Vad gör indexering?
Indexering är sättet att få en oordnad tabell i en ordning som kommer att maximera frågans effektivitet under sökning.
När en tabell är oindexerad kommer ordningen på raderna sannolikt inte att urskiljas av frågan som optimerad på något sätt, och din fråga måste därför söka igenom raderna linjärt. Med andra ord måste frågorna söka igenom varje rad för att hitta de rader som matchar villkoren. Som du kan föreställa dig kan detta ta lång tid. Att titta igenom varje enskild rad är inte särskilt effektivt.
Tabellen nedan representerar till exempel en tabell i en fiktiv datakälla, som är helt oordnad.
| företags-id | enhet | enhetskostnad |
|---|---|---|
| 10 | 12 | 1.15 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 16 | 12 | 1.31 |
| 10 | 12 | 1.15 |
| 12 | 24 | 1.3 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1.35 |
| 14 | 12 | 1,95 |
| 21 | 18 | 1.36 |
| 12 | 12 | 1.05 |
| 20 | 6 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 14 | 24 | 1.05 |
Om vi skulle köra följande fråga:
SELECT
company_id,
units,
unit_cost
FROM
index_test
WHERE
company_id = 18
Databasen skulle behöva söka igenom alla 17 rader i den ordning de visas i tabellen, uppifrån och ned, en i taget. Så för att söka efter alla potentiella instanser av company_id nummer 18 måste databasen titta igenom hela tabellen efter alla förekomster av 18 i company_id kolumn.
Detta kommer bara att bli mer och mer tidskrävande när bordets storlek ökar. När datanas förfining ökar, är det som så småningom kan hända att en tabell med en miljard rader sammanfogas med en annan tabell med en miljard rader; frågan måste nu söka igenom dubbelt så många rader som kostar dubbelt så mycket tid.
Du kan se hur detta blir problematiskt i vår ständigt datamättade värld. Tabeller ökar i storlek och sökning ökar i exekveringstid.
Att fråga efter en oindexerad tabell, om den presenteras visuellt, skulle se ut så här:
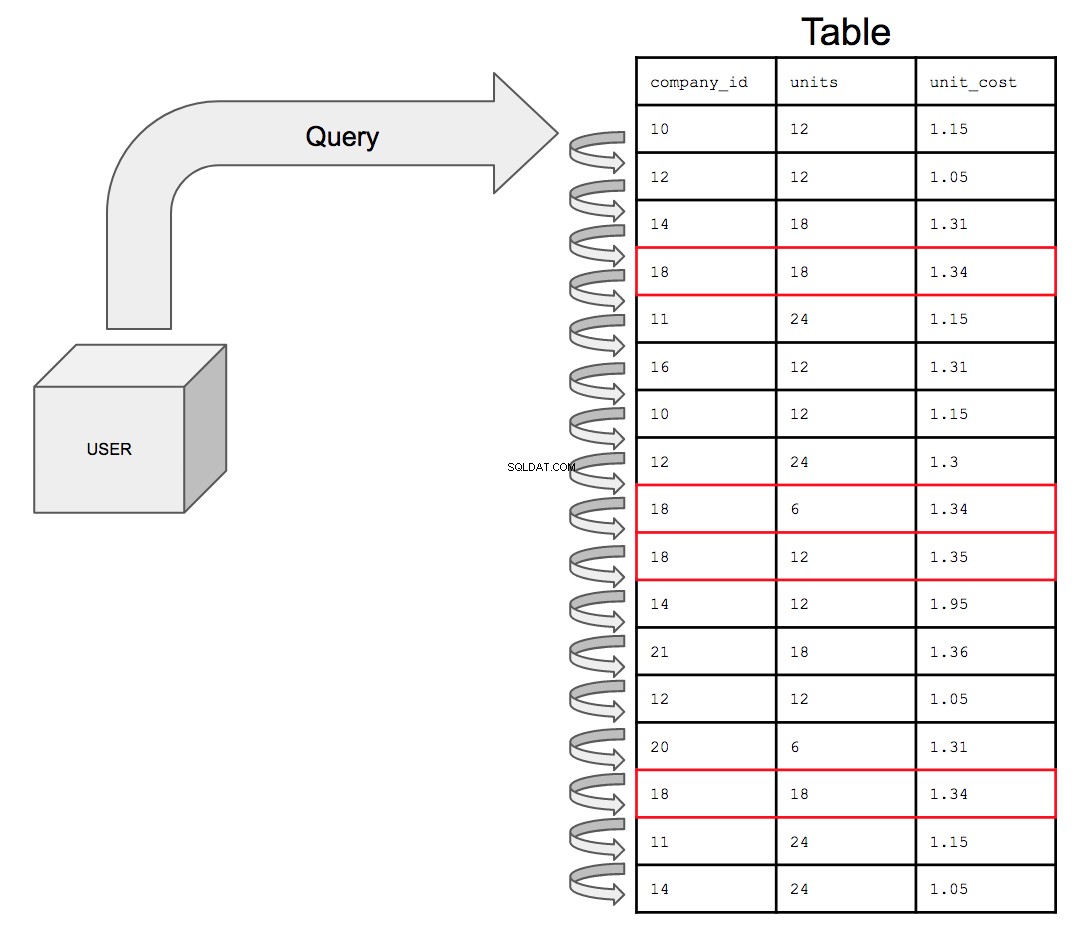
Vad indexering gör är att ställa in den kolumn som du är sökvillkor på i en sorterad ordning för att hjälpa till att optimera frågeprestanda.
