Databaser måste fungera optimalt, men det är inte så lätt. Databasen INFORMATION SCHEMA kan vara ditt hemliga vapen i kriget om databasoptimering.
Vi är vana vid att skapa databaser med ett grafiskt gränssnitt eller en serie SQL-kommandon. Det är helt okej, men det är också bra att förstå lite om vad som händer i bakgrunden. Detta är viktigt för att skapa, underhålla och optimera en databas, och det är också ett bra sätt att spåra förändringar som sker "bakom kulisserna".
I den här artikeln kommer vi att titta på en handfull SQL-frågor som kan hjälpa dig att titta på hur en MySQL-databas fungerar.
INFORMATION_SCHEMA-databasen
Vi har redan diskuterat INFORMATION_SCHEMA databas i den här artikeln. Om du inte redan har läst den, skulle jag definitivt föreslå att du gör det innan du fortsätter.
Om du behöver en uppdatering av INFORMATION_SCHEMA databas – eller om du bestämmer dig för att inte läsa den första artikeln – här är några grundläggande fakta du behöver veta:
INFORMATION_SCHEMAdatabasen är en del av ANSI-standarden. Vi kommer att arbeta med MySQL, men andra RDBMS har sina varianter. Du kan hitta versioner för H2 Database, HSQLDB, MariaDB, Microsoft SQL Server och PostgreSQL.- Detta är databasen som håller reda på alla andra databaser på servern; vi hittar beskrivningar av alla objekt här.
- Som vilken annan databas som helst,
INFORMATION_SCHEMAdatabasen innehåller ett antal relaterade tabeller och information om olika objekt. - Du kan fråga den här databasen med SQL och använda resultaten för att:
- Övervaka databasstatus och prestanda, och
- Generera kod automatiskt baserat på frågeresultat.
Låt oss nu gå vidare till att fråga efter INFORMATION_SCHEMA-databasen. Vi börjar med att titta på datamodellen vi ska använda.
Datamodellen
Modellen vi använder i den här artikeln visas nedan.
Detta är en förenklad modell som låter oss lagra information om klasser, instruktörer, elever och andra relaterade detaljer. Låt oss kort gå igenom tabellerna.
Vi lagrar listan över instruktörer i lecturer tabell. För varje föreläsare kommer vi att spela in ett first_name och ett last_name .
class Tabellen listar alla klasser vi har i vår skola. För varje post i den här tabellen lagrar vi class_name , föreläsarens ID, ett planerat start_date och end_date , och eventuella ytterligare class_details . För enkelhetens skull antar jag att vi bara har en föreläsare per klass.
Lektionerna är vanligtvis organiserade som en serie föreläsningar. De kräver vanligtvis ett eller flera prov. Vi lagrar listor över relaterade föreläsningar och prov i lecture och exam tabeller. Båda kommer att ha ID för den relaterade klassen och den förväntade start_time och end_time .
Nu behöver vi elever till våra klasser. En lista över alla elever lagras i student tabell. Återigen lagrar vi bara first_name och last_name av varje elev.
Det sista vi behöver göra är att spåra elevernas aktiviteter. Vi lagrar en lista över varje klass som en elev registrerat sig för, elevens närvarorekord och deras provresultat. Var och en av de återstående tre tabellerna – on_class , on_lecture och on_exam – kommer att ha en referens till eleven och en referens till lämplig tabell. Endast on_exam tabellen kommer att ha ett extra värde:betyg.
Ja, den här modellen är väldigt enkel. Vi skulle kunna lägga till många andra detaljer om studenter, föreläsare och klasser. Vi kan lagra historiska värden när poster uppdateras eller raderas. Ändå kommer denna modell att räcka för den här artikeln.
Skapa en databas
Vi är redo att skapa en databas på vår lokala server och undersöka vad som händer inuti den. Vi exporterar modellen (i Vertabelo) med "Generate SQL script " knapp.
Sedan skapar vi en databas på MySQL Server-instansen. Jag kallade min databas för "classes_and_students ”.
Nästa sak vi behöver göra är att köra ett tidigare genererat SQL-skript.
Nu har vi databasen med alla dess objekt (tabeller, primära och främmande nycklar, alternativa nycklar).
Databasstorlek
När skriptet har körts, data om "classes and students databasen lagras i INFORMATION_SCHEMA databas. Dessa data finns i många olika tabeller. Jag kommer inte att lista dem alla igen här; det gjorde vi i föregående artikel.
