Ivrig att lära dig allt om Hadoop-klustret?
Hadoop är ett mjukvaruramverk för att analysera och lagra stora mängder data över kluster av råvaruhårdvara. I den här artikeln kommer vi att studera ett Hadoop-kluster.
Låt oss först börja med en introduktion till Cluster.
Vad är ett kluster?
Ett kluster är en samling noder. Noder är inget annat än en anslutningspunkt/korsningspunkt inom ett nätverk.
Ett datorkluster är en samling datorer anslutna till ett nätverk, som kan kommunicera med varandra och fungerar som ett enda system.
Vad är Hadoop Cluster?
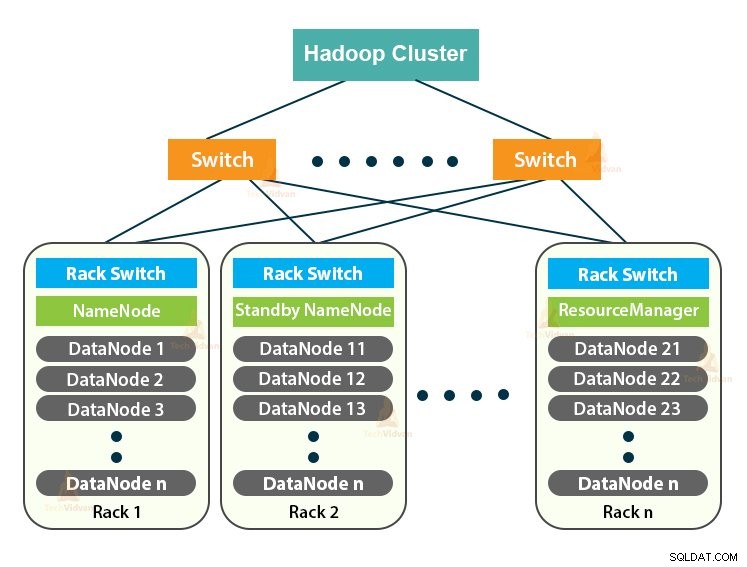
Hadoop Cluster är bara ett datorkluster som används för att hantera en stor mängd data på ett distribuerat sätt.
Det är ett beräkningskluster designat för att lagra och analysera enorma mängder ostrukturerad eller strukturerad data i en distribuerad datormiljö.
Hadoop-kluster är också kända som Shared-nothing-system eftersom ingenting delas mellan noderna i klustret förutom nätverkets bandbredd. Detta minskar bearbetningsfördröjningen.
Sålunda, när det finns ett behov av att bearbeta frågor om den enorma mängden data, minimeras den klusteromfattande latensen.
Låt oss nu studera arkitekturen i Hadoop Cluster.
Architecture of Hadoop Cluster
Hadoop-klustret följer en master-slav-arkitektur. Den består av masternoden, slavnoderna och klientnoden.
1. Master i Hadoop Cluster
Master in the Hadoop Cluster är en högeffektsmaskin med hög konfiguration av minne och CPU. De två demonerna som är NameNode och ResourceManager körs på masternoden.
a. Funktioner för NameNode
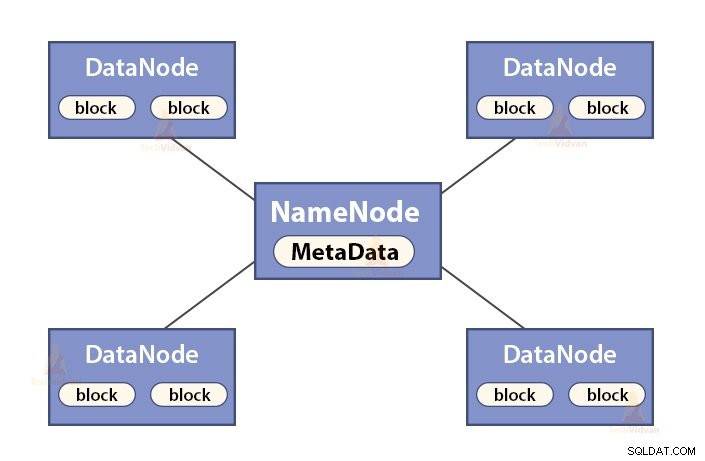
NameNode är en huvudnod i Hadoop HDFS . NameNode hanterar filsystemets namnutrymme. Den lagrar filsystemets metadata i minnet för snabb hämtning. Därför bör den konfigureras på avancerade maskiner.
Funktionerna för NameNode är:
- Hanterar filsystemets namnutrymme
- Lagrar metadata om block av en fil, blockerar plats, behörigheter etc.
