Att ansvara för prestanda för SQL Server kan vara en skrämmande uppgift. Det finns många områden som vi måste övervaka och förstå. Vi förväntas också kunna hålla koll på alla dessa mätvärden och veta vad som händer på våra servrar hela tiden. Jag gillar att fråga DBA:er vad det första de tänker på när de hör frasen "tuning SQL Server;" det överväldigande svaret jag får är "frågejustering." Jag håller med om att justering av frågor är mycket viktigt och är en oändlig uppgift som vi står inför eftersom arbetsbelastningen ständigt förändras.
Det finns dock många andra aspekter att tänka på när man tänker på SQL Server-prestanda. Det finns många inställningar på instans-, OS- och databasnivå som måste justeras från standardinställningarna. Att vara konsult gör att jag kan arbeta inom många olika branscher och få exponering för alla möjliga prestationsfrågor. När jag arbetar med en ny klient försöker jag alltid utföra en hälsorevision av servern för att veta vad jag har att göra med. När jag utförde dessa granskningar har en av sakerna som jag har funnit vid upprepade tillfällen varit överdrivna läs- och skrivfördröjningar på diskarna där SQL Server-data och loggfiler finns.
Läs-/skrivfördröjning
För att se dina disklatenser i SQL Server kan du snabbt och enkelt fråga DMV sys.dm_io_virtual_file_stats . Denna DMV accepterar två parametrar:database_id och fil_id . Vad som är fantastiskt är att du kan skicka NULL som båda värden och returnerar latenserna för alla filer för alla databaser. Utdatakolumnerna inkluderar:
- databas-id
- fil_id
- exempel_ms
- antal_av_läsningar
- antal_of_bytes_read
- io_stall_read_ms
- antal_of_writes
- antal_of_bytes_written
- io_stall_write_ms
- io_stall
- storlek_på_disk_bytes
- file_handle
Som du kan se från kolumnlistan finns det verkligen användbar information som denna DMV hämtar, men kör bara SELECT * FROM sys.dm_io_virtual_file_stats(NULL, NULL); hjälper inte mycket om du inte har memorerat dina database_id och kan göra lite matte i huvudet.
När jag frågar filstatistiken använder jag en fråga från Paul Randals blogginlägg, "Hur man undersöker IO-delsystems latenser inifrån SQL Server." Detta skript gör kolumnnamnen lättare att läsa, inkluderar enheten som filen är på, databasnamnet och sökvägen till filen.
Genom att fråga denna DMV kan du enkelt se var I/O-hotspots är för dina filer. Du kan se var de högsta skriv- och läsfördröjningarna finns och vilka databaser som är de skyldiga. Genom att veta detta kan du börja titta på inställningsmöjligheterna för dessa specifika databaser. Detta kan inkludera indexjustering, kontroll för att se om buffertpoolen är under minnestryck, eventuellt flytta databasen till en snabbare del av I/O-undersystemet, eller eventuellt partitionera databasen och sprida filgrupperna över andra LUN:er.
Så du kör frågan och den returnerar massor av värden i ms för latens – vilka värden är okej och vilka är dåliga?
Vilka värden är bra eller dåliga?
Om du frågar SQLskills kommer vi att berätta något i stil med:
- Utmärkt:<1ms
- Mycket bra:<5ms
- Bra:5 – 10 ms
- Dålig:10 – 20 ms
- Dåligt:20 – 100 ms
- Riktigt dåligt:100 – 500 ms
- OMG!:> 500ms
Om du gör en Bing-sökning hittar du artiklar från Microsoft som ger rekommendationer som liknar:
- Bra:<10 ms
- Okej:10 – 20 ms
- Dåligt:20 – 50 ms
- Allvarligt dåligt:> 50ms
Som du kan se finns det några små variationer i siffrorna, men konsensus är att allt över 20ms kan anses vara besvärligt. Med det sagt kan din genomsnittliga skrivfördröjning vara 20 ms och det är 100 % acceptabelt för din organisation och det är okej. Du måste känna till allmänna I/O-latenser för ditt system så att du vet vad normalt är när det blir dåligt.
