Förra månaden postade jag en utmaning för att skapa en effektiv nummerseriegenerator. Svaren var överväldigande. Det fanns många briljanta idéer och förslag, med massor av applikationer långt bortom just denna utmaning. Det fick mig att inse hur fantastiskt det är att vara en del av en gemenskap och att fantastiska saker kan uppnås när en grupp smarta människor går samman. Tack Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason och John Number2 för att du delar med dig av dina idéer och kommentarer.
Först tänkte jag bara skriva en artikel för att sammanfatta idéerna som folk skickade in, men det var för många. Så jag delar upp täckningen till flera artiklar. Den här månaden kommer jag i första hand att fokusera på Charlies och Alan Bursteins föreslagna förbättringar av de två ursprungliga lösningarna som jag postade förra månaden i form av inline-TVF:erna som heter dbo.GetNumsItzikBatch och dbo.GetNumsItzik. Jag kommer att namnge de förbättrade versionerna dbo.GetNumsAlanCharlieItzikBatch respektive dbo.GetNumsAlanCharlieItzik.
Det här är så spännande!
Itziks ursprungliga lösningar
Som en snabb påminnelse använder de funktioner jag täckte förra månaden en bas-CTE som definierar en tabellvärdekonstruktor med 16 rader. Funktionerna använder en serie kaskadkopplade CTE:er, som var och en applicerar en produkt (korskoppling) av två instanser av dess föregående CTE. På så sätt, med fem CTE:er utöver basen, kan du få en uppsättning på upp till 4 294 967 296 rader. En CTE som kallas Nums använder funktionen ROW_NUMBER för att producera en serie siffror som börjar med 1. Slutligen beräknar den yttre frågan talen i det begärda intervallet mellan ingångarna @låg och @hög.
Funktionen dbo.GetNumsItzikBatch använder en dummy-koppling till en tabell med ett kolumnlagerindex för att få batchbearbetning. Här är koden för att skapa dummy-tabellen:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Och här är koden som definierar funktionen dbo.GetNumsItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Jag använde följande kod för att testa funktionen med "Kassera resultat efter exekvering" aktiverat i SSMS:
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Här är prestandastatistiken som jag fick för den här körningen:
CPU time = 16985 ms, elapsed time = 18348 ms.
Funktionen dbo.GetNumsItzik är liknande, bara den har inte en dummy join och får normalt radlägesbearbetning genom hela planen. Här är funktionens definition:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Här är koden jag använde för att testa funktionen:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Här är prestandastatistiken som jag fick för den här körningen:
CPU time = 19969 ms, elapsed time = 21229 ms.
Alan Bursteins och Charlies förbättringar
Alan och Charlie föreslog flera förbättringar av mina funktioner, några med måttliga prestandaimplikationer och några med mer dramatiska. Jag börjar med Charlies upptäckter angående kompileringsoverhead och konstant vikning. Jag kommer sedan att täcka Alans förslag, inklusive 1-baserade kontra @låg-baserade sekvenser (även delade av Charlie och Jeff Moden), undvika onödig sortering och beräkna ett nummerintervall i motsatt ordning.
Kompileringstidsfynd
Som Charlie noterade används ofta en nummerseriegenerator för att generera serier med mycket litet antal rader. I dessa fall kan kompileringstiden för koden bli en betydande del av den totala frågebehandlingstiden. Det är särskilt viktigt när du använder iTVF, eftersom till skillnad från med lagrade procedurer, är det inte den parameteriserade frågekoden som optimeras, snarare frågekoden efter att parameterinbäddning äger rum. Med andra ord, parametrarna ersätts med ingångsvärdena före optimering, och koden med konstanterna optimeras. Denna process kan ha både negativa och positiva konsekvenser. En av de negativa implikationerna är att du får fler kompilationer då funktionen anropas med olika ingångsvärden. Av denna anledning bör kompileringstider definitivt tas med i beräkningen – särskilt när funktionen används mycket ofta med små intervall.
