I det tidigare inlägget diskuterade vi hur man verifierar att MySQL-replikering är i bra skick. Vi tittade också på några av de typiska problemen. I det här inlägget kommer vi att ta en titt på några fler problem som du kan se när du hanterar MySQL-replikering.
Saknade eller dubblerade poster
Detta är något som inte bör hända, men det händer väldigt ofta - en situation där en SQL-sats som körs på mastern lyckas men samma sats som körs på en av slavarna misslyckas. Huvudorsaken är slavdrift - något (vanligtvis felaktiga transaktioner men också andra problem eller buggar i replikeringen) gör att slaven skiljer sig från sin master. Till exempel, en rad som fanns på mastern finns inte på en slav och den kan inte tas bort eller uppdateras. Hur ofta det här problemet dyker upp beror mest på dina replikeringsinställningar. Kort sagt, det finns tre sätt på vilka MySQL lagrar binära logghändelser. För det första betyder "statement" att SQL skrivs i vanlig text, precis som det har körts på en master. Den här inställningen har den högsta toleransen för slavdrift men det är också den som inte kan garantera slavkonsistens - det är svårt att rekommendera att använda den i produktionen. Andra formatet, "rad", lagrar frågeresultatet istället för frågesats. Till exempel kan en händelse se ut så här:
### UPDATE `test`.`tab`
### WHERE
### @1=2
### @2=5
### SET
### @1=2
### @2=4Det betyder att vi uppdaterar en rad i 'tab'-tabellen i 'test'-schemat där första kolumnen har värdet 2 och andra kolumnen har värdet 5. Vi sätter första kolumnen till 2 (värdet ändras inte) och andra kolumnen kolumn till 4. Som du kan se finns det inte mycket utrymme för tolkning - det är exakt definierat vilken rad som används och hur den ändras. Som ett resultat är detta format bra för slavkonsistens, men som du kan föreställa dig är det väldigt sårbart när det kommer till datadrift. Det är fortfarande det rekommenderade sättet att köra MySQL-replikering.
Slutligen fungerar den tredje, "blandad", på ett sätt som de händelser som är säkra att skriva i form av påståenden använder "påstående"-format. De som kan orsaka dataavdrift kommer att använda "rad"-format.
Hur upptäcker du dem?
Som vanligt hjälper VISA SLAVSTATUS oss att identifiera problemet.
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000021, end_log_pos 970 Last_SQL_Errno: 1062
Last_SQL_Error: Could not execute Write_rows event on table test.tab; Duplicate entry '3' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log binlog.000021, end_log_pos 1229Som du kan se är fel tydliga och självförklarande (och de är i princip identiska mellan MySQL och MariaDB.
Hur åtgärdar du problemet?
Detta är tyvärr den komplexa delen. Först och främst måste du identifiera en källa till sanning. Vilken värd innehåller rätt data? Mästare eller slav? Vanligtvis skulle du anta att det är befälhavaren men anta det inte som standard - undersök! Det kan vara så att en del av applikationen efter failover fortfarande skickade skrivningar till den gamla mästaren, som nu fungerar som en slav. Det kan vara så att read_only inte har ställts in korrekt på den värden eller så använder applikationen superuser för att ansluta till databasen (ja, vi har sett detta i produktionsmiljöer). I ett sådant fall kan slaven vara källan till sanningen - åtminstone till viss del.
Beroende på vilken data som ska stanna och vilken som ska gå, skulle det bästa tillvägagångssättet vara att identifiera vad som behövs för att få replikeringen tillbaka i synk. Först och främst är replikeringen trasig så du måste ta hand om detta. Logga in på mastern och kontrollera den binära loggen även som orsakade att replikeringen gick sönder.
