Redan 2012 skrev jag ett blogginlägg här som lyfte fram metoder för att beräkna en median. I det inlägget tog jag upp det mycket enkla fallet:vi ville hitta medianen för en kolumn över en hel tabell. Det har nämnts för mig flera gånger sedan dess att ett mer praktiskt krav är att beräkna en partitionerad median . Liksom med det grundläggande fallet finns det flera sätt att lösa detta i olika versioner av SQL Server; inte överraskande, vissa presterar mycket bättre än andra.
I det föregående exemplet hade vi bara generiska kolumner id och val. Låt oss göra detta mer realistiskt och säga att vi har säljare och antalet försäljningar de har gjort under en period. För att testa våra frågor, låt oss först skapa en enkel hög med 17 rader och verifiera att de alla ger de resultat vi förväntar oss (SalesPerson 1 har en median på 7,5 och SalesPerson 2 har en median på 6,0):
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) VALUES (1, 6 ),(1, 11),(1, 4 ),(1, 4 ), (1, 15),(1, 14),(1, 4 ),(1, 9 ), (2, 6 ),(2, 11),(2, 4 ),(2, 4 ), (2, 15),(2, 14),(2, 4 );
Här är frågorna, som vi ska testa (med mycket mer data!) mot högen ovan, såväl som med stödjande index. Jag har kasserat ett par frågor från det tidigare testet, som antingen inte skalade alls eller inte mappade särskilt bra till partitionerade medianer (nämligen 2000_B, som använde en #temp-tabell, och 2005_A, som använde motsatt rad tal). Jag har dock lagt till några intressanta idéer från en ny artikel av Dwain Camps (@DwainCSQL), som bygger på mitt tidigare inlägg.
SQL Server 2000+
Den enda metoden från det tidigare tillvägagångssättet som fungerade tillräckligt bra på SQL Server 2000 för att ens inkludera den i det här testet var metoden "min av ena halvan, max av den andra":
SELECT DISTINCT s.SalesPerson, Median = (
(SELECT MAX(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount) AS t)
+ (SELECT MIN(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount DESC) AS b)
) / 2.0
FROM dbo.Sales AS s; Jag försökte ärligt talat efterlikna #temp table-versionen som jag använde i det enklare exemplet, men den skalade inte bra alls. Vid 20 eller 200 rader fungerade det bra; vid 2000 tog det nästan en minut; vid 1 000 000 gav jag upp efter en timme. Jag har tagit med det här för eftervärlden (klicka för att avslöja).
CREATE TABLE #x
(
i INT IDENTITY(1,1),
SalesPerson INT,
Amount INT,
i2 INT
);
CREATE CLUSTERED INDEX v ON #x(SalesPerson, Amount);
INSERT #x(SalesPerson, Amount)
SELECT SalesPerson, Amount
FROM dbo.Sales
ORDER BY SalesPerson,Amount OPTION (MAXDOP 1);
UPDATE x SET i2 = i-
(
SELECT COUNT(*) FROM #x WHERE i <= x.i
AND SalesPerson < x.SalesPerson
)
FROM #x AS x;
SELECT SalesPerson, Median = AVG(0. + Amount)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE SalesPerson = x.SalesPerson
AND x.i2 - (SELECT MAX(i2) / 2.0 FROM #x WHERE SalesPerson = x.SalesPerson)
IN (0, 0.5, 1)
)
GROUP BY SalesPerson;
GO
DROP TABLE #x; SQL Server 2005+ 1
Detta använder två olika fönsterfunktioner för att härleda en sekvens och totalt antal belopp per säljare.
SELECT SalesPerson, Median = AVG(1.0*Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount),
c = COUNT(*) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; SQL Server 2005+ 2
Detta kom från Dwain Camps artikel, som gör samma sak som ovan, på ett lite mer genomarbetat sätt. Detta tar i princip upp de intressanta raderna i varje grupp.
