ProxySQL är en dedikerad lastbalanserare för MySQL som kommer med en mängd olika funktioner inklusive, men inte begränsat till omdirigering av frågor, cachelagring av frågor eller trafikformning. Den kan användas för att enkelt ställa in en läs-skriv-delning och omdirigera frågor till separata backend-noder. Som ett resultat ger det många övertygande skäl att använda. Å andra sidan är HAProxy en bra lastbalanserare men den är inte dedikerad för databaser och även om den kan användas kan den inte riktigt jämföras funktionsmässigt med ProxySQL. Detta kan vara anledningen till att miljöer som fortfarande är beroende av HAProxy försöker migrera till ProxySQL.
I detta korta blogginlägg kommer vi att dela med oss av ett par förslag angående migreringsprocessen.
Planera din uppgradering
Detta är ganska uppenbart och borde försvinna utan frågor, men vi vill ändå ha det skriftligt. Planera din uppgradering. Se till att du är bekant med processen, att du testat allt utförligt. Skapa en testmiljö där du kan verifiera olika tillvägagångssätt för uppgraderingen och bestämma vilken som fungerar bäst för dig.
Testa läs-/skrivdelning i ProxySQL om du överväger att använda den
Beroende på dina krav kan du överväga att använda läs/skrivdelning i ProxySQL. Detta är förmodligen en av de mest övertygande anledningarna till att uppgradera. Istället för att implementera det på applikationssidan (eller inte implementera det alls om du inte kan åstadkomma det i applikationen), kan du lita på att ProxySQL utför läs/skrivdelningen åt dig. Installationen är mycket enkel, speciellt om du distribuerar ProxySQL med ClusterControl - det sker i stort sett automatiskt.
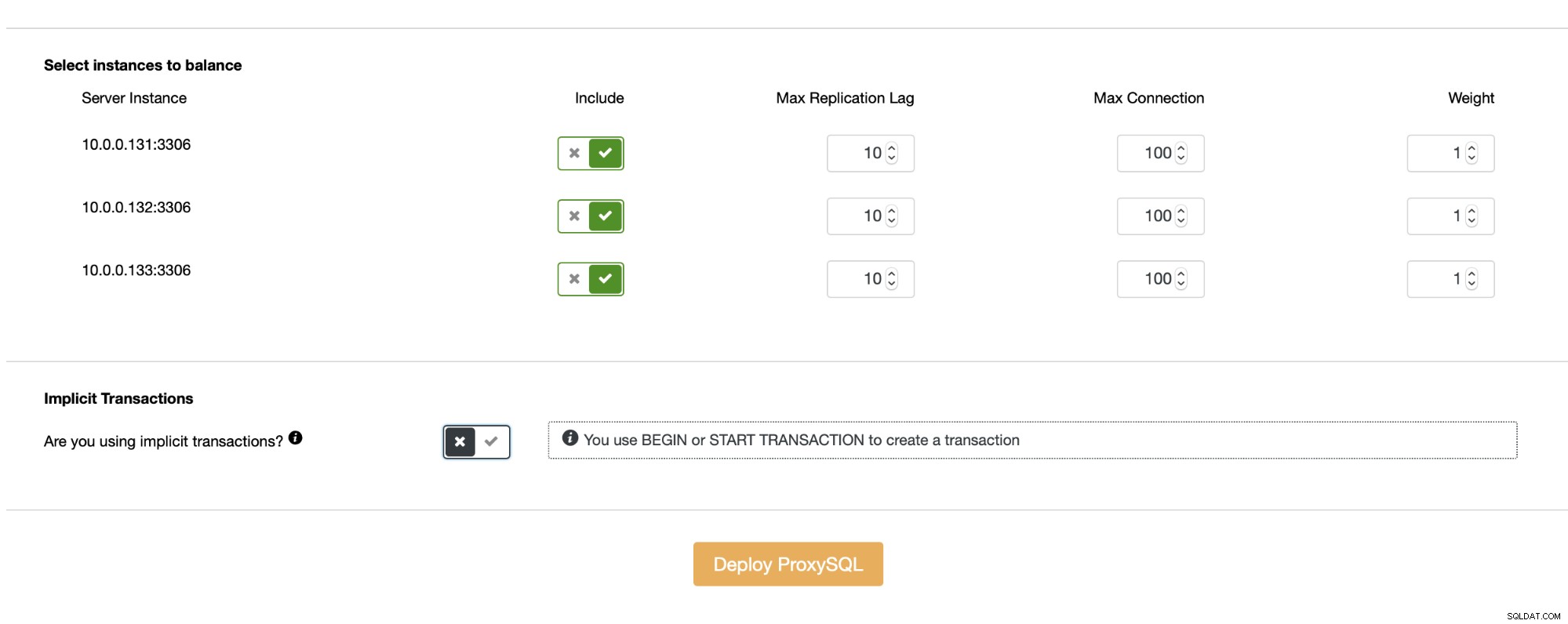
Så länge du inte använder implicita transaktioner kommer ClusterControl att ställa in läs/skrivdelning för dig med hjälp av en uppsättning frågeregler:
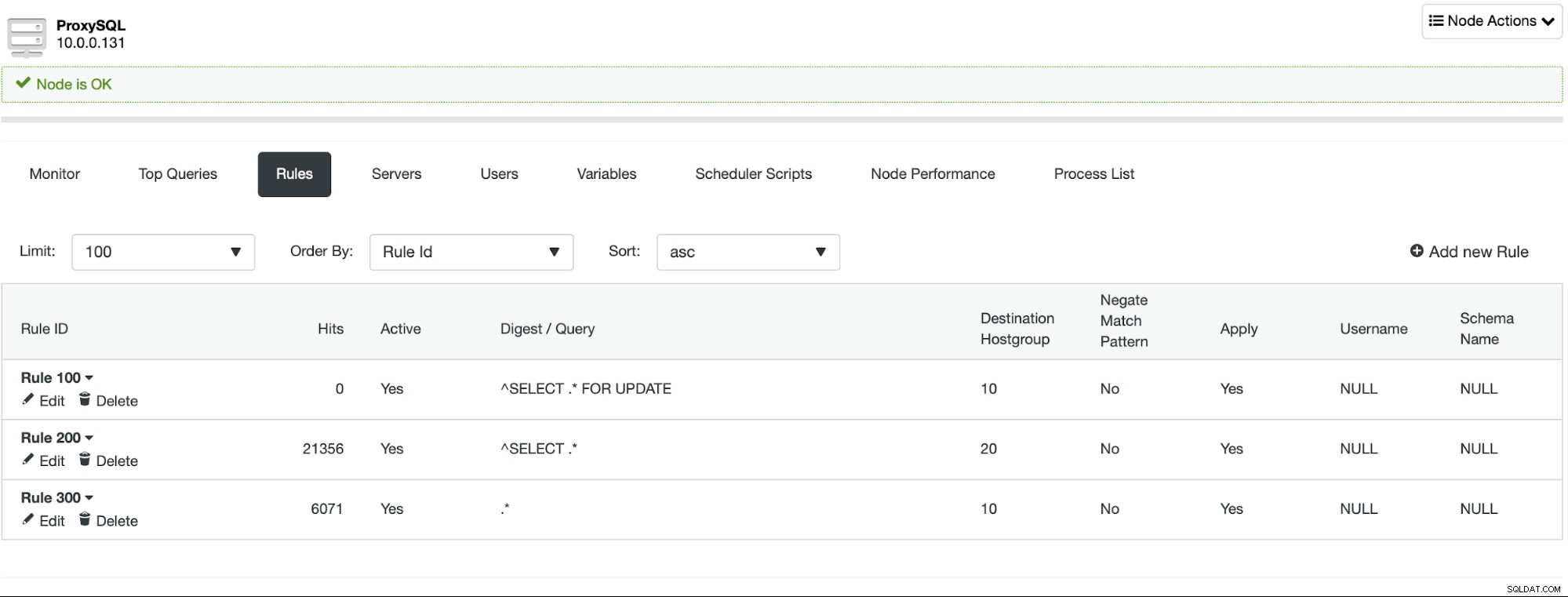
Även om det är väldigt enkelt att implementera läs/skrivdelning, bör du var försiktig när du planerar att göra det. Applikationer kan förlita sig på någon funktionalitet som inte riktigt fungerar direkt i ProxySQL. I de flesta fall kommer ytterligare konfigurationer att låta dig dra nytta av den här funktionen, men det är mycket viktigt under testfasen att identifiera om din app bara kommer att fungera eller behöver du lägga till någon anpassad konfiguration. Särskilt knepiga delar är läs-efter-skriv-problem - i så fall kan du behöva konfigurera om ProxySQL för att inaktivera anslutningsmultiplexering för vissa av frågorna.