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106672
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106671Som ni ser missar vi ett evenemang:5d1e2227-07c6-11e7-8123-080027495a77:1106672. Låt oss kontrollera det i masterns binära loggar:
mysqlbinlog -v --include-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1106672' /var/lib/mysql/binlog.000021
#170320 20:53:37 server id 1 end_log_pos 1066 CRC32 0xc582a367 GTID last_committed=3 sequence_number=4
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672'/*!*/;
# at 1066
#170320 20:53:37 server id 1 end_log_pos 1138 CRC32 0x6f33754d Query thread_id=5285 exec_time=0 error_code=0
SET TIMESTAMP=1490043217/*!*/;
SET @@session.pseudo_thread_id=5285/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1436549152/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
BEGIN
/*!*/;
# at 1138
#170320 20:53:37 server id 1 end_log_pos 1185 CRC32 0xa00b1f59 Table_map: `test`.`tab` mapped to number 571
# at 1185
#170320 20:53:37 server id 1 end_log_pos 1229 CRC32 0x5597e50a Write_rows: table id 571 flags: STMT_END_F
BINLOG '
UUHQWBMBAAAALwAAAKEEAAAAADsCAAAAAAEABHRlc3QAA3RhYgACAwMAAlkfC6A=
UUHQWB4BAAAALAAAAM0EAAAAADsCAAAAAAEAAgAC//wDAAAABwAAAArll1U=
'/*!*/;
### INSERT INTO `test`.`tab`
### SET
### @1=3
### @2=7
# at 1229
#170320 20:53:37 server id 1 end_log_pos 1260 CRC32 0xbbc3367c Xid = 5224257
COMMIT/*!*/;Vi kan se att det var en infogning som anger första kolumn till 3 och andra till 7. Låt oss verifiera hur vår tabell ser ut nu:
mysql> SELECT * FROM test.tab;
+----+------+
| id | b |
+----+------+
| 1 | 2 |
| 2 | 4 |
| 3 | 10 |
+----+------+
3 rows in set (0.01 sec)Nu har vi två alternativ, beroende på vilken data som ska råda. Om korrekt data finns på mastern kan vi helt enkelt ta bort rad med id=3 på slaven. Se bara till att inaktivera binär loggning för att undvika att införa felaktiga transaktioner. Å andra sidan, om vi bestämde oss för att rätt data finns på slaven, måste vi köra REPLACE-kommandot på mastern för att ställa in rad med id=3 för att korrigera innehållet av (3, 10) från nuvarande (3, 7). På slaven måste vi dock hoppa över aktuellt GTID (eller, för att vara mer exakt, måste vi skapa en tom GTID-händelse) för att kunna starta om replikering.
Att ta bort en rad på en slav är enkelt:
SET SESSION log_bin=0; DELETE FROM test.tab WHERE id=3; SET SESSION log_bin=1;Att infoga ett tomt GTID är nästan lika enkelt:
mysql> SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672';
Query OK, 0 rows affected (0.00 sec)mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)mysql> COMMIT;
Query OK, 0 rows affected (0.00 sec)mysql> SET @@SESSION.GTID_NEXT=automatic;
Query OK, 0 rows affected (0.00 sec)En annan metod för att lösa just detta problem (så länge vi accepterar mastern som en källa till sanning) är att använda verktyg som pt-table-checksum och pt-table-sync för att identifiera var slaven inte är konsekvent med sin master och vad SQL måste köras på mastern för att få slaven tillbaka i synk. Tyvärr är den här metoden ganska på den tunga sidan - mycket belastning läggs till mastern och en massa frågor skrivs in i replikeringsströmmen vilket kan påverka fördröjningen på slavar och den allmänna prestandan för replikeringsinställningen. Detta gäller särskilt om det finns ett betydande antal rader som måste synkroniseras.