Här är sammanställningstiderna Charlie hittade för de olika bas-CTE-kardinaliteterna:
2: 22ms 4: 9ms 16: 7ms 256: 35ms
Det är märkligt att se att bland dessa är 16 det optimala, och att det blir ett mycket dramatiskt hopp när du går upp till nästa nivå, som är 256. Kom ihåg att funktionerna dbo.GetNumsItzikBacth och dbo.GetNumsItzik använder bas CTE-kardinalitet på 16 .
Konstant vikning
Konstant vikning är ofta en positiv implikation som under rätt förhållanden kan möjliggöras tack vare parameterinbäddningsprocessen som en iTVF upplever. Anta till exempel att din funktion har ett uttryck @x + 1, där @x är en indataparameter för funktionen. Du anropar funktionen med @x =5 som indata. Det infogade uttrycket blir då 5 + 1, och om det är kvalificerat för konstant vikning (mer om detta inom kort), blir det 6. Om detta uttryck är en del av ett mer utarbetat uttryck som involverar kolumner och tillämpas på många miljoner rader, kan detta resultera i icke försumbara besparingar i CPU-cykler.
Det knepiga är att SQL Server är väldigt kräsen när det gäller vad som ska vikas konstant och vad som inte ska vikas konstant. SQL Server kommer till exempel inte konstant vikning col1 + 5 + 1, och inte heller kommer den att vika 5 + col1 + 1. Men den kommer att vika 5 + 1 + col1 till 6 + col1. Jag vet. Så, till exempel, om din funktion returnerade SELECT @x + col1 + 1 AS mycol1 FRÅN dbo.T1, kan du aktivera konstant vikning med följande små ändring:SELECT @x + 1 + col1 AS mycol1 FRÅN dbo.T1. tro mig inte? Granska planerna för följande tre frågor i PerformanceV5-databasen (eller liknande frågor med dina data) och se själv:
SELECT orderid + 5 + 1 AS myorderid FROM dbo.orders; SELECT 5 + orderid + 1 AS myorderid FROM dbo.orders; SELECT 5 + 1 + orderid AS myorderid FROM dbo.orders;
Jag fick följande tre uttryck i Compute Scalar-operatorerna för dessa tre frågor:
[Expr1003] = Scalar Operator([PerformanceV5].[dbo].[Orders].[orderid]+(5)+(1)) [Expr1003] = Scalar Operator((5)+[PerformanceV5].[dbo].[Orders].[orderid]+(1)) [Expr1003] = Scalar Operator((6)+[PerformanceV5].[dbo].[Orders].[orderid])
Ser du vart jag är på väg med detta? I mina funktioner använde jag följande uttryck för att definiera resultatkolumnen n:
@low + rownum - 1 AS n
Charlie insåg att med följande lilla ändring kan han möjliggöra konstant vikning:
@low - 1 + rownum AS n
Till exempel, planen för den tidigare frågan som jag angav mot dbo.GetNumsItzik, med @low =1, hade ursprungligen följande uttryck definierat av Compute Scalar-operatorn:
[Expr1154] = Scalar Operator((1)+[Expr1153]-(1))
Efter tillämpning av ovanstående mindre ändring blir uttrycket i planen:
[Expr1154] = Scalar Operator((0)+[Expr1153])
Det är lysande!
När det gäller prestandakonsekvenserna, kom ihåg att prestandastatistiken som jag fick för frågan mot dbo.GetNumsItzikBatch före ändringen var följande:
CPU time = 16985 ms, elapsed time = 18348 ms.
Här är siffrorna jag fick efter ändringen:
CPU time = 16375 ms, elapsed time = 17932 ms.
Här är siffrorna som jag fick för frågan mot dbo. GetNumsItzik ursprungligen:
CPU time = 19969 ms, elapsed time = 21229 ms.
Och här är siffrorna efter ändringen:
CPU time = 19266 ms, elapsed time = 20588 ms.
Prestanda förbättrades bara lite med några procent. Men vänta, det finns mer! Om du behöver bearbeta den beställda datan kan prestandan påverkan vara mycket mer dramatisk, som jag kommer till senare i avsnittet om beställning.
1-baserad kontra @låg-baserad sekvens och motsatta radnummer
Alan, Charlie och Jeff noterade att i de allra flesta av de verkliga fallen där du behöver ett antal siffror behöver du att det börjar med 1, eller ibland 0. Det är mycket mindre vanligt att behöva en annan utgångspunkt. Så det kan vara mer meningsfullt att låta funktionen alltid returnera ett intervall som börjar med t.ex. 1, och när du behöver en annan startpunkt, tillämpa eventuella beräkningar externt i frågan mot funktionen.
