Det är ganska vanligt att se databaser fördelade över flera geografiska platser. Ett scenario för att göra den här typen av inställningar är för återställning efter katastrof, där ditt standby-datacenter finns på en annan plats än ditt huvuddatacenter. Det kan lika gärna krävas så att databaserna ligger närmare användarna.
Den största utmaningen för att uppnå denna inställning är att designa databasen på ett sätt som minskar risken för problem relaterade till nätverkspartitioneringen. En av lösningarna kan vara att använda Galera Cluster istället för vanlig asynkron (eller semisynkron) replikering. I den här bloggen kommer vi att diskutera för- och nackdelar med detta tillvägagångssätt. Detta är den första delen i en serie om två bloggar. I den andra delen kommer vi att designa det geodistribuerade Galera Cluster och se hur ClusterControl kan hjälpa oss att distribuera en sådan miljö.
Varför Galera-kluster istället för Asynkron replikering för geodistribuerade kluster?
Låt oss överväga de viktigaste skillnaderna mellan Galera och vanlig replikering. Regelbunden replikering ger dig bara en nod att skriva till, detta innebär att varje skrivning från fjärrdatacenter måste skickas över Wide Area Network (WAN) för att nå mastern. Det betyder också att alla proxyservrar som finns i fjärrdatacentret måste kunna övervaka hela topologin, som sträcker sig över alla inblandade datacenter eftersom de måste kunna avgöra vilken nod som för närvarande är master.
Detta leder till antalet problem. Först måste flera anslutningar upprättas över WAN, detta lägger till latens och saktar ner alla kontroller av att proxy kan köras. Dessutom tillför detta onödiga omkostnader på proxyservrar och databaser. För det mesta är du bara intresserad av att dirigera trafik till de lokala databasnoderna. Det enda undantaget är mastern och endast på grund av detta tvingas proxyservrar att titta på hela infrastrukturen snarare än bara den del som finns i det lokala datacentret. Naturligtvis kan du försöka övervinna detta genom att använda proxyservrar för att dirigera endast SELECT, samtidigt som du använder någon annan metod (dedikerat värdnamn för master som hanteras av DNS) för att peka applikationen till master, men detta tillför onödiga nivåer av komplexitet och rörliga delar, vilket kan allvarligt påverka din förmåga att hantera flera noder och nätverksfel utan att förlora datakonsistensen.
Galera Cluster kan stödja flera skribenter. Latens är också en faktor, eftersom alla noder i Galera-klustret måste koordinera och kommunicera för att certifiera skrivuppsättningar, kan det till och med vara anledningen till att du kan välja att inte använda Galera när latensen är för hög. Det är också ett problem i replikeringskluster - i replikeringskluster påverkar latens endast skrivningar från fjärrdatacenter medan anslutningarna från datacentret där mastern är belägen skulle gynnas av commits med låg latens.
I MySQL-replikering måste du också ta det värsta scenariot i åtanke och se till att applikationen är ok med fördröjda skrivningar. Master kan alltid ändras och du kan inte vara säker på att du hela tiden kommer att skriva till en lokal nod.
En annan skillnad mellan replikering och Galera Cluster är hanteringen av replikeringsfördröjningen. Geo-distribuerade kluster kan påverkas allvarligt av fördröjning:latens, begränsad genomströmning av WAN-anslutningen, allt detta kommer att påverka förmågan hos ett replikerat kluster att hänga med i replikeringen. Tänk på att replikering genererar en till all trafik.
