Obs! Det här inlägget publicerades ursprungligen endast i vår e-bok, High Performance Techniques for SQL Server, Volym 2. Du kan ta reda på om våra e-böcker här.
Sammanfattning:Den här artikeln undersöker en del överraskande beteende hos ISTÄLLET FÖR utlösare och avslöjar en allvarlig bugg för uppskattning av kardinalitet i SQL Server 2014.
Triggers och radversionering
Endast DML AFTER-utlösare använder radversionshantering (i SQL Server 2005 och framåt) för att tillhandahålla den insatta och raderade pseudotabeller i en triggerprocedur. Denna poäng framgår inte tydligt i mycket av den officiella dokumentationen. På de flesta ställen säger dokumentationen helt enkelt att radversionering används för att bygga den insatta och raderade tabeller i triggers utan kvalifikationer (exempel nedan):
Användning av radversionsresurs
Förstå radversionsbaserade isoleringsnivåer
Kontrollera utlösarkörning vid massimport av data
Förmodligen skrevs de ursprungliga versionerna av dessa poster innan INSTEAD OF triggers lades till produkten och uppdaterades aldrig. Antingen det, eller så är det ett enkelt (men upprepat) förbiseende.
Hur som helst, hur radversionering fungerar med AFTER-utlösare är ganska intuitivt. Dessa utlösare utlöses efter ändringarna i fråga har utförts, så det är lätt att se hur underhåll av versioner av de modifierade raderna gör det möjligt för databasmotorn att tillhandahålla den insatta och raderade pseudo-tabeller. Den borttagna pseudotabell är konstruerad från versioner av de berörda raderna innan ändringarna ägde rum; den insatta pseudotabellen bildas från versionerna av de berörda raderna vid den tidpunkt då triggerproceduren startade.
Istället för utlösare
I STÄLLET FÖR utlösare är olika eftersom denna typ av DML-utlösare helt ersätter den utlösta åtgärden. Den insatta och raderade pseudotabeller representerar nu ändringar som skulle ha gjorts, om det utlösande uttalandet faktiskt hade verkställts. Row-versioning kan inte användas för dessa utlösare eftersom inga ändringar har skett, per definition. Så, om du inte använder radversioner, hur gör SQL Server det?
Svaret är att SQL Server ändrar exekveringsplanen för den utlösande DML-satsen när en INSTEAD OF-utlösare finns. Istället för att modifiera de berörda tabellerna direkt, skriver exekveringsplanen information om ändringarna i en dold arbetstabell. Denna arbetstabell innehåller all data som behövs för att utföra de ursprungliga ändringarna, vilken typ av modifiering som ska utföras på varje rad (radera eller infoga), samt all information som behövs i utlösaren för en OUTPUT-sats.
Exekutivplan utan trigger
För att se allt detta i aktion kommer vi först att köra ett enkelt test utan att det finns en trigger I STÄLLET FÖR:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Utförandeplanen för borttagningen är mycket enkel:
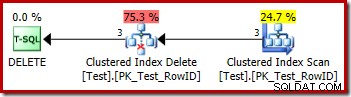
Varje rad som kvalificerar sig skickas direkt till en Clustered Index Delete-operator, som tar bort den. Lätt.
Exekutivplan med en ISTADEN FÖR trigger
Låt oss nu modifiera testet så att det inkluderar en INSTAD OF DELETE-utlösare (en som bara utför samma raderingsåtgärd för enkelhetens skull):
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Utförandeplanen för DELETE är nu helt annorlunda:
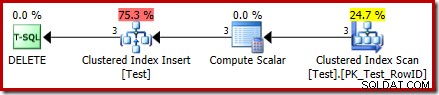
Operatorn Clustered Index Delete har ersatts av en Clustered Index Infoga . Detta är infogningen till den dolda arbetstabellen, som döps om (i den offentliga utförandeplansrepresentationen) till namnet på bastabellen som påverkas av borttagningen. Byte av namn sker när XML-showplanen genereras från den interna exekveringsplanrepresentationen, så det finns inget dokumenterat sätt att se den dolda arbetstabellen.