;WITH Counts AS
(
SELECT SalesPerson, c
FROM
(
SELECT SalesPerson, c1 = (c+1)/2,
c2 = CASE c%2 WHEN 0 THEN 1+c/2 ELSE 0 END
FROM
(
SELECT SalesPerson, c=COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
) a
) a
CROSS APPLY (VALUES(c1),(c2)) b(c)
)
SELECT a.SalesPerson, Median=AVG(0.+b.Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount)
FROM dbo.Sales a
) a
CROSS APPLY
(
SELECT Amount FROM Counts b
WHERE a.SalesPerson = b.SalesPerson AND a.rn = b.c
) b
GROUP BY a.SalesPerson; SQL Server 2005+ 3
Detta baserades på ett förslag från Adam Machanic i kommentarerna till mitt tidigare inlägg, och även förstärkt av Dwain i hans artikel ovan.
;WITH Counts AS
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
)
SELECT a.SalesPerson, Median = AVG(0.+Amount)
FROM Counts a
CROSS APPLY
(
SELECT TOP (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
b.Amount, r = ROW_NUMBER() OVER (ORDER BY b.Amount)
FROM dbo.Sales b
WHERE a.SalesPerson = b.SalesPerson
ORDER BY b.Amount
) p
WHERE r BETWEEN ((a.c - 1) / 2) + 1 AND (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
GROUP BY a.SalesPerson; SQL Server 2005+ 4
