Förra året postade jag ett tips som heter Förbättra SQL Server Efficiency genom att byta till I STÄLLET FÖR Triggers.
Den stora anledningen till att jag tenderar att gynna en ISTÄLLET FÖR trigger, särskilt i fall där jag förväntar mig många affärslogiköverträdelser, är att det verkar intuitivt att det skulle vara billigare att förhindra en åtgärd helt och hållet än att gå vidare och utföra den (och logga det!), bara för att använda en EFTER-utlösare för att ta bort de felande raderna (eller rulla tillbaka hela operationen). Resultaten som visades i det tipset visade att så var fallet – och jag misstänker att de skulle bli ännu mer uttalade med fler icke-klustrade index som påverkas av operationen.
Det var dock på en långsam disk och på en tidig CTP av SQL Server 2014. När jag förberedde en bild för en ny presentation som jag kommer att göra i år på triggers, fann jag att på en nyare version av SQL Server 2014 – kombinerat med uppdaterad hårdvara – det var lite knepigare att demonstrera samma delta i prestanda mellan en EFTER- och INSTEAD OF-trigger. Så jag gav mig i kast med att upptäcka varför, även om jag omedelbart visste att det här skulle bli mer jobb än jag någonsin har gjort för en enda bild.
En sak jag vill nämna är att triggers kan använda tempdb på olika sätt, och detta kan förklara några av dessa skillnader. En AFTER-trigger använder versionslagret för de infogade och raderade pseudotabellerna, medan en INSTEAD OF-trigger gör en kopia av dessa data i en intern arbetstabell. Skillnaden är subtil, men värd att påpeka.
Variablerna
Jag ska testa olika scenarier, inklusive:
- Tre olika utlösare:
- En AFTER-utlösare som tar bort specifika rader som misslyckas
- En AFTER-utlösare som rullar tillbaka hela transaktionen om någon rad misslyckas
- En utlösare I STÄLLET FÖR som bara infogar de rader som passerar
- Olika återställningsmodeller och inställningar för ögonblicksbildsisolering:
- FULL med SNAPSHOT aktiverat
- FULL med SNAPSHOT inaktiverat
- ENKEL med SNAPSHOT aktiverat
- ENKEL med SNAPSHOT inaktiverat
- Olika disklayouter*:
- Data på SSD, logga in på 7200 RPM HDD
- Data på SSD, logga in på SSD
- Data på 7200 RPM HDD, logga på SSD
- Data på 7200 RPM HDD, logga in 7200 RPM HDD
- Olika felfrekvenser:
- 10 %, 25 % och 50 % felfrekvens över:
- Enstaka satsinlägg med 20 000 rader
- 10 batcher med 2 000 rader
- 100 satser med 200 rader
- 1 000 satser med 20 rader
- 20 000 singleton-inlägg
*
tempdbär en enda datafil på en långsam disk med 7200 RPM. Detta är avsiktligt och avsett att förstärka eventuella flaskhalsar som orsakas av de olika användningarna avtempdb. Jag planerar att återbesöka det här testet någon gång närtempdbär på en snabbare SSD. - 10 %, 25 % och 50 % felfrekvens över:
Okej, TL;DR Redan!
Om du bara vill veta resultatet, hoppa ner. Allt i mitten är bara bakgrund och en förklaring av hur jag ställde upp och körde testerna. Jag är inte förkrossad över att inte alla kommer att vara intresserade av alla detaljer.
Scenariot
För denna speciella uppsättning tester är det verkliga scenariot ett där en användare väljer ett skärmnamn, och utlösaren är utformad för att fånga fall där det valda namnet bryter mot vissa regler. Det kan till exempel inte vara någon variant av "ninny-muggins" (du kan säkert använda din fantasi här).
