Som SQL Server DBA:er har vi hört att indexstrukturer dramatiskt kan förbättra prestandan för en given fråga (eller uppsättning frågor). Ändå finns det vissa detaljer som många DBA:er förbiser, som följande:
- Indexstrukturer kan bli fragmenterade, vilket kan leda till prestandaförsämringar.
- När en indexstruktur har distribuerats för en databastabell, uppdaterar SQL Server den närhelst skrivoperationer äger rum för den tabellen. Detta händer om kolumnerna som överensstämmer med indexet påverkas.
- Det finns metadata inuti SQL Server som kan användas för att veta när statistiken för en viss indexstruktur uppdaterades (om någonsin) för sista gången. Otillräcklig eller föråldrad statistik kan påverka prestandan för vissa frågor.
- Det finns metadata inuti SQL Server som kan användas för att veta hur mycket en indexstruktur antingen har förbrukats av läsoperationer eller uppdaterats av skrivoperationer av SQL Server själv. Denna information kan vara användbar för att veta om det finns index vars skrivvolym vida överstiger den lästa. Det kan potentiellt vara en indexstruktur som inte är så användbar att ha kvar.*
*Det är mycket viktigt att komma ihåg att systemvyn som innehåller just denna metadata raderas varje gång SQL Server-instansen startas om, så det kommer inte att vara information från dess uppfattning.
På grund av vikten av dessa detaljer har jag skapat en lagrad procedur för att hålla reda på information om indexstrukturer i hans/hennes miljö, för att agera så proaktivt som möjligt.
Inledande överväganden
- Se till att kontot som kör denna lagrade procedur har tillräckligt med privilegier. Du kan antagligen börja med systemadministratörerna och sedan gå så detaljerat som möjligt för att se till att användaren har det minimum av behörigheter som krävs för att SP ska fungera korrekt.
- Databasobjekten (databastabell och lagrad procedur) kommer att skapas i den databas som valts vid den tidpunkt då skriptet körs, så välj med omsorg.
- Skriptet är skapat på ett sätt så att det kan köras flera gånger utan att få ett felmeddelande. För den lagrade proceduren använde jag CREATE OR ALTER PROCEDURE-satsen, tillgänglig sedan SQL Server 2016 SP1.
- Ändra gärna namnet på de skapade databasobjekten om du vill använda en annan namnkonvention.
- När du väljer att bevara data som returneras av den lagrade proceduren, kommer måltabellen först att trunkeras så att endast den senaste resultatuppsättningen kommer att lagras. Du kan göra nödvändiga justeringar om du vill att detta ska bete sig annorlunda, oavsett anledning (för att behålla historisk information kanske?).
Hur använder man den lagrade proceduren?
- Kopiera och klistra in T-SQL-koden (tillgänglig i den här artikeln).
- SP:n förväntar sig två parametrar:
- @persistData:'Y' om DBA vill spara utdata i en måltabell, och 'N' om DBA bara vill se utdata direkt.
- @db:'alla' för att få information om alla databaser (system &användare), 'användare' för att rikta in sig på användardatabaser, 'system' för att endast rikta in sig på systemdatabaser (exklusive tempdb), och sist det faktiska namnet på en viss databas.
Fält som presenteras och deras betydelse
- dbName: namnet på databasen där indexobjektet finns.
- schemaName: namnet på schemat där indexobjektet finns.
- tabellnamn: namnet på tabellen där indexobjektet finns.
- indexName: namnet på indexstrukturen.
- typ: typen av index (t.ex. Clustered, Non-Clustered).
- allocation_unit_type: anger typen av data som hänvisar till (t.ex. raddata, lobdata).
- fragmentering: mängden fragmentering (i %) som indexstrukturen för närvarande har.
