Är det inte bra att ha en ny version av SQL Server tillgänglig? Detta är något som bara händer vartannat år, och den här månaden såg vi en nå General Availability. (Ok, jag vet att vi får en ny version av SQL Database i Azure nästan kontinuerligt, men jag räknar detta som annorlunda.) Denna månads T-SQL-tisdag (värd av Michael Swart – @mjswart) är ett erkännande av denna nya utgåva som handlar om allt som rör SQL Server 2016!
Är det inte bra att ha en ny version av SQL Server tillgänglig? Detta är något som bara händer vartannat år, och den här månaden såg vi en nå General Availability. (Ok, jag vet att vi får en ny version av SQL Database i Azure nästan kontinuerligt, men jag räknar detta som annorlunda.) Denna månads T-SQL-tisdag (värd av Michael Swart – @mjswart) är ett erkännande av denna nya utgåva som handlar om allt som rör SQL Server 2016!
Så idag vill jag titta på SQL 2016:s Temporal Tables-funktion och ta en titt på några frågeplanssituationer som du kan få se. Jag älskar Temporal Tables, men har stött på lite av en gotcha som du kanske vill vara medveten om.
Nu, trots att SQL Server 2016 nu finns i RTM, använder jag AdventureWorks2016CTP3, som du kan ladda ner här – men ladda inte bara ner AdventureWorks2016CTP3.bak , hämta även SQLServer2016CTP3Samples.zip från samma sida.
Du ser, i provarkivet finns det några användbara skript för att testa nya funktioner, inklusive några för Temporal Tables. Det är win-win – du får prova en massa nya funktioner, och jag behöver inte upprepa så mycket manus i det här inlägget. Hur som helst, gå och ta de två skripten om Temporal Tables, som kör AW 2016 CTP3 Temporal Setup.sql , följt av Temporal System-Versioning Sample.sql .
Dessa skript ställer in temporära versioner av några tabeller, inklusive HumanResources.Employee . Den skapar HumanResources.Employee_Temporal (även om det tekniskt sett kunde ha hetat vad som helst). I slutet av CREATE TABLE satsen visas den här biten och lägger till två dolda kolumner som ska användas för att indikera när raden är giltig och indikerar att en tabell ska skapas som heter HumanResources.Employee_Temporal_History för att lagra de gamla versionerna.
... ValidFrom datetime2(7) GENERERADES ALLTID SOM RADSTART DOLDA INTE NULL, ValidTo datetime2(7) GENERADES ALLTID SOM RADSLUT DIDDEN INTE NULL, PERIOD FÖR SYSTEM_TIME (ValidFrom, ValidTo)) MED (SYSTEM_VERSIONING =TABLESTORY =[HumanResources].[Employee_Temporal_History]));
Det jag vill utforska i det här inlägget är vad som händer med frågeplaner när historiken används.
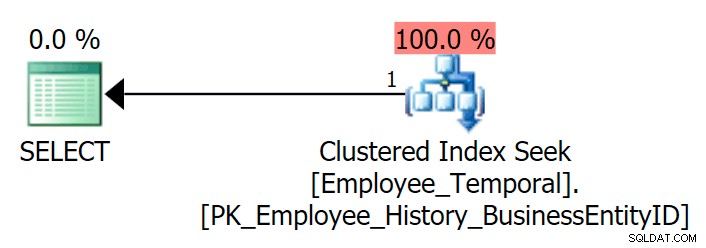
Om jag frågar tabellen för att se den senaste raden för ett visst BusinessEntityID , jag får en Clustered Index Seek, som förväntat.
VÄLJ e.BusinessEntityID, e.ValidFrom, e.ValidToFROM HumanResources.Employee_Temporal AS eWHERE e.BusinessEntityID =4;
Jag är säker på att jag skulle kunna fråga den här tabellen med andra index, om den hade några. Men i det här fallet gör det inte det. Låt oss skapa en.
SKAPA UNIKT INDEX rf_ix_Login on HumanResources.Employee_Temporal(LoginID);
Nu kan jag fråga tabellen med LoginID , och kommer att se en nyckelsökning om jag ber om andra kolumner än Loginid eller BusinessEntityID . Inget av detta är förvånande.
SELECT * FROM HumanResources.Employee_Temporal eWHERE e.LoginID =N'adventure-works\rob0';
Låt oss använda SQL Server Management Studio i en minut och ta en titt på hur den här tabellen ser ut i Object Explorer.

