Spelar dina val av SQL-serverdatatyper och deras storlekar någon roll?
Svaret ligger i resultatet du fick. Har din databas ballong på kort tid? Är dina frågor långsamma? Fick du fel resultat? Vad sägs om körtidsfel under infogning och uppdateringar?
Det är inte så mycket en skrämmande uppgift om du vet vad du gör. Idag kommer du att lära dig de 5 sämsta valen man kan göra med dessa datatyper. Om de har blivit en vana för dig är det här vi borde fixa för din egen och dina användares skull.
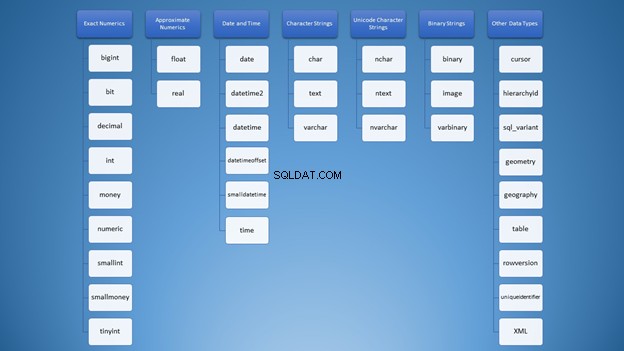
Många datatyper i SQL, massor av förvirring
När jag först lärde mig om SQL Server-datatyper var valen överväldigande. Alla typer är blandade i mitt sinne som detta ordmoln i figur 1:

Men vi kan organisera det i kategorier:
Ändå, för att använda strängar, har du massor av alternativ som kan leda till fel användning. Först tänkte jag att varchar och nvarchar var precis likadana. Dessutom är de båda teckensträngstyper. Att använda siffror är inte annorlunda. Som utvecklare behöver vi veta vilken typ vi ska använda i olika situationer.
Men du kanske undrar, vad är det värsta som kan hända om jag gör fel val? Låt mig berätta!
1. Välja fel SQL-datatyper
Detta objekt kommer att använda strängar och heltal för att bevisa poängen.
Använda fel teckensträng SQL-datatyp
Först, låt oss gå tillbaka till strängar. Det finns en sak som heter Unicode och icke-Unicode-strängar. Båda har olika förvaringsstorlekar. Du definierar ofta detta på kolumner och variabeldeklarationer.
Syntaxen är antingen varchar (n)/röding (n) eller nvarchar (n)/nchar (n) där n är storleken.
Observera att n är inte antalet tecken utan antalet byte. Det är en vanlig missuppfattning som händer eftersom, i varchar , antalet tecken är detsamma som storleken i byte. Men inte i nvarchar .
För att bevisa detta, låt oss skapa två tabeller och lägga in lite data i dem.
CREATE TABLE dbo.VarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString VARCHAR(4000)
)
GO
CREATE TABLE dbo.NVarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString NVARCHAR(4000)
)
GO
INSERT INTO VarcharTable (someString)
VALUES (REPLICATE('x',4000))
GO 1000
INSERT INTO NVarcharTable (someString)
VALUES (REPLICATE(N'y',4000))
GO 1000
Låt oss nu kontrollera deras radstorlekar med DATALENGTH.
SET STATISTICS IO ON
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM VarcharTable
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM NVarcharTable
SET STATISTICS IO OFF
Figur 3 visar att skillnaden är tvåfaldig. Kolla in det nedan.
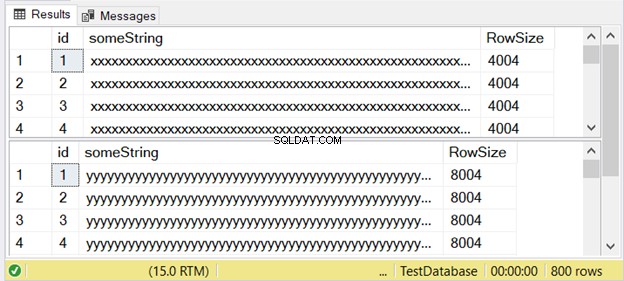
Lägg märke till den andra resultatuppsättningen med en radstorlek på 8004. Detta använder nvarchar data typ. Den är också nästan dubbelt större än radstorleken för den första resultatuppsättningen. Och detta använder varchar datatyp.
Du ser konsekvenserna för lagring och I/O. Figur 4 visar de logiska läsningarna av de två frågorna.