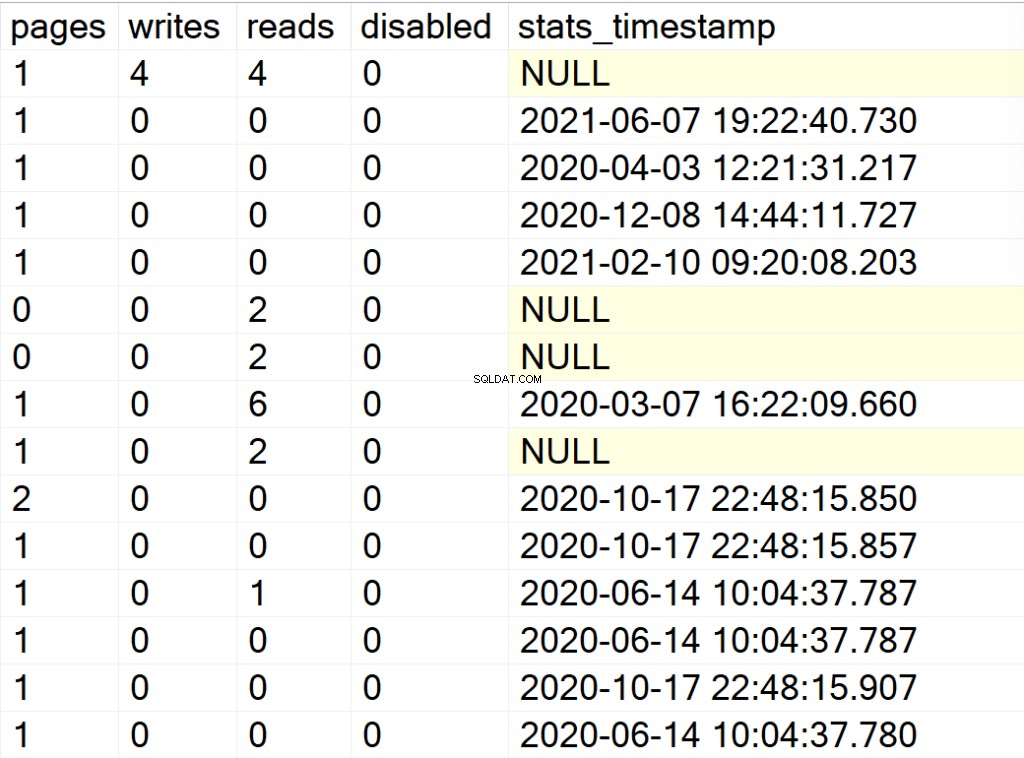
- sidor: antalet 8KB-sidor som bildar indexstrukturen.
- skriver: antalet skrivningar som indexstrukturen har upplevt sedan SQL Server-instansen senast startade om.
- läser: antalet läsningar som indexstrukturen har upplevt sedan SQL Server-instansen senast startade om.
- inaktiverad: 1 om indexstrukturen för närvarande är inaktiverad eller 0 om strukturen är aktiverad.
- stats_timestamp: tidsstämpelvärdet för när statistiken för den specifika indexstrukturen senast uppdaterades (NULL om aldrig).
- data_insamling_tidsstämpel: synlig endast om 'Y' skickas till @persistData-parametern, och den används för att veta när SP:n kördes och informationen lyckades sparas i tabellen DBA_Index.
Utförandetester
Jag kommer att demonstrera några exekveringar av den lagrade proceduren så att du kan få en uppfattning om vad du kan förvänta dig av den:
*Du kan hitta den fullständiga T-SQL-koden för skriptet i slutet av den här artikeln, så se till att köra den innan du går vidare med följande avsnitt.
*Resultatuppsättningen kommer att vara för bred för att passa bra i en skärmdump, så jag kommer att dela alla nödvändiga skärmdumpar för att presentera den fullständiga informationen.