Vi kan se historiktabellen som nämns under HumanResources.Employee_Temporal , och kolumnerna och indexen från både själva tabellen och historiktabellen. Men medan indexen på rätt tabell är den primära nyckeln (på BusinessEntityID ) och indexet som jag just skapade, Historiktabellen har inte matchande index.
Indexet i historiktabellen är på ValidTo och ValidFrom . Vi kan högerklicka på indexet och välja Egenskaper, och vi ser den här dialogrutan:
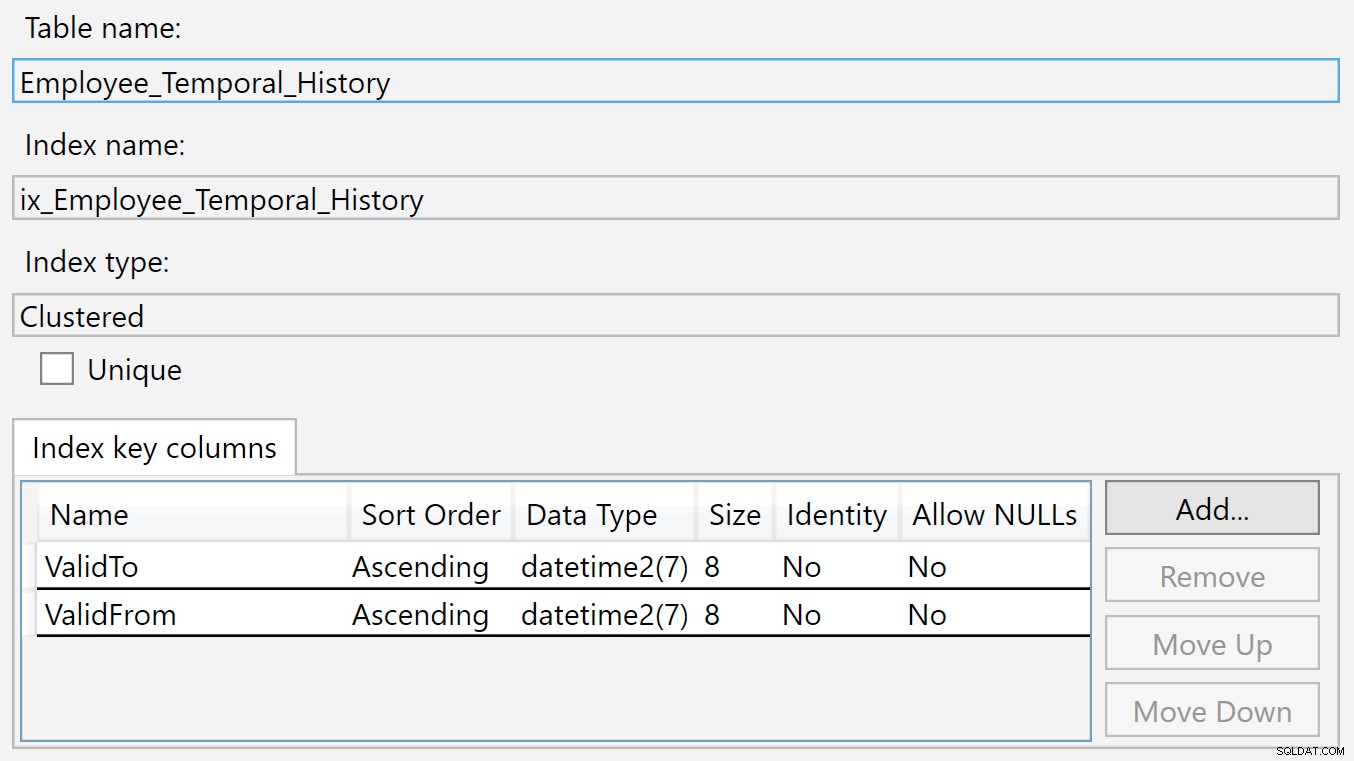
En ny rad infogas i den här historiktabellen när den inte längre är giltig i huvudtabellen eftersom den just har tagits bort eller ändrats. Värdena i ValidTo kolumner är naturligt fyllda med den aktuella tiden, så ValidTo fungerar som en stigande nyckel, som en identitetskolumn, så att nya inlägg visas i slutet av b-trädstrukturen.