Detta liknar "2005+ 1" ovan, men istället för att använda COUNT(*) OVER() för att härleda räkningarna utför den en självkoppling mot ett isolerat aggregat i en härledd tabell.
SELECT SalesPerson, Median = AVG(1.0 * Amount)
FROM
(
SELECT s.SalesPerson, s.Amount, rn = ROW_NUMBER() OVER
(PARTITION BY s.SalesPerson ORDER BY s.Amount), c.c
FROM dbo.Sales AS s
INNER JOIN
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales GROUP BY SalesPerson
) AS c
ON s.SalesPerson = c.SalesPerson
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; SQL Server 2012+ 1
Detta var ett mycket intressant bidrag från andra SQL Server MVP Peter "Peso" Larsson (@SwePeso) i kommentarerna till Dwains artikel; den använder CROSS APPLY och den nya OFFSET / FETCH funktionalitet på ett ännu mer intressant och överraskande sätt än Itziks lösning på den enklare medianberäkningen.
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median); SQL Server 2012+ 2
Slutligen har vi den nya PERCENTILE_CONT() funktion introducerad i SQL Server 2012.
SELECT SalesPerson, Median = MAX(Median)
FROM
(
SELECT SalesPerson,Median = PERCENTILE_CONT(0.5) WITHIN GROUP
(ORDER BY Amount) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
GROUP BY SalesPerson; De riktiga testerna