Alan kom faktiskt på en elegant idé att låta inline TVF returnera både en kolumn som börjar med 1 (helt enkelt det direkta resultatet av ROW_NUMBER-funktionen) aliaserad som rn och en kolumn som börjar med @low aliased som n. Eftersom funktionen blir inforad, när den yttre frågan interagerar endast med kolumnen rn, utvärderas inte ens kolumnen n, och du får prestandafördelen. När du behöver sekvensen för att börja med @low interagerar du med kolumnen n och betalar den tillämpliga extra kostnaden, så det finns inget behov av att lägga till några explicita externa beräkningar. Alan föreslog till och med att man skulle lägga till en kolumn som heter op som beräknar siffrorna i motsatt ordning och interagerar med den endast när man behöver en sådan sekvens. Kolumnen op är baserad på beräkningen:@high + 1 – rownum. Den här kolumnen har betydelse när du behöver bearbeta raderna i fallande nummerordning som jag visar senare i beställningssektionen.
Så låt oss tillämpa Charlies och Alans förbättringar på mina funktioner.
För batch-lägesversionen, se till att du skapar dummy-tabellen med kolumnarkivets index först, om den inte redan finns:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Använd sedan följande definition för funktionen dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Här är ett exempel på hur du använder funktionen:
SELECT * FROM dbo.GetNumsAlanCharlieItzikBatch(-2, 3) AS F ORDER BY rn;
Denna kod genererar följande utdata:
rn op n --- --- --- 1 3 -2 2 2 -1 3 1 0 4 0 1 5 -1 2 6 -2 3
Testa sedan funktionens prestanda med 100 miljoner rader och returnera först kolumnen n:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Här är prestandastatistiken som jag fick för den här körningen:
CPU time = 16375 ms, elapsed time = 17932 ms.
Som du kan se finns det en liten förbättring jämfört med dbo.GetNumsItzikBatch i både CPU och förfluten tid tack vare den ständiga vikningen som ägde rum här.
Testa funktionen, bara denna gång returnerar kolumnen rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Här är prestandastatistiken som jag fick för den här körningen:
CPU time = 15890 ms, elapsed time = 18561 ms.
CPU-tiden minskade ytterligare, även om förfluten tid tycks ha ökat en aning i denna körning jämfört med när du frågade kolumnen n.
Figur 1 har planerna för båda frågorna.
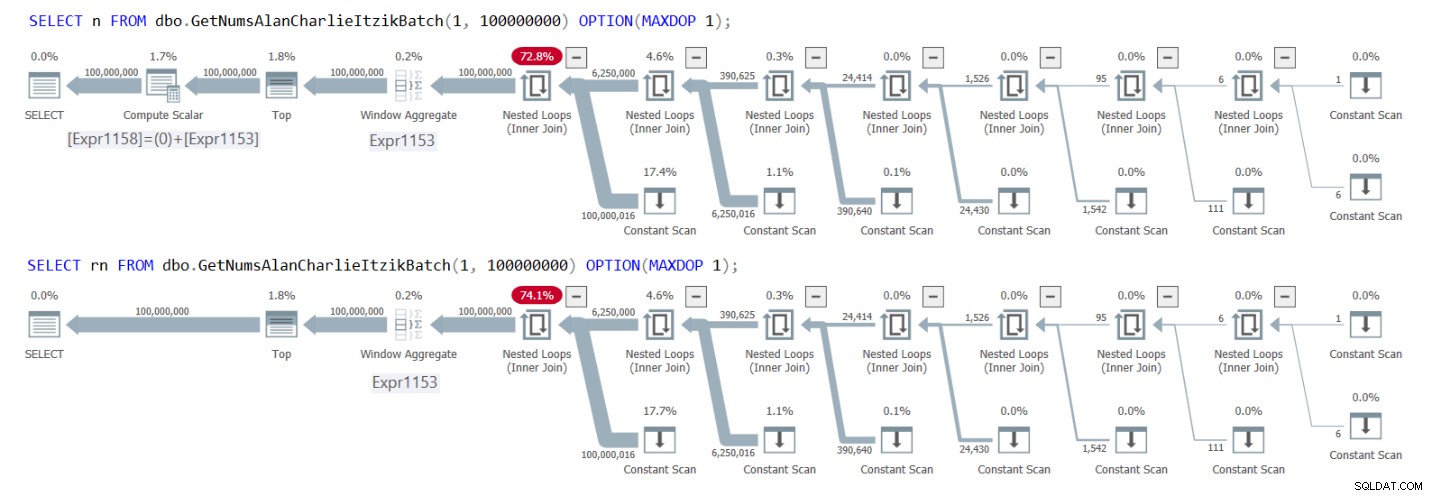 Figur 1:Planer för GetNumsAlanCharlieItzikBatch som returnerar n kontra rn
Figur 1:Planer för GetNumsAlanCharlieItzikBatch som returnerar n kontra rn