Jag skapade en tabell med 20 000 unika användarnamn:
USE model; GO -- 20,000 distinct, good Names ;WITH distinct_Names AS ( SELECT Name FROM sys.all_columns UNION SELECT Name FROM sys.all_objects ) SELECT TOP (20000) Name INTO dbo.GoodNamesSource FROM ( SELECT Name FROM distinct_Names UNION SELECT Name + 'x' FROM distinct_Names UNION SELECT Name + 'y' FROM distinct_Names UNION SELECT Name + 'z' FROM distinct_Names ) AS x; CREATE UNIQUE CLUSTERED INDEX x ON dbo.GoodNamesSource(Name);
Sedan skapade jag en tabell som skulle vara källan för mina "stygga namn" att kolla mot. I det här fallet är det bara ninny-muggins-00001 genom ninny-muggins-10000 :
USE model;
GO
CREATE TABLE dbo.NaughtyUserNames
(
Name NVARCHAR(255) PRIMARY KEY
);
GO
-- 10,000 "bad" names
INSERT dbo.NaughtyUserNames(Name)
SELECT N'ninny-muggins-' + RIGHT(N'0000' + RTRIM(n),5)
FROM
(
SELECT TOP (10000) n = ROW_NUMBER() OVER (ORDER BY Name)
FROM dbo.GoodNamesSource
) AS x;
Jag skapade dessa tabeller i model databas så att varje gång jag skapar en databas, skulle den finnas lokalt, och jag planerar att skapa många databaser för att testa scenariomatrisen ovan (istället för att bara ändra databasinställningar, rensa loggen, etc). Observera att om du skapar objekt i modellen för teständamål, se till att du tar bort dessa objekt när du är klar.
För övrigt kommer jag avsiktligt att lämna nyckelöverträdelser och annan felhantering utanför detta, vilket gör det naiva antagandet att det valda namnet kontrolleras för unikhet långt innan infogningen någonsin görs, men inom samma transaktion (precis som kontrollera mot den stygga namntabellen kunde ha gjorts i förväg).
För att stödja detta skapade jag även följande tre nästan identiska tabeller i model , för testisoleringsändamål:
USE model; GO -- AFTER (rollback) CREATE TABLE dbo.UserNames_After_Rollback ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Rollback(DateCreated) INCLUDE(Name); -- AFTER (delete) CREATE TABLE dbo.UserNames_After_Delete ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Delete(DateCreated) INCLUDE(Name); -- INSTEAD CREATE TABLE dbo.UserNames_Instead ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_Instead(DateCreated) INCLUDE(Name); GO
Och följande tre triggers, en för varje tabell:
USE model;
GO
-- AFTER (rollback)
CREATE TRIGGER dbo.trUserNames_After_Rollback
ON dbo.UserNames_After_Rollback
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
IF EXISTS
(
SELECT 1 FROM inserted AS i
WHERE EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
)
)
BEGIN
ROLLBACK TRANSACTION;
END
END
GO
-- AFTER (delete)
CREATE TRIGGER dbo.trUserNames_After_Delete
ON dbo.UserNames_After_Delete
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
DELETE d
FROM inserted AS i
INNER JOIN dbo.NaughtyUserNames AS n
ON i.Name = n.Name
INNER JOIN dbo.UserNames_After_Delete AS d
ON i.UserID = d.UserID;
END
GO
-- INSTEAD
CREATE TRIGGER dbo.trUserNames_Instead
ON dbo.UserNames_Instead
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserNames_Instead(Name)
SELECT i.Name
FROM inserted AS i
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
);
END
GO Du skulle förmodligen vilja överväga ytterligare hantering för att meddela användaren att deras val har återställts eller ignorerats – men även detta utelämnas för enkelhetens skull.
Testinställningen
Jag skapade exempeldata som representerade de tre felfrekvenserna jag ville testa, ändrade 10 procent till 25 och sedan 50, och la även till dessa tabeller i model :
USE model;
GO
DECLARE @pct INT = 10, @cap INT = 20000;
-- change this ----^^ to 25 and 50
DECLARE @good INT = @cap - (@cap*(@pct/100.0));
SELECT Name, rn = ROW_NUMBER() OVER (ORDER BY NEWID())
INTO dbo.Source10Percent FROM
-- change this ^^ to 25 and 50
(
SELECT Name FROM
(
SELECT TOP (@good) Name FROM dbo.GoodNamesSource ORDER BY NEWID()
) AS g
UNION ALL
SELECT Name FROM
(
SELECT TOP (@cap-@good) Name FROM dbo.NaughtyUserNames ORDER BY NEWID()
) AS b
) AS x;
CREATE UNIQUE CLUSTERED INDEX x ON dbo.Source10Percent(rn);
-- and here as well -------------------------^^ Varje tabell har 20 000 rader, med olika blandning av namn som kommer att godkännas och misslyckas, och radnummerkolumnen gör det enkelt att dela upp data i olika batchstorlekar för olika tester, men med repeterbara felfrekvenser för alla tester.