För att testa prestandan för ovanstående frågor kommer vi att bygga en mycket mer omfattande tabell. Vi kommer att ha 100 unika säljare, med 10 000 försäljningsbelopp vardera, för totalt 1 000 000 rader. Vi kommer också att köra varje fråga mot högen som den är, med ett tillagt icke-klustrat index på (SalesPerson, Amount) , och med ett klustrat index på samma kolumner. Här är inställningen:
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO --CREATE CLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --CREATE NONCLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --DROP INDEX x ON dbo.sales; ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3;
Och här är resultaten av ovanstående frågor, mot högen, det icke-klustrade indexet och det klustrade indexet:
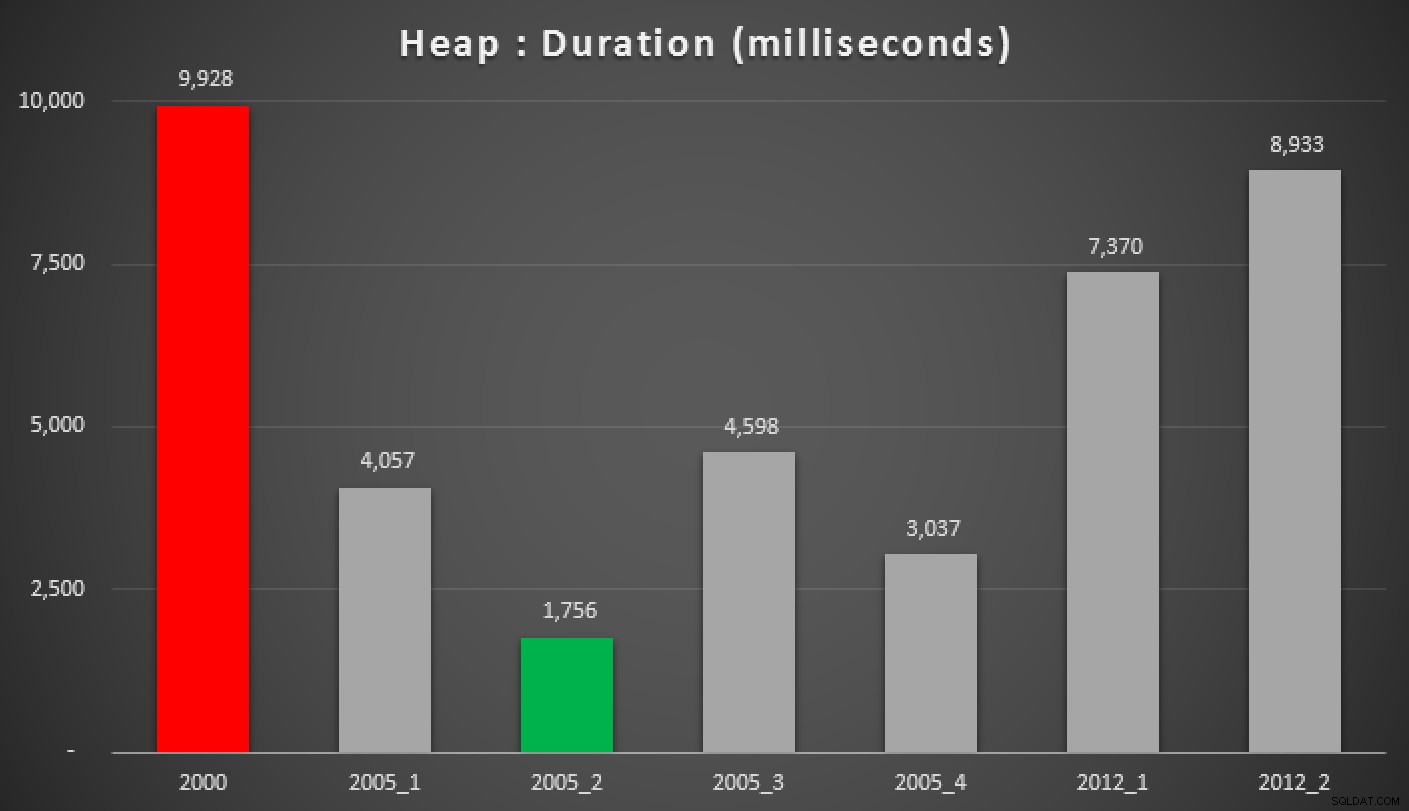
Varaktighet, i millisekunder, för olika grupperade medianmetoder (mot en hög)
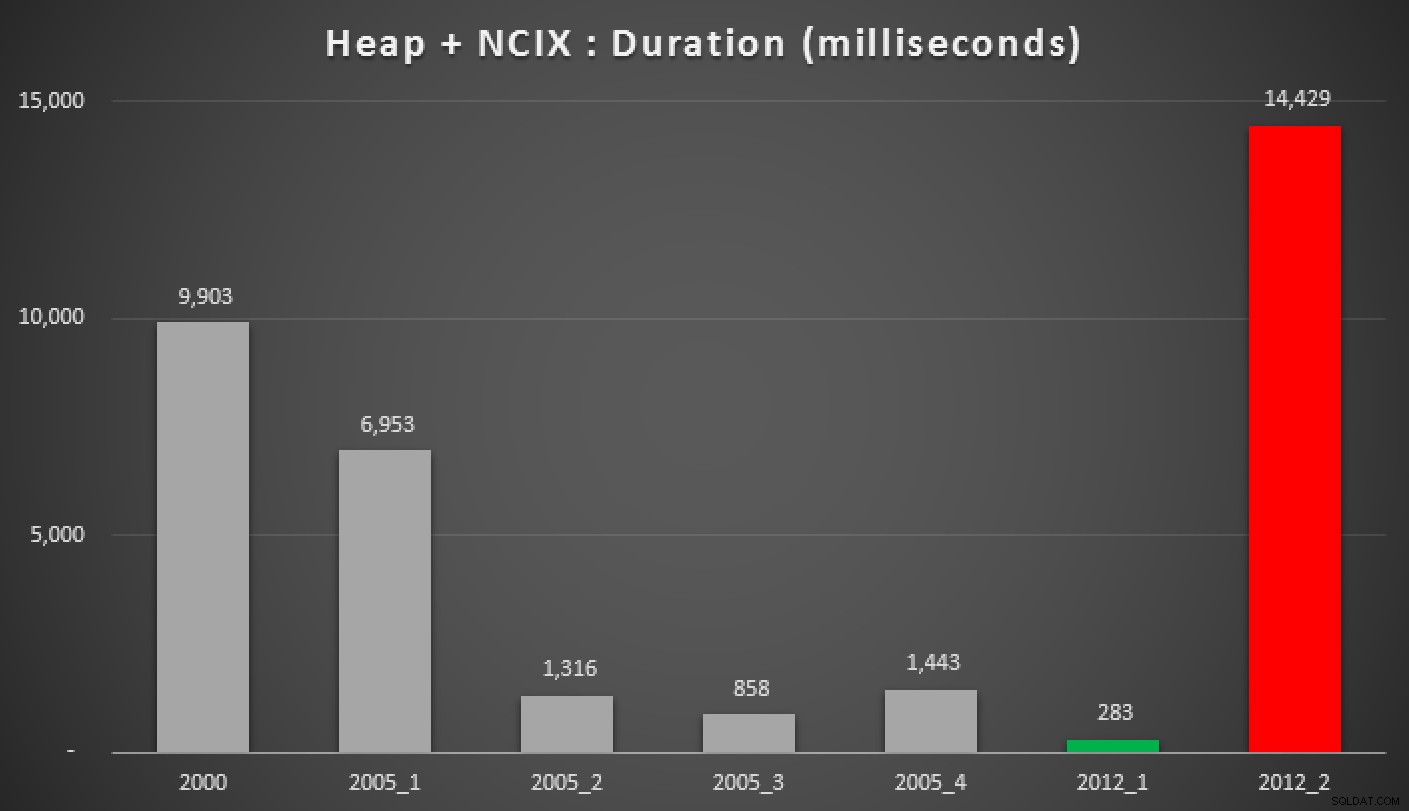
Varaktighet, i millisekunder, för olika grupperade medianmetoder (mot en hög med ett icke-klustrat index)
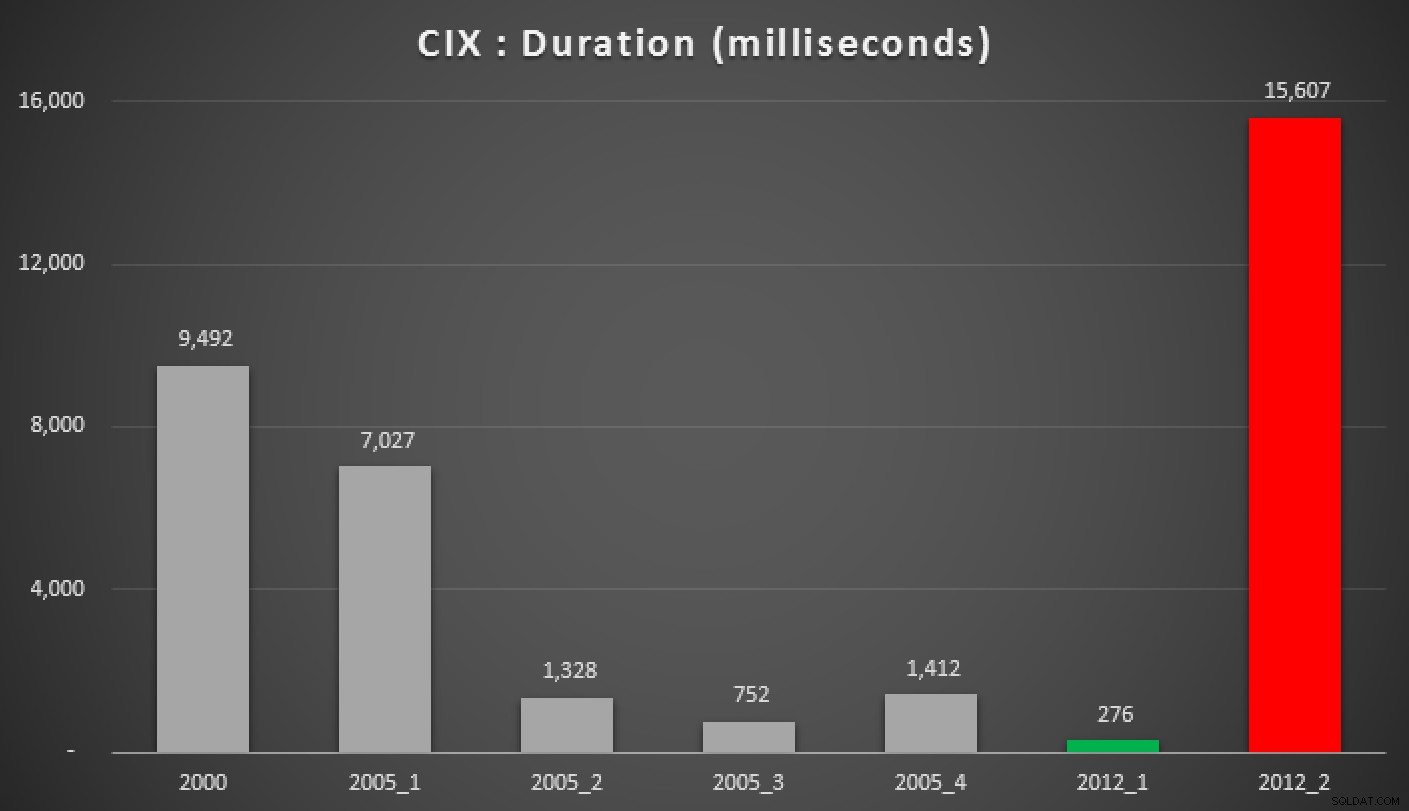
Varaktighet, i millisekunder, för olika grupperade medianmetoder (mot en klustrade index)
Hur är det med Hekaton?
