Den här bloggen är den andra delen av Implementing a Multi-Datacenter Setup for PostgreSQL. I det här slaget kommer vi att visa hur man distribuerar PostgreSQL i den här typen av miljö och hur man failover i händelse av masterfel med ClusterControls automatiska återställningsfunktion.
Vid det här tillfället antar vi att du har anslutning mellan datacentren (som vi såg i den första delen av denna blogg) och att du har de nödvändiga servrarna för denna uppgift (som vi också nämnde i föregående del).
Distribuera ett PostgreSQL-kluster
Vi kommer att använda ClusterControl för den här uppgiften, så vi antar att du har den installerad (den kan installeras på samma Load Balancer-server, men om du kan använda en annan ännu bättre).
Gå till din ClusterControl-server och välj alternativet "Distribuera". Om du redan har en PostgreSQL-instans igång, måste du välja "Importera befintlig server/databas" istället.
När du väljer PostgreSQL måste du ange Användare, Nyckel eller Lösenord och port till anslut med SSH till våra PostgreSQL-värdar. Du behöver också namnet på ditt nya kluster och om du vill att ClusterControl ska installera motsvarande programvara och konfigurationer åt dig.
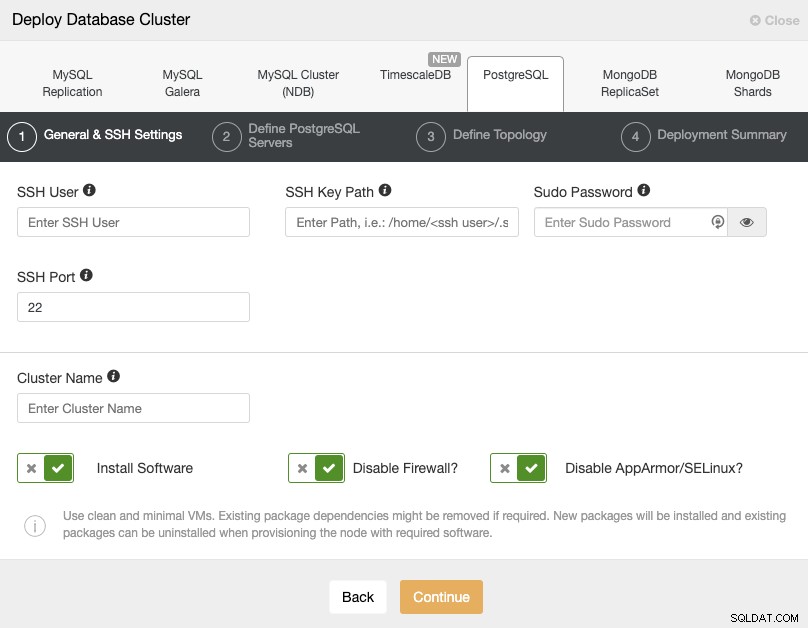
Kontrollera användarkraven för ClusterControl för denna uppgift här, men om du följt förra bloggen bör du använda "fjärranvändaren" här och rätt SSH-port (som vi nämnde, rekommenderas att använda en annan om du använder den offentliga IP-adressen för att komma åt den istället för en VPN).
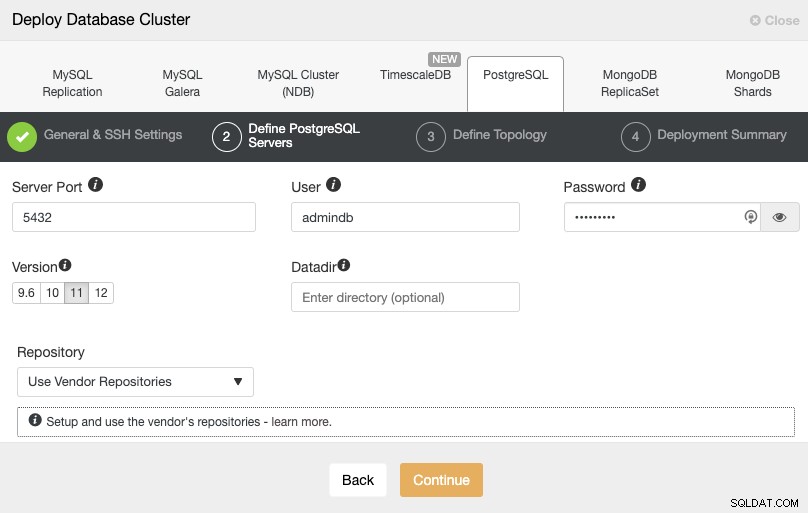
När du har ställt in SSH-åtkomstinformationen måste du definiera databasanvändaren, version och datadir (valfritt). Du kan också ange vilket förråd som ska användas. I nästa steg måste du lägga till dina servrar i klustret du ska skapa.