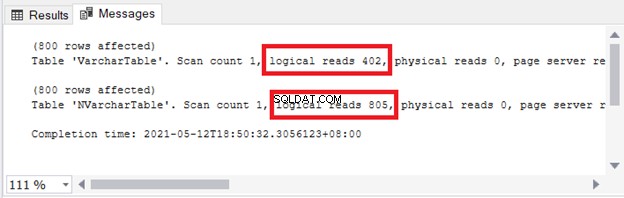
Ser? Logiska läsningar är också tvåfaldiga när du använder nvarchar jämfört med varchar .
Så du kan inte bara använda var och en omväxlande. Om du behöver lagra flerspråkig tecken, använd nvarchar . Annars använder du varchar .
Detta betyder att om du använder nvarchar endast för enbyte-tecken (som engelska) är lagringsstorleken högre . Frågeprestanda är också långsammare med högre logiska läsningar.
I SQL Server 2019 (och senare) kan du lagra hela utbudet av Unicode-teckendata med varchar eller char med något av UTF-8-sorteringsalternativen.
Använda fel numerisk datatyp SQL
Samma koncept gäller med bigint kontra int – deras storlekar kan betyda natt och dag. Som nvarchar och varchar , stor är dubbelt så stor som int (8 byte för bigint och 4 byte för int ).
Ändå är ett annat problem möjligt. Om du inte har något emot deras storlekar kan fel inträffa. Om du använder en int kolumn och lagra ett tal större än 2 147 483 647, kommer ett aritmetiskt spill att inträffa:
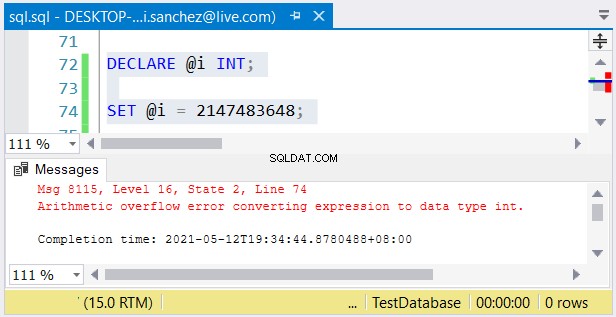
När du väljer heltalstyper se till att data med det maximala värdet passar . Du kanske till exempel designar en tabell med historiska data. Du planerar att använda heltal som det primära nyckelvärdet. Tror du att det inte kommer att nå 2 147 483 647 rader? Använd sedan int istället för stort som primärnyckelkolumntyp.
Det värsta som kan hända
Att välja fel datatyper kan påverka frågeprestanda eller orsaka körtidsfel. Välj alltså den datatyp som är rätt för datan.
2. Skapa stora tabellrader med hjälp av Big Data-typer för SQL
Vår nästa artikel är relaterad till den första, men den kommer att utöka poängen ännu mer med exempel. Det har också något att göra med sidor och stora varchar eller nvarchar kolumner.
Vad är det med sidor och radstorlekar?
Konceptet med sidor i SQL Server kan jämföras med sidorna i en spiral anteckningsbok. Varje sida i en anteckningsbok har samma fysiska storlek. Du skriver ord och ritar bilder på dem. Om en sida inte räcker för en uppsättning stycken och bilder fortsätter du på nästa sida. Ibland river du också en sida och börjar om.
På samma sätt lagras tabelldata, indexposter och bilder i SQL Server på sidor.
En sida har samma storlek på 8 KB. Om en rad med data är mycket stor kommer den inte att passa 8 KB-sidan. En eller flera kolumner kommer att skrivas på en annan sida under allokeringsenheten ROW_OVERFLOW_DATA. Den innehåller en pekare till den ursprungliga raden på sidan under tilldelningsenheten IN_ROW_DATA.
Baserat på detta kan du inte bara passa många kolumner i en tabell under databasdesignen. Det kommer att få konsekvenser för I/O. Dessutom, om du frågar mycket på dessa radöverflödesdata är körningstiden långsammare . Det här kan vara en mardröm.
Ett problem uppstår när du maxar alla kolumner av varierande storlek. Sedan kommer data att överföras till nästa sida under ROW_OVERFLOW_DATA. uppdatera kolumnerna med mindre data, och det måste tas bort från den sidan. Den nya mindre dataraden kommer att skrivas på sidan under IN_ROW_DATA tillsammans med de andra kolumnerna. Föreställ dig vilken I/O som är involverad här.