Naturligtvis behöver vi en plats för att fånga resultaten. Jag valde att använda en separat databas för detta, köra varje test flera gånger, helt enkelt fånga varaktighet.
CREATE DATABASE ControlDB; GO USE ControlDB; GO CREATE TABLE dbo.Tests ( TestID INT, DiskLayout VARCHAR(15), RecoveryModel VARCHAR(6), TriggerType VARCHAR(14), [snapshot] VARCHAR(3), FailureRate INT, [sql] NVARCHAR(MAX) ); CREATE TABLE dbo.TestResults ( TestID INT, BatchDescription VARCHAR(15), Duration INT );
Jag fyllde i dbo.Tests tabell med följande skript, så att jag kunde köra olika delar för att ställa in de fyra databaserna för att matcha de aktuella testparametrarna. Observera att D:\ är en SSD, medan G:\ är en 7200 RPM disk:
TRUNCATE TABLE dbo.Tests;
TRUNCATE TABLE dbo.TestResults;
;WITH d AS
(
SELECT DiskLayout FROM (VALUES
('DataSSD_LogHDD'),
('DataSSD_LogSSD'),
('DataHDD_LogHDD'),
('DataHDD_LogSSD')) AS d(DiskLayout)
),
t AS
(
SELECT TriggerType FROM (VALUES
('After_Delete'),
('After_Rollback'),
('Instead')) AS t(TriggerType)
),
m AS
(
SELECT RecoveryModel = 'FULL'
UNION ALL SELECT 'SIMPLE'
),
s AS
(
SELECT IsSnapshot = 0
UNION ALL SELECT 1
),
p AS
(
SELECT FailureRate = 10
UNION ALL SELECT 25
UNION ALL SELECT 50
)
INSERT ControlDB.dbo.Tests
(
TestID,
DiskLayout,
RecoveryModel,
TriggerType,
IsSnapshot,
FailureRate,
Command
)
SELECT
TestID = ROW_NUMBER() OVER
(
ORDER BY d.DiskLayout, t.TriggerType, m.RecoveryModel, s.IsSnapshot, p.FailureRate
),
d.DiskLayout,
m.RecoveryModel,
t.TriggerType,
s.IsSnapshot,
p.FailureRate,
[sql]= N'SET NOCOUNT ON;
CREATE DATABASE ' + QUOTENAME(d.DiskLayout)
+ N' ON (name = N''data'', filename = N''' + CASE d.DiskLayout
WHEN 'DataSSD_LogHDD' THEN N'D:\data\data1.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data1.ldf'');'
WHEN 'DataSSD_LogSSD' THEN N'D:\data\data2.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data2.ldf'');'
WHEN 'DataHDD_LogHDD' THEN N'G:\data\data3.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data3.ldf'');'
WHEN 'DataHDD_LogSSD' THEN N'G:\data\data4.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data4.ldf'');' END
+ '
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET RECOVERY ' + m.RecoveryModel + ';'';'
+ CASE WHEN s.IsSnapshot = 1 THEN
'
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET ALLOW_SNAPSHOT_ISOLATION ON;'';
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET READ_COMMITTED_SNAPSHOT ON;'';'
ELSE '' END
+ '
DECLARE @d DATETIME2(7), @i INT, @LoopID INT, @loops INT, @perloop INT;
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT LoopID, loops, perloop FROM dbo.Loops;