Äntligen, som alltid, kan du bygga om din slav med hjälp av data från mastern - på så sätt kan du vara säker på att slaven kommer att uppdateras med den färskaste, uppdaterade data. Detta är faktiskt inte nödvändigtvis en dålig idé - när vi talar om ett stort antal rader att synkronisera med pt-table-checksum/pt-table-sync, kommer detta med betydande overhead i replikeringsprestanda, övergripande CPU och I/O belastning och mantimmar krävs.
ClusterControl låter dig bygga om en slav med hjälp av en ny kopia av masterdata.
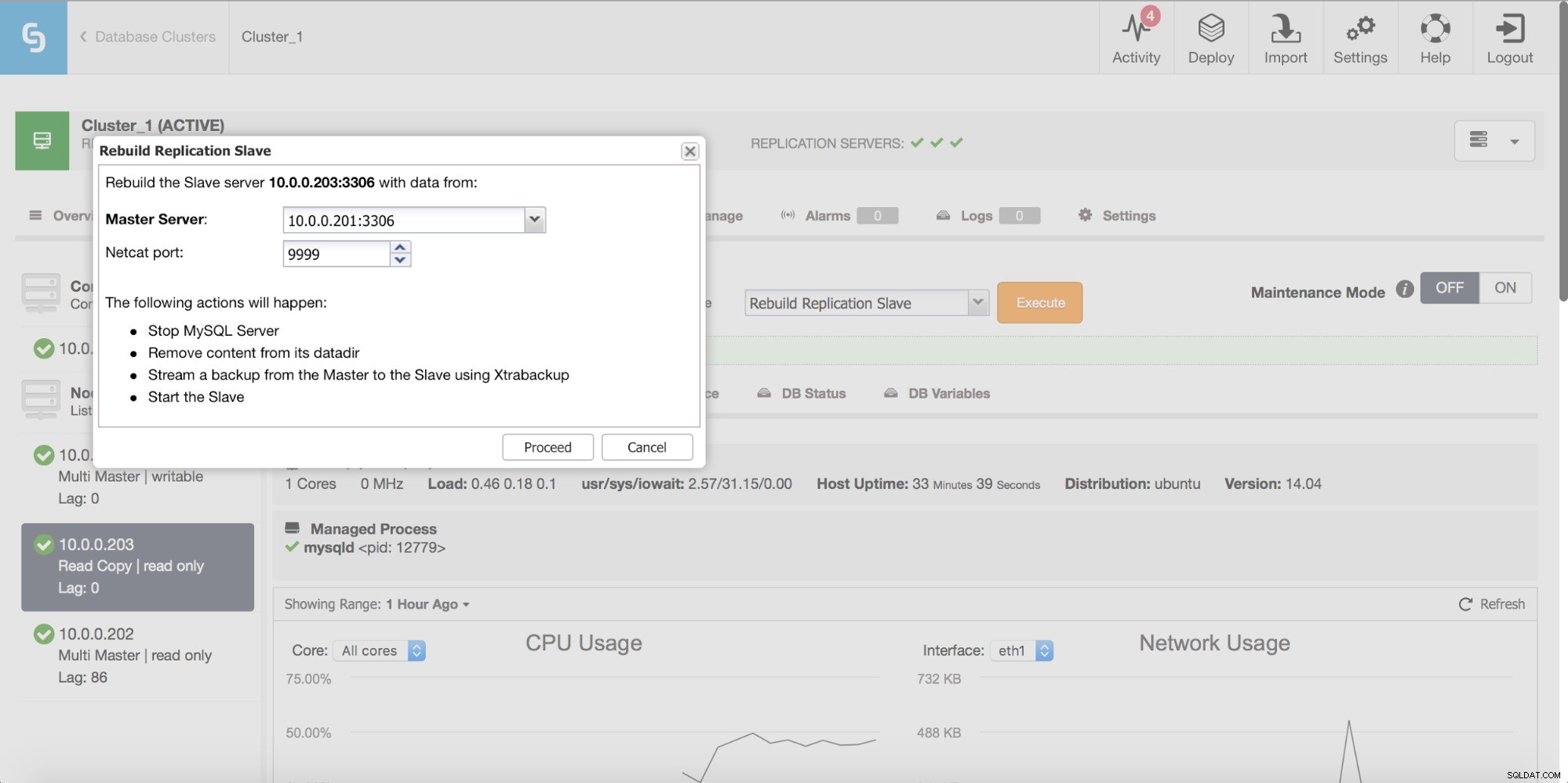
Konsistenskontroller
Som vi nämnde i föregående kapitel kan konsekvens bli ett allvarligt problem och kan orsaka mycket huvudvärk för användare som kör MySQL-replikeringsinställningar. Låt oss se hur du kan verifiera att dina MySQL-slavar är synkroniserade med mastern och vad du kan göra åt det.
Hur man upptäcker en inkonsekvent slav
Tyvärr är det typiska sättet som en användare får veta att en slav är inkonsekvent genom att stöta på ett av problemen vi nämnde i föregående kapitel. För att undvika det krävs proaktiv övervakning av slavkonsistens. Låt oss kolla hur det kan göras.
Vi kommer att använda ett verktyg från Percona Toolkit:pt-table-checksum. Den är utformad för att skanna replikeringskluster och identifiera eventuella avvikelser.
Vi byggde ett anpassat scenario med sysbench och vi introducerade lite inkonsekvens på en av slavarna. Vad som är viktigt (om du vill testa det som vi gjorde), måste du använda en korrigeringsfil nedan för att tvinga pt-table-checksum att känna igen "sbtest"-schemat som icke-systemschema:
--- pt-table-checksum 2016-12-15 14:31:07.000000000 +0000
+++ pt-table-checksum-fix 2017-03-21 20:32:53.282254794 +0000
@@ -7614,7 +7614,7 @@
my $filter = $self->{filters};
- if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|test/ ) {
+ if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|^test/ ) {
PTDEBUG && _d('Database', $db, 'is a system database, ignoring');
return 0;
}Till en början kommer vi att köra pt-table-checksum på följande sätt:
master:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T20:33:30 0 0 1000000 15 0 27.103 sbtest.sbtest1
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2
03-21T20:34:26 0 0 1000000 15 0 28.503 sbtest.sbtest3
03-21T20:34:52 0 0 1000000 18 0 26.021 sbtest.sbtest4
03-21T20:35:34 0 0 1000000 17 0 42.730 sbtest.sbtest5
03-21T20:36:04 0 0 1000000 16 0 29.309 sbtest.sbtest6
03-21T20:36:42 0 0 1000000 15 0 38.071 sbtest.sbtest7
03-21T20:37:16 0 0 1000000 12 0 33.737 sbtest.sbtest8Ett par viktiga anteckningar om hur vi anropade verktyget. Först och främst måste användaren som vi ställer in finns på alla slavar. Om du vill kan du också använda '--slave-user' för att definiera andra, mindre privilegierade användare för åtkomst till slavar. En annan sak värd att förklara - vi använder radbaserad replikering som inte är helt kompatibel med pt-table-checksum. Om du har radbaserad replikering, vad som händer är att pt-table-checksum kommer att ändra binärt loggformat på sessionsnivå till "statement" eftersom detta är det enda formatet som stöds. Problemet är att en sådan förändring endast kommer att fungera på en första nivå av slavar som är direkt anslutna till en master. Om du har mellanliggande masters (alltså mer än en nivå av slavar), kan användning av pt-table-checksum bryta replikeringen. Det är därför som standard, om verktyget upptäcker radbaserad replikering, avslutas det och skriver ut fel:
"Replica slave1 har binlog_format ROW som kan få pt-table-checksum att bryta replikeringen. Läs "Repliker som använder radbaserad replikering" i avsnittet BEGRÄNSNINGAR i verktygets dokumentation. Om du förstår riskerna, specificera --no-check-binlog-format för att inaktivera denna kontroll.”