Exempel på stor rad
Låt oss förbereda vår data först. Vi kommer att använda teckensträngsdatatyper med stora storlekar.
CREATE TABLE [dbo].[LargeTable](
[id] [int] IDENTITY(1,1) NOT NULL,
[SomeString] [varchar](15) NOT NULL,
[LargeString] [nvarchar](3980) NOT NULL,
[AnotherString] [varchar](8000) NULL,
CONSTRAINT [PK_LargeTable] PRIMARY KEY CLUSTERED
(
[id] ASC
))
GO
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',500),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',50))
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',8000))
GO 100
Hämta radstorleken
Låt oss undersöka deras radstorlekar baserat på DATALENGTH.
utifrån de genererade uppgifternaSELECT *, DATALENGTH(id)
+ DATALENGTH(SomeString)
+ DATALENGTH(LargeString)
+ DATALENGTH(ISNULL(AnotherString,0)) AS RowSize
FROM LargeTable
De första 300 posterna kommer att passa IN_ROW_DATA-sidorna eftersom varje rad har mindre än 8060 byte eller 8 KB. Men de sista 100 raderna är för stora. Kolla in resultatuppsättningen i figur 6.
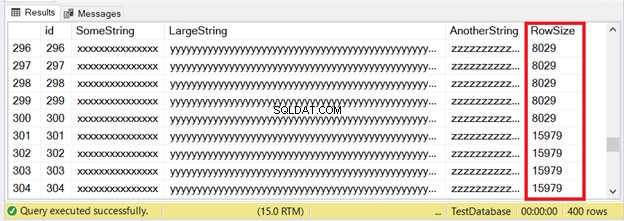
Du ser en del av de första 300 raderna. De nästa 100 överskrider gränsen för sidstorlek. Hur vet vi att de senaste 100 raderna finns i tilldelningsenheten ROW_OVERFLOW_DATA?
Inspekterar ROW_OVERFLOW_DATA
Vi använder sys.dm_db_index_physical_stats . Den returnerar sidinformation om tabell- och indexposter.
SELECT
ps.index_id
,[Index] = i.[name]
,ps.index_type_desc
,ps.alloc_unit_type_desc
,ps.index_depth
,ps.index_level
,ps.page_count
,ps.record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),
OBJECT_ID('dbo.LargeTable'), NULL, NULL, 'DETAILED') AS ps
INNER JOIN sys.indexes AS i ON ps.index_id = i.index_id
AND ps.object_id = i.object_id;
Resultatuppsättningen finns i figur 7.

Där är det. Figur 7 visar 100 rader under ROW_OVERFLOW_DATA. Detta överensstämmer med figur 6 när det finns stora rader som börjar med raderna 301 till 400.
Nästa fråga är hur många logiska läsningar vi får när vi frågar dessa 100 rader. Låt oss försöka.
SELECT * FROM LargeTable
WHERE id BETWEEN 301 AND 400
ORDER BY AnotherString DESC

Vi ser 102 logiska läsningar och 100 loblogiska läsningar av LargeTable . Lämna dessa siffror tills vidare – vi jämför dem senare.
Nu ska vi se vad som händer om vi uppdaterar de 100 raderna med mindre data.
UPDATE LargeTable
SET AnotherString = 'updated',LargeString='updated'
WHERE id BETWEEN 301 AND 400
Denna uppdateringssats använde samma logiska läsningar och loblogiska läsningar som i figur 8. Av detta vet vi att något större hände på grund av loblogiska läsningar på 100 sidor.
Men för att vara säker, låt oss kontrollera det med sys.dm_db_index_physical_stats som vi gjorde tidigare. Figur 9 visar resultatet:

Borta! Sidor och rader från ROW_OVERFLOW_DATA blev noll efter uppdatering av 100 rader med mindre data. Nu vet vi att datarörelsen från ROW_OVERFLOW_DATA till IN_ROW_DATA sker när stora rader krymps. Tänk om detta händer mycket för tusentals eller till och med miljontals poster. Galet, eller hur?
I figur 8 såg vi 100 logiska avläsningar. Se nu figur 10 efter att ha kört frågan igen:

Det blev noll!
Det värsta som kan hända
Långsam frågeprestanda är biprodukten av radöverflödesdata. Överväg att flytta de stora kolumnerna till en annan tabell för att undvika det. Eller, om tillämpligt, minska storleken på varchar eller nvarchar kolumn.
