Det här blogginlägget är den tredje delen av serien med bloggar om index i MySQL . I den andra delen av blogginläggsserien om MySQL-index täckte vi index och lagringsmotorer och berörde några PRIMÄRA NYCKELöverväganden. Diskussionen inkluderade hur man matchar ett kolumnprefix, några FULLTEXT-indexöverväganden och hur du bör använda B-Tree-index med jokertecken och hur du använder ClusterControl för att övervaka dina frågors prestanda, och sedan index.
I det här blogginlägget kommer vi att gå in på lite mer detaljer om index i MySQL :vi kommer att täcka hashindex, indexkardinalitet, indexselektivitet, vi kommer att berätta intressanta detaljer om att täcka index, och vi kommer också att gå igenom några indexeringsstrategier. Och, naturligtvis, kommer vi att beröra ClusterControl. Låt oss börja, ska vi?
Hash-index i MySQL
MySQL DBA:er och utvecklare som sysslar med MySQL har också ett annat knep i rockärmen när det gäller MySQL - hashindex är också ett alternativ. Hash-index används ofta i MEMORY-motorn i MySQL - som med i stort sett allt i MySQL, har den typen av index sina egna upp- och nackdelar. Den största nackdelen med den här typen av index är att de endast används för jämställdhetsjämförelser som använder operatorerna =eller <=> vilket betyder att de inte är riktigt användbara om du vill söka efter ett antal värden, men den främsta fördelen är att uppslagningar går väldigt snabbt. Ett par nackdelar till inkluderar det faktum att utvecklare inte kan använda något prefix längst till vänster på nyckeln för att hitta rader (om du vill göra det, använd B-Tree-index istället), det faktum att MySQL inte kan avgöra ungefär hur många rader det finns mellan två värden - om hashindex används kan optimeraren inte heller använda ett hashindex för att påskynda ORDER BY-operationer. Tänk på att hashindex inte är det enda som MEMORY-motorn stöder - MEMORY-motorer kan också ha B-Tree-index.
Indexkardinalitet i MySQL
När det gäller MySQL-index, kanske du också hört en annan term gå runt - denna term kallas indexkardinalitet. I mycket enkla termer hänvisar indexkardinalitet till det unika hos värden som lagras i en kolumn som använder ett index. För att se indexkardinaliteten för ett specifikt index kan du helt enkelt gå till strukturfliken i phpMyAdmin och observera informationen där eller så kan du också köra en SHOW INDEXS-fråga:
mysql> SHOW INDEXES FROM demo_table;
+---------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| demo_table | 1 | demo | 1 | demo | A | 494573 | NULL | NULL | | BTREE | | |
+---------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 sec)Frågeutgången SHOW INDEXS som kan ses ovan som du kan se har många fält, varav ett visar indexkardinaliteten:detta fält returnerar ett uppskattat antal unika värden i indexet - högre kardinalitet, desto större är chansen att frågeoptimeraren använder indexet för uppslagningar. Med det sagt har indexkardinalitet också en bror - hans namn är indexselektivitet.
Indexselektivitet i MySQL
En indexselektivitet är antalet distinkta värden i förhållande till antalet poster i tabellen. Enkelt uttryckt definierar indexselektivitet hur tätt ett databasindex hjälper MySQL att begränsa sökningen efter värden. En idealisk indexselektivitet är värdet 1. En indexselektivitet beräknas genom att dividera de distinkta värdena i en tabell med det totala antalet poster, till exempel om du har 1 000 000 poster i din tabell, men bara 100 000 av dem är distinkta värden , skulle din indexselektivitet vara 0,1. Om du har 10 000 poster i din tabell och 8 500 av dem är distinkta värden, skulle din indexselektivitet vara 0,85. Det är mycket bättre. Du förstår poängen. Ju högre din indexselektivitet är, desto bättre.
Täcker index i MySQL
Ett täckande index är en speciell typ av index i InnoDB. När ett täckande index används, inkluderas alla obligatoriska fält för en fråga, eller "täcks", av indexet, vilket innebär att du också kan dra nytta av att bara läsa indexet istället för data. Om inget annat hjälper kan ett täckande index vara din biljett till förbättrad prestanda. Några av fördelarna med att använda täckande index inkluderar:
-
Ett av huvudscenarierna där ett täckande index kan vara användbart inkluderar visning av frågor utan ytterligare I/O-läsningar på stora bord.
-
MySQL kan också komma åt mindre data på grund av att indexposter är mindre än storleken på rader.
-
De flesta lagringsmotorer cachelagrar index bättre än data.
Att skapa täckande index på en tabell är ganska enkelt - täck helt enkelt fälten som nås av SELECT-, WHERE- och GROUP BY-satser:
ALTER TABLE demo_table ADD INDEX index_name(column_1, column_2, column_3);Tänk på att när du har att göra med täckande index är det mycket viktigt att välja rätt ordning på kolumner i indexet. För att dina täckande index ska vara effektiva sätter du kolumnerna som du använder med WHERE-satser först, ORDER BY och GROUP BY nästa och kolumnerna som används med SELECT-satsen sist.
