Introduktion:Det här exemplet visaren äldre metod att använda IRI RowGen för att generera och fylla i stora eller komplexa samlingsprototyper för testning eller systemkapacitet med hjälp av platta filer. Som du kommer att läsa skulle RowGen skapa nödvändiga testdata och skapa en CSV-fil som skulle laddas in i MongoDB med hjälp av Mongo Import Utility.
Uppdatering 2019:IRI erbjuder nu även JSON och direkt drivrutinsstöd för att flytta data mellan MongoDB-samlingar och SortCL-kompatibla IRI-programprodukter som RowGen eller FieldShield. Det betyder att du kan använda RowGen för att generera test-JSON-filer för import till MongoDB (inte olikt metoden som visas nedan i den här artikeln), eller använda FieldShield för att maskera data i Mongo-tabeller till testmål.
Observera att både FieldShield och RowGen ingår i IRI Voracitys datahanteringsplattform, som erbjuder fyra sätt att skapa testdata.
Även om MongoDB är en bra plattformsoberoende, dokumentorienterad NoSQL-databas, har den inget bekvämt sätt att generera och fylla i stora eller komplexa samlingsprototyper som kan användas för att testa frågor eller planera kapacitet. Den här artikeln förklarar hur man skapar testdata som MongoDB kan använda via IRI RowGen, och specificerar parametrarna för en syntetisk, men realistisk, CSV-fil som MongoDB kan importera för funktions- och prestandatestning.
Du måste först överväga strukturen och innehållet i testdatan för din samlingsbehov (MongoDB-tabell). Se den här artikeln för typiska planeringsöverväganden.
I exemplet vet vi att vår samling kommer att bestå av kunder som alla har användarnamn , För- och efternamn , E-postadresser och Kreditkortsnummer .
För att skapa vår testdata måste vi först generera några uppsättningsfiler. En uppsättningsfil är en lista över ett eller flera tabbavgränsade värden som kanske redan finns, eller som måste genereras manuellt eller automatiskt från databaskolumner via guiden "Generera ny uppsättningsfil" i IRI RowGen.
Genererar namn
1) Skapa ett sammansatt datavärde (för- och efternamn kombinerade) jobbskript med namnet “CreateNamesSet.rcl” som RowGen kan köra för att skapa en uppsättningsfil; kalla utgången för “User.set” eftersom dessa namn också kommer att användas som grund för våra användarnamn.
2) Skapa tre fält som ska genereras i Names.set:efternamn, tabbavgränsare och förnamn. Namnge det första fältet "LastName" och välj metoden som vilja välja värden från en IRI-levererad uppsättningsfil som heter “names_last.set”. Lägg till det bokstavliga värdet "\t" för att lägga till en tabbavgränsare och upprepa sedan processen som används för LastName- och FirstName-värdena med names_first.set.
3) Kör CreateNamesSet.rcl med RowGen, antingen på kommandoraden eller från IRI Workbench GUI, för att skapa den tabbavgränsade User.set-filen med för- och efternamn, som kommer att användas i både genereringen av användarnamn och i den slutliga testfilen som fyller vår prototypsamling.