/* Visa all indexinformation för alla system- och användardatabaser */
EXEC GetIndexData @persistData = 'N',@db = 'all'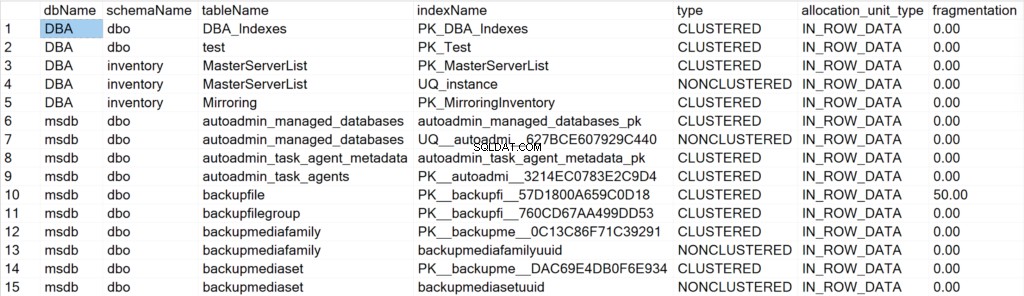
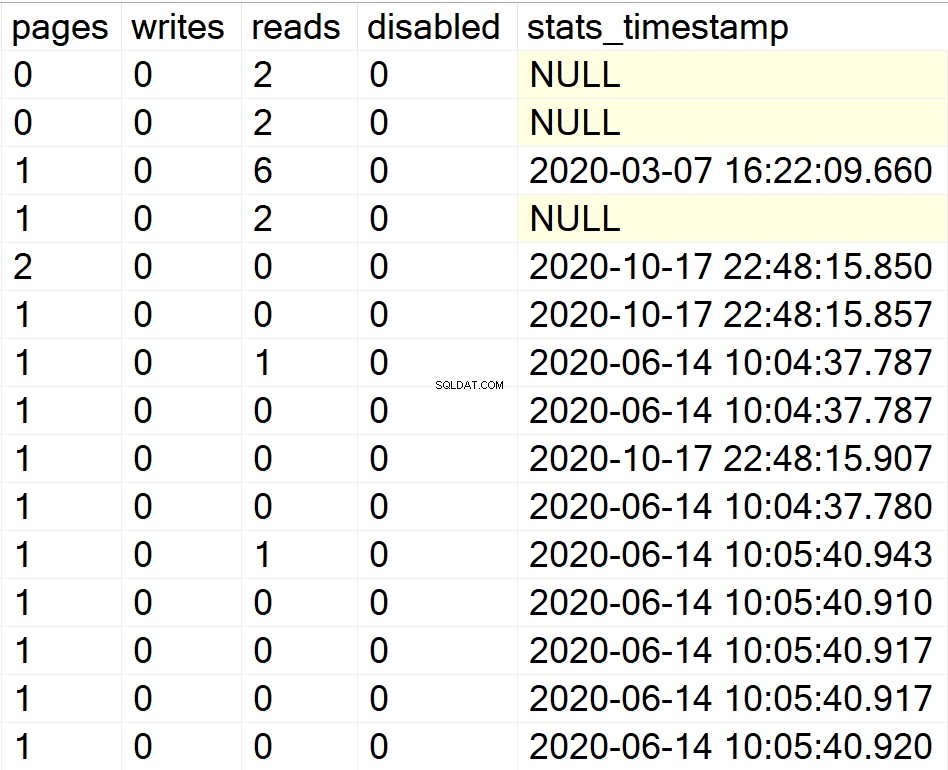
/* Visa all indexinformation för alla systemdatabaser */
EXEC GetIndexData @persistData = 'N',@db = 'system'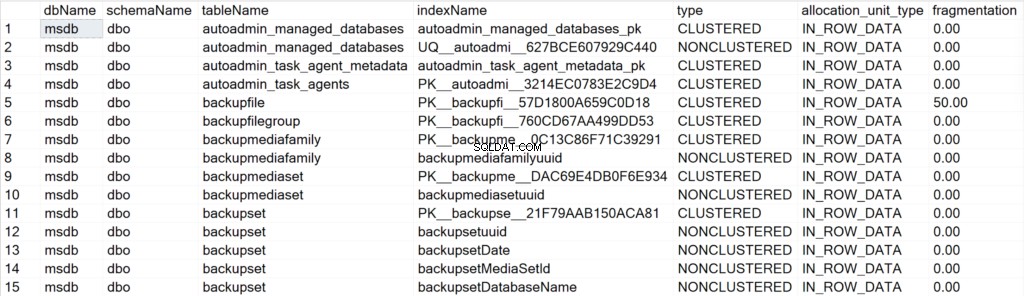
/* Visa all indexinformation för alla användardatabaser */
EXEC GetIndexData @persistData = 'N',@db = 'user'
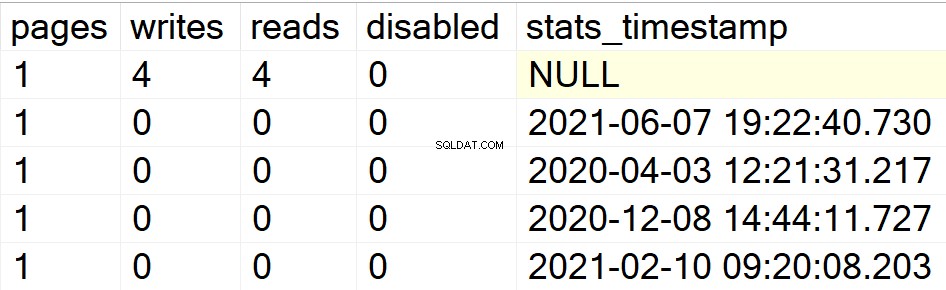
/* Visa all indexinformation för specifika användardatabaser */
I mina tidigare exempel visades endast databasen DBA upp som min enda användardatabas med index i den. Låt mig därför skapa en indexstruktur i en annan databas som jag har liggande i samma instans så att du kan se om SP gör sitt eller inte.