Låt oss se hur vi kan använda standard SQL på denna databas. Jag börjar med en mycket viktig fråga:
SET @table_schema = "classes_and_students";
SELECT
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) AS "DB Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)"
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema;
Vi frågar bara efter INFORMATION_SCHEMA.TABLES tabell här. Den här tabellen borde ge oss mer än tillräckligt med information om alla bord på servern. Observera att jag endast har filtrerat tabeller från "classes_and_students " databas med SET variabel på första raden och senare med detta värde i frågan. De flesta tabeller innehåller kolumnerna TABLE_NAME och TABLE_SCHEMA , som anger tabellen och schemat/databasen dessa data tillhör.
Denna fråga kommer att returnera den aktuella storleken på vår databas och det lediga utrymme som reserverats för vår databas. Här är det faktiska resultatet:

Som förväntat är storleken på vår tomma databas mindre än 1 MB, och det reserverade lediga utrymmet är mycket större.
Tabellstorlekar och egenskaper
Nästa intressanta sak att göra skulle vara att titta på storlekarna på tabellerna i vår databas. För att göra det använder vi följande fråga:
SET @table_schema = "classes_and_students";
SELECT
INFORMATION_SCHEMA.TABLES.TABLE_NAME,
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) "Table Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)",
MAX( INFORMATION_SCHEMA.TABLES.TABLE_ROWS) AS table_rows_number,
MAX( INFORMATION_SCHEMA.TABLES.AUTO_INCREMENT) AS auto_increment_value
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema
GROUP BY INFORMATION_SCHEMA.TABLES.TABLE_NAME
ORDER BY 2 DESC;
Frågan är nästan identisk med den föregående, med ett undantag:resultatet grupperas på tabellnivå.
Här är en bild av resultatet som returneras av denna fråga:
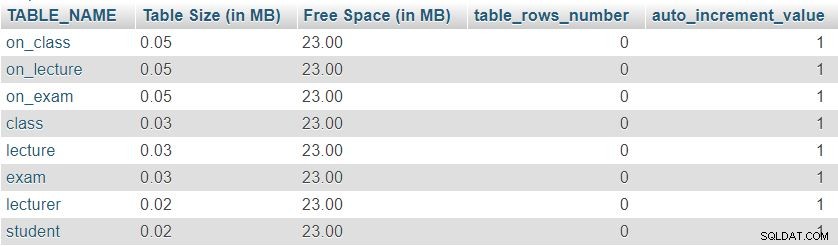
Först kan vi lägga märke till att alla åtta tabeller har en minimal "Tabellstorlek" reserverad för tabelldefinition, som inkluderar kolumner, primärnyckel och index. "Fritt utrymme" är lika fördelat mellan alla tabeller.
Vi kan också se antalet rader för närvarande i varje tabell och det aktuella värdet för auto_increment egendom för varje bord. Eftersom alla tabeller är helt tomma har vi inga data och auto_increment är satt till 1 (ett värde som kommer att tilldelas nästa infogade rad).
Primära nycklar
Varje tabell bör ha ett primärt nyckelvärde definierat, så det är klokt att kontrollera om detta är sant för vår databas. Ett sätt att göra detta är att sammanfoga en lista över alla tabeller med en lista med begränsningar. Detta borde ge oss den information vi behöver.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
COUNT(*) AS PRI_number
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN (
SELECT
INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA,
INFORMATION_SCHEMA.COLUMNS.TABLE_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.COLUMNS.COLUMN_KEY = 'PRI'
) col
ON tab.TABLE_SCHEMA = col.TABLE_SCHEMA
AND tab.TABLE_NAME = col.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema
GROUP BY
tab.TABLE_NAME;
_NAME; Vi har också använt INFORMATION_SCHEMA.COLUMNS tabellen i den här frågan. Medan den första delen av frågan helt enkelt returnerar alla tabeller i databasen, kommer den andra delen (efter LEFT JOIN ) kommer att räkna antalet PRI i dessa tabeller. Vi använde LEFT JOIN eftersom vi vill se om en tabell har 0 PRI i COLUMNS bord.
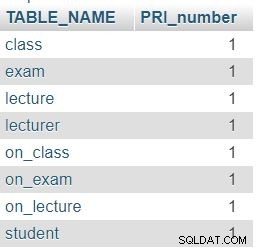
Som förväntat innehåller varje tabell i vår databas exakt en kolumn med primärnyckel (PRI).
"öar"?