Mina läs-/skrivfördröjningar är dåliga, vad ska jag göra?
Om du upptäcker att läs- och skrivfördröjningar är dåliga på din server, finns det flera ställen där du kan börja leta efter problem. Det här är inte en heltäckande lista utan en vägledning om var du ska börja.
- Analysera din arbetsbelastning. Är din indexeringsstrategi korrekt? Att inte ha rätt index kommer att leda till att mycket mer data läses från disken. Skannar istället för sökningar.
- Är din statistik uppdaterad? Dålig statistik kan leda till dåliga val för genomförandeplaner.
- Har du problem med parametersniffning som orsakar dåliga genomförandeplaner?
- Är buffertpoolen under minnestryck, till exempel från en uppsvälld plancache?
- Några nätverksproblem? Fungerar ditt SAN-tyg korrekt? Låt din lagringstekniker validera sökväg och nätverk.
- Flytta hotspots till olika lagringsarrayer. I vissa fall kan det vara en enda databas eller bara några databaser som orsakar alla problem. Att isolera dem till en annan uppsättning skivor eller snabbare avancerade diskar som SSD:er kan vara den bästa logiska lösningen.
- Kan du partitionera databasen för att flytta besvärliga tabeller till en annan disk för att sprida belastningen?
Väntestatistik
Precis som att övervaka din filstatistik kan övervakning av din väntestatistik berätta mycket om flaskhalsar i din miljö. Vi har turen att ha ännu en fantastisk DMV (sys.dm_os_wait_stats ) att vi kan fråga som kommer att hämta all tillgänglig vänteinformation som samlats in sedan den senaste omstarten eller sedan den senaste gången väntetiden återställdes; det finns väntetider relaterade till diskens prestanda också. Denna DMV kommer att returnera viktig information inklusive:
- wait_type
- waiting_task_count
- väntetid_ms
- max_wait_time_ms
- signal_wait_time_ms
Att fråga denna DMV på min SQL Server 2014-maskin returnerade 771 väntetyper. SQL Server väntar alltid på något, men det finns många väntan som vi inte bör oroa oss för. Av denna anledning använder jag en annan fråga från Paul Randal; hans blogginlägg, "Vänta statistik, eller snälla berätta för mig var det gör ont", har ett utmärkt manus som utesluter en massa väntan som vi egentligen inte bryr oss om. Paul listar också många av de vanliga problematiska väntetiderna samt ger vägledning för de vanliga väntetiderna.
Varför är väntestatistik viktig?
Övervakning av höga väntetider för vissa händelser kommer att berätta när det finns problem på gång. Du behöver en baslinje för att veta vad som är normalt och när saker överskrider en tröskel eller smärtnivå. Om du har riktigt hög PAGEIOLATCH_XX då vet du att SQL Server måste vänta på att en datasida ska läsas från disken. Detta kan vara disk, minne, byte av arbetsbelastning eller ett antal andra problem.
En kund som jag nyligen arbetade med såg ett mycket ovanligt beteende. När jag kopplade till databasservern och kunde observera servern under en arbetsbelastning började jag genast kolla filstatistik, väntestatistik, minnesanvändning, tempdb-användning etc. En sak som direkt stack ut var WRITELOG är den vanligaste väntan. Jag vet att denna väntan har att göra med en loggspolning till disken och påminde mig om Pauls serie om Trimning av transaktionsloggfett. Hög WRITELOG väntar kan vanligtvis identifieras av högskrivna latenser för transaktionsloggfilen. Så jag använde sedan mitt filstatistikskript för att granska läs- och skrivfördröjningen på disken. Jag kunde då se hög skrivfördröjning på datafilen men inte min loggfil. När du tittar på WRITELOG det var en hög väntetid men väntetiden i ms var extremt låg. Men något i det andra inlägget i Pauls serie fanns fortfarande i mitt huvud. Jag borde titta på inställningarna för automatisk tillväxt för databasen bara för att utesluta "Död med tusen snitt". När jag tittade på databasens databasegenskaper såg jag att datafilen var inställd på att växa automatiskt med 1 MB och transaktionsloggen inställd på att växa automatiskt med 10 %. Båda filerna hade nästan 0 oanvänt utrymme. Jag delade med klienten vad jag hittade och hur detta dödade deras prestation. Vi gjorde snabbt den lämpliga förändringen och testerna gick framåt, mycket bättre förresten. Tyvärr är det inte den enda gången jag har stött på det här problemet. En annan gång en databas var 66 GB stor, kom den dit med 1 MB tillväxt.