Som ett resultat av denna förändring verkar planen därför utföra en insättning till bastabellen för att ta bort rader från den. Detta är förvirrande, men det avslöjar åtminstone närvaron av en ISTADEN FÖR trigger. Att ersätta Insert-operatorn med en Delete kan vara ännu mer förvirrande. Det ideala skulle kanske vara en ny grafisk ikon för ett ISTÄLLET FÖR triggerarbetsbord? Hur som helst, det är vad det är.
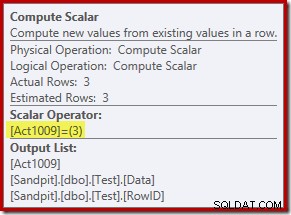
Den nya Compute Scalar-operatorn definierar typen av åtgärd som utförs på varje rad. Denna åtgärdskod är ett heltal med följande betydelser:
- 3 =DELETE
- 4 =INFOGA
- 259 =DELETE i en MERGE-plan
- 260 =INFOGA i en SLUT-plan
För den här frågan är åtgärden en konstant 3, vilket betyder att varje rad ska raderas :
Uppdatera åtgärder
Dessutom ersätter en exekveringsplan INSTEAD OF UPDATE en enda uppdateringsoperatör med två Clustered Index Infogar i samma dolda arbetsbord – en för de insatta pseudotabellrader och en för de borttagna pseudotabellrader. Ett exempel på genomförandeplan:

En MERGE som utför en UPPDATERING producerar också en exekveringsplan med två inlägg till samma bastabell av liknande skäl:

Utlösande exekveringsplan
Utförandeplanen för triggerkroppen har också några intressanta funktioner:
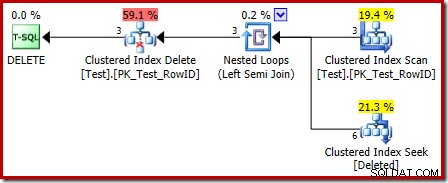
Det första att lägga märke till är att den grafiska ikonen som används för den borttagna tabellen inte är densamma som ikonen som används i AFTER trigger planer:
Representationen i ISTÄLLET FÖR triggerplanen är en Clustered Index Seek. Det underliggande objektet är samma interna arbetsbord som vi såg tidigare, men här heter det raderat istället för att få bastabellnamnet, förmodligen för någon form av överensstämmelse med AFTER-utlösare.
Sökoperationen på borttaget tabellen kanske inte var vad du förväntade dig (om du förväntade dig en sökning på RowID):
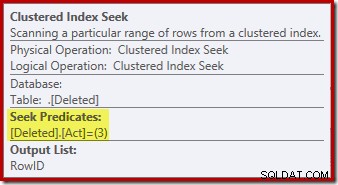
Denna "sökning" returnerar alla rader från arbetstabellen som har en åtgärdskod på 3 (radera), vilket gör den exakt lika med Deleted Scan operatör ses i AFTER trigger planer. Samma interna arbetstabell används för att hålla rader för båda insatta och raderade pseudo-tabeller i STÄLLET FÖR triggers. Motsvarigheten till en insatt skanning är en sökning på åtgärdskod 4 (vilket är möjligt i en radera trigger, men resultatet kommer alltid att vara tomt). Det finns inga index på den interna arbetstabellen förutom det icke-unika klustrade indexet på åtgärden enbart kolumn. Dessutom finns det ingen statistik kopplad till detta interna index.
Analysen hittills kan få dig att undra var sammankopplingen mellan RowID-kolumnerna utförs. Den här jämförelsen sker med operatören Nested Loops Left Semi Join som ett restpredikat:
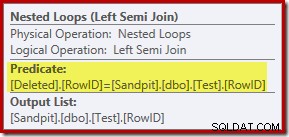
Nu när vi vet att "sök" är i praktiken en fullständig genomsökning av de borttagna tabell, verkar exekveringsplanen som valts av frågeoptimeraren ganska ineffektiv. Det övergripande flödet av exekveringsplanen är att varje rad från testtabellen potentiellt jämförs med hela uppsättningen borttagna rader, vilket låter mycket som en kartesisk produkt.
Det räddande är att kopplingen är en semi-join, vilket innebär att jämförelseprocessen stannar för en given testrad så snart den första raderades rad uppfyller restpredikatet. Ändå verkar strategin vara nyfiken. Kanske skulle utförandeplanen vara bättre om testtabellen innehöll fler rader?
