Revision är övervakning och registrering av valda användardatabasåtgärder. Det används vanligtvis för att undersöka misstänkt aktivitet eller övervaka och samla in data om specifika databasaktiviteter. Databasadministratören kan till exempel samla in statistik om vilka tabeller som uppdateras, hur många operationer som utförs eller hur många samtidiga användare som ansluter vid vissa tidpunkter.
I det här blogginlägget kommer vi att täcka de grundläggande aspekterna av granskning av våra databassystem med öppen källkod, särskilt MySQL, MariaDB, PostgreSQL och MongoDB. Den här artikeln riktar sig till DevOps-ingenjörer som vanligtvis har mindre erfarenhet eller exponering av bästa praxis för revisionsefterlevnad och god datastyrning när de hanterar infrastrukturen främst för databassystemen.
Statusrevision
MySQL Statement Auditing
MySQL har den allmänna frågeloggen (eller general_log), som i princip registrerar vad mysqld gör. Servern skriver information till den här loggen när klienter ansluter eller kopplar från, och den loggar varje SQL-sats som tas emot från klienter. Den allmänna frågeloggen kan vara mycket användbar vid felsökning men egentligen inte byggd för kontinuerlig granskning. Det har en stor prestandapåverkan och bör endast aktiveras under korta tidsluckor. Det finns andra alternativ att använda performance_schema.events_statements*-tabeller eller Audit Plugin istället.
PostgreSQL-utlåtandegranskning
För PostgreSQL kan du aktivera log_statment till "all". Värden som stöds för denna parameter är none (off), ddl, mod och all (alla satser). För "ddl" loggas alla datadefinitionssatser, såsom CREATE-, ALTER- och DROP-satser. För "mod" loggar den alla DDL-satser, plus datamodifierande satser som INSERT, UPDATE, DELETE, TRUNCATE och COPY FROM.
Du måste förmodligen konfigurera de relaterade parametrarna som log_directory, log_filename, logging_collector och log_rotation_age, som visas i följande exempel:
log_directory = 'pg_log'
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
log_statement = 'all'
logging_collector = on
log_rotation_age = 10080 # 1 week in minutes Ovanstående ändringar kräver en PostgreSQL-omstart, så planera noga innan du ansöker till din produktionsmiljö. Du kan sedan hitta de aktuella loggarna under pg_log-katalogen. För PostgreSQL 12 är platsen /var/lib/pgsql/12/data/pg_log/ . Observera att loggfilerna tenderar att växa mycket med tiden och kan äta upp diskutrymmet avsevärt. Du kan också använda log_rotation_size istället om du har begränsat lagringsutrymme.
MongoDB Statement Auditing
För MongoDB finns det 3 loggningsnivåer som kan hjälpa oss att granska uttalandena (operationer eller operationer i MongoDB-term):
-
Nivå 0 - Detta är standardprofileringsnivån där profileraren inte samlar in någon data. Mongoden skriver alltid operationer längre än tröskelvärdet slowOpThresholdMs till sin logg.
-
Nivå 1 - Samlar in profileringsdata endast för långsamma operationer. Som standard är långsamma operationer de som är långsammare än 100 millisekunder. Du kan ändra tröskeln för "långsamma" operationer med alternativet slowOpThresholdMs runtime eller kommandot setParameter.
-
Nivå 2 – Samlar in profileringsdata för alla databasoperationer.
För att logga alla operationer, ställ in db.setProfilingLevel(2, 1000), där den ska profilera alla operationer med operationer som tar längre tid än de definierade millisekunderna, i detta fall är 1 sekund (1000 ms) . Frågan som ska sökas i systemprofilsamlingen efter alla frågor som tog längre tid än en sekund, sorterade efter fallande tidsstämpel. För att läsa operationerna kan vi använda följande fråga:
mongodb> db.system.profile.find( { millis : { $gt:1000 } } ).sort( { ts : -1 } )Det finns även Mongotail-projektet, som förenklar operationsprofileringsprocessen med ett externt verktyg istället för att fråga direkt till profilsamlingen.
