official Docker Image.
$ docker pull centosSedan kör vi två nodbehållare, timescale1 och timescale2, länkade med ClusterControl och vi mappar en lokal port för att ansluta till databasen (valfritt).
$ docker run -dt --privileged --name timescale1 -p 8551:5432 --link clustercontrol:clustercontrol centos /usr/sbin/init
$ docker run -dt --privileged --name timescale2 -p 8552:5432 --link clustercontrol:clustercontrol centos /usr/sbin/initEftersom vi behöver installera och konfigurera SSH-tjänsten måste vi köra behållaren med privilegierade och /usr/sbin/init-parametrar för att kunna hantera tjänsten inuti behållaren.
Efter att ha kört dessa kommandon bör vi skapa denna Docker-miljö:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
230686d8126e centos "/usr/sbin/init" 4 seconds ago Up 3 seconds 0.0.0.0:8552->5432/tcp timescale2
c0e7b245f7fe centos "/usr/sbin/init" 23 seconds ago Up 22 seconds 0.0.0.0:8551->5432/tcp timescale1
7eadb6bb72fb severalnines/clustercontrol "/entrypoint.sh" 2 weeks ago Up About an hour (healthy) 22/tcp, 443/tcp, 3306/tcp, 9500-9501/tcp, 9510-9511/tcp, 9999/tcp, 0.0.0.0:5000->80/tcp clustercontrolVi kan komma åt varje nod med följande kommando:
$ docker exec -ti [db-container] bashSom vi nämnde tidigare måste vi installera SSH-tjänsten, så låt oss installera den, tillåta root-åtkomst och ställa in root-lösenordet för varje databasbehållare:
$ docker exec -ti [db-container] yum update -y
$ docker exec -ti [db-container] yum install -y openssh-server openssh-clients
$ docker exec -it [db-container] sed -i 's|^#PermitRootLogin.*|PermitRootLogin yes|g' /etc/ssh/sshd_config
$ docker exec -it [db-container] systemctl start sshd
$ docker exec -it [db-container] passwdDet sista steget är att ställa in den lösenordslösa SSH för alla databasbehållare. För detta behöver vi veta IP-adressen för varje databasnod. För att veta det kan vi köra följande kommando för varje nod:
$ docker inspect [db-container] |grep IPAddress
"IPAddress": "172.17.0.5",Fäst sedan till ClusterControl-behållarens interaktiva konsol:
$ docker exec -it clustercontrol bashOch kopiera SSH-nyckeln till alla databasbehållare:
$ ssh-copy-id 172.17.0.5Nu har vi servernoderna igång, vi måste distribuera vårt databaskluster. För att göra det på ett enkelt sätt använder vi ClusterControl.
För att utföra en distribution från ClusterControl, öppna ClusterControl UI på https://[Docker_Host]:5000/clustercontrol, välj sedan alternativet "Deploy" och följ instruktionerna som visas.
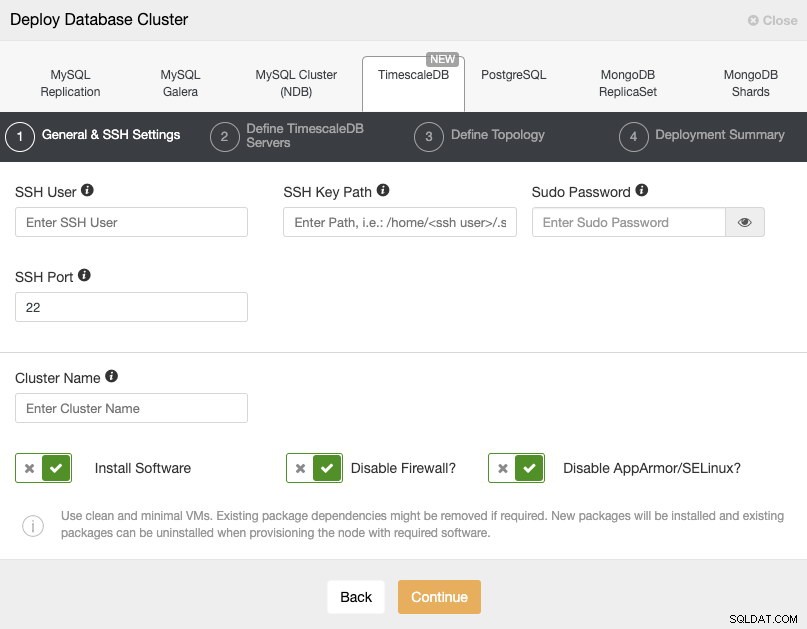
När vi väljer TimescaleDB måste vi ange Användare, Nyckel eller Lösenord och port för att ansluta med SSH till våra servrar. Vi behöver också ett namn för vårt nya kluster och om vi vill att ClusterControl ska installera motsvarande programvara och konfigurationer åt oss.