EXEC GetIndexData @persistData = 'N',@db = 'db2'
Alla exemplen som visats hittills visar resultatet som du får när du inte vill bevara data, för de olika kombinationerna av alternativ för @db-parametern. Utdata är tom när du antingen anger ett alternativ som inte är giltigt eller när måldatabasen inte existerar. Men hur är det när DBA vill bevara data i en databastabell? Låt oss ta reda på det.
*Jag kommer bara att köra SP för ett fall eftersom resten av alternativen för @db-parametern i stort sett har visats ovan och resultatet är detsamma men kvarstår i en databastabell.
EXEC GetIndexData @persistData = 'Y',@db = 'user'
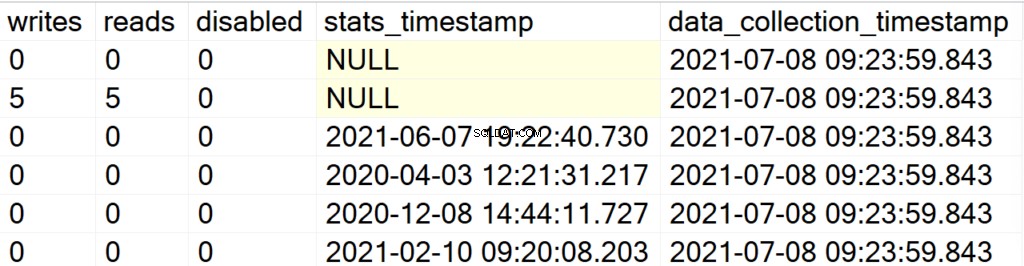
Nu, efter att du har kört den lagrade proceduren, kommer du inte att få någon utdata. För att fråga resultatuppsättningen måste du utfärda en SELECT-sats mot tabellen DBA_Index. Huvudattraktionen här är att du kan fråga efter den erhållna resultatuppsättningen, för efteranalys, och tillägget av data_collection_timestamp-fältet som låter dig veta hur ny/gammal data du tittar på är.
Sidofrågor
Nu, för att ge mer värde till DBA, har jag förberett några frågor som kan hjälpa dig att få användbar information från data som finns kvar i tabellen.
*Fråga för att hitta mycket fragmenterade index överlag.
*Välj antalet % som du anser passar.
*De 1500 sidorna är baserade på en artikel jag läst, baserad på Microsofts rekommendation.
SELECT * FROM DBA_Indexes WHERE fragmentation >= 85 AND pages >= 1500;*Fråga för att hitta inaktiverade index i din miljö.
SELECT * FROM DBA_Indexes WHERE disabled = 1;*Fråga för att hitta index (oftast icke-klustrade) som inte används så mycket av frågor, åtminstone inte sedan förra gången SQL Server-instansen startade om.
SELECT * FROM DBA_Indexes WHERE writes > reads AND type <> 'CLUSTERED';*Fråga för att hitta statistik som antingen aldrig har uppdaterats eller som är gammal.
*Du bestämmer vad som är gammalt i din miljö, så se till att justera antalet dagar därefter.
SELECT * FROM DBA_Indexes WHERE stats_timestamp IS NULL OR DATEDIFF(DAY, stats_timestamp, GETDATE()) > 60;Här är den fullständiga koden för den lagrade proceduren:
*I början av skriptet kommer du att se standardvärdet som den lagrade proceduren antar om inget värde skickas för varje parameter.