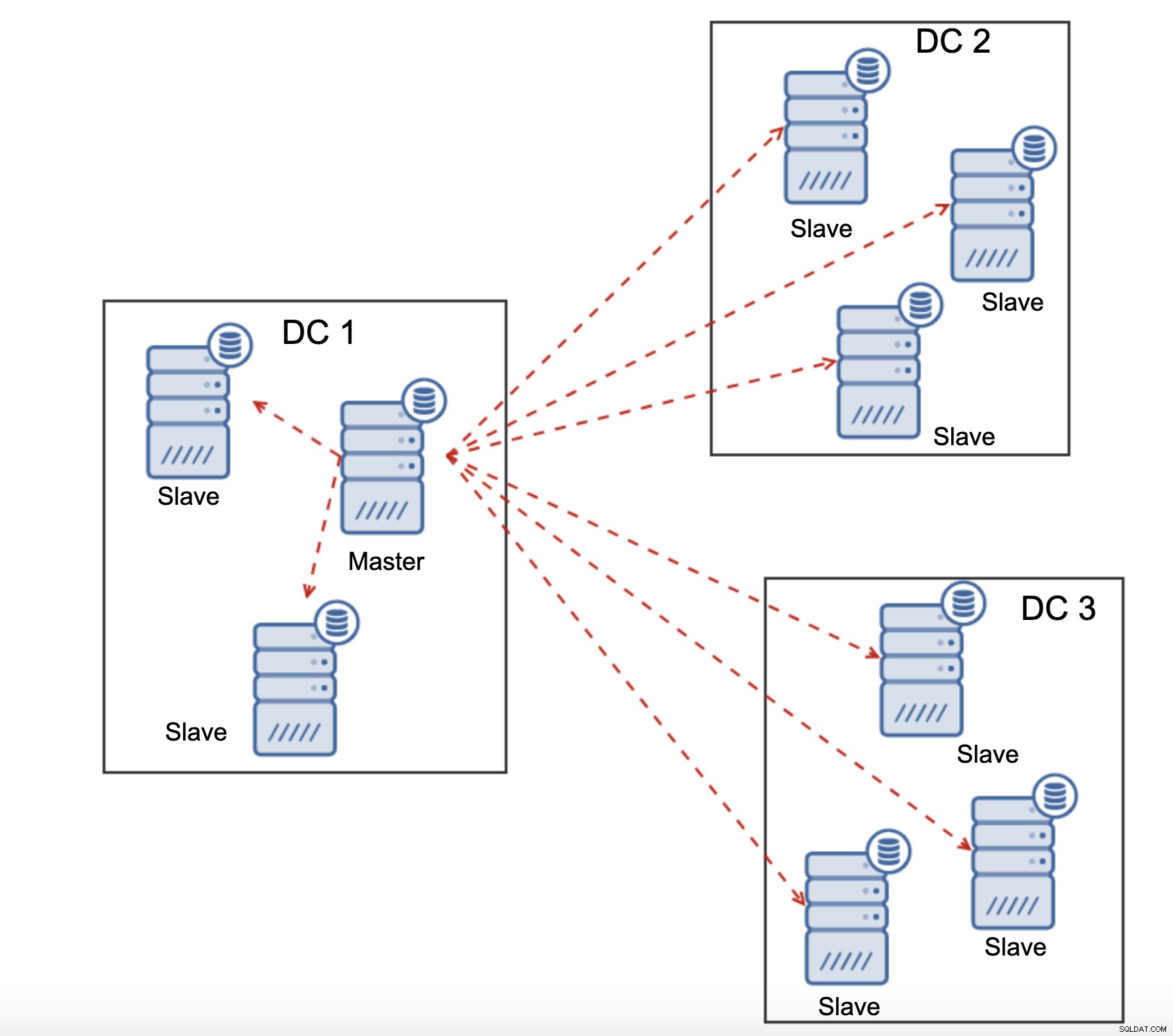
Alla slavar måste ta emot hela replikeringstrafiken - mängden data du har att skicka till fjärrslavar över WAN ökar med varje fjärrslav som du lägger till. Detta kan lätt resultera i WAN-länkens mättnad, speciellt om du gör många ändringar och WAN-länken inte har bra genomströmning. Som du kan se i diagrammet ovan, med tre datacenter och tre noder i var och en av dem måste master skicka 6x replikeringstrafiken över WAN-anslutning.
Med Galera-kluster är saker och ting annorlunda. Till att börja med använder Galera flödeskontroll för att hålla noderna synkroniserade. Om en av noderna börjar släpa efter har den en förmåga att be resten av klustret att sakta ner och låta den komma ikapp. Visst, detta minskar prestandan för hela klustret, men det är fortfarande bättre än när du inte riktigt kan använda slavar för SELECT eftersom de tenderar att släpa från tid till annan - i sådana fall kan resultaten du får vara föråldrade och felaktiga.