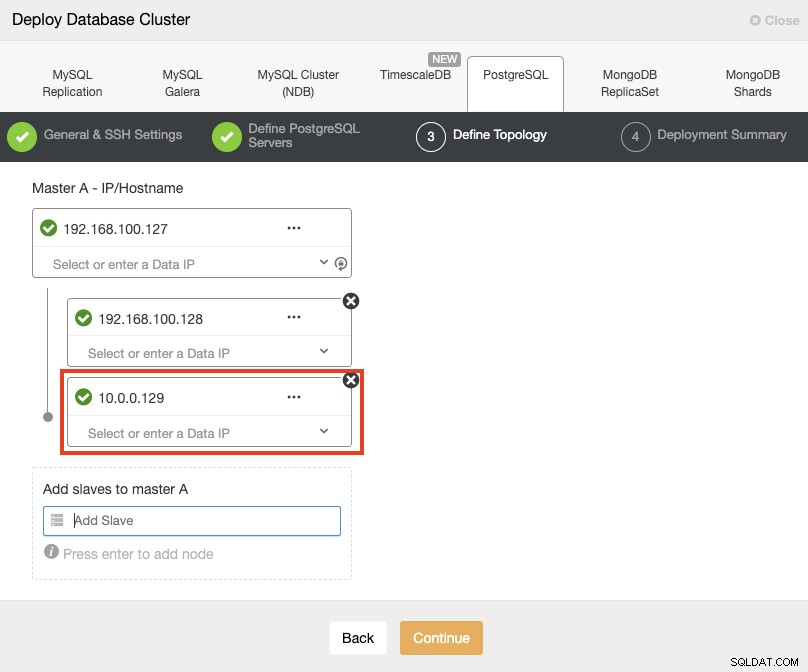
När du lägger till dina servrar kan du ange IP eller värdnamn. I den här delen kommer du att använda de offentliga IP-adresserna för dina servrar, och som du kan se i den röda rutan använder jag ett annat nätverk för den andra standbynoden. ClusterControl har inga begränsningar för nätverket som ska användas. Det enda kravet för detta är att ha SSH-åtkomst till noden.
Så efter vårt tidigare exempel bör dessa IP-adresser vara:
Primary Node: 35.166.37.12
Standby 1 Node: 35.166.37.13
Standby 2 Node: 18.197.23.14 (red box)I det sista steget kan du välja om din replikering ska vara Synkron eller Asynkron.
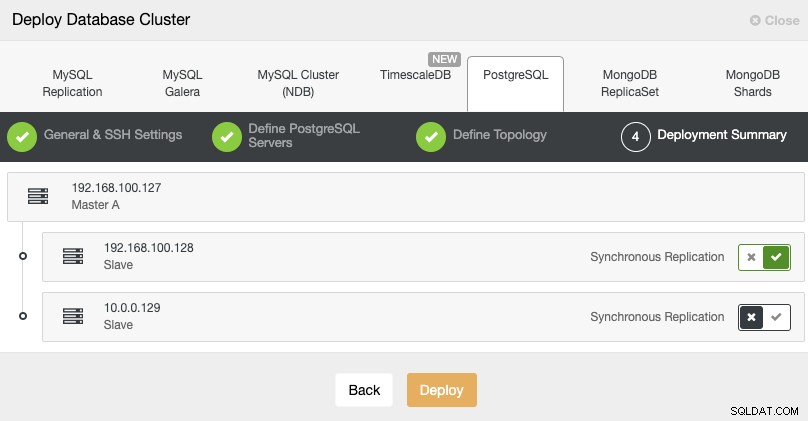
I det här fallet är det viktigt att använda asynkron replikering för din fjärrnod , om inte, kan ditt kluster påverkas av latens- eller nätverksproblem.