OPEN c;
FETCH c INTO @LoopID, @loops, @perloop;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC sp_executesql N''TRUNCATE TABLE '
+ QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + ';'';
SELECT @d = SYSDATETIME(), @i = 1;
WHILE @i <= @loops
BEGIN
BEGIN TRY
INSERT ' + QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + '(Name)
SELECT Name FROM ' + QUOTENAME(d.DiskLayout) + '.dbo.Source' + RTRIM(p.FailureRate) + 'Percent
WHERE rn > (@i-1)*@perloop AND rn <= @i*@perloop;
END TRY
BEGIN CATCH
SET @TestID = @TestID;
END CATCH
SET @i += 1;
END
INSERT ControlDB.dbo.TestResults(TestID, LoopID, Duration)
SELECT @TestID, @LoopID, DATEDIFF(MILLISECOND, @d, SYSDATETIME());
FETCH c INTO @LoopID, @loops, @perloop;
END
CLOSE c;
DEALLOCATE c;
DROP DATABASE ' + QUOTENAME(d.DiskLayout) + ';'
FROM d, t, m, s, p; -- implicit CROSS JOIN! Do as I say, not as I do! :-) Sedan var det enkelt att köra alla tester flera gånger:
USE ControlDB;
GO
SET NOCOUNT ON;
DECLARE @TestID INT, @Command NVARCHAR(MAX), @msg VARCHAR(32);
DECLARE d CURSOR LOCAL FAST_FORWARD FOR
SELECT TestID, Command
FROM ControlDB.dbo.Tests ORDER BY TestID;
OPEN d;
FETCH d INTO @TestID, @Command;
WHILE @@FETCH_STATUS <> -1
BEGIN
SET @msg = 'Starting ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
EXEC sp_executesql @Command, N'@TestID INT', @TestID;
SET @msg = 'Finished ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
FETCH d INTO @TestID, @Command;
END
CLOSE d;
DEALLOCATE d;
GO 10
På mitt system tog det nästan 6 timmar, så var beredd på att låta detta gå oavbrutet. Se också till att du inte har några aktiva anslutningar eller frågefönster öppna mot model databas, annars kan du få det här felet när skriptet försöker skapa en databas:
Det gick inte att få exklusivt lås på databasens "modell". Försök igen senare.
Resultat
Det finns många datapunkter att titta på (och alla frågor som används för att härleda data hänvisas till i bilagan). Tänk på att varje genomsnittlig varaktighet som anges här är över 10 tester och att totalt 100 000 rader infogas i måltabellen.
Diagram 1 – Totala aggregat
Den första grafen visar övergripande aggregat (genomsnittlig varaktighet) för de olika variablerna isolerat (alltså *alla* tester med en AFTER-trigger som raderar, *alla* tester med en AFTER-trigger som rullar tillbaka, etc).
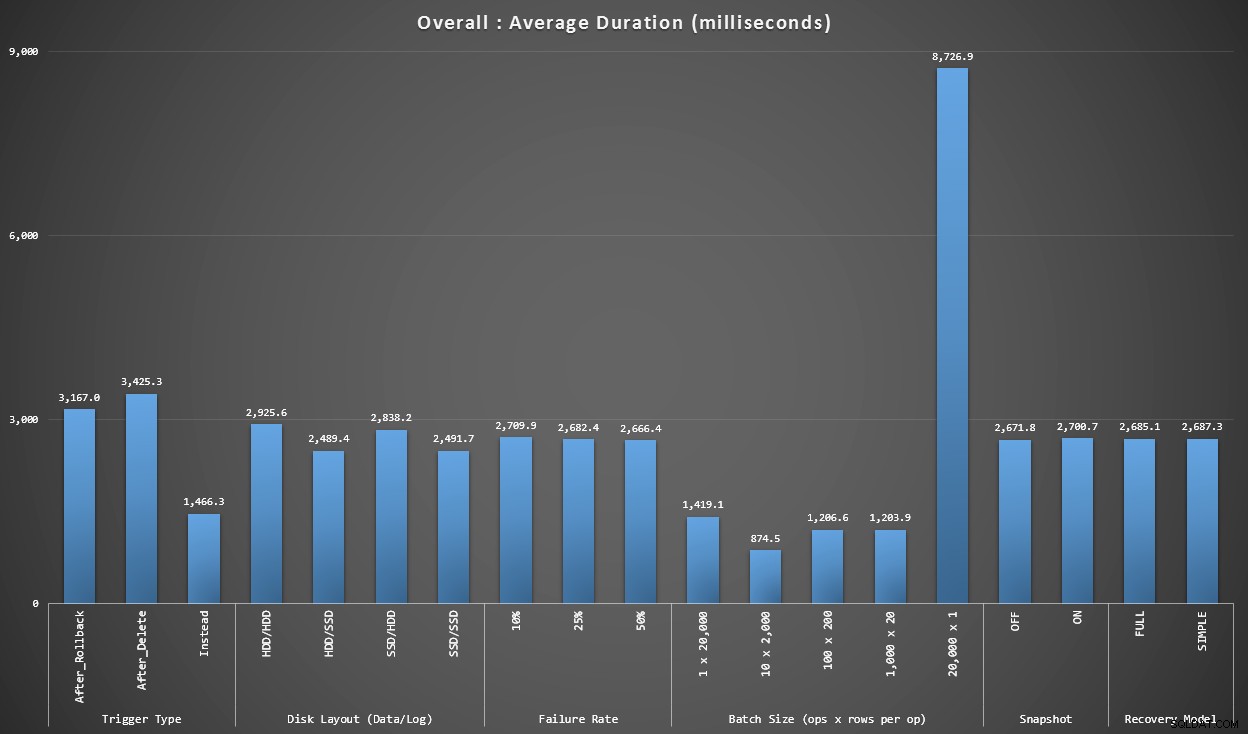
Genomsnittlig varaktighet, i millisekunder, för varje variabel isolerat em>
Några saker faller på oss direkt:
- Utlösaren INSTEAD OF här är dubbelt så snabb som båda EFTER-utlösare.