Men hur fungerar detta när du vill fråga i tabellen?
Om vi vill fråga vår tabell efter vad som var aktuellt vid en viss tidpunkt, bör vi använda en frågestruktur som:
VÄLJ * FROM HumanResources.Employee_TemporalFOR SYSTEM_TIME FRÅN '20160612 11:22';
Den här frågan måste sammanfoga lämpliga rader från huvudtabellen med lämpliga rader från historiktabellen.
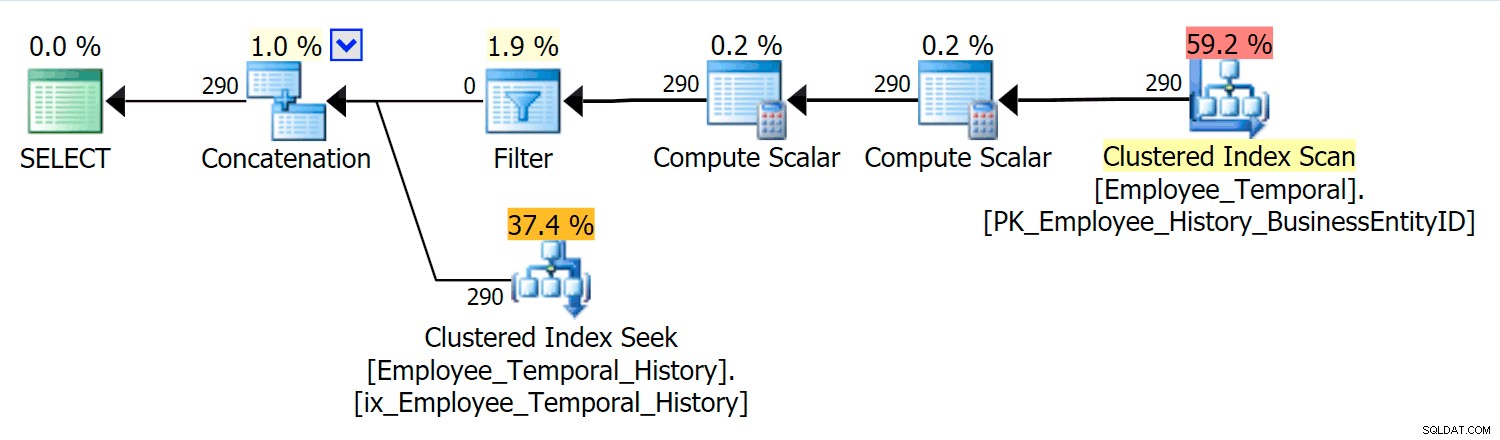
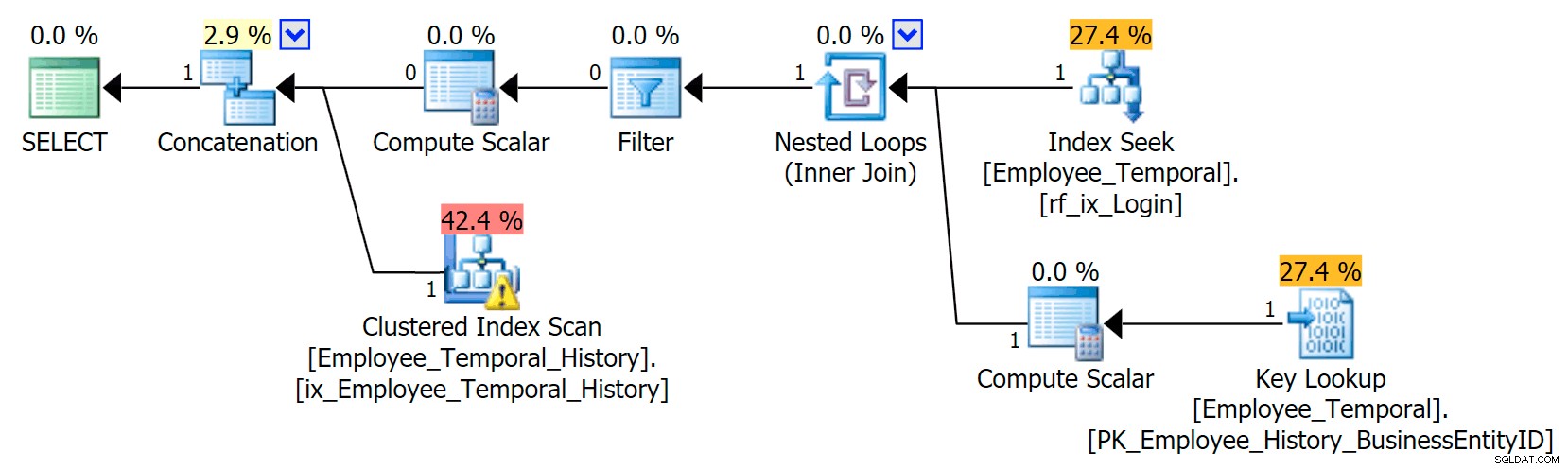
I det här scenariot var raderna som var giltiga för det ögonblick jag valde alla från historiktabellen, men ändå ser vi en Clustered Index Scan mot huvudtabellen, som filtrerades av en filteroperator. Predikatet för detta filter är:
[HumanResources].[Employee_Temporal].[ValidFrom] <='2016-06-12 11:22:00.0000000' OCH [HumanResources].[Employee_Temporal].[ValidTo]> '6-2016-2016 :00.0000000'
Låt oss återkomma till detta om ett ögonblick.