Indexeringsstrategier i MySQL
Att följa råden som tas upp i dessa tre delar av blogginlägg om index i MySQL kan ge dig en riktigt bra grund, men det finns också ett par indexeringsstrategier du kanske vill använda om du vill verkligen utnyttja kraften i index i din MySQL-arkitektur. För att dina index ska följa MySQL bästa praxis, överväg:
-
Isolera kolumnen som du använder indexet på - i allmänhet använder MySQL inte index om kolumnerna de används på är inte isolerade. Till exempel skulle en sådan fråga inte använda ett index eftersom det inte är isolerat:
SELECT demo_column FROM demo_table WHERE demo_id + 1 = 10;
En sådan fråga skulle dock:
SELECT demo_column FROM demo_table WHERE demo_id = 10; -
Använd inte index på de kolumner som du indexerar. Att till exempel använda en fråga som så skulle inte göra så mycket nytta så det är bättre att undvika sådana frågor om du kan:
SELECT demo_column FROM demo_table WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(column_date) <= 10; -
Om du använder LIKE-frågor tillsammans med indexerade kolumner, undvik att sätta jokertecken i början av sökfrågan eftersom på så sätt kommer MySQL inte att använda ett index heller. Det är istället för att skriva frågor så här:
SELECT * FROM demo_table WHERE demo_column LIKE ‘%search query%’;
Överväg att skriva dem så här:SELECT * FROM demo_table WHERE demo_column LIKE ‘search_query%’;
Den andra frågan är bättre eftersom MySQL vet vad kolumnen börjar med och kan använda index mer effektivt. Som med allt kan dock EXPLAIN-satsen vara till stor hjälp om du vill försäkra dig om att dina index faktiskt används av MySQL.
Använda ClusterControl för att hålla dina frågor prestanda
Om du vill förbättra din MySQL-prestanda bör råden ovan leda dig på rätt väg. Om du känner att du behöver något mer, överväg ClusterControl för MySQL. En av de saker som ClusterControl kan hjälpa dig med inkluderar prestationshantering - som redan noterats i tidigare blogginlägg kan ClusterControl också hjälpa dig att hålla dina frågor prestera på bästa sätt hela tiden - det beror på att ClusterControl också innehåller en fråga monitor som låter dig övervaka prestandan för dina frågor, se långsamma, långvariga frågor och även frågeavvikare som varnar dig om möjliga flaskhalsar i din databasprestanda innan du kanske kan märka dem själv:
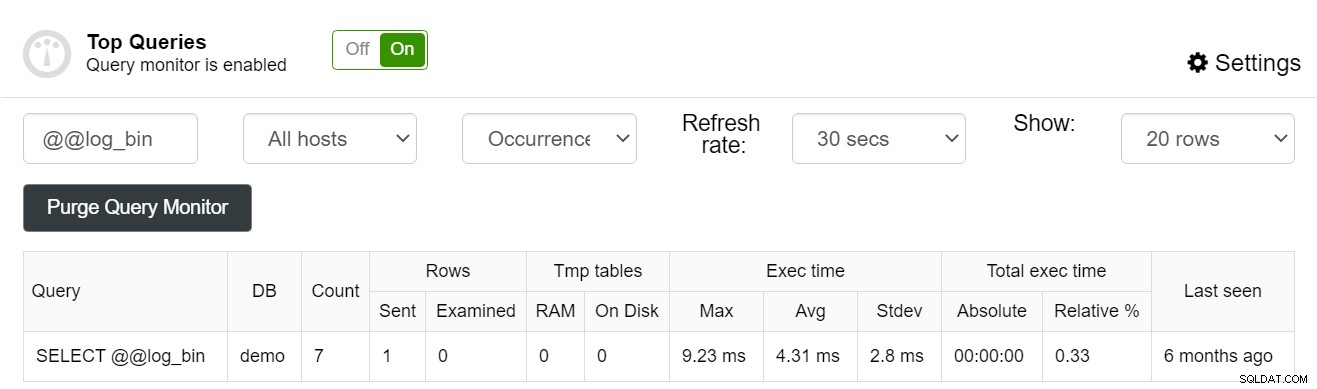
Du kan till och med filtrera dina frågor så att du kan göra ett antagande om ett index användes av en enskild fråga eller inte:
ClusterControl kan vara ett utmärkt verktyg för att förbättra din databasprestanda samtidigt som du slipper underhållsbesväret. För att lära dig mer om vad ClusterControl kan göra för att förbättra prestandan för dina MySQL-instanser, överväg att ta en titt på ClusterControl för MySQL-sidan.
Sammanfattning
Som du säkert kan se vid det här laget, är index i MySQL en mycket komplex best. För att välja det bästa indexet för din MySQL-instans, veta vad index är och vad de gör, känna till typerna av MySQL-index, känna till deras fördelar och nackdelar, utbilda dig själv om hur MySQL-index interagerar med lagringsmotorer, ta även en titt på ClusterControl för MySQL om du känner att automatisering av vissa uppgifter relaterade till index i MySQL kan göra din dag enklare.