I vår tidigare Hadoop tut o rial , har vi gett dig en detaljerad beskrivning av InputFormat. Nu i den här bloggen kommer vi att täcka Hadoop OutputFormat.
Vi kommer att diskutera vad som är OutputFormat i Hadoop, vad är RecordWritter i MapReduce OutputFormat. Vi kommer också att täcka typerna av OutputFormat i MapReduce.
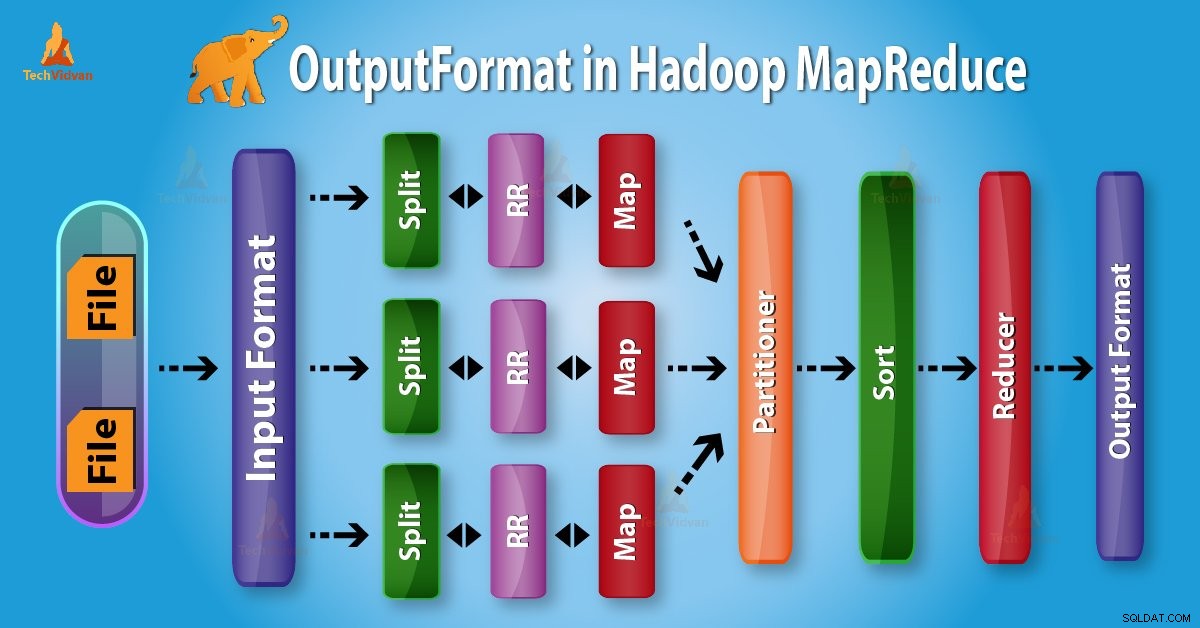
Introduktion till Hadoop OutputFormat
Utdataformat kontrollera utdataspecifikationen för utförande av Map-Reduce-jobbet. Den beskriver hur RecordWriter-implementering används för att skriva utdata till utdatafiler.
Innan vi börjar med OutputFormat, låt oss först lära oss vad som är RecordWriter och vad är RecordWriters arbete i MapReduce?
1. RecordWriter i Hadoop MapReduce
Som vi vet, Reducer tar Mappers mellanutgång som ingång. Sedan kör den en reduceringsfunktion på dem för att generera utdata som återigen är noll eller fler nyckel-värdepar.
Så RecordWriter i MapReduce-jobbkörning skriver dessa utdatanyckel-värdepar från Reducer-fasen till utdatafiler.
2. Hadoop OutputFormat
Ovanifrån är det tydligt att RecordWriter tar utdata från Reducer. Sedan skriver den dessa data till utdatafiler. OutputFormat bestämmer hur dessa utdatanyckel-värdepar skrivs i utdatafiler av RecordWriter.
Funktionerna OutputFormat och InputFormat liknar varandra. OutputFormat-instanser används för att skriva till filer på den lokala disken eller i HDFS. I MapReduce jobbutförande på basis av utdataspecifikation;
- Hadoop MapReduce jobbkontroller att utdatakatalogen inte redan finns.
- OutputFormat i MapReduce-jobbet tillhandahåller RecordWriter-implementeringen som ska användas för att skriva utdatafilerna för jobbet. Sedan lagras utdatafilerna i ett filsystem.
Ramverket använder FileOutputFormat.setOutputPath() metod för att ställa in utdatakatalogen.
Typer av OutputFormat i MapReduce
Det finns olika typer av OutputFormat som är följande:
1. TextOutputFormat
Standard OutputFormat är TextOutputFormat. Den skriver (nyckel, värde) par på enskilda rader med textfiler. Dess nycklar och värden kan vara av vilken typ som helst. Anledningen bakom är att TextOutputFormat gör dem till strängar genom att anropa toString() på dem.
Den separerar nyckel-värdepar med ett tabbtecken. Genom att använda MapReduce.output.textoutputformat.separator egenskap vi kan också ändra den.
KeyValueTextOutputFormat används också för att läsa dessa utdatatextfiler.
2. SequenceFileOutputFormat
Detta OutputFormat skriver sekvensfiler för dess utdata. SequenceFileInputFormat är också mellanformatanvändning mellan MapReduce-jobb. Den serialiserar godtyckliga datatyper till filen.
Och motsvarande SequenceFileInputFormat kommer att deserialisera filen till samma typer. Den presenterar data till nästamappare på samma sätt som den avgavs av den tidigare reduceraren. Statiska metoder styr också komprimeringen.
3. SequenceFileAsBinaryOutputFormat
Det är en annan variant av SequenceFileInputFormat. Den skriver också nycklar och värden till en sekvensfil i binärt format.
4. MapFileOutputFormat
Det är en annan form av FileOutputFormat. Den skriver också utdata som kartfiler. Ramverket lägger till en nyckel i en MapFile i ordning. Så vi måste se till att reduceraren avger nycklar i sorterad ordning.
5. Flera utgångar
Detta format gör det möjligt att skriva data till filer vars namn härrör från utdatanycklarna och värdena.
6. LazyOutputFormat
I MapReduce-jobbkörning skapar FileOutputFormat ibland utdatafiler, även om de är tomma. LazyOutputFormat är också ett omslags OutputFormat.
7. DBOutputFormat
Det är OutputFormat för att skriva till relationsdatabaser och HBase. Det här formatet skickar också reduceringen till en SQL-tabell. Den accepterar också nyckel-värdepar. I detta har nyckeln en typ som utökar DBwritable.
Slutsats
Därför används olika OutputFormat efter behov. Hoppas du tycker att den här bloggen är till hjälp. Om du har några frågor om Hadoop OutputFormat, lämna gärna en kommentar i en kommentarsruta. Vi löser dem gärna.