- Att ha transaktionsloggen på SSD gjorde lite skillnad. Plats för datafilen mycket mindre.
- Satsen med 20 000 singletonskär var 7-8 gånger långsammare än någon annan batchdistribution.
- Den enkla satsinsatsen på 20 000 rader var långsammare än någon av distributionerna som inte är enstaka.
- Felfrekvens, ögonblicksbildsisolering och återställningsmodell hade liten eller ingen inverkan på prestandan.
Diagram 2 – Bästa 10 totalt
Denna graf visar de 10 snabbaste resultaten när varje variabel beaktas. Dessa är alla I STÄLLET FÖR utlösare där den största andelen rader misslyckas (50%). Överraskande nog hade den snabbaste (men inte mycket) både data och inloggning på samma hårddisk (inte SSD). Det finns en blandning av disklayouter och återställningsmodeller här, men alla 10 hade ögonblicksbildsisolering aktiverad, och de 7 bästa resultaten involverade alla batchstorleken på 10 x 2 000 rader.
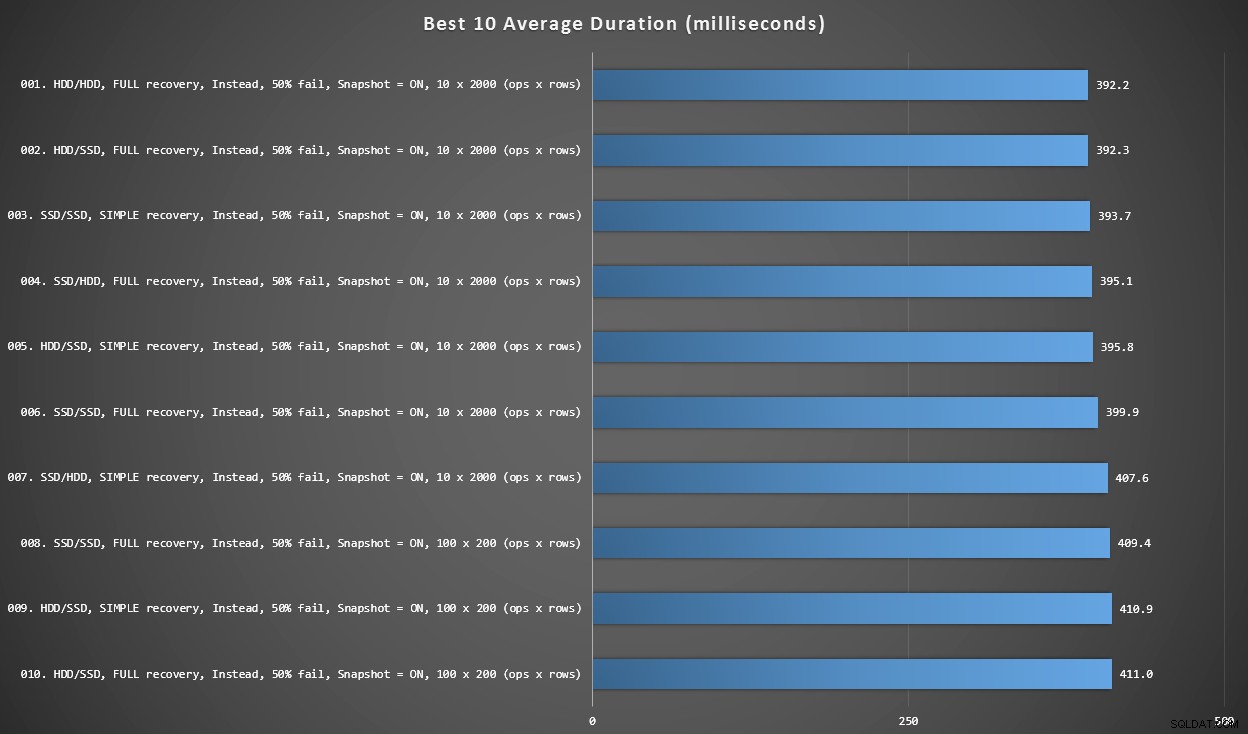
Bästa 10 varaktigheter, i millisekunder, med tanke på varje variabel
Den snabbaste AFTER-utlösaren – en ROLLBACK-variant med 10 % felfrekvens i batchstorleken på 100 x 200 rader – kom in i position #144 (806 ms).