Naturligtvis var jag nyfiken på om den här nya funktionen i SQL Server 2014 kunde hjälpa till med någon av dessa frågor. Så jag skapade en In-Memory-databas, två In-Memory-versioner av försäljningstabellen (en med ett hashindex på (SalesPerson, Amount) , och den andra på bara (SalesPerson) ), och körde samma test igen:
CREATE DATABASE Hekaton; GO ALTER DATABASE Hekaton ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE Hekaton ADD FILE (name = 'xtp', filename = 'c:\temp\hek.mod') TO FILEGROUP xtp; GO ALTER DATABASE Hekaton SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT ON; GO USE Hekaton; GO CREATE TABLE dbo.Sales1 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson, Amount) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO CREATE TABLE dbo.Sales2 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales1 (SalesPerson, Amount) -- TABLOCK/TABLOCKX not allowed here SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3; INSERT dbo.Sales2 (SalesPerson, Amount) SELECT SalesPerson, Amount FROM dbo.Sales1;
Resultaten:
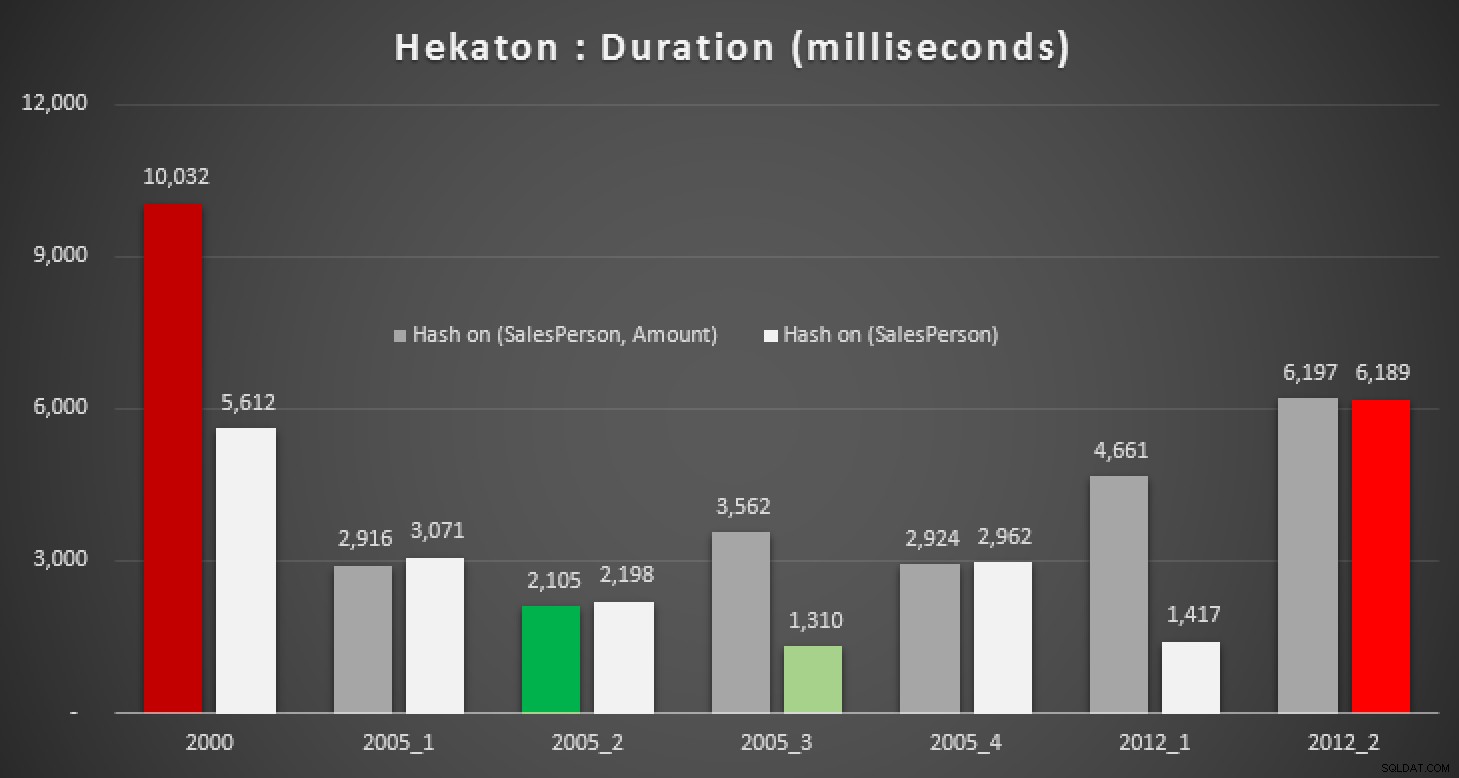
Längd, i millisekunder, för olika medianberäkningar mot In-Memory tabeller
Även med rätt hashindex ser vi inte riktigt några betydande förbättringar jämfört med en traditionell tabell. Dessutom kommer det inte att bli en lätt uppgift att försöka lösa medianproblemet med en inbyggt kompilerad lagrad procedur, eftersom många av språkkonstruktionerna som används ovan inte är giltiga (jag blev också förvånad över några av dessa). Att försöka kompilera alla ovanstående frågevarianter gav denna parad av fel; vissa inträffade flera gånger inom varje procedur, och även efter att du tagit bort dubbletter är detta fortfarande lite komiskt:
Msg 10794, Level 16, State 47, Procedure GroupedMedian_2000Alternativet 'DISTINCT' stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2000queries ( frågor kapslade i en annan fråga) stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 10794, Level 16, State 48, Procedure GroupedMedian_2000
Alternativet 'PERCENT' stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2005_1
Subqueries (frågor kapslade inuti en annan fråga) stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 10794, Level 16, State 9 , Procedur GroupedMedian_2005_1
Aggregeringsfunktionen 'ROW_NUMBER' stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 10794, Level 16, State 56, Procedure GroupedMedian_2005_1
Operatorn 'IN' stöds inte inbyggt kompilerade lagrade procedurer.