IF NOT EXISTS (SELECT * FROM dbo.sysobjects where id = object_id(N'DBA_Indexes') and OBJECTPROPERTY(id, N'IsTable') = 1)
BEGIN
CREATE TABLE DBA_Indexes(
[dbName] VARCHAR(128) NOT NULL,
[schemaName] VARCHAR(128) NOT NULL,
[tableName] VARCHAR(128) NOT NULL,
[indexName] VARCHAR(128) NOT NULL,
[type] VARCHAR(128) NOT NULL,
[allocation_unit_type] VARCHAR(128) NOT NULL,
[fragmentation] DECIMAL(10,2) NOT NULL,
[pages] INT NOT NULL,
[writes] INT NOT NULL,
[reads] INT NOT NULL,
[disabled] TINYINT NOT NULL,
[stats_timestamp] DATETIME NULL,
[data_collection_timestamp] DATETIME NOT NULL
CONSTRAINT PK_DBA_Indexes PRIMARY KEY CLUSTERED ([dbName],[schemaName],[tableName],[indexName],[type],[allocation_unit_type],[data_collection_timestamp])
) ON [PRIMARY]
END
GO
DECLARE @sqlCommand NVARCHAR(MAX)
SET @sqlCommand = '
CREATE OR ALTER PROCEDURE GetIndexData
@persistData CHAR(1) = ''N'',
@db NVARCHAR(64)
AS
BEGIN
SET NOCOUNT ON
DECLARE @query NVARCHAR(MAX)
DECLARE @tmp_IndexInfo TABLE(
[dbName] VARCHAR(128),
[schemaName] VARCHAR(128),
[tableName] VARCHAR(128),
[indexName] VARCHAR(128),
[type] VARCHAR(128),
[allocation_unit_type] VARCHAR(128),
[fragmentation] DECIMAL(10,2),
[pages] INT,
[writes] INT,
[reads] INT,
[disabled] TINYINT,
[stats_timestamp] DATETIME)
SET @query = ''
USE [?]
''
IF(@db = ''all'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') != 2
''
IF(@db = ''system'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') < 5 AND DB_ID(''''?'''') != 2
''
IF(@db = ''user'')
SET @query += ''
IF DB_ID(''''?'''') > 4
''
IF(@db != ''user'' AND @db != ''all'' AND @db != ''system'')
SET @query += ''
IF DB_NAME() = ''+CHAR(39)example@sqldat.com+CHAR(39)+''
''
SET @query += ''
BEGIN
DECLARE @DB_ID INT;
SET @DB_ID = DB_ID();
SELECT
db_name(@DB_ID) AS db_name,
s.name,
t.name,
i.name,
i.type_desc,
ips.alloc_unit_type_desc,
CONVERT(DECIMAL(10,2),ips.avg_fragmentation_in_percent),
ips.page_count,
ISNULL(ius.user_updates,0),
ISNULL(ius.user_seeks + ius.user_scans + ius.user_lookups,0),
i.is_disabled,
STATS_DATE(st.object_id, st.stats_id)
FROM sys.indexes i
JOIN sys.tables t ON i.object_id = t.object_id
JOIN sys.schemas s ON s.schema_id = t.schema_id
JOIN sys.dm_db_index_physical_stats (@DB_ID, NULL, NULL, NULL, NULL) ips ON ips.database_id = @DB_ID AND ips.object_id = t.object_id AND ips.index_id = i.index_id
LEFT JOIN sys.dm_db_index_usage_stats ius ON ius.database_id = @DB_ID AND ius.object_id = t.object_id AND ius.index_id = i.index_id
JOIN sys.stats st ON st.object_id = t.object_id AND st.name = i.name
WHERE i.index_id > 0
END''
INSERT INTO @tmp_IndexInfo
EXEC sp_MSForEachDB @query
IF @persistData = ''N''
SELECT * FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
ELSE
BEGIN
TRUNCATE TABLE DBA_Indexes
INSERT INTO DBA_Indexes
SELECT *,GETDATE() FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
END
END
'
EXEC (@sqlCommand)
GOSlutsats
- Du kan distribuera denna SP i varje SQL Server-instans under din support och implementera en varningsmekanism över hela din stapel med instanser som stöds.
- Om du implementerar ett agentjobb som frågar efter denna information relativt ofta, kan du hålla dig på toppen av spelet för att ta hand om indexstrukturerna i din(de) miljö(er) som stöds.
- Se till att testa den här mekanismen ordentligt i en sandlådemiljö och, när du planerar för en produktionsinstallation, se till att välja perioder med låg aktivitet.
Indexfragmenteringsproblem kan vara knepiga och stressande. För att hitta och fixa dem kan du använda olika verktyg, som dbForge Index Manager som kan laddas ner här.