Diagram 3 – Sämsta 10 totalt
Denna graf visar de långsammaste 10 resultaten när varje variabel beaktas; alla är AFTER-varianter, alla involverar 20 000 singleton-insatser, och alla har data och loggar på samma långsamma hårddisk.
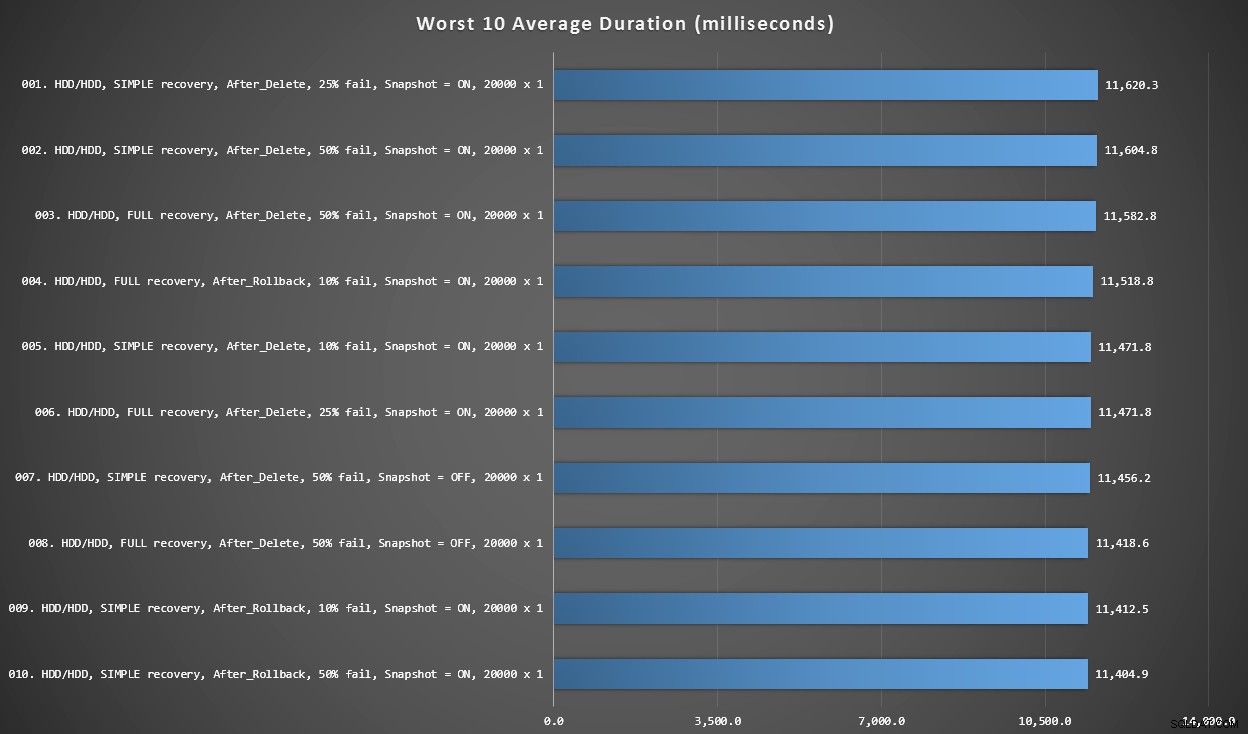
Sämsta 10 varaktigheter, i millisekunder, med tanke på varje variabel
Det långsammaste testet I STÄLLET FÖR var i position #97, vid 5 680 ms – ett 20 000 singleton insert-test där 10 % misslyckades. Det är också intressant att observera att inte en enda AFTER-trigger som använde 20 000 singleton-skärsatsstorleken klarade sig bättre – i själva verket var det 96:e sämsta resultatet ett EFTER (radera) test som kom in på 10 219 ms – nästan dubbelt så mycket som det näst långsammaste resultatet.