Clustered Index Seek i historiktabellen måste helt klart utnyttja ett Seek Predicate på ValidTo. Starten av sökningens intervallsökning är HumanResources.Employee_Temporal_History.ValidTo > Scalar Operator('2016-06-12 11:22:00') , men det finns inget slut, eftersom varje rad som har en ValidTo efter den tid vi bryr oss om är en kandidatrad och måste testas för en lämplig ValidFrom värde av Residual Predicate, som är HumanResources.Employee_Temporal_History.ValidFrom <= '2016-06-12 11:22:00' .
Nu är intervall svåra att indexera för; det är en känd sak som har diskuterats på många bloggar. De mest effektiva lösningarna överväger kreativa sätt att skriva frågor, men inga sådana smarta funktioner har byggts in i Temporal Tables. Du kan dock sätta index på andra kolumner också, till exempel på ValidFrom, eller till och med ha index som matchar de typer av frågor du kan ha i huvudtabellen. Med ett klustrat index som en sammansatt nyckel på båda ValidTo och ValidFrom , dessa två kolumner inkluderas i varannan kolumn, vilket ger ett bra tillfälle att testa restpredikat.
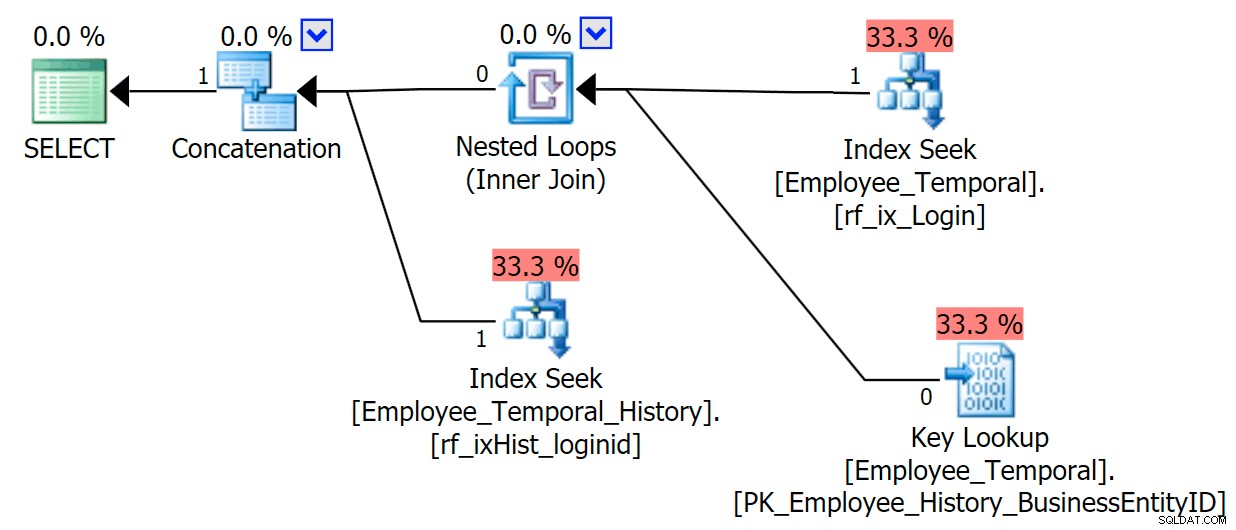
Om jag vet vilken inloggningsid jag är intresserad av, får min plan en annan form.