Du kan övervaka statusen för skapandet av ditt nya kluster från ClusterControl-aktivitetsmonitorn.
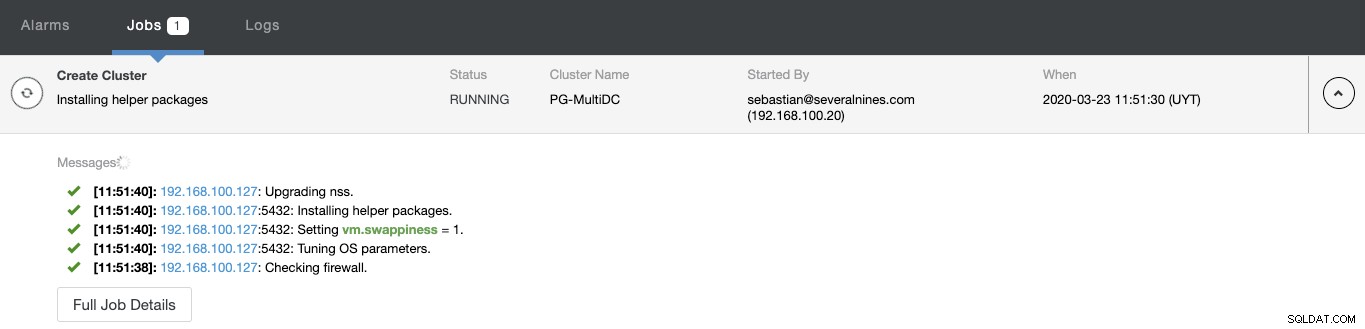
När uppgiften är klar kan du se ditt nya PostgreSQL-kluster i huvudskärmen för ClusterControl.

Lägga till en PostgreSQL Load Balancer (HAProxy)
När du har skapat ditt kluster kan du utföra flera uppgifter på det, som att lägga till en lastbalanserare (HAProxy) eller en ny replik.
För att följa vårt tidigare exempel, låt oss lägga till en lastbalanserare som, som vi nämnde, hjälper dig att hantera din HA-miljö. För detta, gå till ClusterControl -> Välj PostgreSQL Cluster -> Cluster Actions -> Add Load Balancer.
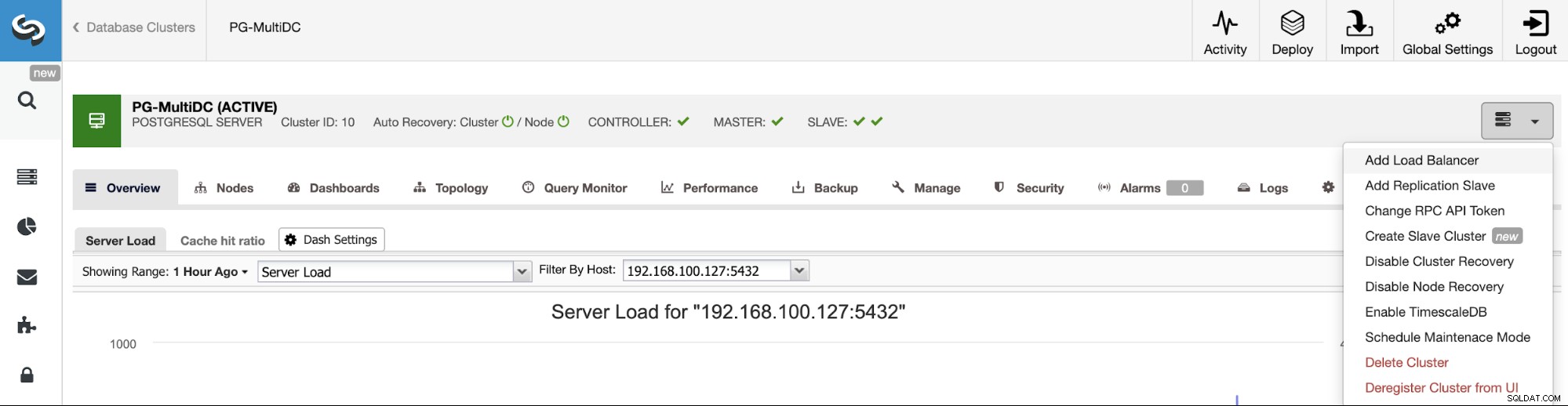
Här måste du lägga till informationen som ClusterControl kommer att använda för att installera och konfigurera din HAProxy lastbalanserare. Denna Load Balancer kan installeras på samma ClusterControl-server, men om du kan använda en annan, ännu bättre.
