Översikt
Den här artikeln diskuterar två olika metoder som är tillgängliga för att ta bort dubbletter av rader från SQL-tabeller, vilket ofta blir svårt med tiden eftersom data växer om detta inte görs i tid.
Förekomsten av dubblettrader är ett vanligt problem som SQL-utvecklare och testare ställs inför då och då, men dessa dubblettrader faller inom ett antal olika kategorier som vi kommer att diskutera i den här artikeln.
Den här artikeln fokuserar på ett specifikt scenario, när data infogas i en databastabell, leder till introduktionen av dubbletter av poster och sedan kommer vi att titta närmare på metoder för att ta bort dubbletter och slutligen ta bort dubbletter med dessa metoder.
Förbereda exempeldata
Innan vi börjar utforska de olika tillgängliga alternativen för att ta bort dubbletter, är det värt att nu skapa en exempeldatabas som kommer att hjälpa oss att förstå situationerna när duplicerade data tar sig in i systemet och de metoder som ska användas för att utrota dem .
Konfigurera Sample Database (UniversityV2)
Börja med att skapa en mycket enkel databas som endast består av en elev tabell i början.
-- (1) Create UniversityV2 sample database
CREATE DATABASE UniversityV2;
GO
USE UniversityV2
CREATE TABLE [dbo].[Student] (
[StudentId] INT IDENTITY (1, 1) NOT NULL,
[Name] VARCHAR (30) NULL,
[Course] VARCHAR (30) NULL,
[Marks] INT NULL,
[ExamDate] DATETIME2 (7) NULL,
CONSTRAINT [PK_Student] PRIMARY KEY CLUSTERED ([StudentId] ASC)
);
Befolka elevtabell
Låt oss bara lägga till två poster i elevtabellen:
-- Adding two records to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (1, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (2, N'Peter', N'Database Management System', 85, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Datakontroll
Se tabellen som innehåller två distinkta poster för tillfället:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
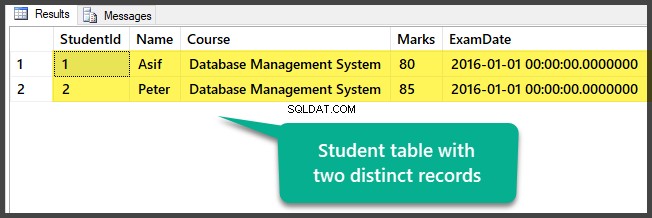
Du har framgångsrikt förberett exempeldatan genom att skapa en databas med en tabell och två distinkta (olika) poster.
Vi kommer nu att diskutera några potentiella scenarier där dubbletter introducerades och raderades från enkla till lite komplexa situationer.
Fall 01:Lägga till och ta bort dubbletter
Nu ska vi introducera dubbletter av rad(er) i elevtabellen.
Förutsättningar
I det här fallet sägs en tabell ha dubbletter av poster om en elevs namn , Kurs , märken och ExamDate sammanfaller i mer än en post även om elevens ID är annorlunda.
Så vi antar att inga två elever kan ha samma namn, kurs, betyg och tentamensdatum.
Lägga till dubbletter av data för Student Asif
Låt oss medvetet infoga en dubblettpost för Student:Asif till eleven tabell enligt följande:
-- Adding Student Asif duplicate record to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (3, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Visa dubbletter av studentdata
Visa eleven tabell för att se dubbletter av poster:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
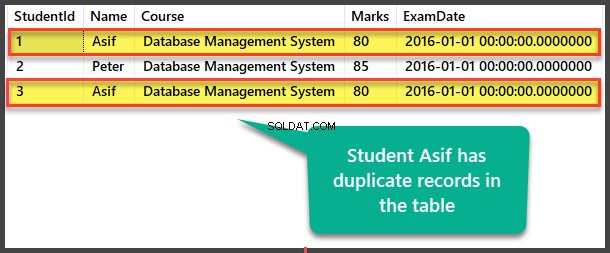
Hitta dubbletter med självreferensmetoden
Tänk om det finns tusentals poster i den här tabellen, då är det inte mycket hjälp att titta på tabellen.
I självreferensmetoden tar vi två referenser till samma tabell och sammanfogar dem med hjälp av kolumn-för-kolumn-mappning med undantag för ID:t som görs mindre än eller större än det andra.