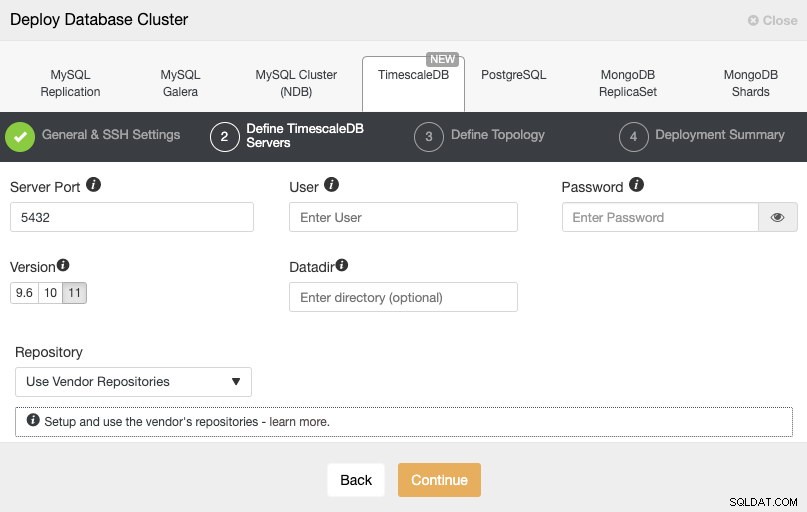
Efter att ha ställt in SSH-åtkomstinformationen måste vi definiera databasanvändare, version och datadir (valfritt). Vi kan också specificera vilket arkiv som ska användas.
I nästa steg måste vi lägga till våra servrar i klustret som vi ska skapa.
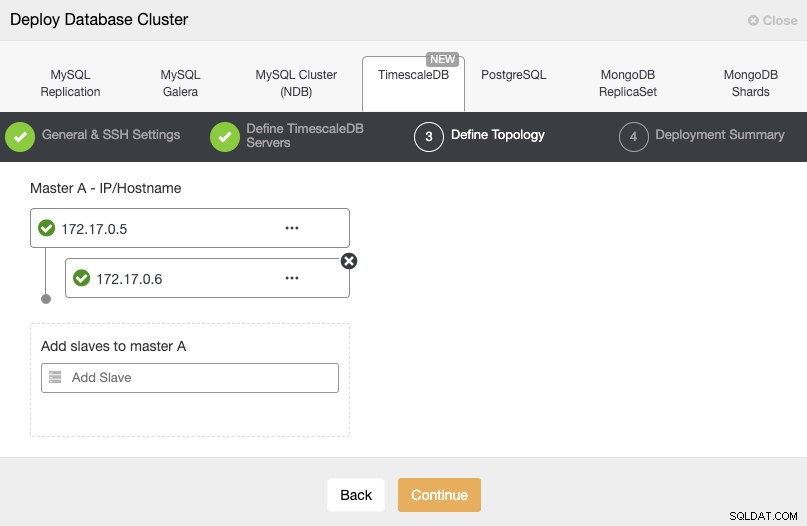
Här måste vi använda IP-adressen som vi fick från varje container tidigare.
I det sista steget kan vi välja om vår replikering ska vara Synchronous eller Asynchronous.
Vi kan övervaka statusen för skapandet av vårt nya kluster från ClusterControl-aktivitetsmonitorn.