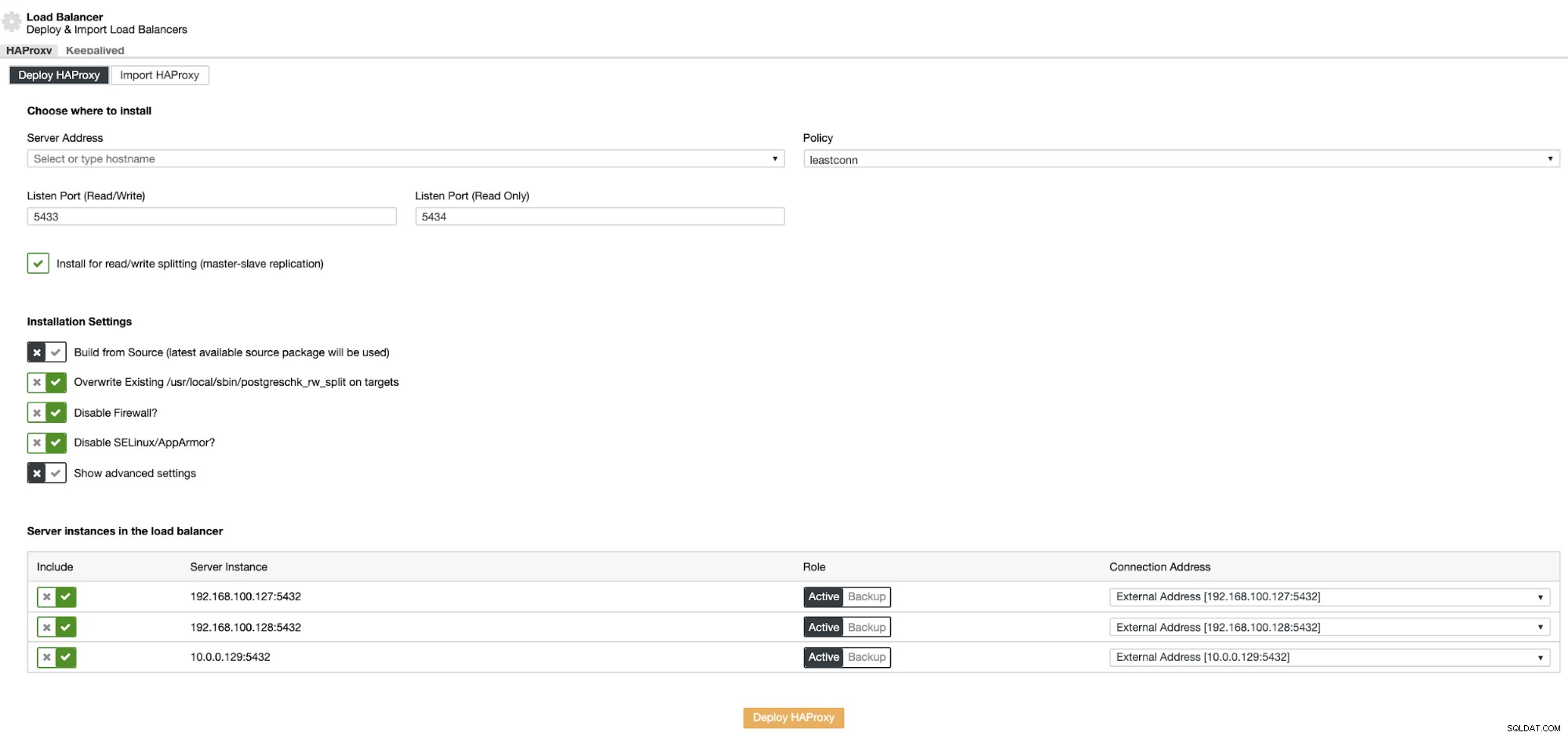
Informationen som du behöver presentera är:
Åtgärd:Implementera eller importera.