"Öar" är tabeller som är helt separerade från resten av modellen. De inträffar när en tabell inte innehåller några främmande nycklar och inte hänvisas till i någon annan tabell. Detta borde verkligen inte inträffa om det inte finns en riktigt bra anledning, t.ex. när tabeller innehåller parametrar eller lagrar resultat eller rapporter i modellen.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
(CASE WHEN f1.number_referenced IS NULL THEN 0 ELSE f1.number_referenced END) AS number_referenced,
(CASE WHEN f2.number_referencing IS NULL THEN 0 ELSE f2.number_referencing END) AS number_referencing
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN
-- # table was used as a reference
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME,
COUNT(*) AS number_referenced
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME
) f1
ON tab.TABLE_SCHEMA = f1.REFERENCED_TABLE_SCHEMA
AND tab.TABLE_NAME = f1.REFERENCED_TABLE_NAME
LEFT JOIN
-- # of references in the table
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME,
COUNT(*) AS number_referencing
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME IS NOT NULL
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME
) f2
ON tab.TABLE_SCHEMA = f2.TABLE_SCHEMA
AND tab.TABLE_NAME = f2.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema;
Vad är tanken bakom den här frågan? Tja, vi använder INFORMATION_SCHEMA.KEY_COLUMN_USAGE tabell för att testa om någon kolumn i tabellen är en referens till en annan tabell eller om någon kolumn används som referens i någon annan tabell. Den första delen av frågan väljer alla tabeller. Efter den första LEFT JOIN, räknar vi antalet gånger en kolumn från denna tabell användes som referens. Efter den andra LEFT JOIN, räknar vi antalet gånger en kolumn från den här tabellen refererade till någon annan tabell.
Resultatet som returneras är:
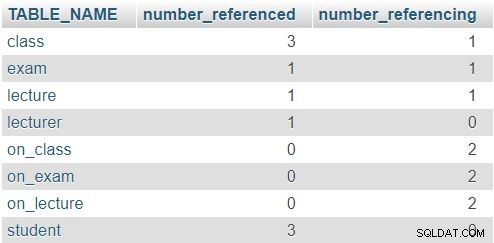
På raden för class tabell, siffrorna 3 och 1 indikerar att denna tabell refererades tre gånger (i lecture , exam och on_class tabeller) och att den innehåller ett attribut som refererar till en annan tabell (lecturer_id ). De andra tabellerna följer ett liknande mönster, även om de faktiska siffrorna naturligtvis kommer att vara annorlunda. Regeln här är att ingen rad ska ha 0 i båda kolumnerna.
Lägga till rader
Hittills har allt gått som förväntat. Vi har framgångsrikt importerat vår datamodell från Vertabelo till den lokala MySQL-servern. Alla tabeller innehåller nycklar, precis som vi vill att de ska, och alla tabeller är relaterade till varandra – det finns inga "öar" i vår modell.
Nu kommer vi att infoga några rader i våra tabeller och använda de tidigare visade frågorna för att spåra ändringarna i vår databas.
Efter att ha lagt till 1 000 rader i föreläsartabellen kör vi frågan igen från "Table Sizes and Properties " sektion. Det kommer att returnera följande resultat:
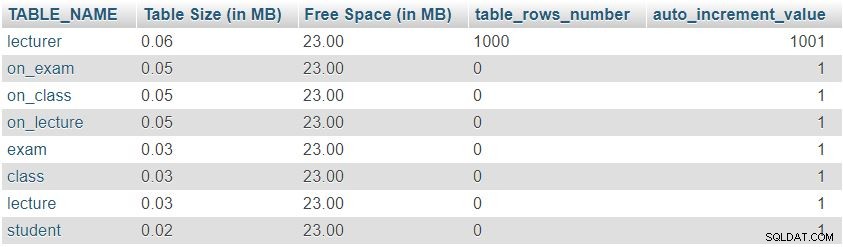
Vi kan lätt lägga märke till att antalet rader och auto_increment-värden har ändrats som förväntat, men det var ingen signifikant förändring i tabellstorlek.
Detta var bara ett testexempel; i verkliga situationer skulle vi märka betydande förändringar. Antalet rader kommer att förändras drastiskt i tabeller som fylls i av användare eller automatiserade processer (dvs tabeller som inte är ordböcker). Att kontrollera storleken på och värdena i sådana tabeller är ett mycket bra sätt att snabbt hitta och korrigera oönskat beteende.
Vill du dela?
Att arbeta med databaser är en ständig strävan efter optimal prestanda. För att bli mer framgångsrik i den strävan bör du använda alla tillgängliga verktyg. Idag har vi sett några frågor som är användbara i vår kamp för bättre prestanda. Har du hittat något annat användbart? Har du spelat med INFORMATION_SCHEMA databas tidigare? Dela din upplevelse i kommentarerna nedan.