Du kan tydligt se i planerna att när du interagerar med kolumnen rn, finns det inget behov av den extra Compute Scalar-operatören. Lägg också märke till i den första planen resultatet av den konstanta vikningsaktiviteten som jag beskrev tidigare, där @låg – 1 + rownum infogades till 1 – 1 + rownum och sedan veks till 0 + rownum.
Här är definitionen av radlägesversionen av funktionen som heter dbo.GetNumsAlanCharlieItzik:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzik(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum; Använd följande kod för att testa funktionen, fråga först kolumnen n:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Här är resultatstatistiken som jag fick:
CPU time = 19047 ms, elapsed time = 20121 ms.
Som du kan se är det lite snabbare än dbo.GetNumsItzik.
Fråga sedan kolumnen rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Prestandasiffrorna förbättras ytterligare på både CPU:n och den förflutna tidsfronten:
CPU time = 17656 ms, elapsed time = 18990 ms.
Beställningsöverväganden
De ovannämnda förbättringarna är verkligen intressanta, och prestandan påverkan är icke försumbar, men inte särskilt betydande. En mycket mer dramatisk och djupgående inverkan på prestanda kan observeras när du behöver bearbeta data sorterad efter nummerkolumnen. Detta kan vara så enkelt som att behöva returnera de beställda raderna, men är lika relevant för alla orderbaserade bearbetningsbehov, t.ex. en Stream Aggregate-operatör för gruppering och aggregering, en Merge Join-algoritm för sammanfogning och så vidare.
När du frågar efter dbo.GetNumsItzikBatch eller dbo.GetNumsItzik och sorterar efter n, inser optimeraren inte att det underliggande ordningsuttrycket @low + rownum – 1 är orderbevarande med avseende på rownum. Innebörden är lite lik den för ett icke-SARG-bart filtreringsuttryck, bara med ett ordnande uttryck resulterar detta i en explicit sorteringsoperator i planen. Den extra sorteringen påverkar svarstiden. Det påverkar även skalningen, som vanligtvis blir n log n istället för n.
För att visa detta, fråga dbo.GetNumsItzikBatch och begär kolumnen n, sorterad efter n:
SELECT n FROM dbo.GetNumsItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Jag fick följande prestationsstatistik:
CPU time = 34125 ms, elapsed time = 39656 ms.
Körtiden mer än fördubblas jämfört med testet utan ORDER BY-satsen.
Testa funktionen dbo.GetNumsItzik på liknande sätt:
SELECT n FROM dbo.GetNumsItzik(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Jag fick följande siffror för detta test:
CPU time = 52391 ms, elapsed time = 55175 ms.
Även här mer än fördubblas körtiden jämfört med testet utan ORDER BY-satsen.
Figur 2 har planerna för båda frågorna.
