När SQL Server 2012 fortfarande var i beta, bloggade jag om den nya FORMAT() funktion:SQL Server v.Next (Denali):CTP3 T-SQL-förbättringar:FORMAT().
Vid den tiden var jag så exalterad över den nya funktionen att jag inte ens tänkte på att göra några prestandatester. Jag tog upp detta i ett nyare blogginlägg, men enbart i samband med att ta bort tid från en datetime:Trimma tid från datetime – en uppföljning.
Förra veckan trollade min gode vän Jason Horner (blogg | @jasonhorner) mig med dessa tweets:
| |
Mitt problem med detta är bara att FORMAT() ser bekvämt ut, men det är extremt ineffektivt jämfört med andra tillvägagångssätt (oh och det AS VARCHAR sak är dålig också). Om du gör det här ett och två gånger och för små resultatuppsättningar, skulle jag inte oroa dig för mycket om det; men i stor skala kan det bli ganska dyrt. Låt mig illustrera med ett exempel. Låt oss först skapa en liten tabell med 1000 pseudo-slumpmässiga datum:
SELECT TOP (1000) d = DATEADD(DAY, CHECKSUM(NEWID())%1000, o.create_date) INTO dbo.dtTest FROM sys.all_objects AS o ORDER BY NEWID(); GO CREATE CLUSTERED INDEX d ON dbo.dtTest(d);
Låt oss nu fylla cachen med data från den här tabellen och illustrera tre av de vanligaste sätten som människor tenderar att presentera just tiden på:
SELECT d, CONVERT(DATE, d), CONVERT(CHAR(10), d, 120), FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest;
Låt oss nu utföra individuella frågor som använder dessa olika tekniker. Vi kör dem var 5 gånger och vi kör följande varianter:
- Väljer alla 1 000 rader
- Väljar TOP (1) sorterad efter den klustrade indexnyckeln
- Tilldelning till en variabel (som tvingar fram en fullständig genomsökning, men förhindrar SSMS-rendering från att störa prestandan)
Här är manuset:
-- select all 1,000 rows GO SELECT d FROM dbo.dtTest; GO 5 SELECT d = CONVERT(DATE, d) FROM dbo.dtTest; GO 5 SELECT d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest; GO 5 SELECT d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest; GO 5 -- select top 1 GO SELECT TOP (1) d FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) CONVERT(DATE, d) FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest ORDER BY d; GO 5 -- force scan but leave SSMS mostly out of it GO DECLARE @d DATE; SELECT @d = d FROM dbo.dtTest; GO 5 DECLARE @d DATE; SELECT @d = CONVERT(DATE, d) FROM dbo.dtTest; GO 5 DECLARE @d CHAR(10); SELECT @d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest; GO 5 DECLARE @d CHAR(10); SELECT @d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest; GO 5
Nu kan vi mäta prestandan med följande fråga (mitt system är ganska tyst; på ditt kan du behöva utföra mer avancerad filtrering än bara execution_count ):
SELECT [t] = CONVERT(CHAR(255), t.[text]), s.total_elapsed_time, avg_elapsed_time = CONVERT(DECIMAL(12,2),s.total_elapsed_time / 5.0), s.total_worker_time, avg_worker_time = CONVERT(DECIMAL(12,2),s.total_worker_time / 5.0), s.total_clr_time FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.[sql_handle]) AS t WHERE s.execution_count = 5 AND t.[text] LIKE N'%dbo.dtTest%' ORDER BY s.last_execution_time;
