Du vet förmodligen hur man infogar poster i en tabell med enstaka eller flera VALUES-satser. Du vet också hur man gör bulkinfogningar med SQL INSERT INTO SELECT. Men du klickade ändå på artikeln. Handlar det om att hantera dubbletter?
Många artiklar täcker SQL INSERT INTO SELECT. Googla eller Bing it och välj den rubrik du gillar bäst – det räcker. Jag kommer inte heller att täcka grundläggande exempel på hur det görs. Istället kommer du att seexempel på hur du använder det OCH hanterar dubbletter samtidigt . Så du kan göra detta välbekanta budskap ur dina INSERT-ansträngningar:
Msg 2601, Level 14, State 1, Line 14
Cannot insert duplicate key row in object 'dbo.Table1' with unique index 'UIX_Table1_Key1'. The duplicate key value is (value1).
Men först till kvarn.

[sendpulse-form id="12989″]
Förbered testdata för SQL INSERT INTO SELECT Code Samples
Jag tänker lite på pasta den här gången. Så jag kommer att använda data om pastarätter. Jag hittade en bra lista över pastarätter i Wikipedia som vi kan använda och extrahera i Power BI med hjälp av en webbdatakälla. Jag skrev in Wikipedias URL. Sedan specificerade jag 2-tabellsdata från sidan. Rensade lite och kopierade data till Excel.
Nu har vi data – du kan ladda ner den härifrån. Det är rått eftersom vi kommer att göra 2 relationstabeller av det. Att använda INSERT INTO SELECT hjälper oss att göra den här uppgiften,
Importera data till SQL Server
Du kan antingen använda SQL Server Management Studio eller dbForge Studio för SQL Server för att importera 2 ark till Excel-filen.
Skapa en tom databas innan du importerar data. Jag döpte borden till dbo.ItalianPastaDishes och dbo.NonItalianPastaDishes .
Skapa ytterligare två tabeller
Låt oss definiera de två utdatatabellerna med kommandot SQL Server ALTER TABLE.
CREATE TABLE [dbo].[Origin](
[OriginID] [int] IDENTITY(1,1) NOT NULL,
[Origin] [varchar](50) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_Origin] PRIMARY KEY CLUSTERED
(
[OriginID] ASC
))
GO
ALTER TABLE [dbo].[Origin] ADD CONSTRAINT [DF_Origin_Modified] DEFAULT (getdate()) FOR [Modified]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_Origin] ON [dbo].[Origin]
(
[Origin] ASC
)
GO
CREATE TABLE [dbo].[PastaDishes](
[PastaDishID] [int] IDENTITY(1,1) NOT NULL,
[PastaDishName] [nvarchar](75) NOT NULL,
[OriginID] [int] NOT NULL,
[Description] [nvarchar](500) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_PastaDishes_1] PRIMARY KEY CLUSTERED
(
[PastaDishID] ASC
))
GO
ALTER TABLE [dbo].[PastaDishes] ADD CONSTRAINT [DF_PastaDishes_Modified_1] DEFAULT (getdate()) FOR [Modified]
GO
ALTER TABLE [dbo].[PastaDishes] WITH CHECK ADD CONSTRAINT [FK_PastaDishes_Origin] FOREIGN KEY([OriginID])
REFERENCES [dbo].[Origin] ([OriginID])
GO
ALTER TABLE [dbo].[PastaDishes] CHECK CONSTRAINT [FK_PastaDishes_Origin]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_PastaDishes_PastaDishName] ON [dbo].[PastaDishes]
(
[PastaDishName] ASC
)
GO
Obs:Det finns unika index skapade på två tabeller. Det kommer att hindra oss från att infoga dubbletter av poster senare. Restriktioner kommer att göra den här resan lite svårare men spännande.
Nu när vi är redo, låt oss dyka in.
5 enkla sätt att hantera dubbletter med SQL INSERT INTO SELECT
Det enklaste sättet att hantera dubbletter är att ta bort unika begränsningar, eller hur?
Fel!
Med unika begränsningar borta är det lätt att göra ett misstag och infoga data två gånger eller mer. Det vill vi inte. Och vad händer om vi har ett användargränssnitt med en rullgardinslista för att välja ursprunget till pastarätten? Kommer dubletterna att göra dina användare nöjda?
Att ta bort de unika begränsningarna är därför inte ett av de fem sätten att hantera eller ta bort dubbletter av poster i SQL. Vi har bättre alternativ.
1. Använd INSERT INTO SELECT DISTINCT
Det första alternativet för hur man identifierar SQL-poster i SQL är att använda DISTINCT i SELECT. För att utforska fallet fyller vi i Ursprung tabell. Men först, låt oss använda fel metod:
-- This is wrong and will trigger duplicate key errors
INSERT INTO Origin
(Origin)
SELECT origin FROM NonItalianPastaDishes
GO
INSERT INTO Origin
(Origin)
SELECT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
GO
Detta kommer att utlösa följande dubbletter av fel:
Msg 2601, Level 14, State 1, Line 2
Cannot insert a duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (United States).