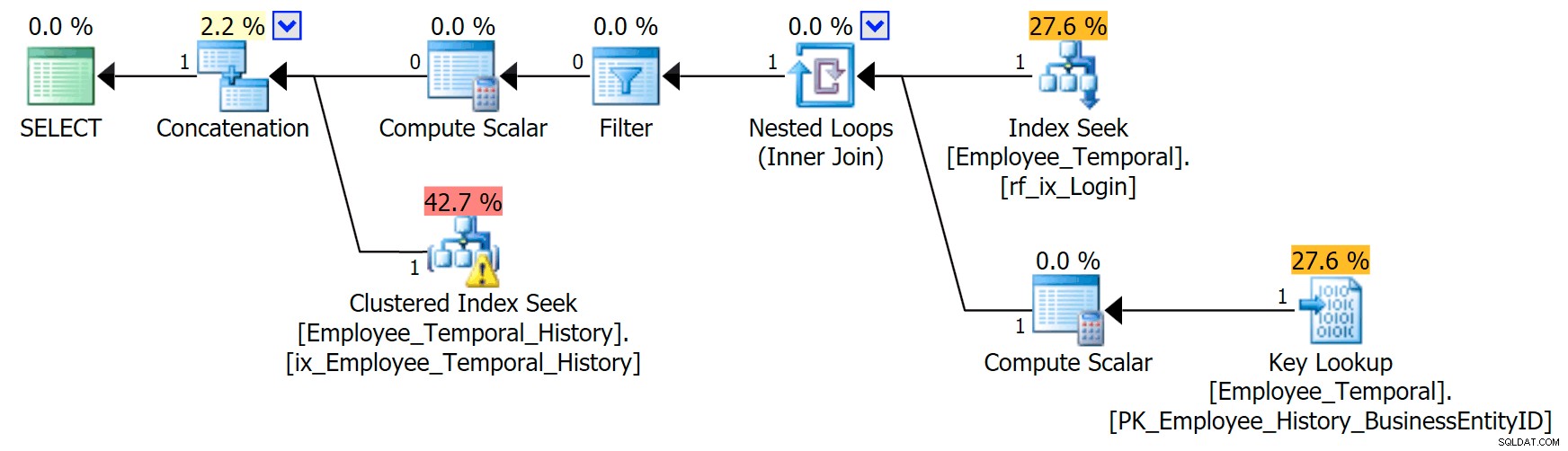
Den översta grenen av sammanlänkningsoperatorn ser ut som tidigare, även om den filteroperatorn har gått in i striden för att ta bort alla rader som inte är giltiga, men den grupperade indexsökningen på den nedre grenen har en varning. Detta är en varning för restpredikat, som exemplen i ett tidigare inlägg av mig. Den kan filtrera till poster som är giltiga tills någon tid efter den tid vi bryr oss om, men Residual Predicate filtrerar nu till LoginID samt ValidFrom .
[HumanResources].[Employee_Temporal_History].[ValidFrom] <='2016-06-12 11:22:00.0000000' OCH [HumanResources].[Employee_Temporal_History] =.[Login-ID-0] /pre>Ändringar av rob0:s rader kommer att vara en liten del av raderna i historiken. Den här kolumnen kommer inte att vara unik som i huvudtabellen, eftersom raden kan ha ändrats flera gånger, men det finns fortfarande en bra kandidat för indexering.