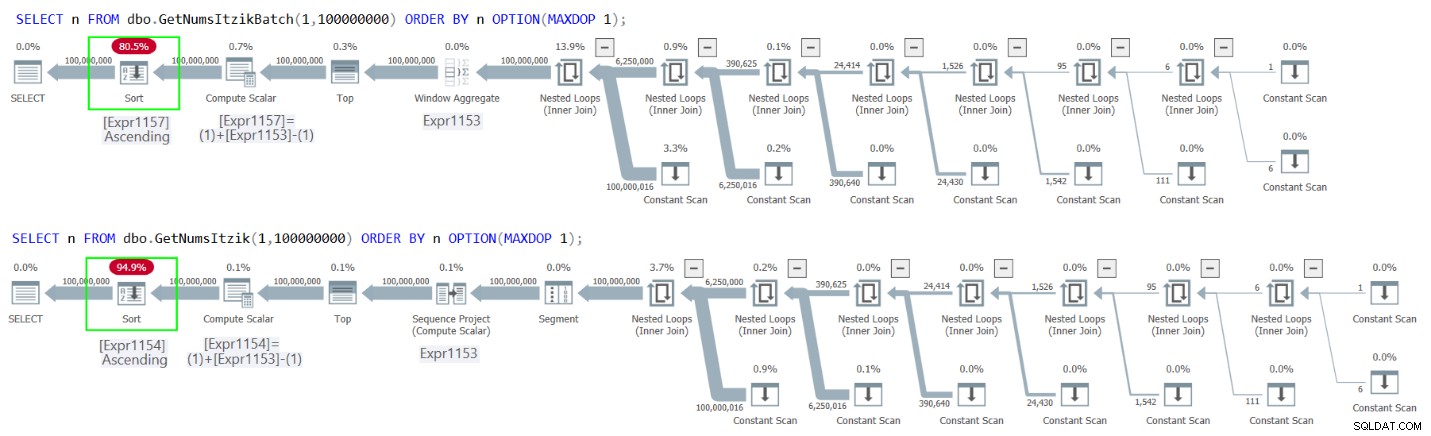 Figur 2:Planer för GetNumsItzikBatch och GetNumsItzik beställning av n
Figur 2:Planer för GetNumsItzikBatch och GetNumsItzik beställning av n
I båda fallen kan du se den explicita sorteringsoperatorn i planerna.
När du frågar efter dbo.GetNumsAlanCharlieItzikBatch eller dbo.GetNumsAlanCharlieItzik och beställer av rn behöver optimeraren inte lägga till en Sorteringsoperator till planen. Så du kan returnera n, men beställ efter rn, och på så sätt undvika en sortering. Det som dock är lite chockerande – och jag menar det på ett bra sätt – är att den reviderade versionen av n som upplever ständig vikning är ordningsbevarande! Det är lätt för optimeraren att inse att 0 + rownum är ett ordningsbevarande uttryck med avseende på rownum och därmed undvika en sortering.
Försök. Fråga dbo.GetNumsAlanCharlieItzikBatch, returnera n och beställa efter antingen n eller rn, som så:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Jag fick följande prestationssiffror:
CPU time = 16500 ms, elapsed time = 17684 ms.
Det är naturligtvis tack vare att det inte behövdes någon sortsoperatör i planen.
Kör ett liknande test mot dbo.GetNumsAlanCharlieItzik:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Jag fick följande nummer:
CPU time = 19546 ms, elapsed time = 20803 ms.
Figur 3 har planerna för båda frågorna:
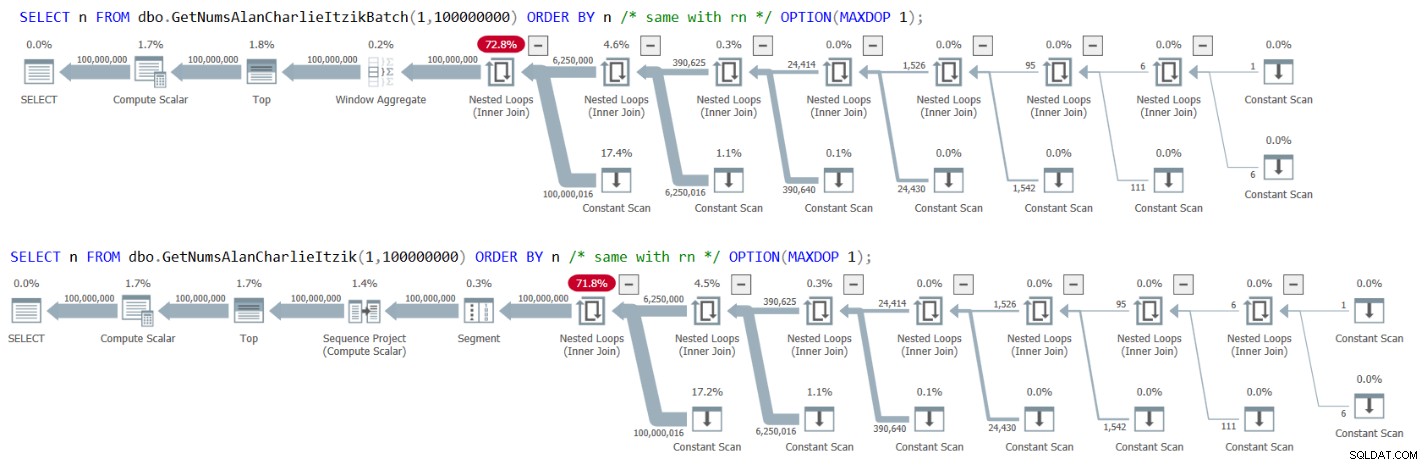
Figur 3:Planer för GetNumsAlanCharlieItzikBatch och Getarlietzik, beställning efter numsAlan eller n.