Resultaten i mitt fall var ganska konsekventa:
| Fråga (trunkerad) | Längd (mikrosekunder) | |||
|---|---|---|---|---|
| total_elapsed | avg_elapsed | total_clr | ||
| VÄLJ 1 000 rader | SELECT d FROM dbo.dtTest ORDER BY d; |
1,170 |
234.00 |
0 |
SELECT d = CONVERT(DATE, d) FROM dbo.dtTest ORDER BY d; |
2,437 |
487.40 |
0 |
|
SELECT d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ORD ... |
151,521 |
30,304.20 |
0 |
|
SELECT d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest ORDER ... |
240,152 |
48,030.40 |
107,258 |
|
| SELECT TOP (1) | SELECT TOP (1) d FROM dbo.dtTest ORDER BY d; |
251 |
50.20 |
0 |
SELECT TOP (1) CONVERT(DATE, d) FROM dbo.dtTest ORDER BY ... |
440 |
88.00 |
0 |
|
SELECT TOP (1) CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ... |
301 |
60.20 |
0 |
|
SELECT TOP (1) FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest O ... |
1,094 |
218.80 |
589 |
|
| Assign variable | DECLARE @d DATE; SELECT @d = d FROM dbo.dtTest; |
639 |
127.80 |
0 |
DECLARE @d DATE; SELECT @d = CONVERT(DATE, d) FROM dbo.d ... |
644 |
128.80 |
0 |
|
DECLARE @d CHAR(10); SELECT @d = CONVERT(CHAR(10), d, 12 ... | 1,972 |
394.40 |
0 |
|
DECLARE @d CHAR(10); SELECT @d = FORMAT(d, 'yyyy-MM-dd') ... |
118,062 |
23,612.40 |
98,556 |
|
And to visualize the avg_elapsed_time output (klicka för att förstora):
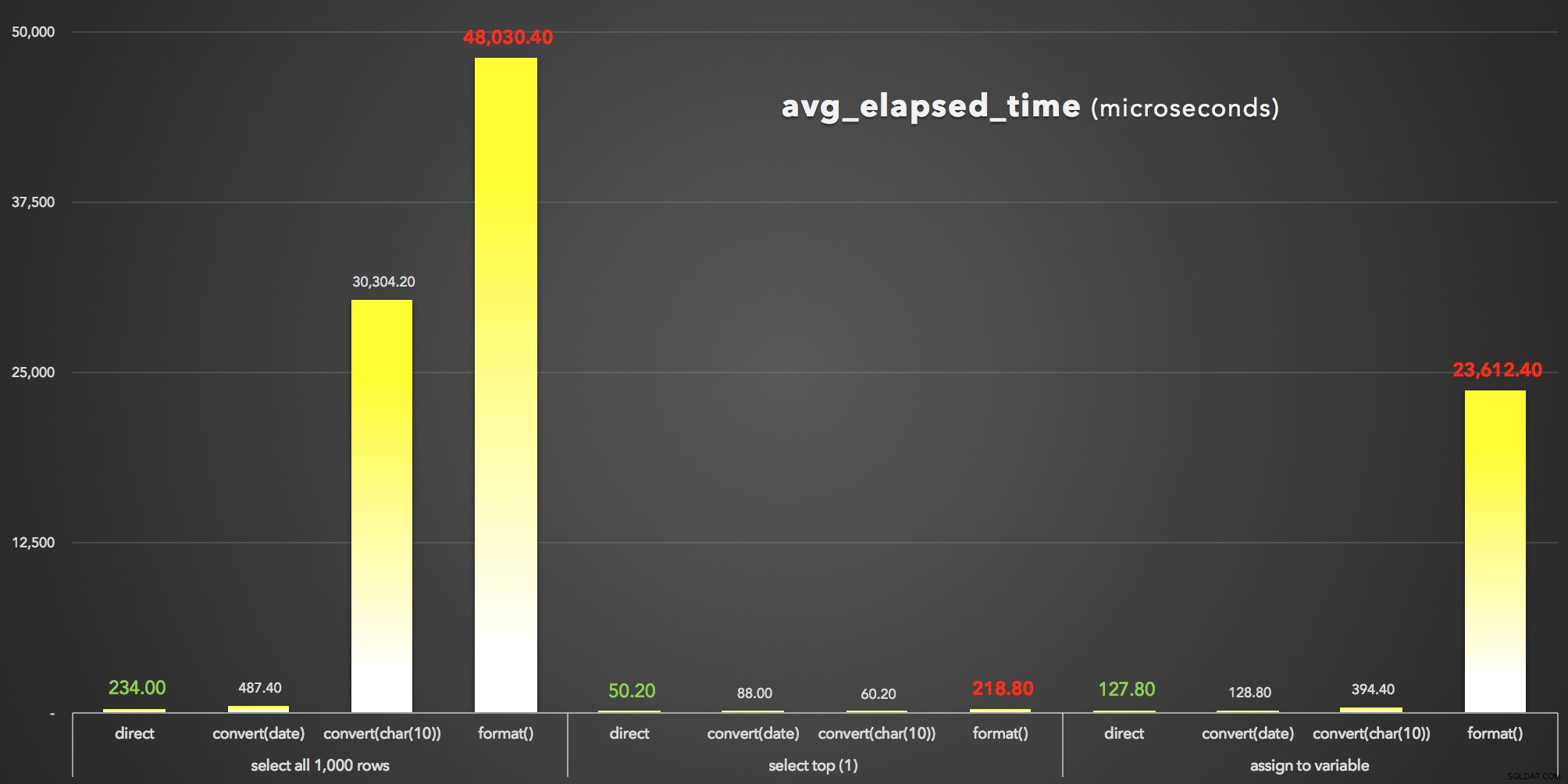 FORMAT() är helt klart förloraren :resultat avg_elapsed_time (mikrosekunder)
FORMAT() är helt klart förloraren :resultat avg_elapsed_time (mikrosekunder)
Vad vi kan lära oss av dessa resultat (igen):
- Först och främst
FORMAT()är dyrt . FORMAT()kan visserligen ge mer flexibilitet och ge mer intuitiva metoder som överensstämmer med de på andra språk som C#. Men utöver dess overhead, och medanCONVERT()stilnummer är kryptiska och mindre uttömmande, du kanske måste använda den äldre metoden ändå, eftersomFORMAT()är endast giltig i SQL Server 2012 och senare.- Till och med vänteläget
CONVERT()metoden kan vara drastiskt dyr (men bara allvarligt i de fall där SSMS var tvungen att återge resultaten - den hanterar helt klart strängar annorlunda än datumvärden). - Att bara dra ut datetime-värdet direkt från databasen var alltid mest effektivt. Du bör ange vilken extra tid det tar för din applikation att formatera datumet som önskat på presentationsnivån - det är högst troligt att du inte alls kommer att vilja att SQL Server ska engagera sig i snyggingsformatet (och faktiskt många skulle hävda att det är där den logiken alltid hör hemma).
Vi pratar bara om mikrosekunder här, men vi pratar också bara om 1 000 rader. Skala ut det till dina faktiska tabellstorlekar, och effekten av att välja fel formateringsmetod kan vara förödande.
Om du vill prova det här experimentet på din egen maskin har jag laddat upp ett exempelskript:FormatIsNiceAndAllBut.sql_.zip