Diagram 4 – Log Disk Type, Singleton Inserts
Graferna ovan ger oss en grov uppfattning om de största smärtpunkterna, men de är antingen för inzoomade eller inte tillräckligt inzoomade. Den här grafen filtrerar ner till data baserade på verkligheten:i de flesta fall kommer denna typ av operation att vara en singleton-insättning. Jag tänkte att jag skulle dela upp det efter felfrekvens och vilken typ av disk loggen finns på, men bara titta på rader där batchen består av 20 000 individuella inlägg.
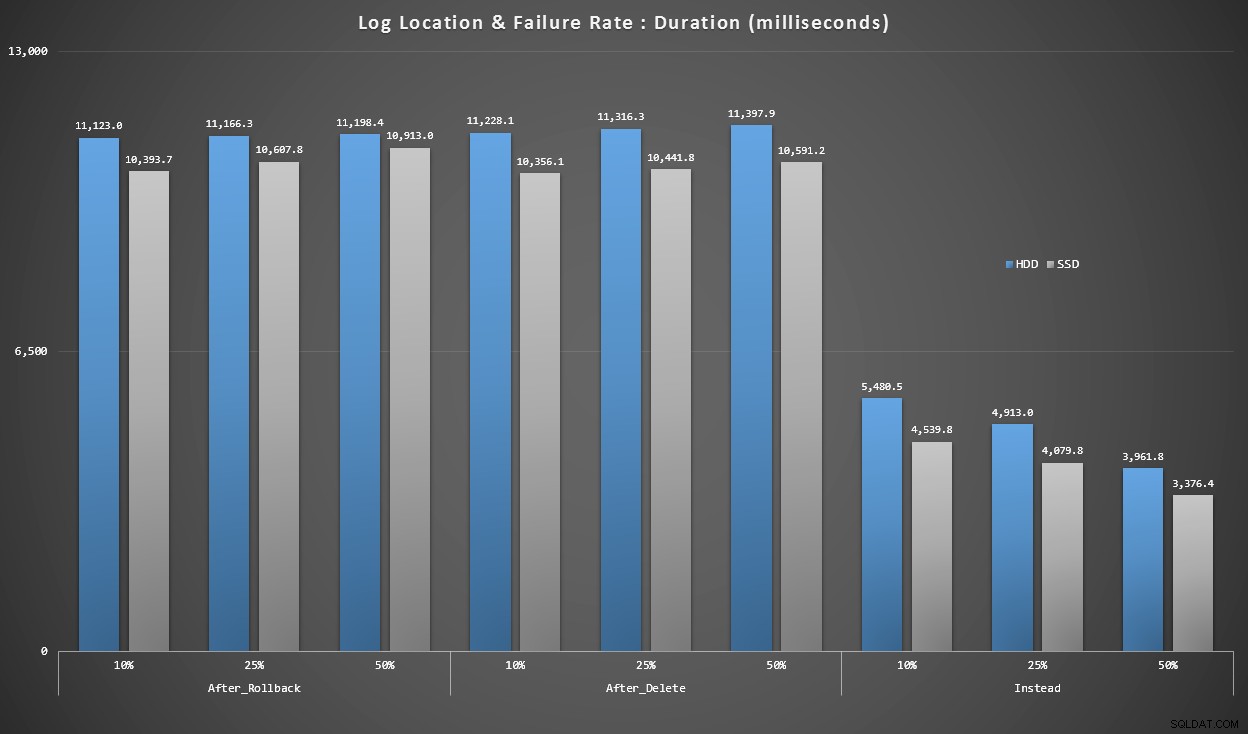
Längd, i millisekunder, grupperad efter felfrekvens och loggplats, för 20 000 enskilda inlägg
Här ser vi att alla AFTER-utlösare är i genomsnitt inom intervallet 10-11 sekunder (beroende på loggplats), medan alla INSTEAD OF-utlösare är långt under 6-sekundersmärket.