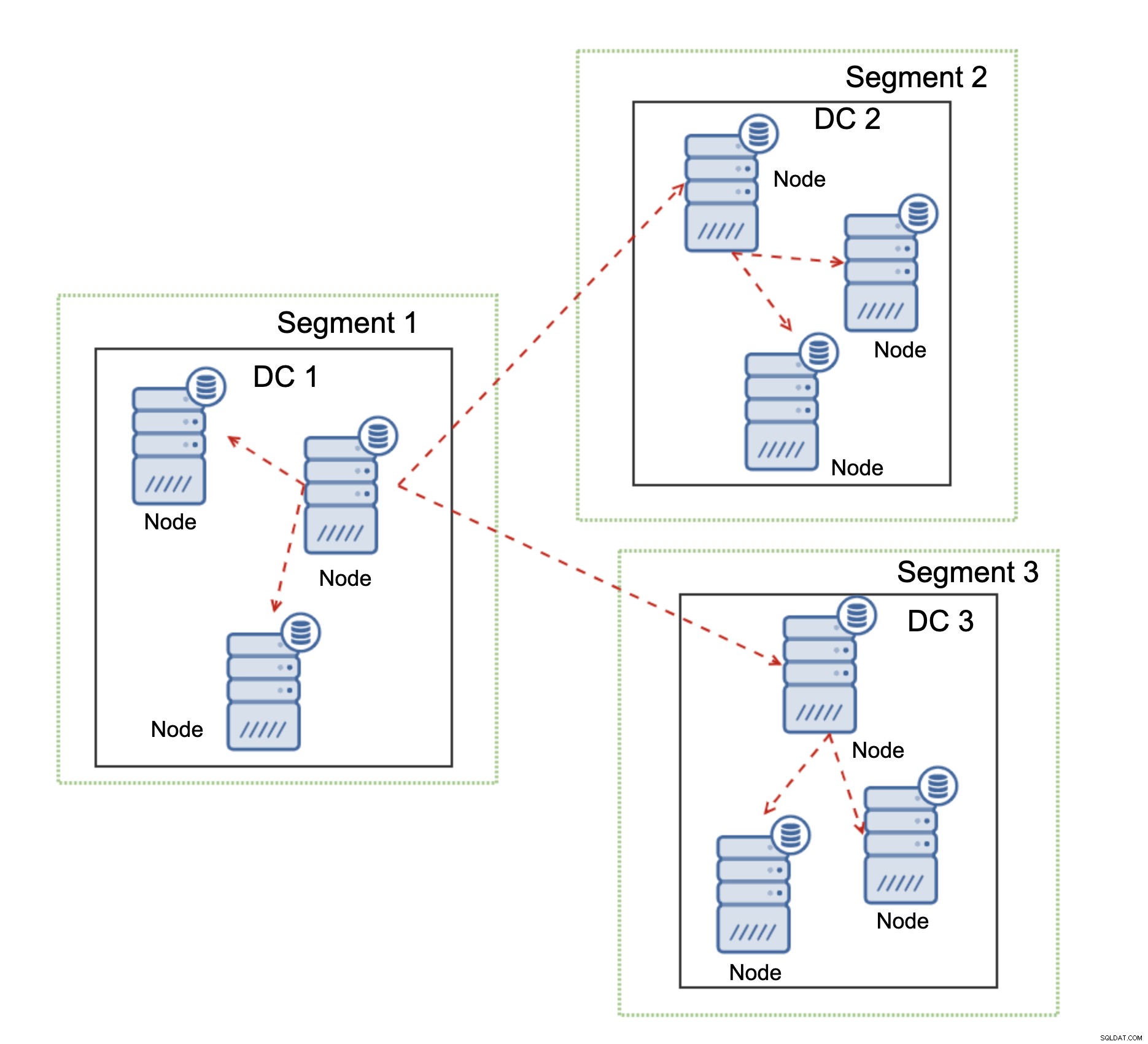
En annan funktion i Galera Cluster, som avsevärt kan förbättra dess prestanda när den används över WAN, är segment. Som standard använder Galera all till all kommunikation och varje skrivuppsättning skickas av noden till alla andra noder i klustret. Detta beteende kan ändras med hjälp av segment. Segment tillåter användare att dela upp Galera-klustret i flera delar. Varje segment kan innehålla flera noder och det väljer en av dem som en relänod. En sådan nod tar emot skrivuppsättningar från andra segment och omfördelar dem över Galera-noder som är lokala för segmentet. Som ett resultat, som du kan se i diagrammet ovan, är det möjligt att minska replikeringstrafiken som går över WAN tre gånger - bara två "repliker" av replikeringsströmmen skickas över WAN:en per datacenter jämfört med en per slav i MySQL-replikering.
Hantering av Galera Cluster Network Partitioning
Där Galera Cluster lyser är hanteringen av nätverkspartitioneringen. Galera Cluster övervakar ständigt tillståndet för noderna i klustret. Varje nod försöker ansluta till sina kamrater och byta tillstånd för klustret. Om en delmängd av noder inte kan nås försöker Galera vidarebefordra kommunikationen så om det finns ett sätt att nå dessa noder kommer de att nås.

Ett exempel kan ses på diagrammet ovan:DC 1 förlorade anslutningen med DC2 men DC2 och DC3 kan ansluta. I det här fallet kommer en av noderna i DC3 att användas för att vidarebefordra data från DC1 till DC2 för att säkerställa att kommunikationen inom kluster kan upprätthållas.