Låt oss titta på självreferensmetoden för att hitta dubbletter som ser ut så här:
USE UniversityV2
-- Self-Referencing method to finding duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1,[dbo].[Student] S2
WHERE S1.StudentId<S2.StudentId AND
S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
Utdata från ovanstående skript visar oss endast dubblettposterna:

Hitta dubbletter genom självreferensmetod-2
Ett annat sätt att hitta dubbletter med hjälp av självreferens är att använda INNER JOIN enligt följande:
-- Self-Referencing method 2 to find duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
INNER JOIN
[dbo].[Student] S2
ON S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
WHERE S1.StudentId<S2.StudentId

Ta bort dubbletter med självreferensmetoden
Vi kan ta bort dubbletter med samma metod som vi använde för att hitta dubbletter med undantag för att använda DELETE i linje med dess syntax enligt följande:
USE UniversityV2
-- Removing duplicates by using Self-Referencing method
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
Datakontroll efter borttagning av dubbletter
Låt oss snabbt kontrollera posterna efter att vi har tagit bort dubbletterna:
USE UniversityV2
-- View Student data after duplicates have been removed
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
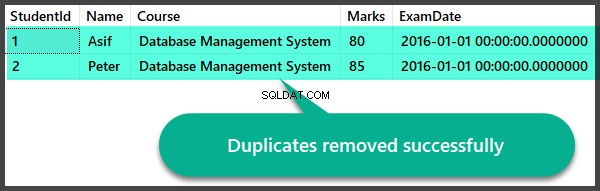
Skapa dubbletter Visa och ta bort dubbletter lagrad procedur
Nu när vi vet att våra skript framgångsrikt kan hitta och ta bort dubbletter av rader i SQL, är det bättre att omvandla dem till visning och lagrad procedur för att underlätta användningen:
USE UniversityV2;
GO
-- Creating view find duplicate students having same name, course, marks, exam date using Self-Referencing method
CREATE VIEW dbo.Duplicates
AS
SELECT
S1.[StudentId] AS S1_StudentId
,S2.StudentId AS S2_StudentID
,S1.Name AS S1_Name
,S2.Name AS S2_Name
,S1.Course AS S1_Course
,S2.Course AS S2_Course
,S1.ExamDate AS S1_ExamDate
,S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
,[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
GO
-- Creating stored procedure to removing duplicates by using Self-Referencing method
CREATE PROCEDURE UspRemoveDuplicates
AS
BEGIN
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
END
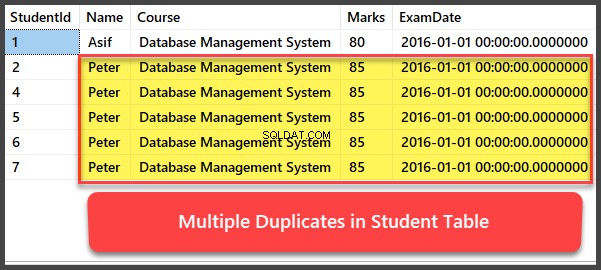
Lägga till och visa flera dubbletter av poster
Låt oss nu lägga till ytterligare fyra poster till Studenten tabell och alla poster är dubbletter på ett sådant sätt att de har samma namn, kurs, betyg och tentamensdatum:
--Adding multiple duplicates to Student table
INSERT INTO Student (Name,
Course,
Marks,
ExamDate)
VALUES ('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01');
-- Viewing Student table after multiple records have been added to Student table
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Ta bort dubbletter genom att använda UspRemoveDuplicates-proceduren
USE UniversityV2
-- Removing multiple duplicates
EXEC UspRemoveDuplicates
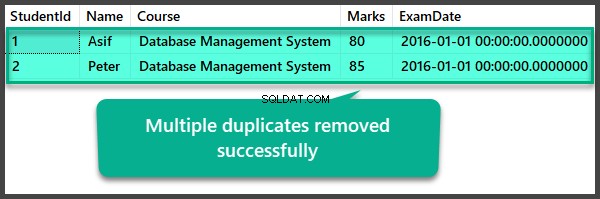
Datakontroll efter borttagning av flera dubbletter
USE UniversityV2
--View Student table after multiple duplicates removal
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Fall 02:Lägga till och ta bort dubbletter med samma ID
Hittills har vi identifierat dubbletter av poster med distinkta ID:n, men tänk om ID:n är desamma.
Tänk till exempel på scenariot där en tabell nyligen har importerats från en text- eller Excel-fil som inte har någon primärnyckel.
Förutsättningar
I det här fallet sägs en tabell ha dubblettposter om alla kolumnvärdena är exakt samma inklusive någon ID-kolumn och primärnyckeln saknas vilket gjorde det lättare att ange dubblettposterna.