Tänk på att det inte rekommenderas att köra fullständig uttalandegranskning i produktionsdatabasservrarna eftersom det vanligtvis medför en betydande inverkan på databastjänsten med en enorm volym loggning. Det rekommenderade sättet är att istället använda ett insticksprogram för databasgranskning (som visas längre ner), som tillhandahåller ett standardsätt för att producera granskningsloggar som ofta krävs för att uppfylla statliga, finansiella eller ISO-certifieringar.
Privilege Auditing för MySQL, MariaDB och PostgreSQL
Privilege-revision granskar privilegierna och åtkomstkontrollen till databasobjekten. Åtkomstkontroll säkerställer att de användare som kommer åt databasen är positivt identifierade och kan komma åt, uppdatera eller radera de data som de har rätt till. Detta område förbises ofta av DevOps-ingenjören, vilket gör överprivilegiering till ett vanligt misstag när man skapar och beviljar en databasanvändare.
Exempel på överprivilegierade är:
-
Användarens åtkomstvärdar är tillåtna från ett mycket brett spektrum, till exempel beviljande av användarvärd example@sqldat.com' %', istället för en individuell IP-adress.
-
Administrativa behörigheter som tilldelas till icke-administrativa databasanvändare, till exempel en databasanvändare för applikationen tilldelas med SUPER- eller RELOAD-behörighet.
-
Brist på resurskontroll mot någon form av överdriven användning som Max User Connections, Max Queries Per Hour eller Max Anslutningar per timme.
-
Tillåt specifika databasanvändare att också komma åt andra scheman.
För MySQL, MariaDB och PostgreSQL kan du utföra behörighetsgranskning via informationsschemat genom att fråga grant-, roll- och behörighetsrelaterade tabeller. För MongoDB, använd följande fråga (kräver viewUser-åtgärd för andra databaser):
