I det tidigare blogginlägget har vi tagit upp grunderna för skalning - vad det är, vilka typer är det, vad är ett måste om vi vill skala. Det här blogginlägget kommer att fokusera på utmaningarna och de sätt på vilka vi kan skala ut.
Utmaning med att skala ut
Att skala databaser är inte den lättaste uppgiften av flera anledningar. Låt oss fokusera lite på utmaningarna relaterade till att skala ut din databasinfrastruktur.
Statlig tjänst
Vi kan särskilja två olika typer av tjänster:statslösa och tillståndslösa. Statslösa tjänster är de som inte förlitar sig på någon form av befintlig data. Du kan bara gå vidare, starta en sådan tjänst och det kommer lyckligtvis bara att fungera. Du behöver inte oroa dig för informationens tillstånd eller tjänsten. Om det är uppe kommer det att fungera korrekt och du kan enkelt sprida trafiken över flera tjänsteinstanser bara genom att lägga till fler kloner eller kopior av befintliga virtuella datorer, behållare eller liknande. Ett exempel på en sådan tjänst kan vara en webbapplikation - distribuerad från repo, med en korrekt konfigurerad webbserver, en sådan tjänst kommer bara att starta och fungera korrekt.
Problemet med databaser är att databasen är allt annat än statslös. Data måste infogas i databasen, den måste bearbetas och bevaras. Bilden av databasen är inget mer än bara ett par paket installerade över OS-avbildningen och utan data och korrekt konfiguration är den ganska värdelös. Detta ökar komplexiteten i databasens skalning. För tillståndslösa tjänster är det bara att distribuera dem och konfigurera vissa lastbalanserare för att inkludera nya instanser i arbetsbelastningen. För databaser som distribuerar databasen är instansen bara startpunkten. Längre ner i banan finns datahantering - du måste överföra data från din befintliga databasinstans till den nya. Detta kan vara en betydande del av problemet och den tid som krävs för att de nya instanserna ska börja hantera trafiken. Först efter att data har överförts kan vi ställa in de nya noderna så att de blir en del av den befintliga replikeringstopologin - data måste uppdateras på dem i realtid, baserat på trafiken som når ut till andra noder.
Tid som krävs för att skala upp
Det faktum att databaser är tillståndsfulla tjänster är en direkt orsak till den andra utmaningen som vi står inför när vi vill skala ut databasinfrastrukturen. Statslösa tjänster - du bara startar dem och det är allt. Det är en ganska snabb process. För databaser måste du överföra data. Hur lång tid det tar, det beror på flera faktorer. Hur stor är datamängden? Hur snabb är lagringen? Hur snabbt är nätverket? Vilka andra steg krävs för att tillhandahålla den nya noden med färska data? Är data komprimerad/dekomprimerad eller krypterad/dekrypterad i processen? I den verkliga världen kan det ta från minuter till flera timmar att tillhandahålla data på en ny nod. Detta begränsar allvarligt fallen där du kan skala upp din databasmiljö. Plötsliga, tillfälliga belastningstoppar? Inte riktigt, de kan vara borta för länge innan du kommer att kunna starta ytterligare databasnoder. Plötslig och konsekvent belastningsökning? Ja, det kommer att vara möjligt att hantera det genom att lägga till fler noder, men det kan ta till och med timmar att ta fram dem och låta dem ta över trafiken från befintliga databasnoder.