Skapa kurstabell utan primärnyckel
För att återskapa scenariot där dubbletter av poster i frånvaro av en primärnyckel hamnar i en tabell, låt oss först skapa en ny kurs tabell utan någon primärnyckel i University2-databasen enligt följande:
USE UniversityV2
-- Creating Course table without primary key
CREATE TABLE [dbo].[Course] (
[CourseId] INT NOT NULL,
[Name] VARCHAR (30) NOT NULL,
[Detail] VARCHAR (200) NULL,
);
Följ kurstabell
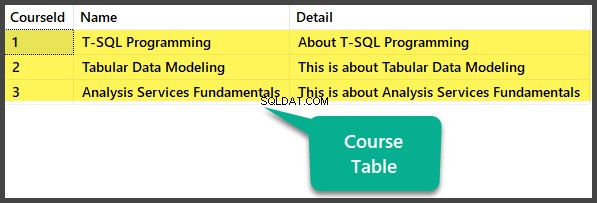
-- Populating Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (2, N'Tabular Data Modeling', N'This is about Tabular Data Modeling')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (3, N'Analysis Services Fundamentals', N'This is about Analysis Services Fundamentals')
Datakontroll
Se Kursen tabell:
USE UniversityV2
-- Viewing Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course
Lägga till dubbletter av data i kurstabell
Infoga nu dubbletter i Kursen tabell:
USE UniversityV2
-- Inserting duplicate records in Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
Visa dubbletter av kursdata
Välj alla kolumner för att se tabellen:
USE UniversityV2
-- Viewing duplicate data in Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course

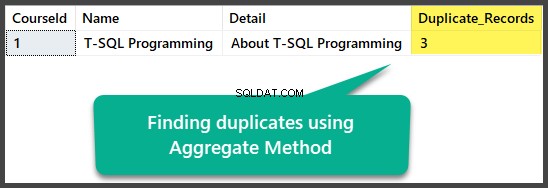
Hitta dubbletter med aggregerad metod
Vi kan hitta exakta dubbletter genom att använda aggregatmetoden genom att gruppera alla kolumner med totalt mer än en efter att ha valt alla kolumner tillsammans med att räkna alla rader med funktionen aggregat count(*):
-- Finding duplicates using Aggregate method
SELECT <column1>,<column2>,<column3>…
,COUNT(*) AS Total_Records
FROM <Table>
GROUP BY <column1>,<column2>,<column3>…
HAVING COUNT(*)>1
Detta kan tillämpas enligt följande:
USE UniversityV2
-- Finding duplicates using Aggregate method
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
Ta bort dubbletter med aggregerad metod
Låt oss ta bort dubbletterna med hjälp av Aggregate Method enligt följande:
USE UniversityV2
-- Removing duplicates using Aggregate method
-- (1) Finding duplicates and put them into a new table (CourseNew) as a single row
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records INTO CourseNew
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
-- (2) Rename Course (which contains duplicates) as Course_OLD
EXEC sys.sp_rename @objname = N'Course'
,@newname = N'Course_OLD'
-- (3) Rename CourseNew (which contains no duplicates) as Course
EXEC sys.sp_rename @objname = N'CourseNew'
,@newname = N'Course'
-- (4) Insert original distinct records into Course table from Course_OLD table
INSERT INTO Course (CourseId, Name, Detail)
SELECT
co.CourseId
,co.Name
,co.Detail
FROM Course_OLD co
WHERE co.CourseId <> (SELECT
c.CourseId
FROM Course c)
ORDER BY CO.CourseId
-- (4) Data check
SELECT
cn.CourseId
,cn.Name
,cn.Detail
FROM Course cn
-- Clean up
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
Datakontroll
ANVÄND UniversityV2
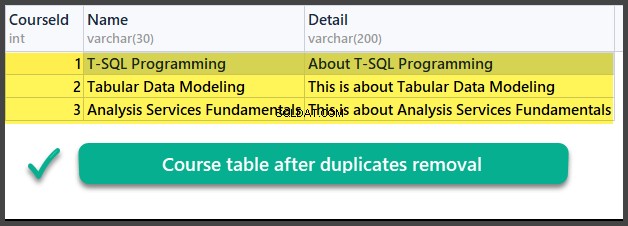
Så vi har framgångsrikt lärt oss hur man tar bort dubbletter från en databastabell med två olika metoder baserat på två olika scenarier.
Saker att göra
Du kan nu enkelt identifiera och befria en databastabell från dubblettvärden.
1. Prova att skapa UspRemoveDuplicatesByAggregate lagrad procedur baserat på metoden som nämns ovan och ta bort dubbletter genom att anropa den lagrade proceduren
2. Prova att ändra den lagrade proceduren som skapats ovan (UspRemoveDuplicatesByAggregates) och implementera Rensa tips som nämns i den här artikeln.
DROP TABLE CourseNew
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
3. Kan du vara säker på att UspRemoveDuplicatesByAggregate lagrad procedur kan köras så många gånger som möjligt, även efter att du tagit bort dubbletterna, för att visa att proceduren förblir konsekvent i första hand?
4. Se min tidigare artikel Hoppa till Start Testdriven Database Development (TDDD) – Del 1 och försök infoga dubbletter i SQLDevBlog-databastabellerna, försök efter det att ta bort dubbletterna med båda metoderna som nämns i detta tips.
5. Försök att skapa en annan exempeldatabas EmployeesSample hänvisar till min tidigare artikel Art of Isolating Dependencies and Data in Database Unit Testing och infoga dubbletter i tabellerna och försök ta bort dem med båda metoderna du lärde dig från det här tipset.
Användbart verktyg:
dbForge Data Compare för SQL Server – kraftfullt SQL-jämförelseverktyg som kan arbeta med big data.