Genererar användarnamn
För användarnamn skapar vi en uppsättningsfil som använder filen Users.set som genereras ovan. Användarnamn för det här exemplet kommer att kombinera efternamn, första initial och ett slumpmässigt genererat tal mellan 100 och 999.
1) Skapa ett nytt RowGen-jobbskript med Compound Data Wizard, kalla det “CreateUsernamesSet.rcl” och döp utdatauppsättningsfilen till “Usernames.set”.
2) Bygg sammansatta användarnamnsvärden med tre komponenter som heter Del1, Del2 och Del3.
3) För del 1 väljer du metoden som väljer värden från (bläddra till) den tidigare genererade User.set-filen och ange "ALLA" för urvalstypen för att upprätthålla kopplingen mellan användare, användarnamn och e-postadresser. Ställ in storleken på 5.
4) För Del2, upprepa processen som användes för Del1, förutom för urvalstyp, välj "Rad" och ställ in kolumnindex till 2. Ställ in storleken till 1. Detta garanterar att alla efternamn kommer att användas i generationen, och att första bokstaven i förnamnet i samma rad läggs till användarnamnet.
5) För del 3, ange genereringen av ett numeriskt värde mellan 100 och 999 för att suffixa ett slumpmässigt heltal med varje användarnamn.
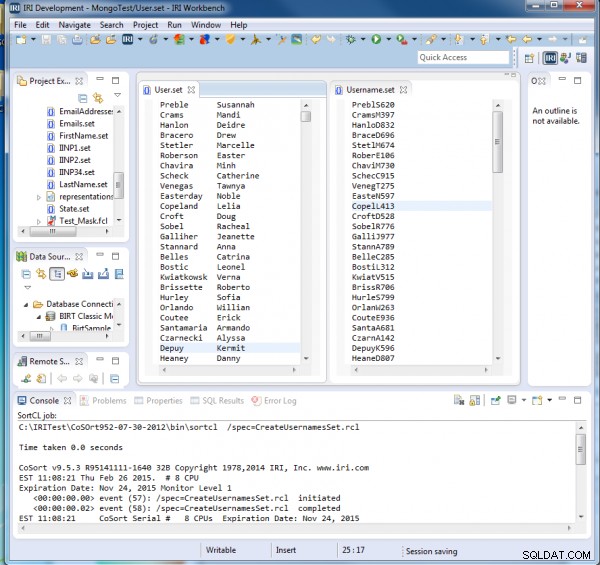
Vid körning av CreateUsernamesSet.rcl ser vi att varje användarnamn innehåller de första fem bokstäverna i deras efternamn, sedan deras första initial och sedan ett slumpmässigt tresiffrigt nummer:
Generera e-post
Närnäst kommer vi att skapa en e-postuppsättningsfil som lägger till användarnamnsvärdena med slumpmässigt valda domännamn. Eftersom vissa e-posttjänster är mer populära än andra kommer vi också att skapa ett viktningssystem för att återspegla en högre frekvens av yahoo- och Gmail-domäner.
1) Kör RowGens jobbguide "New Custom Test Data" för att skapa ett jobb som heter "CreateEmailsSet" som producerar en uppsättningsfil som heter "Emails.set".
2) Skapa användarnamnsdelen av e-postmeddelandet. Klicka på Nytt fält i dialogrutan Testdatadefinition och byt namn på det första fältet Användarnamn. Dubbelklicka på den för att starta dialogrutan Generation Field och "Definiera ..." dess Set-fil som Usernames.set. Ställ in storleken på 9 och klicka på OK.
3) Skapa domändelen av e-postmeddelandet (som inkluderar @-symbolen). I dialogrutan Layoutfält klickar du på Nytt fält och byter namn på det till "adress" och dubbelklickar på det. I dialogrutan Generationsfält anger du ett ” ,” med en position på 10 och en storlek på 20. I avsnittet Datagenerering/Datadistribution nedan, klicka på ”Definiera …” för att namnge en ny datadistribution av objekten ”WeightedEmails”.
4) I New Distribution Wizard, välj "Weighted Distribution of Items" och skriv in dessa objekt i textrutorna för förhållandet respektive bokstavlig text, och lägg sedan till var och en i listan.
(32 | @gmail.com), (32 | @yahoo.com), (2 | @ibm.com), (4 | @msn.com), (2 | @ymail.com), (2 | @inmail.com), (2 | @cnet.net), (2 | @chase.org), (1 | @iri.com), (1 | @gdic.com), (1 | @aci.com), (2 | @oracle.net), (1 | @gmx.org), (4 | @aol.com), (2 | @inbox.com), (2 | @hushmail.com), (2 | @outlook.com), (2 | @zoho.com), (2 | @yandex.net), (2 | @mail.com)
När du har angett dessa värden klickar du på Nästa i den ursprungliga guiden för att gå till dialogrutan Datamål. Använd "Lägg till datamål ..." för att ange utdatafilen "Email.set". Detta kommer också att användas vid samlingsbyggetid.
E-postmeddelandet som vi ställer in de högsta vikterna för (gmail och yahoo) dyker upp oftast, medan andra dyker upp med jämna mellanrum.