Observera att det inte finns någon sorteringsoperatör i planerna.
Får dig att vilja sjunga...
All you need is constant folding All you need is constant folding All you need is constant folding, constant folding Constant folding is all you need
Tack Charlie!
Men vad händer om du behöver returnera eller bearbeta siffrorna i fallande ordning? Det uppenbara försöket är att använda ORDER BY n DESC, eller ORDER BY rn DESC, som så:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n DESC OPTION(MAXDOP 1); SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY rn DESC OPTION(MAXDOP 1);
Tyvärr resulterar dock båda fallen i en explicit sortering i planerna, som visas i figur 4.
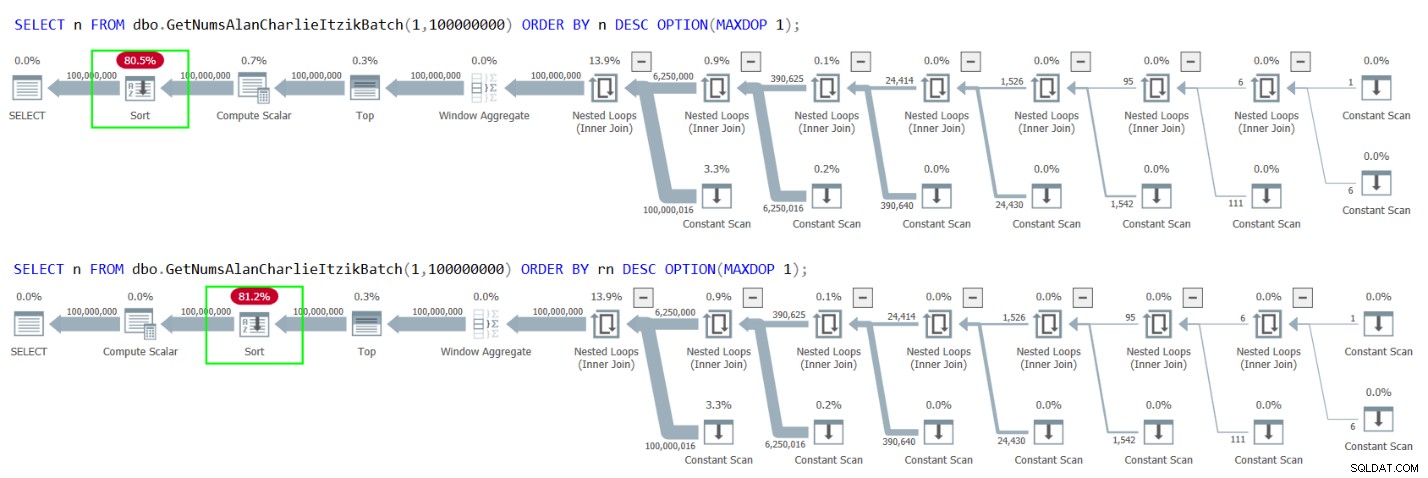 Figur 4:Planer för GetNumsAlanCharlieItzikBatch-beställning genom n eller rn descendingdesn
Figur 4:Planer för GetNumsAlanCharlieItzikBatch-beställning genom n eller rn descendingdesn
Det är här Alans smarta trick med kolumnoperationen blir en livräddare. Returnera kolumnen op medan du beställer med antingen n eller rn, som så:
SELECT op FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Planen för denna fråga visas i figur 5.