Vi använde bara en nivå av slavar så det var säkert att ange "--no-check-binlog-format" och gå vidare.
Slutligen ställer vi in maximal fördröjning till 5 sekunder. Om detta tröskelvärde kommer att nås, kommer pt-table-checksum att pausa under en tid som behövs för att få fördröjningen under tröskeln.
Som du kunde se från utdata,
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2en inkonsekvens har upptäckts i tabellen sbtest.sbtest2.
Som standard lagrar pt-table-checksum kontrollsummor i tabellen percona.checksums. Dessa data kan användas för ett annat verktyg från Percona Toolkit, pt-table-sync, för att identifiera vilka delar av tabellen som bör kontrolleras i detalj för att hitta exakta skillnader i data.
Hur man åtgärdar inkonsekvent slav
Som nämnts ovan kommer vi att använda pt-table-sync för att göra det. I vårt fall kommer vi att använda data som samlats in av pt-table-checksum även om det också är möjligt att peka pt-table-sync till två värdar (mastern och en slav) och det kommer att jämföra all data på båda värdarna. Det är definitivt mer tid- och resurskrävande process, så länge du redan har data från pt-table-checksum är det mycket bättre att använda det. Så här körde vi det för att testa utdata:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=master --printREPLACE INTO `sbtest`.`sbtest2`(`id`, `k`, `c`, `pad`) VALUES ('1', '434041', '61753673565-14739672440-12887544709-74227036147-86382758284-62912436480-22536544941-50641666437-36404946534-73544093889', '23608763234-05826685838-82708573685-48410807053-00139962956') /*percona-toolkit src_db:sbtest src_tbl:sbtest2 src_dsn:h=10.0.0.101,p=...,u=sbtest dst_db:sbtest dst_tbl:sbtest2 dst_dsn:h=10.0.0.103,p=...,u=sbtest lock:1 transaction:1 changing_src:percona.checksums replicate:percona.checksums bidirectional:0 pid:25776 user:root host:vagrant-ubuntu-trusty-64*/;Som du kan se har en del SQL genererats som ett resultat. Viktigt att notera är --replicate variabel. Vad som händer här är att vi pekar pt-table-sync till tabell som genereras av pt-table-checksum. Vi pekar också på master.
För att verifiera om SQL är vettigt använde vi --print option. Observera att SQL-genererad endast är giltig vid den tidpunkt den genereras - du kan inte riktigt lagra den någonstans, granska den och sedan köra. Allt du kan göra är att verifiera om SQL är vettigt och omedelbart efter köra om verktyget med --execute-flaggan:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=10.0.0.101 --executeDetta bör göra slaven tillbaka i synk med mastern. Vi kan verifiera det med pt-table-checksum:
example@sqldat.com:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T21:36:04 0 0 1000000 13 0 23.749 sbtest.sbtest1
03-21T21:36:26 0 0 1000000 7 0 22.333 sbtest.sbtest2
03-21T21:36:51 0 0 1000000 10 0 24.780 sbtest.sbtest3
03-21T21:37:11 0 0 1000000 14 0 19.782 sbtest.sbtest4
03-21T21:37:42 0 0 1000000 15 0 30.954 sbtest.sbtest5
03-21T21:38:07 0 0 1000000 15 0 25.593 sbtest.sbtest6
03-21T21:38:27 0 0 1000000 16 0 19.339 sbtest.sbtest7
03-21T21:38:44 0 0 1000000 15 0 17.371 sbtest.sbtest8Som du kan se finns det inga skillnader längre i tabellen sbtest.sbtest2.
Vi hoppas att du tyckte att det här blogginlägget var informativt och användbart. Klicka här för att lära dig mer om MySQL-replikering. Om du har några frågor eller förslag, kontakta oss gärna via kommentarerna nedan.