mongodb> db.getUsers( { usersInfo: { forAllDBs: true } } )ClusterControl ger en bra sammanfattning av de privilegier som tilldelats en databasanvändare. Gå till Hantera -> Schema och användare -> Användare så får du en rapport över användarnas privilegier, tillsammans med de avancerade alternativen som Kräver SSL, Max anslutningar per timme och så vidare.
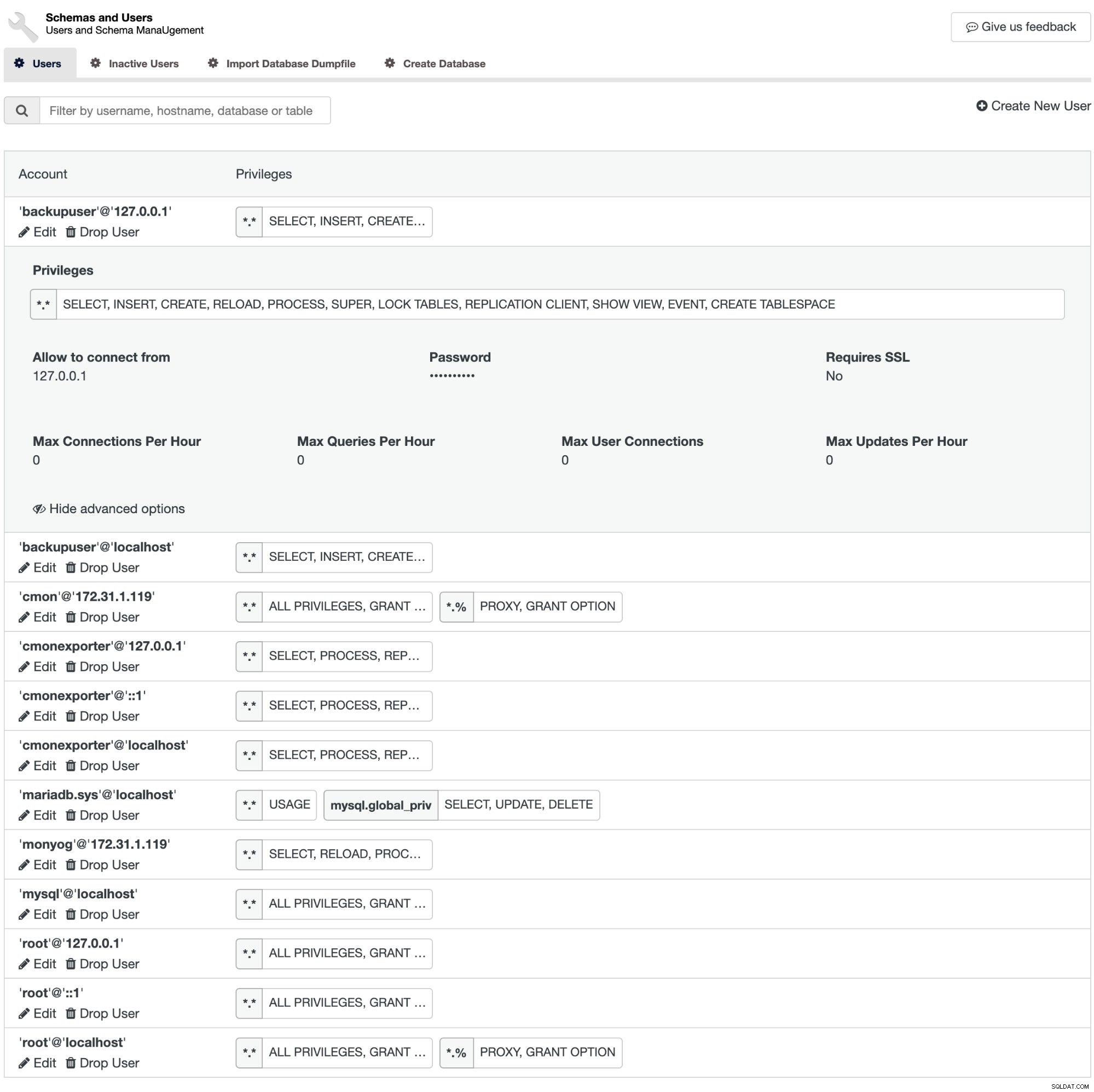
ClusterControl stöder behörighetsrevision för MySQL, MariaDB och PostgreSQL under samma användare gränssnitt.
Revision av schemaobjekt
Schemaobjekt är logiska strukturer skapade av användare. Exempel på schemaobjekt är tabeller, index, vyer, rutiner, händelser, procedurer, funktioner, utlösare och andra. Det är i princip objekt som innehåller data eller kan endast bestå av en definition. Vanligtvis skulle man granska de behörigheter som är associerade med schemaobjekten för att upptäcka dåliga säkerhetsinställningar och förstå relationen och beroenden mellan objekten.
För MySQL och MariaDB finns information_schema och performance_schema som vi kan använda för att i princip granska schemaobjekten. Performance_schema är lite djupgående i instrumenteringen som namnet antyder. Men MySQL innehåller också ett sys-schema sedan version 5.7.7, vilket är en användarvänlig version av performance_schema. Alla dessa databaser är direkt åtkomliga och sökbara av klienterna.
Insticksprogram/tillägg för databasgranskning
Det mest rekommenderade sättet att utföra utlåtandegranskning är att använda ett granskningsplugin eller tillägg, speciellt byggt för den databasteknik som används. MariaDB och Percona har sin egen implementering av Audit-plugin, som skiljer sig lite från MySQL:s Audit-plugin som finns tillgänglig i MySQL Enterprise. Granskningsposter inkluderar information om åtgärden som granskades, användaren som utför åtgärden och datum och tid för åtgärden. Posterna kan lagras i antingen en datalexikon, kallad databasens granskningsspår, eller i operativsystemfiler, kallad en revisionsspår för operativsystemet.