Glöm konfigurationsfilen i ProxySQL
Detta är en av de saker som kommer som en överraskning för nya användare av ProxySQL. Den använder inte riktigt konfigurationsfiler. Det finns en, ja, men den fungerar ganska mycket som ett sätt att bootstrap ProxySQL under den första starten. ProxySQL använder en SQLite-databas som innehåller dess konfiguration och det korrekta sättet att göra eventuella konfigurationsändringar är genom en MySQL-klient ansluten till den administrativa porten för ProxySQL. Därifrån kan du göra konfigurationsändringarna under körning, i stort sett utan att behöva starta om ProxySQL.
Naturligtvis låter ClusterControl UI också konfigurera om ProxySQL:
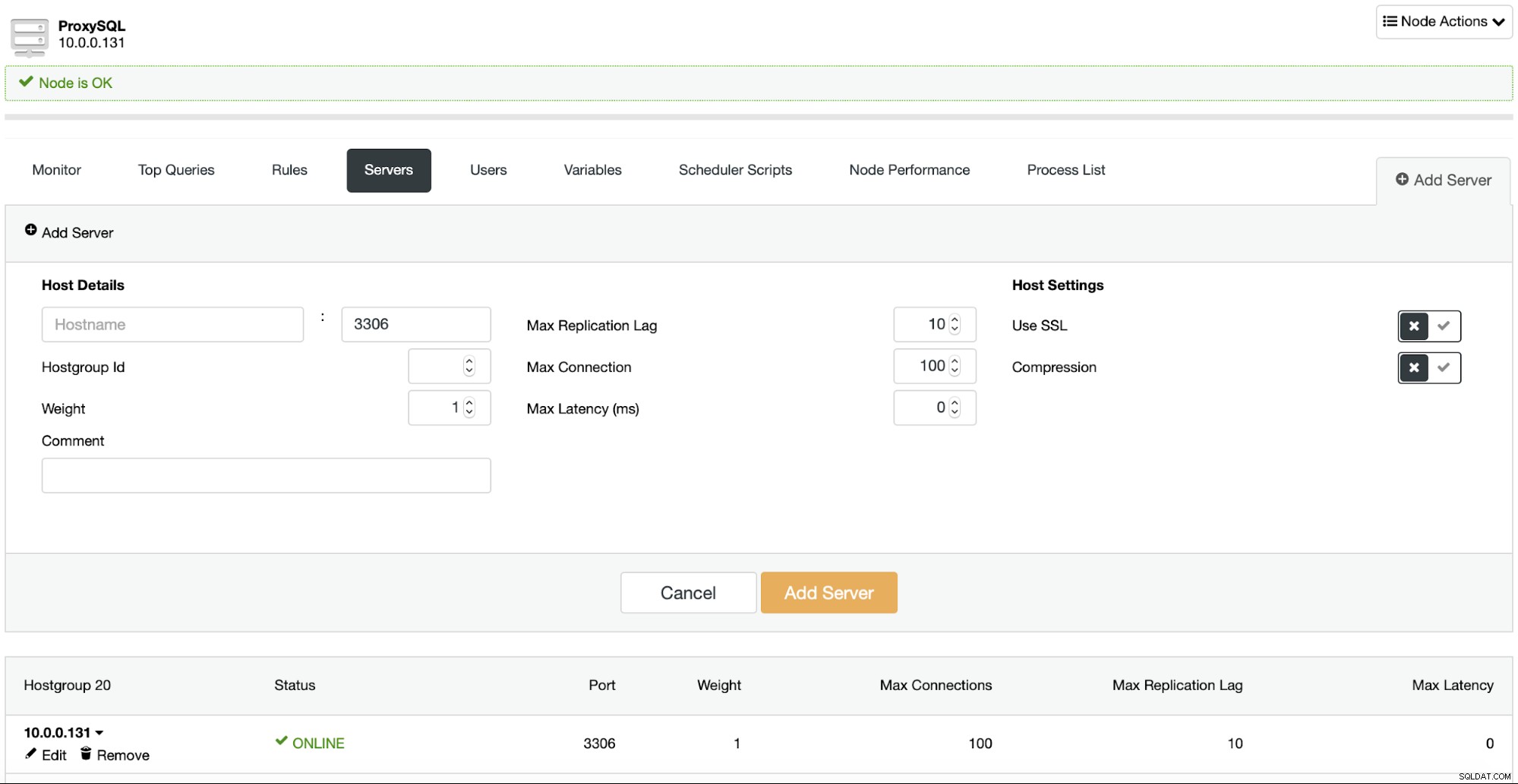
ProxySQL-distributionsmönster
Det finns två huvudsakliga sätt på vilka du vill distribuera ProxySQL. Du kan antingen använda en dedikerad server för att distribuera ProxySQL på:
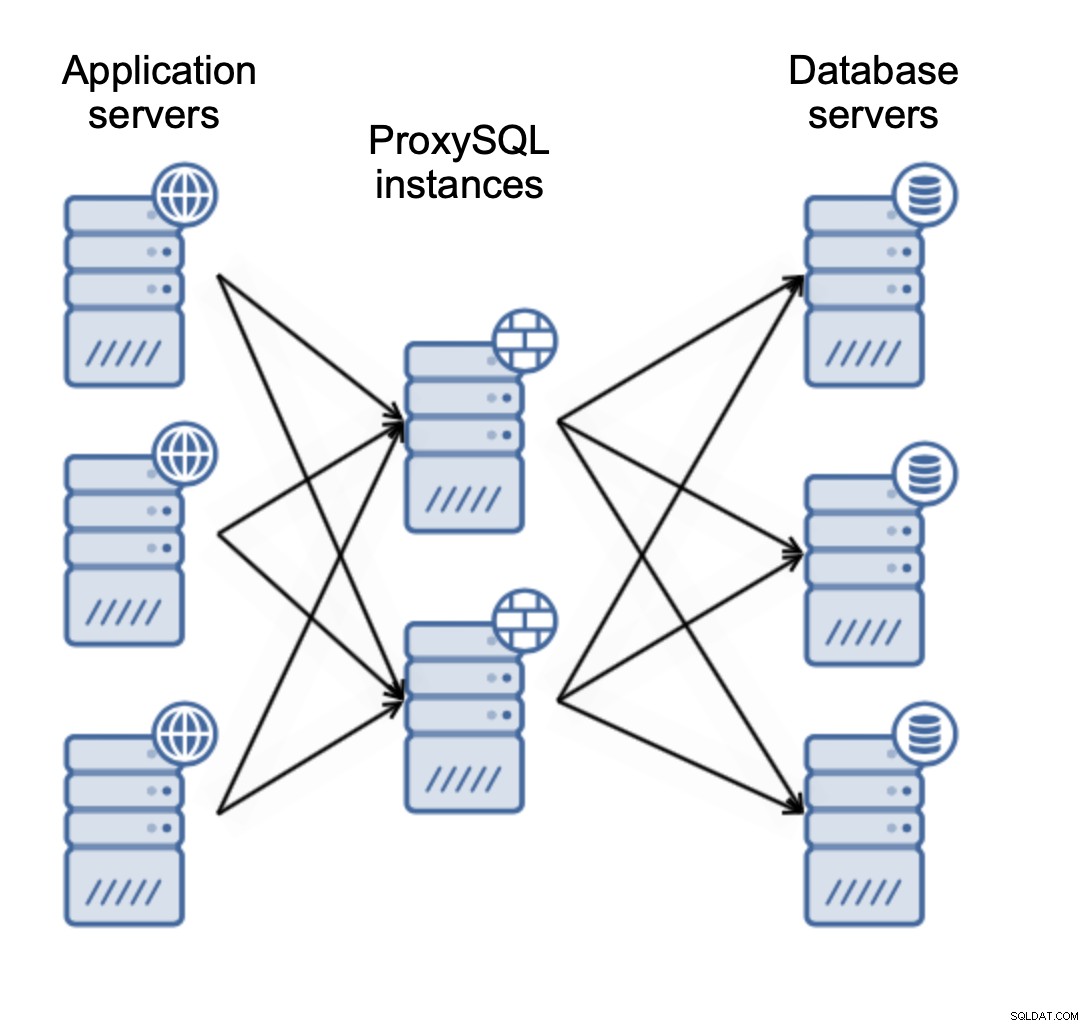
Eller så kan du samlokalisera ProxySQL med applikationsservrar:
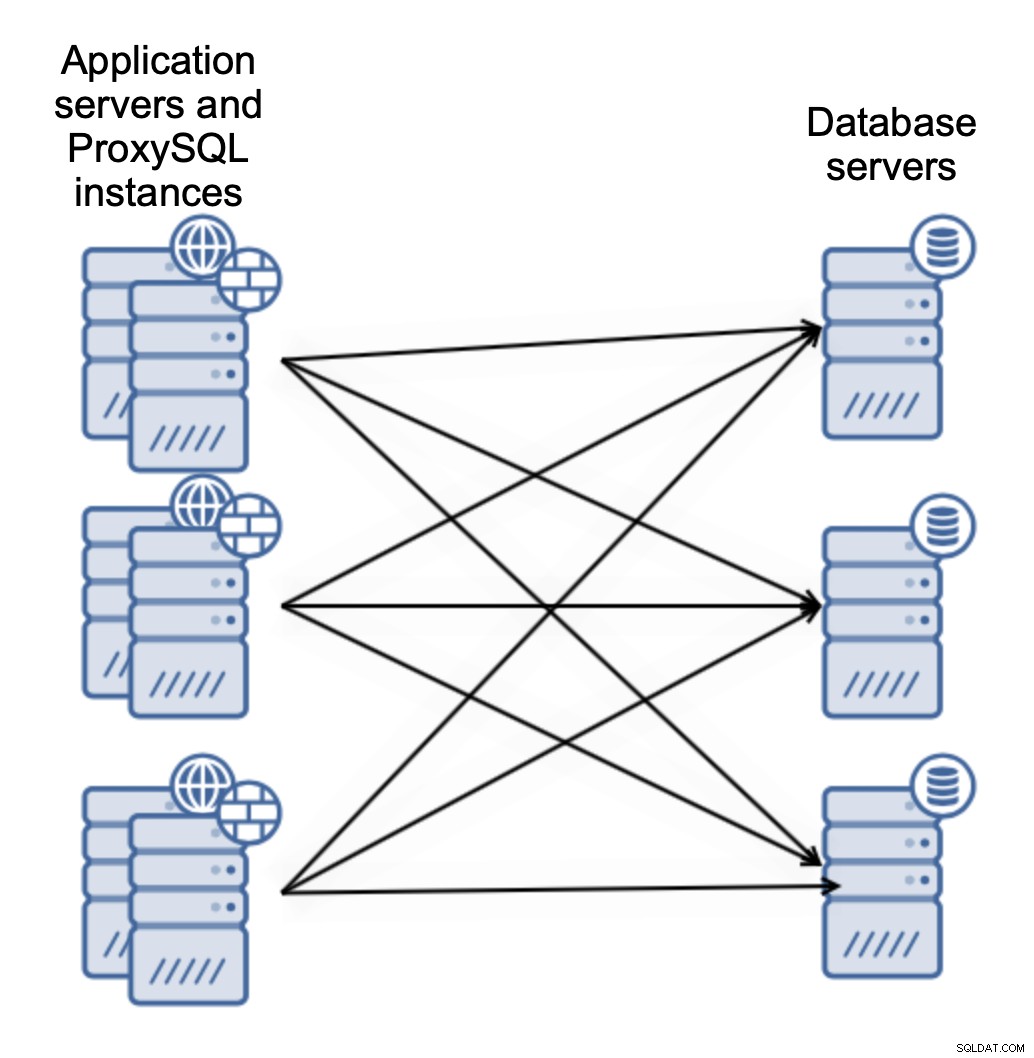
Detta låter din applikation ansluta till den lokala ProxySQL-instansen med Unix-socket, som är bättre prestandamässigt än att använda en fjärransluten TCP-anslutning. Det förenklar också installationen - det finns inget behov av att implementera Keepalved eller någon annan virtuell IP-leverantör för att ladda balans över ProxySQL-instanser. Applikationen ansluter bara till den lokala ProxySQL och det är ganska mycket det.