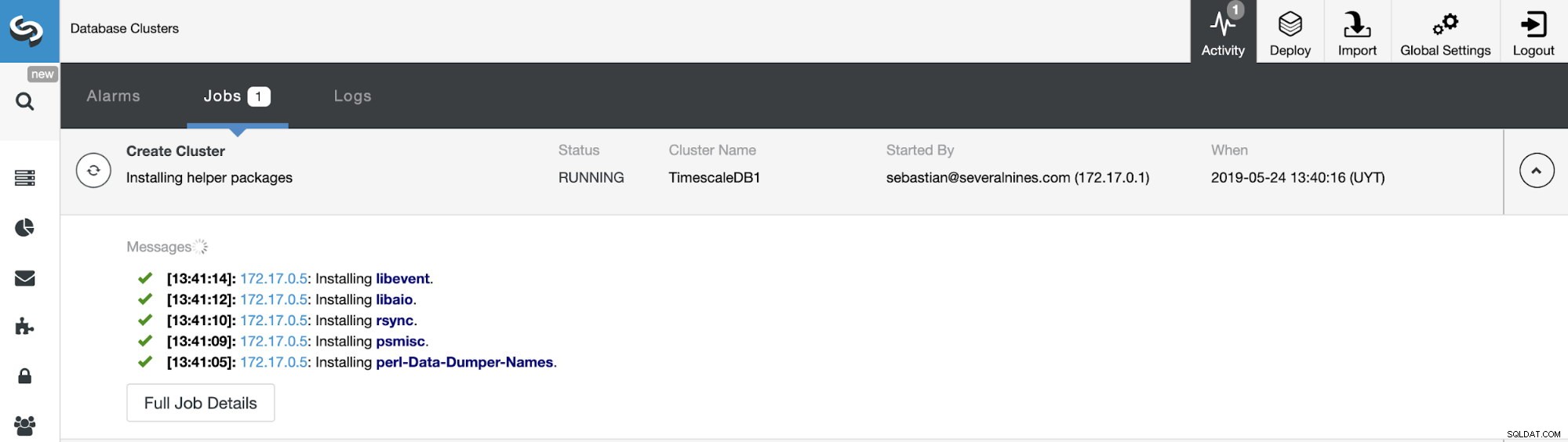
När uppgiften är klar kan vi se vårt kluster på huvudskärmen för ClusterControl.

Observera att om du vill lägga till fler standbynoder kan du göra det från ClusterControl UI på menyn Cluster Actions.
På samma sätt, om du har ditt TimescaleDB-kluster igång på Docker och du vill att ClusterControl ska hantera det för att kunna använda alla funktioner i detta system som övervakning, säkerhetskopiering, automatisk failover och ännu mer, kan du helt enkelt köra ClusterControl-behållare i samma Docker-nätverk som databasbehållarna. Det enda kravet är att säkerställa att målbehållarna har SSH-relaterade paket installerade (openssh-server, openssh-clients). Tillåt sedan lösenordslös SSH från ClusterControl till databasbehållarna. När du är klar använder du funktionen "Importera befintlig server/kluster" och klustret bör importeras till ClusterControl.
Ett möjligt problem med att köra behållare är IP-adressen eller värdnamnstilldelningen. Utan ett orkestreringsverktyg som Kubernetes kan IP-adressen eller värdnamnet vara annorlunda om du stoppar noderna och skapar nya behållare innan du startar dem igen. Du kommer att ha en annan IP-adress för de gamla noderna och ClusterControl antar att alla noder körs i en miljö med en dedikerad IP-adress eller värdnamn, så efter att IP-adressen ändrats bör du importera om klustret till ClusterControl. Det finns många lösningar för det här problemet, du kan kolla den här länken för att använda Kubernetes med StatefulSet, eller den här för att köra containrar utan orkestreringsverktyg.
Slutsats
Som vi kunde se bör driftsättningen av TimescaleDB med Docker vara lätt om du inte vill konfigurera en replikerings- eller failover-miljö och om du inte vill göra några ändringar i OS-versionen eller installationen av databaspaket.
Med ClusterControl kan du importera eller distribuera ditt TimescaleDB-kluster med Docker genom att använda den OS-avbildning som du föredrar, samt automatisera övervaknings- och hanteringsuppgifter som säkerhetskopiering och automatisk failover/återställning.