I vår tidigare Hadoop bloggar som vi har studerat varje komponent i Hadoop MapReduce processen i detalj. I detta kommer vi att diskutera det mycket intressanta ämnet, dvs Map Only-jobbet i Hadoop.
Först tar vi en kort introduktion av kartan och Minska fas i Hadoop Mapreduce, sedan diskuterar vi vad som är Map only-jobbet i Hadoop MapReduce.
Till sist kommer vi också att diskutera fördelarna och nackdelarna med Hadoop Map Only-jobbet i denna handledning.
Vad är Hadoop Map Only Job?
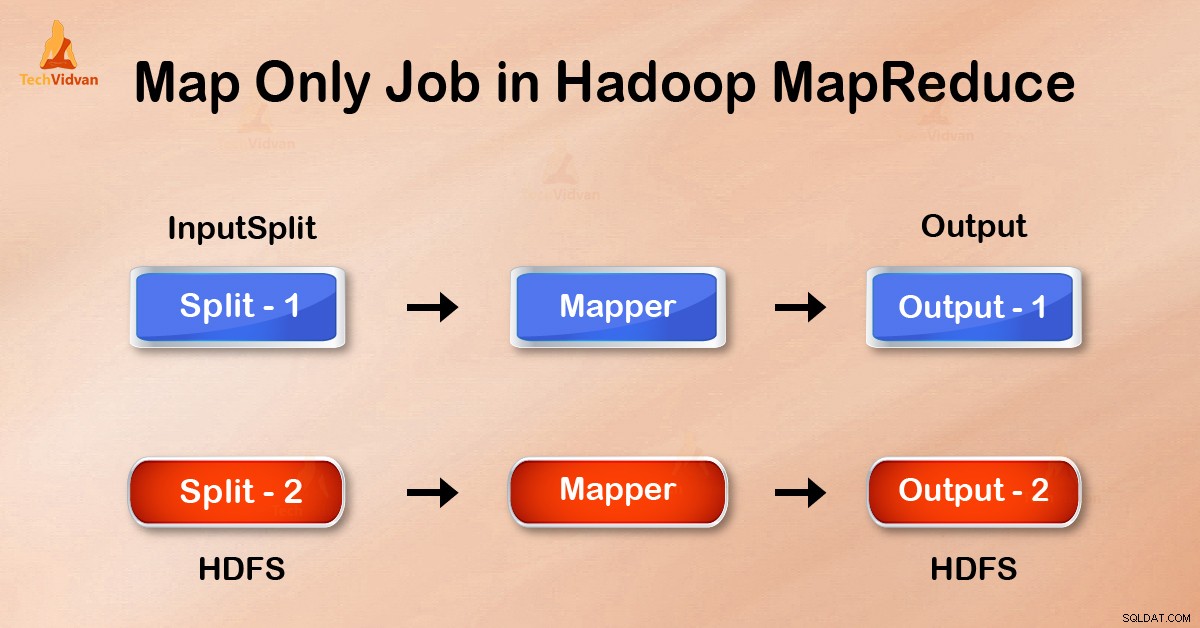
Enbart kartjobb i Hadoop är den process där mapper gör alla uppgifter. Ingen uppgift utförs av reduceraren . Mappers utdata är den slutliga utdata.
MapReduce är databearbetningsskiktet i Hadoop. Den behandlar stora strukturerade och ostrukturerade data lagrade i HDFS . MapReduce bearbetar också en enorm mängd data parallellt.
Den gör detta genom att dela upp jobbet (inlämnat jobb) i en uppsättning självständiga uppgifter (underjobb). I Hadoop fungerar MapReduce genom att dela upp bearbetningen i faser:Karta och Minska .
- Karta: Det är den första fasen av bearbetningen, där vi specificerar all komplex logikkod. Den tar en uppsättning data och konverterar till en annan uppsättning data. Den delar upp varje enskilt element i tupler (nyckel-värdepar ).
- Minska: Det är den andra fasen av bearbetningen. Här specificerar vi lättviktsbearbetning som aggregering/summering. Den tar utdata från kartan som indata. Sedan kombinerar den dessa tupler baserat på nyckeln.
Från detta exempel på ordräkning kan vi säga att det finns två uppsättningar parallella processer, kartlägga och minska. I kartprocessen delas den första ingången för att fördela arbetet mellan alla kartnoder som visas ovan.
Ramverket identifierar sedan varje ord och mappar till siffran 1. Det skapar alltså par som kallas tupler (nyckel-värde) par.
I den första kartläggaren skickar den tre ord lejon, tiger och floden. Således producerar den 3 nyckel-värdepar som nodens utdata. Tre olika nycklar och värde satt till 1 och samma process upprepas för alla noder.
Sedan skickar den dessa tupler till reduktionsnoderna. Partitioner utför blandning så att alla tupler med samma nyckel går till samma nod.
I reduceringsprocessen är det som i princip händer en sammanställning av värden eller snarare en operation på värden som delar samma nyckel.
Låt oss nu överväga ett scenario där vi bara behöver utföra operationen. Vi behöver ingen aggregering, i sådana fall föredrar vi "Endast kartjobb ’.
I Map-Only-jobbet utför kartan alla uppgifter med sin InputSplit . Reducer gör inget jobb. Mappers utgång är den slutliga utgången.
Hur undviker man Reduce Phase i MapReduce?
Genom att ställa in job.setNumreduceTasks(0) i konfigurationen i en drivrutin kan vi undvika reducera fas. Detta kommer att göra ett antal reducerare till 0 . Den enda kartläggaren kommer alltså att göra hela uppgiften.
Fördelar med Map only-jobb i Hadoop
I MapReduce jobbutförande mellan kart- och reduceringsfaser finns nyckel-, sorterings- och shufflefas. Blandar – sortering ansvarar för att sortera nycklarna i stigande ordning. Gruppera sedan värden baserat på samma nycklar. Denna fas är mycket dyr.
Om reduceringsfasen inte krävs bör vi undvika det. Eftersom att undvika reduceringsfas skulle även sorterings- och blandningsfasen elimineras. Därför kommer detta också att spara nätverksstockning.
Anledningen är att vid shuffling reser en utdata från mapparen för att reducera. Och när datastorleken är enorm, måste stor data föras till reduceringen.
Utdata från mapparen skrivs till lokal disk innan den skickas för att reducera. Men i enbart kartjobb skrivs denna utdata direkt till HDFS. Detta sparar ytterligare tid och minskar kostnaderna.
Slutsats
Därför har vi sett att jobbet endast på karta minskar överbelastningen av nätverket genom att undvika att blanda, sortera och minska fas. Map ensam tar hand om den övergripande bearbetningen och producerar resultatet. GENOM att använda job.setNumreduceTasks(0) detta uppnås.
Jag hoppas att du har förstått Hadoop Map Only-jobbet och dess betydelse eftersom vi har täckt allt om Map Only-jobbet i Hadoop. Men om du har några frågor så kan du dela det med oss i kommentarsfältet.