 Figur 5:Plan för GetNumsAlanCharlieItzikBatch som returnerar op och beställer som cnding eller em>
Figur 5:Plan för GetNumsAlanCharlieItzikBatch som returnerar op och beställer som cnding eller em>
Du får tillbaka data sorterad efter n fallande och det finns inget behov av en sortering i planen.
Tack Alan!
Prestanda sammanfattning
Så vad har vi lärt oss av allt detta?
Sammanställningstider kan vara en faktor, speciellt när du använder funktionen ofta med små intervall. På en logaritmisk skala med basen 2 verkar söt 16 vara ett trevligt magiskt tal.
Förstå särdragen med konstant vikning och använd dem till din fördel. När en iTVF har uttryck som involverar parametrar, konstanter och kolumner, placera parametrarna och konstanterna i den inledande delen av uttrycket. Detta kommer att öka sannolikheten för vikning, minska CPU-overhead och öka sannolikheten för bevarande av order.
Det är okej att ha flera kolumner som används för olika ändamål i en iTVF, och fråga de relevanta i varje enskilt fall utan att behöva oroa dig för att betala för de som inte hänvisas till.
När du behöver siffersekvensen returnerad i motsatt ordning, använd den ursprungliga n- eller rn-kolumnen i ORDER BY-satsen med stigande ordning, och returnera kolumnen op, som beräknar talen i omvänd ordning.
Figur 6 sammanfattar prestationstalen som jag fick i de olika testerna.
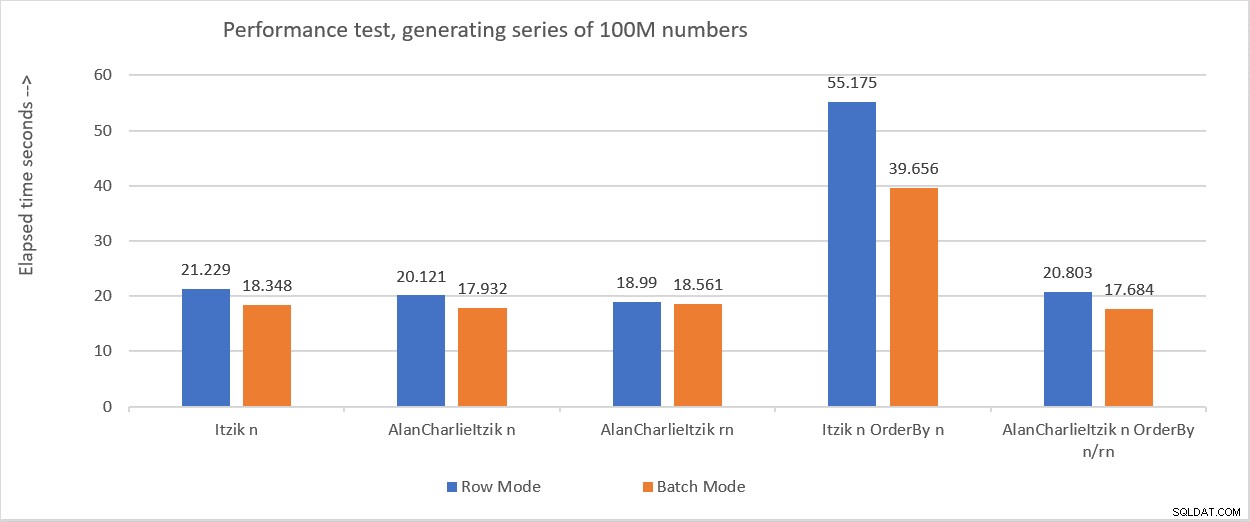 Figur 6:Resultatöversikt
Figur 6:Resultatöversikt
Nästa månad kommer jag att fortsätta utforska ytterligare idéer, insikter och lösningar på nummerseriegeneratorns utmaning.