Slutsats
Hittills verkar det vara klart för mig att INSTEAD OF-utlösaren är en vinnare i de flesta fall – i vissa fall mer än andra (till exempel eftersom felfrekvensen går upp). Andra faktorer, som återhämtningsmodellen, verkar ha mycket mindre inverkan på den totala prestandan.
Om du har andra idéer om hur du kan dela upp data, eller vill ha en kopia av data för att utföra din egen skivning och tärning, vänligen meddela mig. Om du vill ha hjälp med att ställa in den här miljön så att du kan köra dina egna tester kan jag hjälpa till med det också.
Även om detta test visar att I STÄLLET FÖR triggers definitivt är värda att överväga, är det inte hela historien. Jag slog bokstavligen samman dessa triggers med den logik som jag tyckte var mest meningsfull för varje scenario, men triggerkod – som alla T-SQL-satser – kan ställas in för optimala planer. I ett uppföljande inlägg ska jag ta en titt på en potentiell optimering som kan göra AFTER-utlösaren mer konkurrenskraftig.
Bilaga
Frågor som används för avsnittet Resultat:
Diagram 1 – Totala aggregat
SELECT RTRIM(l.loops) + ' x ' + RTRIM(l.perloop), AVG(r.Duration*1.0) FROM dbo.TestResults AS r INNER JOIN dbo.Loops AS l ON r.LoopID = l.LoopID GROUP BY RTRIM(l.loops) + ' x ' + RTRIM(l.perloop); SELECT t.IsSnapshot, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.IsSnapshot; SELECT t.RecoveryModel, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.RecoveryModel; SELECT t.DiskLayout, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.DiskLayout; SELECT t.TriggerType, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.TriggerType; SELECT t.FailureRate, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.FailureRate;
Diagram 2 och 3 – Bästa och sämsta 10
;WITH src AS
(
SELECT DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
Batch = RTRIM(l.loops) + ' x ' + RTRIM(l.perloop),
Duration = AVG(Duration*1.0)
FROM dbo.Tests AS t
INNER JOIN dbo.TestResults AS tr
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON tr.LoopID = l.LoopID
GROUP BY DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
RTRIM(l.loops) + ' x ' + RTRIM(l.perloop)
),
agg AS
(
SELECT label = REPLACE(REPLACE(DiskLayout,'Data',''),'_Log','/')
+ ', ' + RecoveryModel + ' recovery, ' + TriggerType
+ ', ' + RTRIM(FailureRate) + '% fail'
+ ', Snapshot = ' + CASE IsSnapshot WHEN 1 THEN 'ON' ELSE 'OFF' END
+ ', ' + Batch + ' (ops x rows)',
best10 = ROW_NUMBER() OVER (ORDER BY Duration),
worst10 = ROW_NUMBER() OVER (ORDER BY Duration DESC),
Duration
FROM src
)
SELECT grp, label, Duration FROM
(
SELECT TOP (20) grp = 'best', label = RIGHT('0' + RTRIM(best10),2) + '. ' + label, Duration
FROM agg WHERE best10 <= 10
ORDER BY best10 DESC
UNION ALL
SELECT TOP (20) grp = 'worst', label = RIGHT('0' + RTRIM(worst10),2) + '. ' + label, Duration
FROM agg WHERE worst10 <= 10
ORDER BY worst10 DESC
) AS b
ORDER BY grp; Diagram 4 – Log Disk Type, Singleton Inserts
;WITH x AS
(
SELECT
TriggerType,FailureRate,
LogLocation = RIGHT(DiskLayout,3),
Duration = AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON l.LoopID = tr.LoopID
WHERE l.loops = 20000
GROUP BY RIGHT(DiskLayout,3), FailureRate, TriggerType
)
SELECT TriggerType, FailureRate,
HDDDuration = MAX(CASE WHEN LogLocation = 'HDD' THEN Duration END),
SSDDuration = MAX(CASE WHEN LogLocation = 'SSD' THEN Duration END)
FROM x
GROUP BY TriggerType, FailureRate
ORDER BY TriggerType, FailureRate;