Triggertest med 1 000 rader
Följande skript kan användas för att testa triggern med ett större antal rader. Vi börjar med 1 000:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 1000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Utförandeplanen för triggerkroppen är nu:
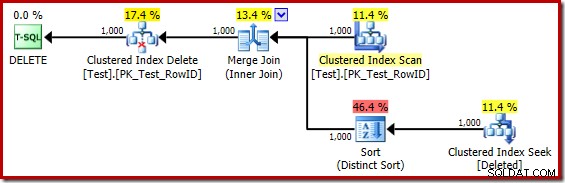
Genom att mentalt ersätta (vilseledande) Clustered Index Seek med en Deleted Scan, ser planen generellt sett ganska bra ut. Optimizern har valt en en-till-många Merge Join istället för en Nested Loops Semi Join, vilket verkar rimligt. The Distinct Sort är dock ett konstigt tillägg:
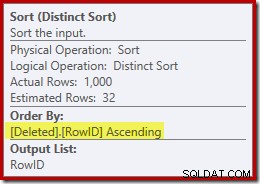
Denna sort utför två funktioner. För det första tillhandahåller den sammanslagningen med den sorterade indata den behöver, vilket är rimligt nog eftersom det inte finns något index på den interna arbetstabellen för att tillhandahålla den nödvändiga ordningen. Det andra slaget gör är att skilja på RowID. Detta kan tyckas konstigt, eftersom RowID är den primära nyckeln i bastabellen.
Problemet är att rader i borttaget Tabellen är helt enkelt kandidatrader som den ursprungliga DELETE-frågan identifierade. Till skillnad från en AFTER-utlösare har dessa rader inte kontrollerats för restriktioner eller nyckelöverträdelser ännu, så frågeprocessorn har ingen garanti för att de faktiskt är unika.
Generellt sett är detta en mycket viktig punkt att ha i åtanke med ISTADEN FÖR utlösare:det finns ingen garanti för att raderna som tillhandahålls uppfyller någon av begränsningarna i bastabellen (inklusive INTE NULL). Detta är inte bara viktigt för triggerförfattaren att komma ihåg; det begränsar också de förenklingar och omvandlingar som frågeoptimeraren kan utföra.
En andra fråga som visas i Sorteringsegenskaperna ovan, men inte markerad, är att utdatauppskattningen bara är 32 rader. Den interna arbetstabellen har ingen statistik kopplad till sig, så optimeraren gissar vid effekten av distinktoperationen. Vi "vet" att RowID-värdena är unika, men utan någon svår information att gå på, gör optimeraren en dålig gissning. Det här problemet kommer att förfölja oss i nästa test.
Triggertest med 5 000 rader
Ändra nu testskriptet för att generera 5 000 rader:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 5000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Utlösningsplanen är:
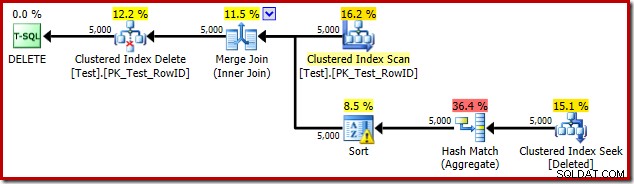
Den här gången har optimeraren beslutat att dela upp de distinkta och sortera operationerna. Distinkten på RowID utförs av operatorn Hash Match (Aggregate):
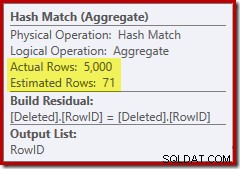
Lägg märke till att optimerarens uppskattning för utdata är 71 rader. Faktum är att alla 5 000 rader överlever det distinkta eftersom RowID är unikt. Den felaktiga uppskattningen innebär att en otillräcklig del av frågeminnesanslaget allokeras till sorteringen, vilket slutar med att spillas ut till tempdb :
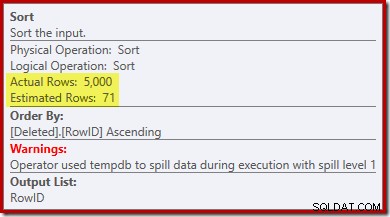
Detta test måste utföras på SQL Server 2012 eller högre för att se sorteringsvarningen i exekveringsplanen. I tidigare versioner innehåller planen ingen information om spill – ett Profiler-spår på händelsen Sort Warnings skulle behövas för att avslöja det (och du skulle behöva korrelera det tillbaka till källfrågan på något sätt).