Fånga din data
Många dataproffs har skapat processer för att regelbundet fånga fil- och väntestatistik för analys. Eftersom väntestatistiken är kumulativ, skulle du vilja fånga dem och jämföra deltan mellan olika tider på dagen eller före och efter att vissa processer körs. Det här är inte alltför komplicerat och det finns många blogginlägg tillgängliga där folk delar hur de åstadkom detta. Den viktiga delen är att mäta denna data så att du kan övervaka den. Hur vet du idag att det är bättre eller sämre på din databasserver om du inte känner till data från gårdagen?
Hur kan SQL Sentry hjälpa?
Jag är glad att du frågade! SQL Sentry Performance Advisor ger latens och väntar fram och tillbaka på instrumentpanelen. Eventuella anomalier är lätta att upptäcka; du kan byta till historiskt läge och se den tidigare trenden och jämföra den med tidigare perioder också. Detta kan visa sig vara ovärderligt när man analyserar dessa "vad hände?" ögonblick. Alla har fått det samtalet, "Igår runt 15:00 verkade systemet bara frysa, kan du berätta vad som hände?" Javisst, låt mig dra upp Profiler och gå tillbaka i tiden. Om du har ett övervakningsverktyg som Performance Advisor, skulle du ha den historiska informationen till hands.
Förutom diagrammen och graferna på instrumentpanelen har du möjlighet att använda inbyggda varningar för förhållanden som höga diskväntningar, höga VLF-antal, hög CPU, låg förväntad livslängd på sidan och många fler. Du har också möjlighet att skapa dina egna anpassade villkor, och du kan lära dig av exemplen på SQL Sentry-webbplatsen eller genom Condition Exchange (Aaron Bertrand har bloggat om detta). Jag berörde varningssidan av detta i min senaste artikel om SQL Server Agent Alerts.
På fliken Diskutrymme i Performance Advisor är det väldigt lätt att se saker som autotillväxtinställningar och höga VLF-antal. Du borde veta, men om du inte gör det, är autotillväxt med 1MB eller 10% inte den bästa inställningen. Om du ser dessa värden (Performance Advisor framhäver dem åt dig) kan du snabbt anteckna och schemalägga tiden för att göra de rätta justeringarna. Jag älskar hur den visar Total VLF också; för många VLF:er kan vara mycket problematiska. Du borde läsa Kimberlys inlägg "Transaction Log VLFs - too many or too few?" om du inte redan har gjort det.
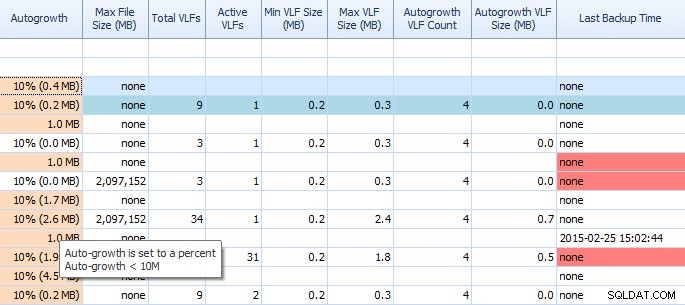 Delvis rutnät på Performance Advisors flik Diskutrymme
Delvis rutnät på Performance Advisors flik Diskutrymme
Ett annat sätt som Performance Advisor kan hjälpa till är genom dess patenterade Disk Activity-modul. Här kan du se att tempdb på F:upplever betydande skrivlatens; du kan se detta på de tjocka röda linjerna under diskens grafik. Du kanske också märker att F:är den enda enhetsbokstav vars skiva är representerad i rött; det här är en visuell signal om att enheten har en feljusterad partition, vilket kan bidra till I/O-problem.