3. Blint använder implicit konvertering
SQL tillåter oss inte att använda data utan att ange typen. Men det är förlåtande om vi gör ett fel val. Den försöker konvertera värdet till den typ den förväntar sig, men med en straffavgift. Detta kan hända i en WHERE-sats eller JOIN.
USE AdventureWorks2017
GO
SET STATISTICS IO ON
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = 77775294979396 -- this will trigger an implicit conversion
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = '77775294979396'
SET STATISTICS IO OFF
Kortnummer kolumn är inte en numerisk typ. Det är nvarchar . Så den första SELECT kommer att orsaka en implicit konvertering. Båda fungerar dock bra och ger samma resultatuppsättning.
Låt oss kontrollera utförandeplanen i figur 11.
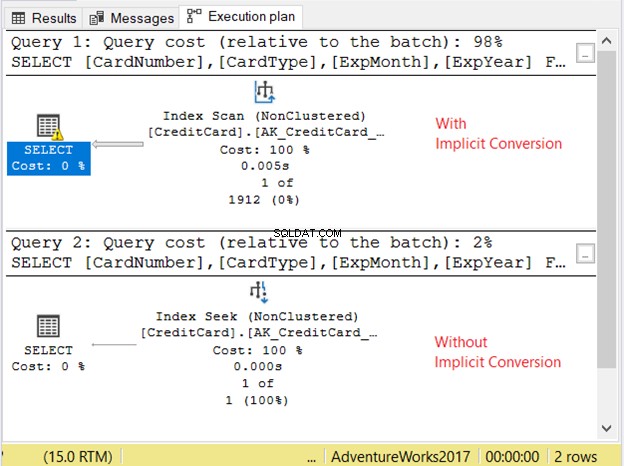
De två frågorna gick väldigt snabbt. I figur 11 är det noll sekunder. Men titta på de 2 planerna. Den med implicit konvertering hade en indexskanning. Det finns också en varningsikon och en fet pil som pekar på SELECT-operatören. Det säger oss att det är dåligt.
Men det slutar inte där. Om du håller musen över SELECT-operatorn ser du något annat:

Varningsikonen i SELECT-operatorn handlar om den implicita konverteringen. Men hur stor är effekten? Låt oss kontrollera de logiska läsningarna.
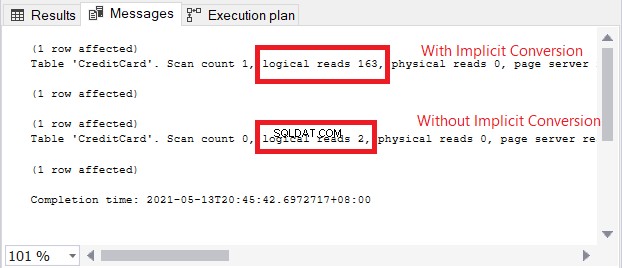
Jämförelsen av logiska läsningar i figur 13 är som himmel och jord. I frågan om kreditkortsinformation orsakade implicit konvertering mer än hundra gånger logiska läsningar. Mycket dåligt!
Det värsta som kan hända
Om en implicit konvertering orsakade höga logiska läsningar och en dålig plan, förvänta dig långsam frågeprestanda på stora resultatuppsättningar. För att undvika detta, använd den exakta datatypen i WHERE-satsen och JOINs för att matcha kolumnerna du jämför.
4. Använda ungefärliga siffror och avrunda den
Kolla in figur 2 igen. SQL-serverdatatyper som tillhör ungefärliga siffror är flytande och riktigt . Kolumner och variabler gjorda av dem lagrar en nära approximation av ett numeriskt värde. Om du planerar att avrunda dessa siffror uppåt eller nedåt kan du få en stor överraskning. Jag har en artikel som diskuterade detta i detalj här. Se hur 1 + 1 resulterar i 3 och hur du kan hantera avrundningstal.
Det värsta som kan hända
Avrunda en flottör eller riktigt kan få galna resultat. Om du vill ha exakta värden efter avrundning, använd decimal eller numerisk istället.
5. Ställa in strängdatatyper med fast storlek till NULL
Låt oss rikta uppmärksamheten mot datatyper med fast storlek som char och nchar . Bortsett från de vadderade utrymmena kommer om du ställer in dem på NULL fortfarande ha en lagringsstorlek som är lika med storleken på char kolumn. Så ställ in ett tecken (500) kolumn till NULL kommer att ha storleken 500, inte noll eller 1.