Ytterligare belastning orsakad av uppskalningsprocessen
Det är mycket viktigt att komma ihåg att tiden som krävs för att skala upp bara är en sida av problemet. Den andra sidan är belastningen som orsakas av skalningsprocessen. Som vi nämnde tidigare måste du överföra hela datamängden till nytillkomna noder. Detta är inget som du kan ignorera, trots allt kan det vara en timme lång process att läsa data från disken, skicka den över nätverket och lagra den på en ny plats. Om donatorn, noden som du läser data från, är överbelastad måste du fundera över hur den kommer att bete sig om den kommer att tvingas utföra ytterligare tung I/O-aktivitet? Kommer ditt kluster att kunna ta på sig en extra arbetsbörda om det redan är hårt pressat och tunt utspritt? Svaret kanske inte är lätt att få eftersom belastningen på noderna kan komma i olika former. CPU-bunden belastning kommer att vara det bästa scenariot eftersom I/O-aktiviteten bör vara låg och ytterligare diskoperationer kommer att vara hanterbara. I/O-bunden belastning, å andra sidan, kan sakta ner dataöverföringen avsevärt, vilket allvarligt påverkar klustrets förmåga att skala.
Skriv skalning
Utskalningsprocessen som vi nämnde tidigare är i stort sett begränsad till skalning av läsningar. Det är ytterst viktigt att förstå att skalning av skrivningar är en helt annan historia. Du kan skala läsningar genom att helt enkelt lägga till fler noder och sprida läsningarna över fler backend-noder. Skriver är inte så lätta att skala. Till att börja med kan du inte skala ut skriverier bara så. Varje nod som innehåller hela datamängden krävs uppenbarligen för att hantera alla skrivningar som utförs någonstans i klustret, eftersom det endast kan bibehålla konsistens genom att tillämpa alla modifieringar på datamängden. Så när du tänker på det, oavsett hur du designar ditt kluster och vilken teknik du använder, måste varje medlem i klustret utföra varje skrivning. Oavsett om det är en replik, som replikerar alla skrivningar från sin master eller nod i ett multi-masterkluster som Galera eller InnoDB Cluster och exekverar alla ändringar i datamängden som utförs på alla andra noder i klustret, blir resultatet detsamma. Skrivningar skalas inte ut bara genom att lägga till fler noder i klustret.
Hur kan vi skala ut databasen?
Så vi vet vilken typ av utmaningar vi står inför. Vilka alternativ har vi? Hur kan vi skala ut databasen?
Genom att lägga till repliker
Först och främst kommer vi att skala ut helt enkelt genom att lägga till fler noder. Visst, det kommer att ta tid och visst, det är inte en process du kan förvänta dig ska ske direkt. Visst, du kommer inte att kunna skala ut sådana skrivningar. Å andra sidan är det mest typiska problemet du kommer att ställas inför CPU-belastningen som orsakas av SELECT-frågor och, som vi diskuterade, kan läsningar helt enkelt skalas genom att bara lägga till fler noder i klustret. Fler noder att läsa från innebär att belastningen på var och en av dem kommer att minska. När du är i början av din resa in i din ansökans livscykel, anta bara att det är detta du kommer att ta itu med. CPU-belastning, inte effektiva frågor. Det är mycket osannolikt att du skulle behöva skala ut skrivningar till långt längre i livscykeln, när din ansökan redan har mognat och du måste hantera antalet kunder.
Genom att skära
Att lägga till noder löser inte skrivproblemet, det är vad vi har fastställt. Vad du istället måste göra är att skära - dela upp datamängden över klustret. I det här fallet innehåller varje nod bara en del av data, inte allt. Detta gör att vi äntligen kan börja skala skrivningar. Låt oss säga att vi har fyra noder, som var och en innehåller hälften av datamängden.