- Den kör filsystemets namnområdesoperationer som att öppna, stänga, byta namn på filer och kataloger, etc.
- Den underhåller och hanterar DataNode.
b. Resurshanterarens funktioner
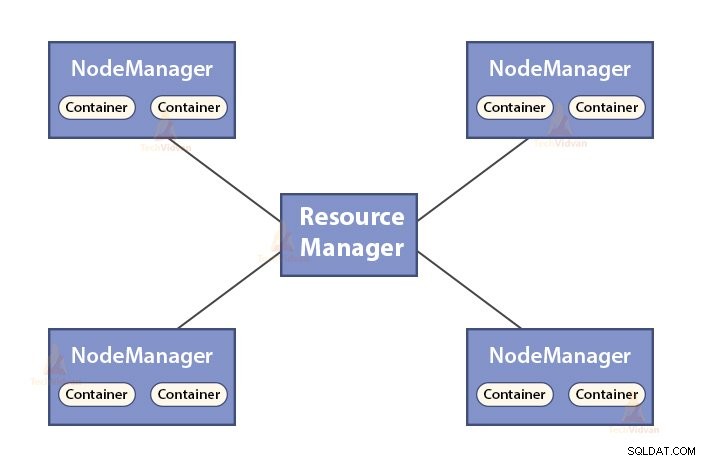
- ResourceManager är huvuddemonen för YARN.
- ResourceManager bestämmer resurserna mellan alla applikationer i systemet.
- Den håller reda på levande och döda noder i klustret.
2. Slavar i Hadoop-klustret
Slavar i Hadoop-klustret är billig råvaruhårdvara. De två demonerna som är DataNodes och YARN NodeManagers körs på slavnoderna.
a. DataNodes funktioner
- DataNodes lagrar de faktiska affärsdata. Den lagrar blocken i en fil.
- Den utför blockskapande, radering, replikering baserat på instruktionerna från NameNode.
- DataNode ansvarar för att betjäna klientens läs-/skrivoperationer.
b. Funktioner i NodeManager
- NodeManager är slavdemonen för YARN.
- Det är ansvarigt för behållare, övervakar deras resursanvändning (som CPU, disk, minne, nätverk) och rapporterar detsamma till ResourceManager.
- NodeManager kontrollerar även tillståndet för den nod som den körs på.
3. Klientnod i Hadoop Cluster
Klientnoder i Hadoop är varken masternod eller slavnoder. De har Hadoop installerat på sig med alla klusterinställningar.
Funktioner för klientnoder
- Kundnoder laddar data till Hadoop-klustret.
- Den skickar in MapReduce-jobb, som beskriver hur denna data ska behandlas.
- Hämta resultatet av jobbet efter att bearbetningen är klar.
Vi kan skala ut Hadoop-klustret genom att lägga till fler noder. Detta gör Hadoop linjärt skalbar . Med varje nodtillägg får vi en motsvarande ökning i genomströmning. Om vi har 'n'-noder, ger det (1/n) ytterligare beräkningskraft att lägga till 1 nod.
Single Node Hadoop Cluster VS Multi-Node Hadoop Cluster
1. Single Node Hadoop Cluster
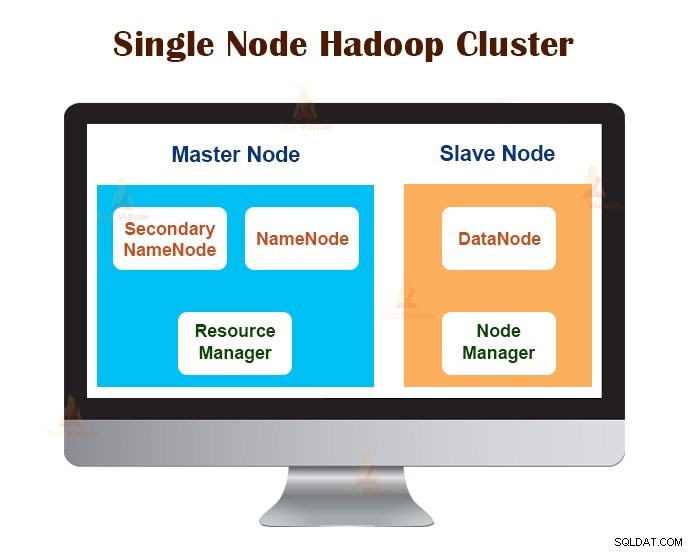
Single Node Hadoop Cluster distribueras på en enda dator. Alla demoner som NameNode, DataNode, ResourceManager, NodeManager körs på samma maskin/värd.
I en klusterinställning med en nod körs allt på en enda JVM-instans. Hadoop-användaren behövde inte göra några konfigurationsinställningar förutom att ställa in variabeln JAVA_HOME.