The statement has been terminated.
Msg 2601, Level 14, State 1, Line 6
Cannot insert duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (Lombardy, Italy).
Det finns ett problem när du försöker välja dubbletter av rader i SQL. För att starta SQL-kontrollen efter dubbletter som fanns tidigare, körde jag SELECT-delen av INSERT INTO SELECT-satsen:
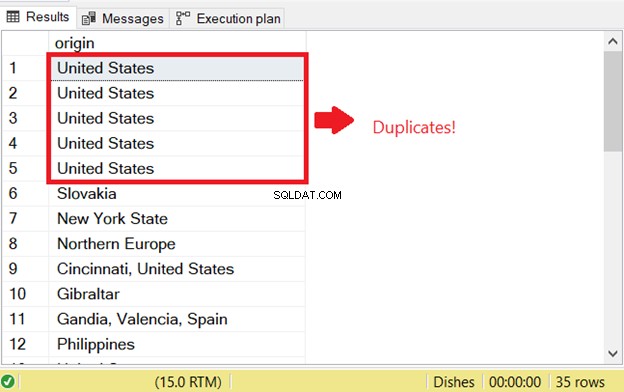
Det är anledningen till det första SQL-dupliceringsfelet. För att förhindra det, lägg till nyckelordet DISTINCT för att göra resultatuppsättningen unik. Här är rätt kod:
-- The correct way to INSERT
INSERT INTO Origin
(Origin)
SELECT DISTINCT origin FROM NonItalianPastaDishes
INSERT INTO Origin
(Origin)
SELECT DISTINCT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
Det infogar posterna framgångsrikt. Och vi är klara med Ursprunget bord.
Genom att använda DISTINCT skapas unika poster ur SELECT-satsen. Det garanterar dock inte att dubbletter inte finns i måltabellen. Det är bra när du är säker på att måltabellen inte har de värden du vill infoga.
Så kör inte dessa uttalanden mer än en gång.
2. Använder WHERE NOT IN
Därefter fyller vi i PastaDishes tabell. För det måste vi först infoga poster från ItalianPastaDishes tabell. Här är koden:
INSERT INTO [dbo].[PastaDishes]
(PastaDishName,OriginID, Description)
SELECT
a.DishName
,b.OriginID
,a.Description
FROM ItalianPastaDishes a
INNER JOIN Origin b ON a.ItalianRegion + ', ' + 'Italy' = b.Origin
WHERE a.DishName NOT IN (SELECT PastaDishName FROM PastaDishes)
Sedan ItalianPastaDishes innehåller rådata måste vi gå med i Ursprunget text istället för OriginID . Försök nu att köra samma kod två gånger. Andra gången den körs kommer inga poster att infogas. Det händer på grund av WHERE-satsen med NOT IN-operatorn. Den filtrerar bort poster som redan finns i måltabellen.
Därefter måste vi fylla i PastaDishes tabellen från NonItalianPastaDishes tabell. Eftersom vi bara är vid den andra punkten i det här inlägget kommer vi inte att infoga allt.
Vi plockade pastarätter från USA och Filippinerna. Här kommer:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using NOT IN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
AND b.OriginID IN (15,22)
Det finns 9 poster infogade från detta uttalande – se figur 2 nedan:
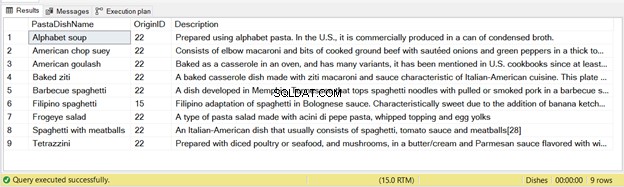
Återigen, om du kör koden ovan två gånger kommer den andra körningen inte att ha några poster infogade.
3. Använder WHERE NOT EXISTS
Ett annat sätt att hitta dubbletter i SQL är att använda NOT EXISTS i WHERE-satsen. Låt oss prova det med samma villkor från föregående avsnitt:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using WHERE NOT EXISTS
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
AND b.OriginID IN (15,22)
Koden ovan kommer att infoga samma 9 poster som du såg i figur 2. Det kommer att undvika att infoga samma poster mer än en gång.
4. Använder OM INTE FINNS
Ibland kan du behöva distribuera en tabell till databasen och det är nödvändigt att kontrollera om en tabell med samma namn redan finns för att undvika dubbletter. I det här fallet kan kommandot SQL DROP TABLE IF EXISTS vara till stor hjälp. Ett annat sätt att säkerställa att du inte infogar dubbletter är att använda OM INTE FINNS. Återigen kommer vi att använda samma villkor från föregående avsnitt:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using IF NOT EXISTS
IF NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
BEGIN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
END
Ovanstående kod kommer först att kontrollera om det finns 9 poster. Om den returnerar sant fortsätter INSERT.