Med ett index på company_id kolumn, skulle tabellen i princip "se ut" så här:
| företags-id | enhet | enhetskostnad |
|---|---|---|
| 10 | 12 | 1.15 |
| 10 | 12 | 1.15 |
| 11 | 24 | 1.15 |
| 11 | 24 | 1.15 |
| 12 | 12 | 1.05 |
| 12 | 24 | 1.3 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 14 | 12 | 1,95 |
| 14 | 24 | 1.05 |
| 16 | 12 | 1.31 |
| 18 | 18 | 1.34 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1.35 |
| 18 | 18 | 1.34 |
| 20 | 6 | 1.31 |
| 21 | 18 | 1.36 |
Nu kan databasen söka efter company_id nummer 18 och returnera alla begärda kolumner för den raden och gå sedan vidare till nästa rad. Om nästa rads comapny_id numret är också 18 så kommer det att returnera alla kolumner som efterfrågas i frågan. Om nästa rads company_id är 20, vet sökfrågan att sluta söka och frågan avslutas.
Hur fungerar indexering?
I verkligheten ordnar inte databastabellen sig själv varje gång frågevillkoren ändras för att optimera frågeprestanda:det skulle vara orealistiskt. I själva verket, vad som händer är att indexet får databasen att skapa en datastruktur. Datastrukturtypen är mycket troligt ett B-träd. Även om fördelarna med B-Tree är många, är den största fördelen för våra syften att den är sorterbar. När datastrukturen är sorterad i ordning gör det vår sökning mer effektiv av de uppenbara skälen som vi påpekade ovan.
När indexet skapar en datastruktur på en specifik kolumn är det viktigt att notera att ingen annan kolumn lagras i datastrukturen. Vår datastruktur för tabellen ovan kommer endast att innehålla company_id tal. Enheter och unit_cost kommer inte att finnas i datastrukturen.
Hur vet databasen vilka andra fält i tabellen som ska returneras?
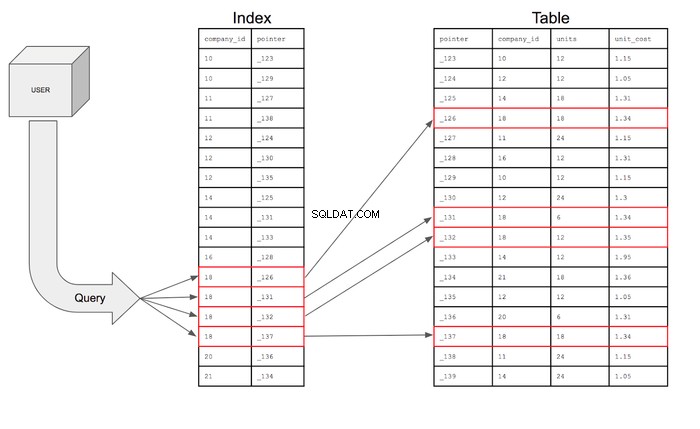
Databasindex kommer också att lagra pekare som helt enkelt är referensinformation för platsen för den ytterligare informationen i minnet. I princip innehåller indexet company_id och just den radens hemadress på minnesdisken. Indexet kommer faktiskt att se ut så här:
| företags-id | pekare |
|---|---|
| 10 | _123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _138 |
| 12 | _124 |
| 12 | _130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _131 |
| 14 | _133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _131 |
| 18 | _132 |
| 18 | _137 |
| 20 | _136 |
| 21 | _134 |
Med det indexet kan frågan endast söka efter raderna i company_id kolumn som har 18 och sedan använda pekaren kan gå in i tabellen för att hitta den specifika raden där pekaren finns. Frågan kan sedan gå in i tabellen för att hämta fälten för de efterfrågade kolumnerna för de rader som uppfyller villkoren.
Om sökningen presenterades visuellt skulle den se ut så här:
Recap
- Indexering lägger till en datastruktur med kolumner för sökvillkoren och en pekare
- Pekaren är adressen på minnesdisken för raden med resten av informationen
- Indexdatastrukturen är sorterad för att optimera frågeeffektiviteten
- Frågan letar efter den specifika raden i indexet; indexet hänvisar till pekaren som hittar resten av informationen.
- Indexet minskar antalet rader som frågan måste söka igenom från 17 till 4.