Standardreplikeringsfaktorn för ett enstaka nod Hadoop-kluster är alltid 1.
2. Multi-Node Hadoop Cluster
Multi-Node Hadoop Cluster distribueras på flera maskiner. Alla demoner i Hadoop-klustret med flera noder är uppe och körs på olika maskiner/värdar.
Ett Hadoop-kluster med flera noder följer master-slave-arkitekturen. Demonerna Namenode och ResourceManager körs på masternoderna, som är avancerade datormaskiner.
Demonerna DataNodes och NodeManagers körs på slavnoderna (arbetsnoder), som är billig råvaruhårdvara.
I Hadoop-klustret med flera noder kan slavmaskiner finnas på vilken plats som helst, oavsett platsen för den fysiska platsen för masterservern.
Kommunikationsprotokoll som används i Hadoop Cluster
HDFS-kommunikationsprotokollen är lagrade på toppen av TCP/IP-protokollet. En klient upprättar en anslutning till NameNode via den konfigurerbara TCP-porten på NameNode-maskinen.
Hadoop-klustret upprättar en anslutning till klienten genom ClientProtocol. Dessutom pratar DataNode med NameNode med hjälp av DataNode Protocol.
RPC-abstraktionen (Remote Procedure Call) omsluter Client Protocol och DataNode-protokoll. Genom designen initierar NameNode inga RPC:er. Den svarar bara på RPC-förfrågningar som utfärdas av klienter eller DataNodes.
Bästa metoder för att bygga Hadoop-kluster
Prestandan hos ett Hadoop-kluster beror på olika faktorer baserade på de väldimensionerade hårdvaruresurserna som använder CPU, minne, nätverksbandbredd, hårddisk och andra välkonfigurerade mjukvarulager.
Att bygga ett Hadoop-kluster är ett icke-trivialt jobb. Det kräver övervägande av olika faktorer som att välja rätt hårdvara, storleksanpassa Hadoop-klustren och konfigurera Hadoop-klustret.
Låt oss nu se var och en i detalj.
1. Att välja rätt hårdvara för Hadoop Cluster
Många organisationer befinner sig i en svår situation när de konfigurerar Hadoop-infrastrukturen eftersom de inte är medvetna om vilken typ av maskiner de behöver köpa för att sätta upp en optimerad Hadoop-miljö och den idealiska konfigurationen de måste använda.
För att välja rätt hårdvara för Hadoop-klustret måste man överväga följande punkter:
- Mängden data som klustret kommer att hantera.
- Typen av arbetsbelastningar som klustret kommer att hantera (CPU-bunden, I/O-bunden).
- Datalagringsmetodik som databehållare, datakomprimeringstekniker som används, om några.
- En datalagringspolicy, det vill säga hur länge vi vill behålla data innan vi rensar bort den.
2. Dimensionera Hadoop-klustret
För att bestämma storleken på Hadoop-klustret bör datavolymen som Hadoop-användarna kommer att bearbeta på Hadoop-klustret vara en viktig faktor.
Genom att känna till mängden data som ska bearbetas, hjälper det att bestämma hur många noder som kommer att krävas för att bearbeta data effektivt och minneskapacitet som krävs för varje nod. Det bör finnas en balans mellan prestandan och kostnaden för den godkända hårdvaran.
3. Konfigurera Hadoop Cluster
Att hitta den perfekta konfigurationen för Hadoop Cluster är inte ett lätt jobb. Hadoop-ramverket måste anpassas till det kluster det körs och även till jobbet.
Det bästa sättet att bestämma den idealiska konfigurationen för Hadoop-klustret är att köra Hadoop-jobben med standardkonfigurationen tillgänglig för att få en baslinje. Efter det kan vi analysera jobbhistorikens loggfiler för att se om det finns någon resurssvaghet eller om tiden det tar att köra jobben är längre än förväntat.
Om det är så ändrar du konfigurationen. Genom att upprepa samma process kan Hadoop Cluster-konfigurationen justeras som bäst passar affärskraven.
Hadoop-klustrets prestanda beror i hög grad på resurserna som tilldelats demonerna. För små till medelstora datakontexter reserverar Hadoop en CPU-kärna på varje DataNode, medan den för långa datauppsättningar allokerar 2 CPU-kärnor på varje DataNode för HDFS- och MapReduce-demoner.
Hadoop Cluster Management
När Hadoop-klustret används i produktionen är det uppenbart att det bör skalas längs alla dimensioner som är volym, variation och hastighet.
Olika funktioner som det borde ha för att bli produktionsklar är – dygnet runt tillgänglighet, robust, hanterbarhet och prestanda. Hadoop Cluster management är huvuddelen av big data-initiativet.