CREATE TABLE dbo.CharNullSample
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
col1 CHAR(500) NULL,
col2 CHAR(200) NULL,
col3 CHAR(350) NULL,
col4 VARCHAR(500) NULL,
col5 VARCHAR(200) NULL,
col6 VARCHAR(350) NULL
)
GO
INSERT INTO CharNullSample (col1, col2, col3, col4, col5, col6)
VALUES (REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350), REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350));
GO 200
I koden ovan maximeras data baserat på storleken på char och varchar kolumner. Om du kontrollerar deras radstorlek med DATALENGTH visas också summan av storlekarna för varje kolumn. Låt oss nu ställa in kolumnerna till NULL.
UPDATE CharNullSample
SET col1 = NULL, col2=NULL, col3=NULL, col4=NULL, col5=NULL, col6=NULL
Därefter frågar vi raderna med DATALENGTH:
SELECT
DATALENGTH(ISNULL(col1,0)) AS Col1Size
,DATALENGTH(ISNULL(col2,0)) AS Col2Size
,DATALENGTH(ISNULL(col3,0)) AS Col3Size
,DATALENGTH(ISNULL(col4,0)) AS Col4Size
,DATALENGTH(ISNULL(col5,0)) AS Col5Size
,DATALENGTH(ISNULL(col6,0)) AS Col6Size
FROM CharNullSample
Vad tror du blir datastorlekarna för varje kolumn? Kolla in figur 14.
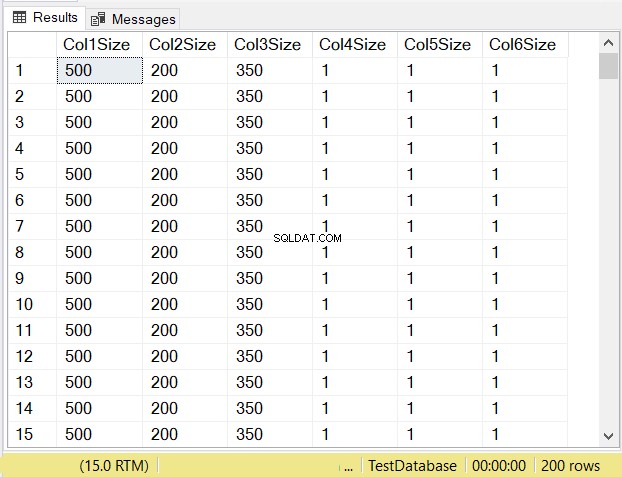
Titta på kolumnstorlekarna för de tre första kolumnerna. Jämför dem sedan med koden ovan när tabellen skapades. Datastorleken för NULL-kolumnerna är lika med storleken på kolumnen. Under tiden, varchar kolumner när NULL har en datastorlek på 1.
Det värsta som kan hända
Under design av tabeller, nullbar char kolumner, när de är inställda på NULL, kommer fortfarande att ha samma lagringsstorlek. De kommer också att förbruka samma sidor och RAM. Om du inte fyller hela kolumnen med tecken, överväg att använda varchar istället.
Vad är härnäst?
Så, spelar dina val i SQL-serverdatatyper och deras storlekar någon roll? De punkter som presenteras här borde räcka för att göra en poäng. Så vad kan du göra nu?
- Ta av tid att granska databasen som du stöder. Börja med den enklaste om du har flera på tallriken. Och ja, ta tid, inte hitta tid. I vår bransch är det nästan omöjligt att hitta tid.
- Granska tabeller, lagrade procedurer och allt som handlar om datatyper. Observera den positiva effekten när du identifierar problem. Du kommer att behöva det när din chef frågar varför du måste arbeta med det här.
- Planera att attackera vart och ett av problemområdena. Följ de metoder eller policyer som ditt företag har för att hantera problemen.
- När problemen är borta, fira.
Låter lätt, men vi vet alla att det inte är det. Vi vet också att det finns en ljus sida i slutet av resan. Det är därför de kallas problem – för det finns en lösning. Så, muntra upp dig.
Har du något mer att tillägga om detta ämne? Låt oss veta i kommentarsektionen. Och om det här inlägget gav dig en bra idé, dela det på dina favoritplattformar för sociala medier.