För PostgreSQL finns det pgAudit, en PostgreSQL-tillägg som tillhandahåller detaljerad sessions- och/eller objektgranskningsloggning via PostgreSQLs standardloggningsfunktion. Det är i grunden en förbättrad version av PostgreSQL:s log_statement-funktion med möjligheten att enkelt söka och slå upp infångade data för granskning genom att följa standardgranskningsloggen.
MongoDB Enterprise (betald) och Percona Server för MongoDB (gratis) inkluderar en granskningsmöjlighet för mongod- och mongos-instanser. Med granskning aktiverad kommer servern att generera granskningsmeddelanden som kan loggas in i syslog, konsol eller fil (JSON- eller BSON-format). I de flesta fall är det att föredra att logga till filen i BSON-format, där prestandapåverkan är mindre än JSON. Den här filen innehåller information om olika användarhändelser inklusive autentisering, auktoriseringsfel och så vidare. Se revisionsdokumentationen för detaljer.
Översiktsspår för operativsystem
Det är också viktigt att konfigurera operativsystemets granskningsspår. För Linux skulle folk vanligtvis använda auditd. Auditd är användarutrymmeskomponenten i Linux Auditing System och ansvarig för att skriva revisionsposter till disken. Visning av loggarna görs med verktygen ausearch eller aureport. Konfigurering av revisionsreglerna görs med verktyget auditctl, eller genom att modifiera regelfilerna direkt.
Följande installationssteg är vår vanliga praxis när vi konfigurerar alla typer av servrar för produktionsanvändning:
$ yum -y install audit # apt install auditd python
$ mv /etc/audit/rules.d/audit.rules /etc/audit/rules.d/audit.rules.ori
$ cd /etc/audit/rules.d/
$ wget https://gist.githubusercontent.com/ashraf-s9s/fb1b674e15a5a5b41504faf76a08b4ae/raw/2764bf0e9bf25418bb86e33c13fb80356999d220/audit.rules
$ chmod 640 audit.rules
$ systemctl daemon-reload
$ systemctl start auditd
$ systemctl enable auditd
$ service auditd restartObservera att den sista radens omstart av tjänsten auditd är obligatorisk eftersom granskning inte fungerar riktigt bra när man laddar regler med systemd. Systemd krävs dock fortfarande för att övervaka den granskade tjänsten. Under uppstart läses reglerna i /etc/audit/audit.rules av auditctl. Själva revisionsdemonen har några konfigurationsalternativ som administratören kanske vill anpassa. De finns i filen auditd.conf.
Följande rad är en utdata från en konfigurerad granskningslogg:
$ ausearch -m EXECVE | grep -i 'password' | head -1
type=EXECVE msg=audit(1615377099.934:11838148): argc=7 a0="mysql" a1="-NAB" a2="--user=appdb1" a3="--password=S3cr3tPassw0rdKP" a4="-h127.0.0.1" a5="-P3306" a6=2D6553484F5720474C4F42414C205641524941424C4553205748455245205641524941424C455F4E414D4520494E20282776657273696F6E272C202776657273696F6E5F636F6D6D656E74272C2027646174616469722729Som du kan se av ovanstående är det lätt att hitta ett klartextlösenord för MySQL ("--password=S3cr3tPassw0rdKP") med hjälp av ausearch-verktyget som fångat av auditd. Denna typ av upptäckt och granskning är avgörande för att säkra vår databasinfrastruktur, där ett klartextlösenord är oacceptabelt i en säker miljö.
Sluta tankar
Revisionslogg eller spår är en viktig aspekt som vanligtvis förbises av DevOps-ingenjörer när de hanterar infrastrukturer och system, än mindre databassystemet som är ett mycket viktigt system för att lagra känslig och konfidentiell data. All exponering eller intrång i dina privata data kan vara extremt skadliga för företaget och ingen skulle vilja att det skulle hända i den nuvarande informationsteknologiska eran.