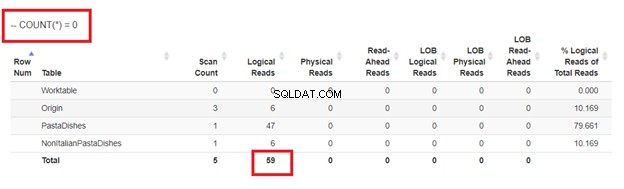
5. Använder COUNT(*) =0
Slutligen kan användningen av COUNT(*) i WHERE-satsen också säkerställa att du inte infogar dubbletter. Här är ett exempel:
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
AND (SELECT COUNT(*) FROM PastaDishes pd
WHERE pd.OriginID IN (15,22)) = 0
För att undvika dubbletter bör ANTAL eller poster som returneras av underfrågan ovan vara noll.
Obs :Du kan designa vilken fråga som helst visuellt i ett diagram med hjälp av Query Builder-funktionen i dbForge Studio för SQL Server.
Jämföra olika sätt att hantera dubbletter med SQL INSERT INTO SELECT
4 sektioner använde samma utdata men olika metoder för att infoga bulkposter med en SELECT-sats. Du kanske undrar om skillnaden bara ligger på ytan. Vi kan kontrollera deras logiska läsningar från STATISTICS IO för att se hur olika de är.
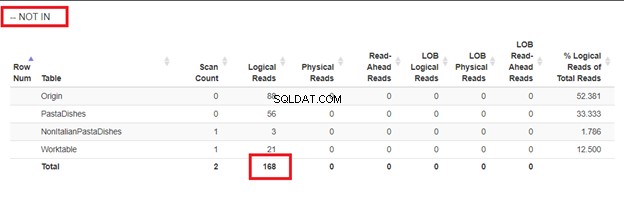
Använder WHERE NOT IN:
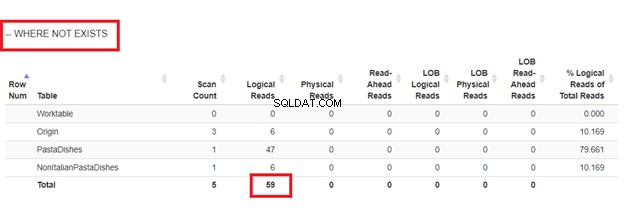
Använder INTE EXISTS:
Använder OM INTE FINNS:
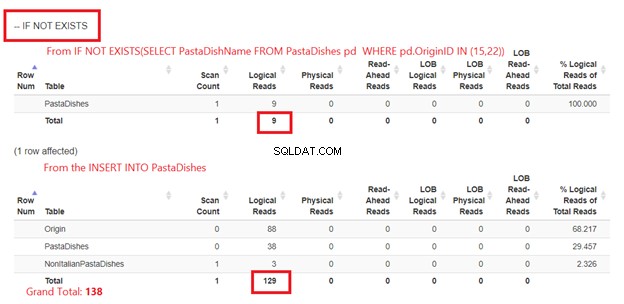
Bild 5 är lite annorlunda. 2 logiska läsningar visas för PastaDishes tabell. Den första är från IF NOT EXISTS(SELECT PastaDishName från PastaDishes VAR OriginID IN (15,22)). Den andra är från INSERT-satsen.
Använd slutligen COUNT(*) =0
Från de logiska läsningarna av 4 tillvägagångssätt vi hade, är det bästa valet WHERE NOT EXISTS eller COUNT(*) =0. När vi inspekterar deras exekveringsplaner ser vi att de har samma QueryHashPlan . De har alltså liknande planer. Under tiden använder den minst effektiva NOT IN.
Betyder det att WHERE NOT EXISTS alltid är bättre än INTE IN? Inte alls.
Inspektera alltid de logiska läsningarna och exekveringsplanen för dina frågor!
Men innan vi avslutar måste vi slutföra uppgiften. Sedan infogar vi resten av posterna och inspekterar resultaten.
-- Insert the rest of the records
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
GO
-- View the output
SELECT
a.PastaDishID
,a.PastaDishName
,b.Origin
,a.Description
,a.Modified
FROM PastaDishes a
INNER JOIN Origin b ON a.OriginID = b.OriginID
ORDER BY b.Origin, a.PastaDishName
Att bläddra bland listan med 179 pastarätter från Asien till Europa gör mig hungrig. Kolla in en del av listan från Italien, Ryssland och mer nedan:

Slutsats
Att undvika dubbletter i SQL INSERT INTO SELECT är trots allt inte så svårt. Du har operatörer och funktioner till hands för att ta dig till den nivån. Det är också en god vana att kontrollera genomförandeplanen och logiska läsningar för att jämföra vilket som är bättre.
Om du tror att någon annan kommer att dra nytta av det här inlägget, vänligen dela det på dina favoritplattformar för sociala medier. Och om du har något att tillägga som vi glömt, låt oss veta i kommentarsektionen nedan.