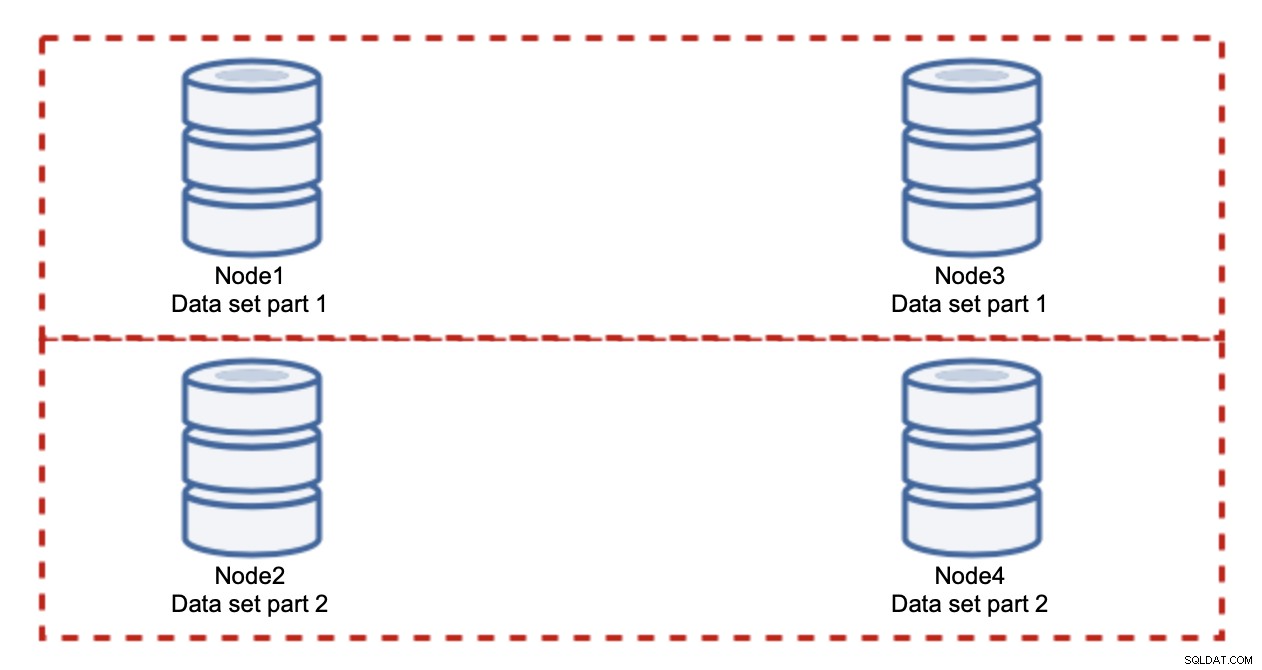
Som du kan se är idén enkel. Om skrivningen är relaterad till del 1 av datamängden kommer den att exekveras på nod1 och nod3. Om det är relaterat till del 2 av datamängden kommer det att exekveras på nod2 och nod4. Du kan tänka på databasnoderna som diskar i en RAID. Här har vi ett exempel på RAID10, två par speglar, för redundans. I verklig implementering kan det vara mer komplext, du kan ha mer än en replik av data för förbättrad hög tillgänglighet. Kontentan är, om man antar en helt rättvis uppdelning av data, hälften av skrivningarna kommer att träffa nod1 och nod3 och den andra halvan noder 2 och 4. Om du vill dela upp belastningen ytterligare kan du introducera det tredje nodparet:
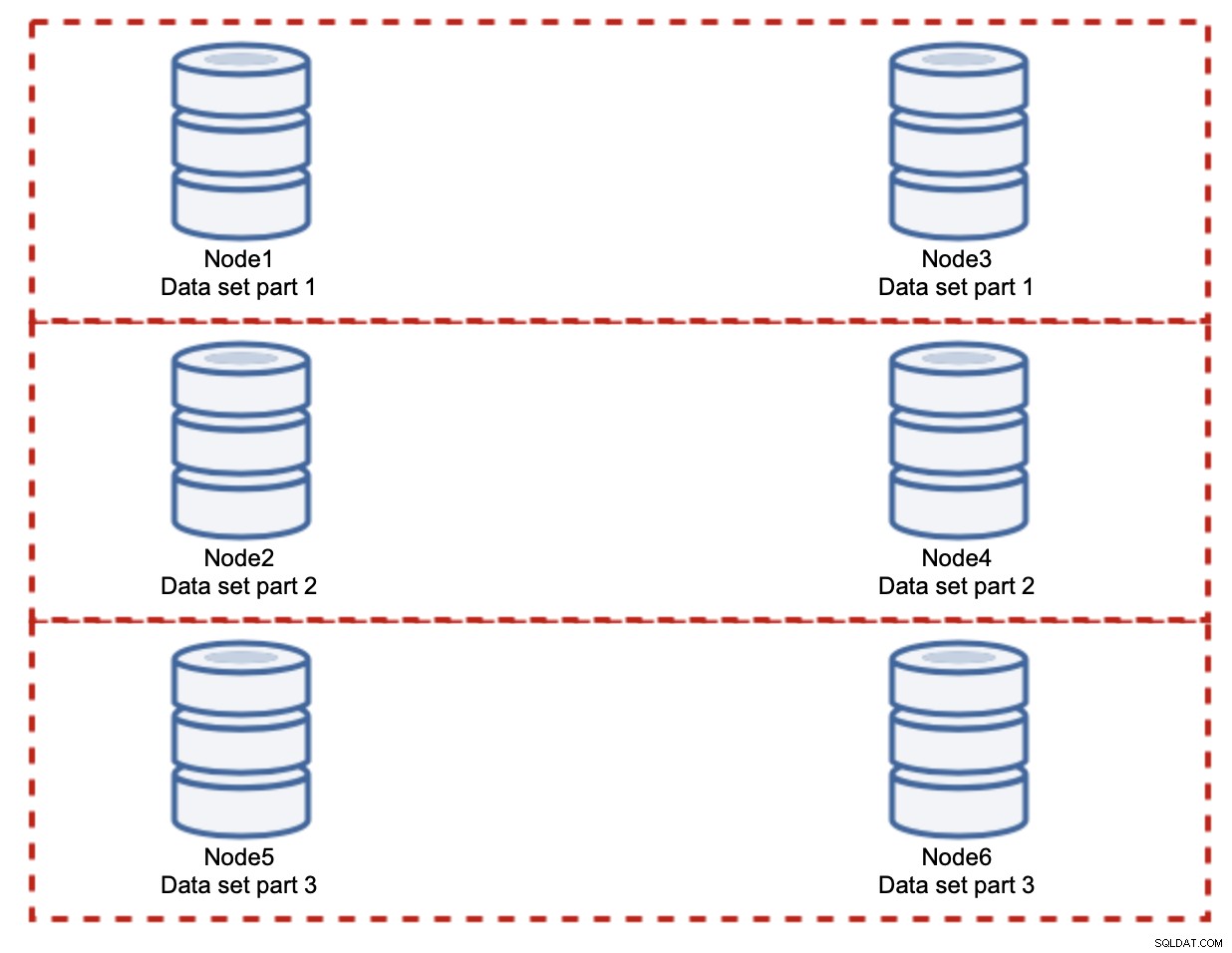
I detta fall, återigen, om man antar en helt rättvis uppdelning, kommer varje par att vara ansvarig för 33 % av alla skrivningar till klustret.
Detta sammanfattar ganska mycket idén med skärning. I vårt exempel, genom att lägga till fler skärvor, kan vi minska skrivaktiviteten på databasnoderna till 33 % av den ursprungliga I/O-belastningen. Som du kanske föreställer dig kommer detta inte utan nackdelar.
Hur ska jag ta reda på vilken shard min data finns på? Detaljer är utanför omfånget för detta anrop, men kortfattat kan du antingen implementera någon sorts funktion på en given kolumn (modulo eller hash i kolumnen 'id') eller så kan du bygga en separat metadatabas där du lagrar detaljerna hur informationen distribueras.
Vi hoppas att du tyckte att den här korta bloggserien var informativ och att du fick en bättre förståelse för de olika utmaningar vi står inför när vi vill skala ut databasmiljön. Om du har några kommentarer eller förslag om detta ämne får du gärna kommentera under det här inlägget och dela med dig av dina erfarenheter