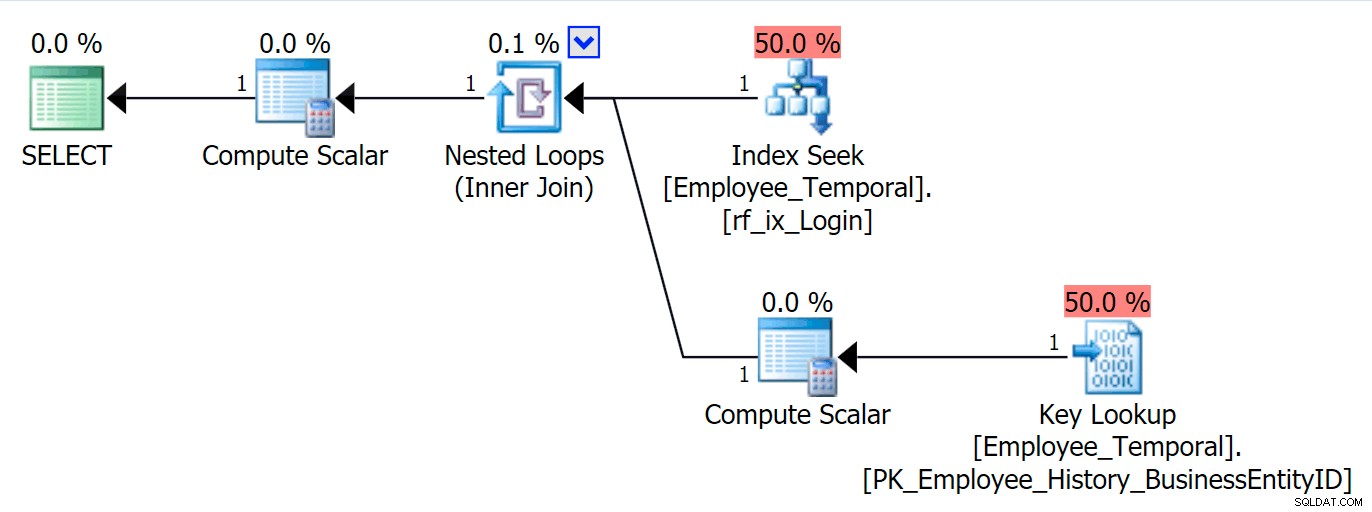
SKAPA INDEX rf_ixHist_loginidON HumanResources.Employee_Temporal_History(LoginID);Detta nya index har en märkbar effekt på vår plan.
Det har nu ändrat vår Clustered Index Seek till en Clustered Index Scan!
Du förstår, frågeoptimeraren ser nu ut att det bästa du kan göra är att använda det nya indexet. Men den beslutar också att ansträngningen med att behöva göra uppslagningar för att få alla andra kolumner (eftersom jag frågade efter alla kolumner) helt enkelt skulle vara för mycket arbete. Vipppunkten nåddes (tyvärr ett felaktigt antagande i detta fall), och en Clustered Index SCAN valdes istället. Även om utan det icke-klustrade indexet skulle det bästa alternativet ha varit att använda en Clustered Index Seek, när det icke-klustrade indexet har övervägts och avvisats av vändpunktsskäl, väljer den att skanna.
Frustrerande nog har jag precis skapat detta index och dess statistik borde vara bra. Den borde veta att en sökning som kräver exakt en uppslagning borde vara bättre än en Clustered Index Scan (endast genom statistik – om du trodde att den borde veta detta eftersom
LoginIDär unik i huvudtabellen, kom ihåg att det kanske inte alltid har varit det). Så jag misstänker att uppslagningar bör undvikas i historiktabeller, även om jag inte har undersökt detta tillräckligt mycket än.Om vi nu bara skulle fråga efter kolumner som visas i vårt icke-klustrade index, skulle vi få ett mycket bättre beteende. Nu när ingen uppslag krävs används vårt nya index på historiktabellen med glädje. Det måste fortfarande tillämpa ett restpredikat baserat på att endast kunna filtrera till
LoginIDochValidTo, men det beter sig mycket bättre än att hamna i en Clustered Index Scan.VÄLJ LoginID, ValidFrom, ValidToFROM HumanResources.Employee_TemporalFOR SYSTEM_TIME FRÅN '20160612 11:22'WHERE LoginID =N'adventure-works\rob0'
Så indexera dina historiktabeller på extra sätt, med tanke på hur du kommer att fråga dem. Inkludera nödvändiga kolumner för att undvika uppslagningar, eftersom du verkligen undviker skanningar.
Dessa historiktabeller kan växa sig stora om data ändras ofta. Så var uppmärksam på hur de hanteras. Samma situation uppstår när du använder den andra
FOR SYSTEM_TIMEkonstruktioner, så du bör (som alltid) granska planerna som dina frågor producerar och indexera för att se till att du är väl positionerad för att utnyttja vad som är en mycket kraftfull funktion i SQL Server 2016.