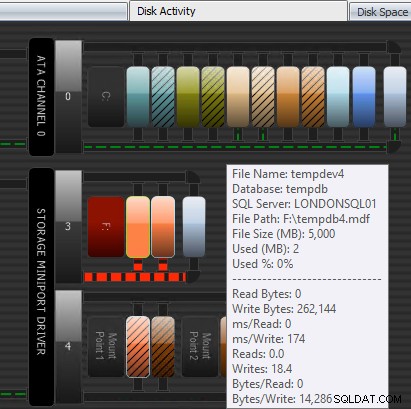 Performance Advisor Disk Activity-modul
Performance Advisor Disk Activity-modul
Och du kan korrelera denna information i rutnäten nedan – problem markeras i rutnäten där också, och ta en titt på ms/Write kolumn:
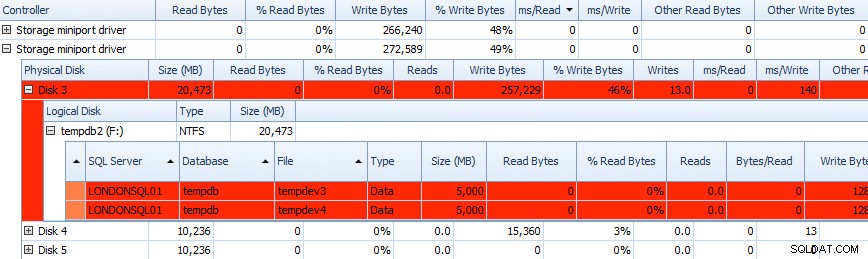 Delvis rutnät av Performance Advisor Disk Activity-data
Delvis rutnät av Performance Advisor Disk Activity-data
Du kan också titta på denna information retroaktivt; om någon klagar på en upplevd diskflaskhals igår eftermiddag eller i tisdags, kan du helt enkelt gå tillbaka med hjälp av datumväljarna i verktygsfältet och se den genomsnittliga genomströmningen och latensen för alla intervall. För mer information om modulen Diskaktivitet, se användarhandboken.
Performance Advisor har också en hel del inbyggda rapporter under kategorierna Performance, Blocking, Top SQL, Disk/File Space och Deadlocks. Bilden nedan visar hur du kommer till Disk/File Space-rapporterna. Att ha rapporterna bara några musklick bort är mycket värdefullt för att omedelbart kunna gräva in och se vad som händer (eller hände) på din server.
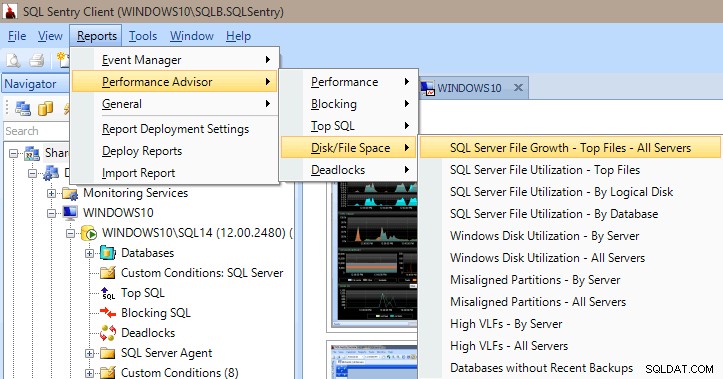 Rapporter från resultatrådgivare
Rapporter från resultatrådgivare
Sammanfattning
Det viktiga med det här inlägget är att känna till dina prestationsmått. Ett vanligt uttalande bland dataproffs är att disken är vår #1 flaskhals. Att känna till filstatistiken för din server kommer att hjälpa dig att förstå smärtpunkterna på din server. I samband med filstatistik är din väntestatistik också ett bra ställe att titta på. Många människor, inklusive jag själv, börjar där. Att ha ett verktyg som SQL Sentry Performance Advisor kan drastiskt hjälpa dig att felsöka och hitta prestandaproblem innan de blir för problematiska; men om du inte har ett sådant verktyg, bekanta dig med sys.dm_os_wait_stats och sys.dm_io_virtual_file_stats kommer att hjälpa dig att börja ställa in din server.