Triggertest med 5 000 rader på SQL Server 2014
Om det tidigare testet upprepas på SQL Server 2014, i en databas som är inställd på kompatibilitetsnivå 120 så att den nya kardinalitetskalkylatorn (CE) används, är utlösarexekveringsplanen annorlunda igen:
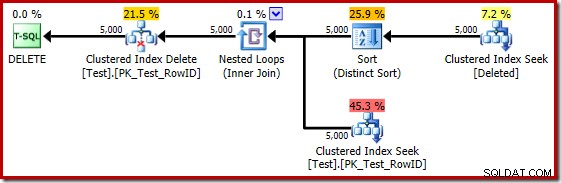
På vissa sätt verkar denna genomförandeplan vara en förbättring. Den (onödiga) Distinkta Sorteringen finns fortfarande kvar, men den övergripande strategin verkar mer naturlig:för varje distinkt kandidat RowID i borttaget tabell, gå med i bastabellen (så verifiera att kandidatraden faktiskt finns) och radera den sedan.
Tyvärr är 2014 års plan baserad på sämre kardinalitetsuppskattningar än vi såg i SQL Server 2012. Byt SQL Sentry Plan Explorer för att visa den uppskattade antal rader visar tydligt problemet:
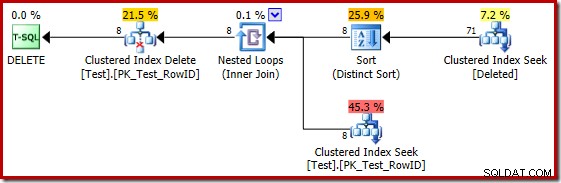
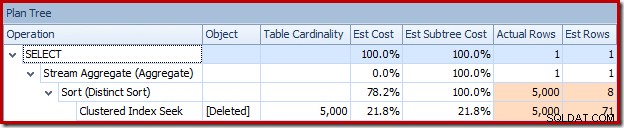
Optimeraren valde en Nested Loops-strategi för sammanfogningen eftersom den förväntade sig ett mycket litet antal rader på sin översta ingång. Det första problemet uppstår vid Clustered Index Seek. Optimeraren vet att den borttagna tabellen innehåller 5 000 rader vid denna tidpunkt, vilket vi kan se genom att byta till planträdvyn och lägga till den valfria kolumnen Tabellkardinalitet (som jag önskar inkluderade som standard):
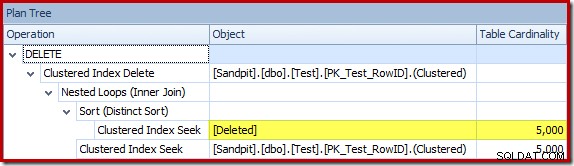
Den "gamla" kardinalitetsuppskattaren i SQL Server 2012 och tidigare är smart nog att veta att "sökningen" på den interna arbetstabellen skulle returnera alla 5 000 rader (så den valde en sammanfogning). Nya CE:n är inte så smart. Den ser arbetsbordet som en "svart låda" och gissar på effekten av sökningen på åtgärdskoden =3:
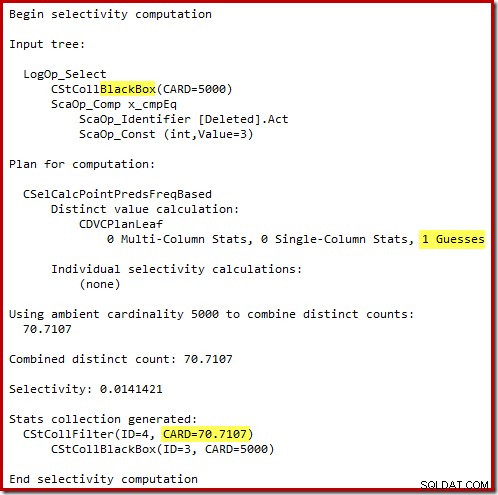
Gissningen på 71 rader (avrundat uppåt) är ett ganska olyckligt resultat, men felet förvärras när den nya CE uppskattar raderna för den distinkta operationen på dessa 71 rader:
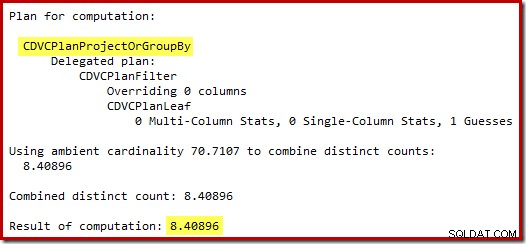
Baserat på de förväntade 8 raderna väljer optimeraren strategin Nested Loops. Ett annat sätt att se dessa uppskattningsfel är att lägga till följande sats i utlösarkroppen (endast i testsyfte):
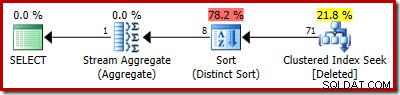
SELECT COUNT_BIG(DISTINCT RowID) FROM Deleted;
Den uppskattade planen visar uppskattningsfelen tydligt:
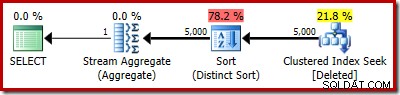
Själva planen visar naturligtvis fortfarande 5 000 rader:
Eller så kan du jämföra uppskattning mot faktisk samtidigt i planträdvyn:
En miljon rader...