Använd ProxySQL-kluster för större distributioner
Att se till att dina ProxySQL-instanser innehåller samma konfiguration hela tiden kan vara utmanande, speciellt om antalet är stort. Det finns många sätt att hantera sådana utmaningar - Ansible/Chef/Puppet, skalmanus och så vidare. Vi föreslår att du litar på den inbyggda lösningen - ProxySQL Cluster. Med bara ett par konfigurationsändringar kan du konfigurera ProxySQL-noder för att bilda ett kluster där en konfigurationsändring på en av noderna kommer att spridas över alla medlemmar i klustret.
Tinker med SO_REUSEPORT för elegant byte av lastbalanserare
En av de mer utmanande delarna kan vara att se till att du byter trafik från HAProxy till ProxySQL på ett sätt som minimerar påverkan på applikationen. Vanligtvis måste du ändra minst en inställning - värdnamn eller port som programmet ska ansluta till. Beroende på din miljö kanske detta inte är idealiskt, särskilt om databasanslutningskonfigurationen är inbyggd i programmet. Det skulle i stort sett kräva att man ändrar kodbasen och skjuter en ny kod till produktionen. Inte den största affären men du kan göra bättre än så.
Det intressanta är att både ProxySQL och nyare versioner av HAProxy (med början från 1.8) kan använda SO_REUSEPORT. Detta socketalternativ är tillgängligt i Linux från 3.9-kärnan och det tillåter flera processer att dela samma port. ProxySQL kan använda det för graciösa uppgraderingar mellan ProxySQL-versioner, HAProxy använder det för att ladda om konfigurationen utan att det påverkar applikationen. Vad som är intressant är att det är möjligt att konfigurera ProxySQL för att dela porten med HAProxy för sömlös migrering mellan dessa två lastbalanserare.
Det finns ett par saker du måste tänka på när du försöker göra detta - för det första använder ProxySQL inte det här alternativet som standard, du måste lägga till -r-flaggan till ProxySQL vid uppstart. Du kan göra det genom att redigera ProxySQL systemd enhetsfil:
example@sqldat.com:~# systemctl edit proxysql --fulloch ändrar ExecStart-direktivet till:
ExecStart=/usr/bin/proxysql -c /etc/proxysql.cnf -rEn annan begränsning som du bör vara medveten om i Linux är att endast processer som startas av samma användar-ID får dela porten. Detta kommer att innebära att du måste konfigurera om ProxySQL för att köras som en "haproxy"-användare.
Som vanligt kanske du vill köra tester innan du försöker utföra den här operationen i en produktionsmiljö. Det är definitivt möjligt att åstadkomma denna bedrift men du bör vara försiktig och dubbelkolla att det inte kommer att påverka din produktion på grund av någon form av icke-standardkonfiguration relaterad till din miljö.
Vi hoppas att den här korta bloggen kommer att ge dig lite insikt i migreringsprocessen från HAProxy till ProxySQL. För databasens backends kommer denna förändring att vara mycket fördelaktig, även om förberedelsedelen kan vara tidskrävande. Om du går igenom ordentliga tester bör den slutliga migreringen vara ganska enkel och säker.