Msg 12310, Nivå 16, State 36, Procedure GroupedMedian_2005_2
Common Table Expressions (CTE) stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 12309, Level 16, State 35, Procedure GroupedMedian_2005_2
INSERT…VÄRDEN… som infogar flera rader stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 10794, Level 16, State 53, Procedure GroupedMedian_2005_2
Operatorn 'APPLY' stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2005_2
Subqueries (frågor kapslade inuti en annan fråga) stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 10794, Level 16, Procedure State 91 GroupedMedian_2005_2
Aggregeringsfunktionen 'ROW_NUMBER' stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 12310, Level 16, State 36, Procedure GroupedMedian_2005_3
Common Table Expressions (CTE) är vanliga tabelluttryck (CTE) stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2005_3
Subqueries (frågor kapslade inuti en annan fråga) stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 10794, Level 16, State , Procedur GroupedMedian_2005_3
Aggregeringsfunktionen 'ROW_NUMBER' stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 10794, Level 16, State 53, Procedure GroupedMedian_2005_3
Operatorn 'APPLY' stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2005_4
Subqueries (frågor kapslade i en annan fråga) stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 10794, Level 16, State 91, Procedure GroupedMedian_2005_4
Aggregeringsfunktionen 'ROW_NUMBER' stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 10794, Level 16, State 56, Procedure GroupedMedian operator /5_
5__420 'IN' stöds inte med inbyggt kompilerad stor ed procedurer.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2012_1
Subqueries (frågor kapslade inuti en annan fråga) stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 10794, Nivå 16, State 38, Procedure GroupedMedian_2012_1
Operatorn 'OFFSET' stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 10794, Level 16, State 53, Procedure GroupedMedian_2012_1
Operatorn 'APPLY stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2012_2
Subqueries (frågor kapslade inuti en annan fråga) stöds inte med inbyggt kompilerade lagrade procedurer.
Msg 10794, Level 16, State 90, Procedure GroupedMedian_2012_2
Aggregeringsfunktionen 'PERCENTILE_CONT' stöds inte med inbyggt kompilerade lagrade procedurer.
Som skrivet för närvarande kunde inte en av dessa frågor portas till en inbyggt kompilerad lagrad procedur. Kanske något att titta på för ett annat uppföljande inlägg.
Slutsats
Kasta Hekaton-resultaten och när ett stödjande index finns, Peter Larssons fråga ("2012+ 1") med OFFSET/FETCH kom ut som den överlägsna vinnaren i dessa tester. Även om den var lite mer komplex än motsvarande fråga i de icke-partitionerade testen, matchade den resultaten jag såg förra gången.
I samma fall, 2000 MIN/MAX tillvägagångssätt och 2012 års PERCENTILE_CONT() kom ut som riktiga hundar; igen, precis som mina tidigare tester mot det enklare fallet.
Om du inte är på SQL Server 2012 än, är ditt näst bästa alternativ "2005+ 3" (om du har ett stödjande index) eller "2005+ 2" om du har att göra med en hög. Ledsen att jag var tvungen att komma på ett nytt namnschema för dessa, mest för att undvika förvirring med metoderna i mitt tidigare inlägg.
Naturligtvis är detta mina resultat mot ett mycket specifikt schema och datauppsättning – som med alla rekommendationer bör du testa dessa metoder mot ditt schema och data, eftersom andra faktorer kan påverka olika resultat.
En annan anmärkning
Förutom att vara en dålig presterande och inte stöds i inbyggt kompilerade lagrade procedurer, en annan smärtpunkt av PERCENTILE_CONT() är att den inte kan användas i äldre kompatibilitetslägen. Om du försöker får du detta felmeddelande:
PERCENTILE_CONT-funktionen är inte tillåten i det aktuella kompatibilitetsläget. Det är endast tillåtet i 110-läge eller högre.