De dåliga gissningsuppskattningarna när du använder kardinalitetsuppskattaren för 2014 gör att optimeraren väljer en strategi för kapslade loopar även när testtabellen innehåller en miljon rader. 2014 års nya CE uppskattad planen för det testet är:
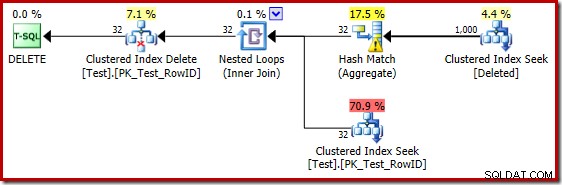
"Söken" uppskattar 1 000 rader från den kända kardinaliteten på 1 000 000 och den distinkta uppskattningen är 32 rader. Planen efter exekvering avslöjar effekten på minnet reserverat för Hash Match:
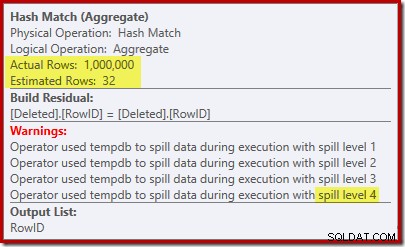
Hash Matchen förväntar sig endast 32 rader och hamnar i verkliga problem, rekursivt spilla hashtabellen innan den slutligen slutförs.
Sluta tankar
Även om det är sant att en trigger aldrig ska skrivas för att göra något som kan uppnås med deklarativ referensintegritet, är det också sant att en välskriven trigger som använder en effektiv genomförandeplanen kan vara jämförbar i prestanda med kostnaden för att upprätthålla ett extra icke-klusterat index.
Det finns två praktiska problem med ovanstående påstående. För det första (och med den bästa viljan i världen) skriver folk inte alltid bra triggerkod. För det andra kan det vara svårt att få en bra genomförandeplan från frågeoptimeraren under alla omständigheter. Utlösarens natur är att de anropas med ett brett utbud av indatakardinaliteter och datadistributioner.
Även för AFTER-utlösare, bristen på index och statistik på de borttagna och insatt pseudotabeller innebär att planval ofta baseras på gissningar eller felaktig information. Även där en bra plan väljs till en början kan senare avrättningar återanvända samma plan när en omkompilering skulle ha varit ett bättre val. Det finns sätt att kringgå begränsningarna, främst genom användning av tillfälliga tabeller och explicita index/statistik, men även där krävs stor försiktighet (eftersom triggers är en form av lagrad procedur).
Med INSTEAD OF triggers kan riskerna bli ännu större eftersom innehållet i den insatta och raderade tabeller är overifierade kandidater – frågeoptimeraren kan inte använda begränsningar på bastabellen för att förenkla och förfina sin exekveringsplan. Den nya kardinalitetskalkylatorn i SQL Server 2014 representerar också ett rejält steg bakåt när det kommer till I STÄLLET FÖR triggerplaner. Att gissa effekten av en sökoperation som motorn introducerade själv är en överraskande och ovälkommen förbiseende.