Serveradress:IP-adress för din HAProxy-server (det kan vara samma ClusterControl IP-adress).
Lyssningsport (läs/skriv):Port för läs-/skrivläge.
Listen Port (Read Only):Port för skrivskyddat läge.
Policy:Det kan vara:
- leastconn:Servern med det lägsta antalet anslutningar tar emot anslutningen.
- roundrobin:Varje server används i tur och ordning, beroende på deras vikt.
- källa:Källans IP-adress hashas och divideras med den totala vikten av de körande servrarna för att ange vilken server som ska ta emot begäran.
Installera för läs/skrivdelning:För master-slave replikering.
Bygg från källa:Du kan välja Installera från en pakethanterare eller bygga från källa.
Och du måste välja vilka servrar du vill lägga till i HAProxy-konfigurationen.
Du kan även konfigurera avancerade inställningar som Admin User, Backend Name, Timeouts och mer.
När du är klar med konfigurationen och bekräftar distributionen kan du följa förloppet i aktivitetsavsnittet på ClusterControl UI.
Och när detta är klart kan du gå till ClusterControl -> Noder -> HAProxy-nod och kontrollera aktuell status.
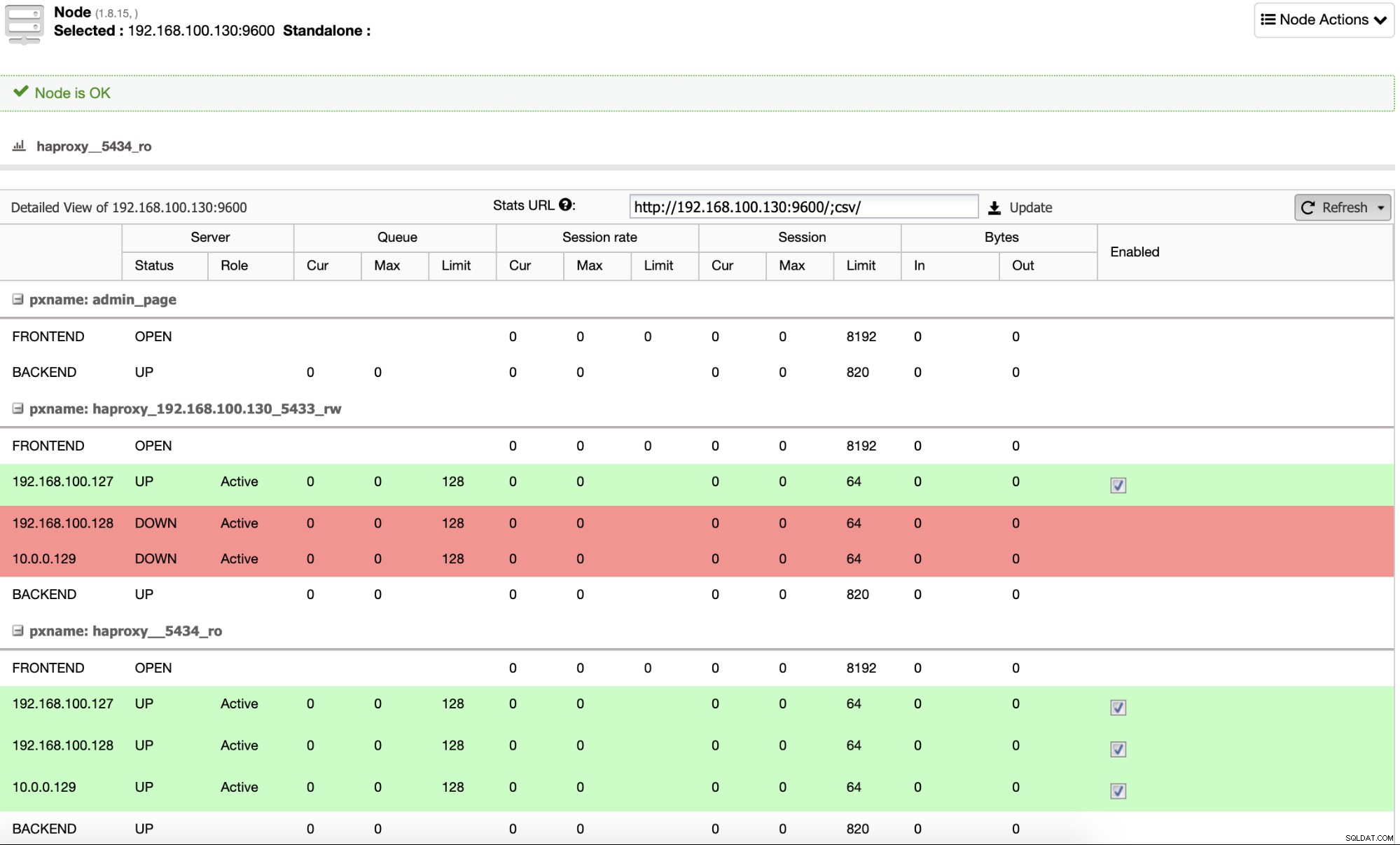
Som standard konfigurerar ClusterControl HAProxy med två olika portar, en för läs- Write, som kommer att användas för applikationen eller användaren för att skriva (och läsa) data, och en annan för Read-Only, som kommer att användas för att balansera lästrafiken mellan alla noder. I Read-Write-porten är endast masternoden aktiverad, och i händelse av masterfel kommer ClusterControl att främja den mest avancerade slaven till master och kommer att omkonfigurera denna port för att inaktivera den gamla mastern och aktivera den nya. På detta sätt kan din applikation fortfarande fungera i händelse av ett fel i huvuddatabasen, eftersom trafiken omdirigeras av lastbalanseraren till rätt nod.
Du kan också övervaka dina HAProxy-servrar genom att kontrollera avsnittet Dashboard.