Det bästa verktyget för Hadoop Cluster Management bör ha följande funktioner:-
- Det måste säkerställa 24×7 hög tillgänglighet, resursförsörjning, mångsidig säkerhet, hantering av arbetsbelastning, hälsoövervakning, prestandaoptimering. Dessutom måste den tillhandahålla jobbschemaläggning, policyhantering, säkerhetskopiering och återställning över en eller flera noder.
- Implementera redundant HDFS NameNode med hög tillgänglighet med lastbalansering, hot standby, omsynkronisering och auto-failover.
- Tillämpa policybaserade kontroller som förhindrar alla program från att ta en oproportionerligt stor andel av resurserna på ett redan maxat Hadoop-kluster.
- Utföra regressionstestning för att hantera distributionen av alla programvarulager över Hadoop-kluster. Detta för att säkerställa att alla jobb eller data inte skulle krascha eller stöta på några flaskhalsar i den dagliga verksamheten.
Fördelar med Hadoop Cluster
De olika fördelarna med Hadoop-klustret är:
1. Skalbar
Hadoop-kluster är skalbara. Vi kan lägga till valfritt antal noder till Hadoop-klustret utan driftstopp och utan några extra ansträngningar. Med varje nodtillägg får vi en motsvarande ökning av genomströmningen.
2. Robusthet
Hadoop Cluster är mest känt för sin pålitliga lagring. Den kan lagra data på ett tillförlitligt sätt, även i fall som DataNode-fel, NameNode-fel och nätverkspartition. DataNoden skickar regelbundet en hjärtslagssignal till NameNode.
I nätverkspartitionen lösgörs en uppsättning DataNodes från NameNode på grund av vilken NameNode inte tar emot något hjärtslag från dessa DataNodes. NameNode betraktar sedan dessa DataNodes som döda och vidarebefordrar ingen I/O-förfrågan till dem.
Replikeringsfaktorn för blocken lagrade i dessa DataNodes faller också under deras angivna värde. Som ett resultat initierar NameNode replikeringen av dessa block och återställer sig från felet.
3. Ombalansering av kluster
Hadoop HDFS-arkitekturen utför automatiskt klusterombalansering. Om det lediga utrymmet i DataNode faller under tröskelnivån, flyttar HDFS-arkitekturen automatiskt vissa data till andra DataNode där tillräckligt med utrymme finns tillgängligt.
4. Kostnadseffektivt
Att ställa in Hadoop-klustret är kostnadseffektivt eftersom det innehåller billig råvaruhårdvara. Alla organisationer kan enkelt skapa ett kraftfullt Hadoop-kluster utan att spendera mycket på dyr serverhårdvara.
Hadoop Clusters med sin distribuerade lagringstopologi övervinner också begränsningarna i det traditionella systemet. Det begränsade lagringsutrymmet kan utökas bara genom att lägga till ytterligare billiga lagringsenheter till systemet.
5. Flexibel
Hadoop-kluster är mycket flexibla eftersom de kan bearbeta data av vilken typ som helst, antingen strukturerad, semi-strukturerad eller ostrukturerad och av alla storlekar från Gigabyte till Petabyte.
6. Snabb bearbetning
I Hadoop Cluster kan data behandlas parallellt i en distribuerad miljö. Detta ger Hadoop snabba databehandlingsmöjligheter. Hadoop-kluster kan bearbeta Terabyte eller Petabyte av data inom en bråkdel av sekunder.
7. Dataintegritet
För att kontrollera eventuella korruptioner i datablock på grund av buggymjukvara, fel i en lagringsenhet, etc. implementerar Hadoop Cluster kontrollsumma på varje block i filen. Om det upptäcker att något block är skadat söker det efter en annan DataNode som innehåller repliken av samma block. Således upprätthåller Hadoop-klustret dataintegritet.
Sammanfattning
Efter att ha läst den här artikeln kan vi säga att Hadoop Cluster är ett speciellt beräkningskluster designat för att analysera och lagra big data. Hadoop Cluster följer master-slave-arkitekturen.
Masternoden är den avancerade datormaskinen och slavnoderna är maskiner med normal CPU- och minneskonfiguration. Vi har också sett att Hadoop Cluster kan ställas in på en enda maskin som kallas single-node Hadoop Cluster eller på flera maskiner som kallas multi-node Hadoop Cluster.
I den här artikeln hade vi också täckt de bästa metoderna som ska följas när vi bygger ett Hadoop-kluster. Vi hade också sett många fördelar med Hadoop Cluster, inklusive skalbarhet, flexibilitet, kostnadseffektivitet, etc.