Generera kreditkortsnummer
Sistligen kommer vi att skapa beräkningsgiltiga kortnummer i formatet XXXX-XXXX-XXXX-XXXX. De första fyra siffrorna återspeglar faktiska Issue Identifier Numbers (IIN) för olika kreditkortsföretag, och den sista siffran verifierar kortens äkthet.
För att göra detta, skapa och kör ett nytt (tomt) jobb. Kalla det "CreateCCNSet.rcl" (eller .scl) och fyll i det med skriptet nedan för att skapa "CCN.set". /INCOLLECT-värdet i RowGen-skript bestämmer antalet genererade rader.

RowGens specialbyggda CCN-genereringsfunktion, ccn_gen(“ANY, “-“) anropas för att fylla i detta fält. Observera att liknande funktioner finns för amerikanska och koreanska personnummer och de nationella ID:n för Italien och Nederländerna.
Skapa den slutliga testfilen
Med alla uppsättningsfiler byggda är det dags att använda dem i test-CSV-filen som vi kommer att skapa och exportera till en MongoDB-samling.
1) Kör RowGens jobbguide "New Custom Test Data" för att skapa ett jobb som heter "CreateMongoUserData.rcl" som kommer att generera Customers.csv-filen, filen som vi sedan exporterar till MongoDB.
2) Klicka på "Layoutfält ..." för att öppna dialogrutan för layoutfält. Klicka på Nytt fält och byt namn på det första fältet till Användarnamn. Dubbelklicka på den för att starta dialogrutan Generation Field och "Definiera ..." dess Set-fil som Usernames.set; välj sedan ALLA för dess urvalstyp.
3) Klicka på Nytt fält och byt namn på det andra fältet till Efternamn. Dubbelklicka på den för att starta dialogrutan Generation Field och "Definiera ..." dess Set-fil som Users.set; välj sedan ALLA för dess urvalstyp.
4) Klicka på Nytt fält och byt namn på det tredje fältet till Förnamn. Dubbelklicka på den för att starta dialogrutan Generation Field och "Definiera ..." dess Set-fil som Users.set; välj sedan RADER för dess urvalstyp och ställ in kolumnindexet till 2.
5) Klicka på Nytt fält och byt namn på det fjärde fältet till E-post. Dubbelklicka på den för att starta dialogrutan Generation Field och "Definiera ..." dess Set-fil som Emails.set; välj sedan ALLA för dess urvalstyp.
6) Klicka på Nytt fält och byt namn på det femte fältet till CreditCardNumbers. Dubbelklicka på den för att starta dialogrutan Generation Field och "Definiera ..." dess Set-fil som CCN.set; välj sedan ALLA för dess urvalstyp.
7) När du har angett dessa värden klickar du på Nästa i den ursprungliga guiden för att gå till dialogrutan Datamål. Använd "Lägg till datamål ..." för att ange utdatafilen Customers.csv; kör sedan skriptet i Workbench eller på kommandoraden för att generera den filen:
rowgen /spec=CreateMongoUserData.rcl

Observera att RowGen, förutom att producera denna CSV-fil vid körning, också kunde ha producerat flera, andra filer, databas, formaterad rapport, namngiven-pipe, procedur och till och med BIRT-visning i realtid , med fält från genererade testdata, allt på samma gång.
Importerar till MongoDB
För att importera CSV-filen till din Mongo-databas, anropa 'mongoimport-verktyget' och kör följande kommando:
--db <Database Name> --collection <Collection Name> --type csv --fields <fieldname1,fieldname2,...> --file <File path to the CSV file to import>

Här är posterna i testsamlingen (visas med MongoVUE), som MongoDB automatiskt indexerar med genererade ID-värden för varje post:
MongoDB tilldelar ett unikt ID-värde till varje samlingspost.
Du kan också ladda testdata direkt i Mongo-databasen med hjälp av Progress Softwares DataDirect ODBC-drivrutin för MongoDB. Innan jag körde RowGen-jobbet i Workbench hade jag en tom samling som heter CUSTOMERS_CNN i MYDB för att ta emot data.
Jag körde jobbet först med stdout för att förhandsgranska mina testdata i konsolfönstret:

Efter att ha kört skriptet i Workbench kan jag nu se mina data med Data Source Explorer och DataDirect JDBC-drivrutinen.

Mer information om tillgängliga genereringsalternativ finns i Testfilmålen avsnitt på: https://www.iri.com/products/rowgen/technical-details.