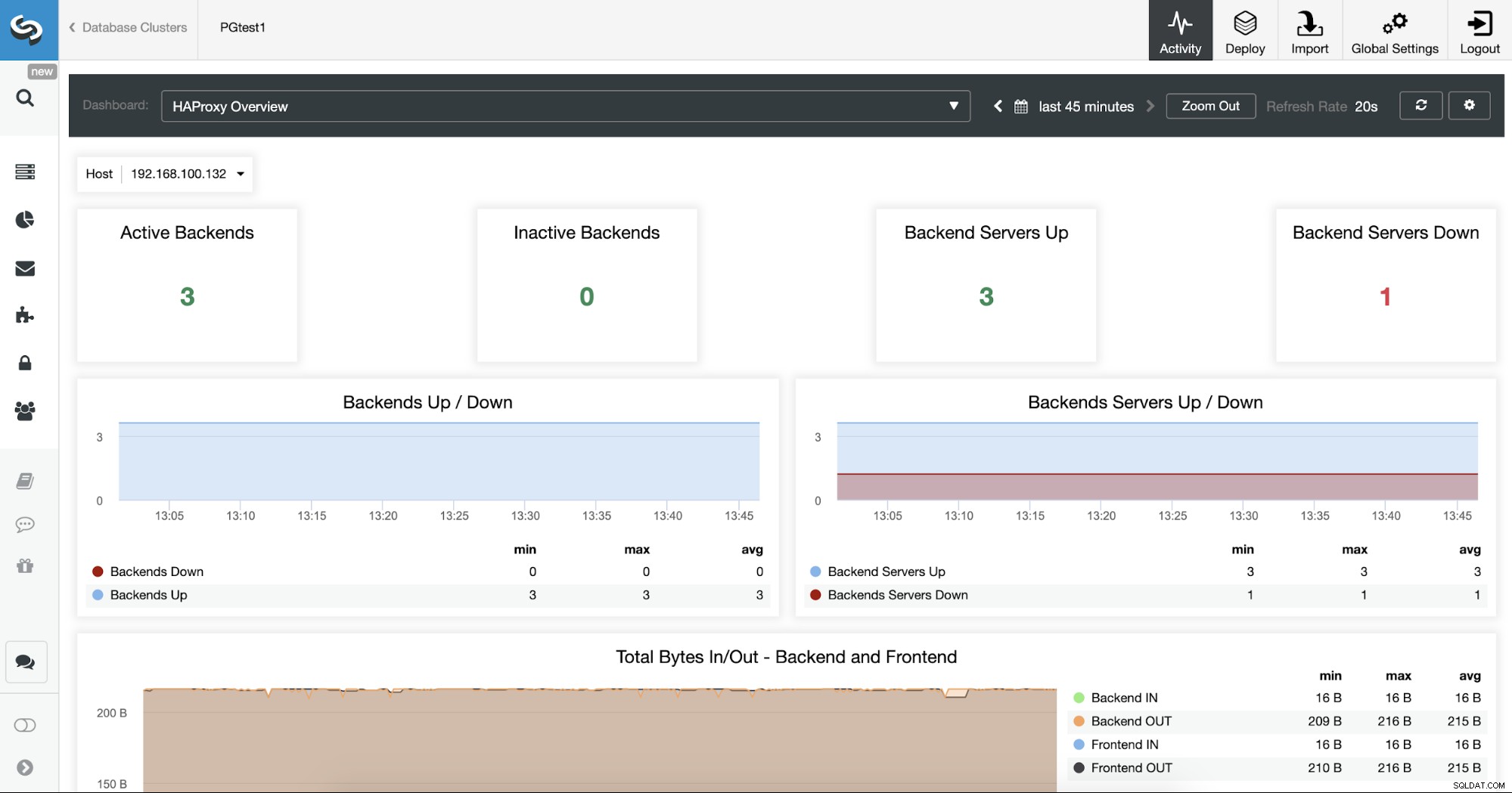
Nu kan du förbättra din HA-design genom att lägga till en ny HAProxy-nod i fjärrdatacenter och konfigurera Keepalved-tjänsten mellan dem. Keepalved låter dig använda en virtuell IP-adress som är tilldelad den aktiva lastbalanseringsnoden. Om den här noden misslyckas kommer den virtuella IP-adressen att migreras till den sekundära HAProxy-noden, så att ha denna IP konfigurerad i din applikation kommer att tillåta dig att hålla allt igång i händelse av ett problem med lastbalanseraren.
All denna konfiguration kan utföras med ClusterControl.
Slutsats
Genom att följa den här tvådelade bloggen kan du implementera en multidatacenterinstallation för PostgreSQL med hög tillgänglighet och SSH-anslutning mellan datacentret, för att undvika komplexiteten med en VPN-konfiguration.
Genom att använda asynkron replikering för fjärrnoden undviker du alla problem relaterade till latensen och nätverksprestanda, och med ClusterControl kommer du att ha automatisk (eller manuell) failover i händelse av fel (bland annat flera funktioner). Detta kan vara det enklaste sättet att nå den här topologin och vi hoppas att det skulle vara användbart för dig.