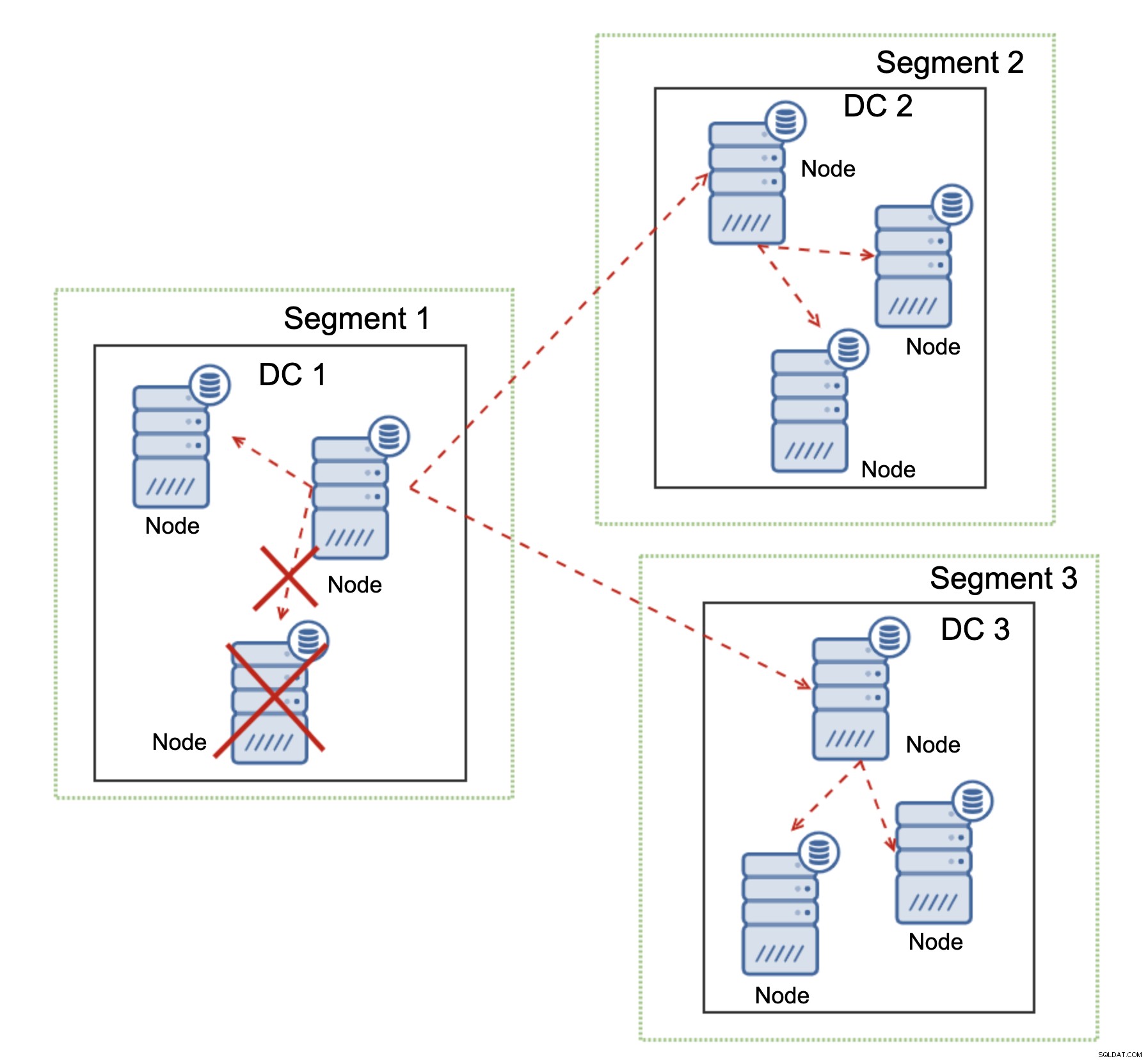
Galera Cluster kan vidta åtgärder baserat på klustrets tillstånd. Den implementerar kvorum - majoriteten av noderna måste vara tillgängliga för att klustret ska kunna fungera. Om noden kopplas bort från klustret och inte kan nå någon annan nod, kommer den att sluta fungera.
Som kan ses i diagrammet ovan, finns det en partiell förlust av nätverkskommunikationen i DC1 och den påverkade noden tas bort från klustret, vilket säkerställer att applikationen inte kommer åt föråldrad data.
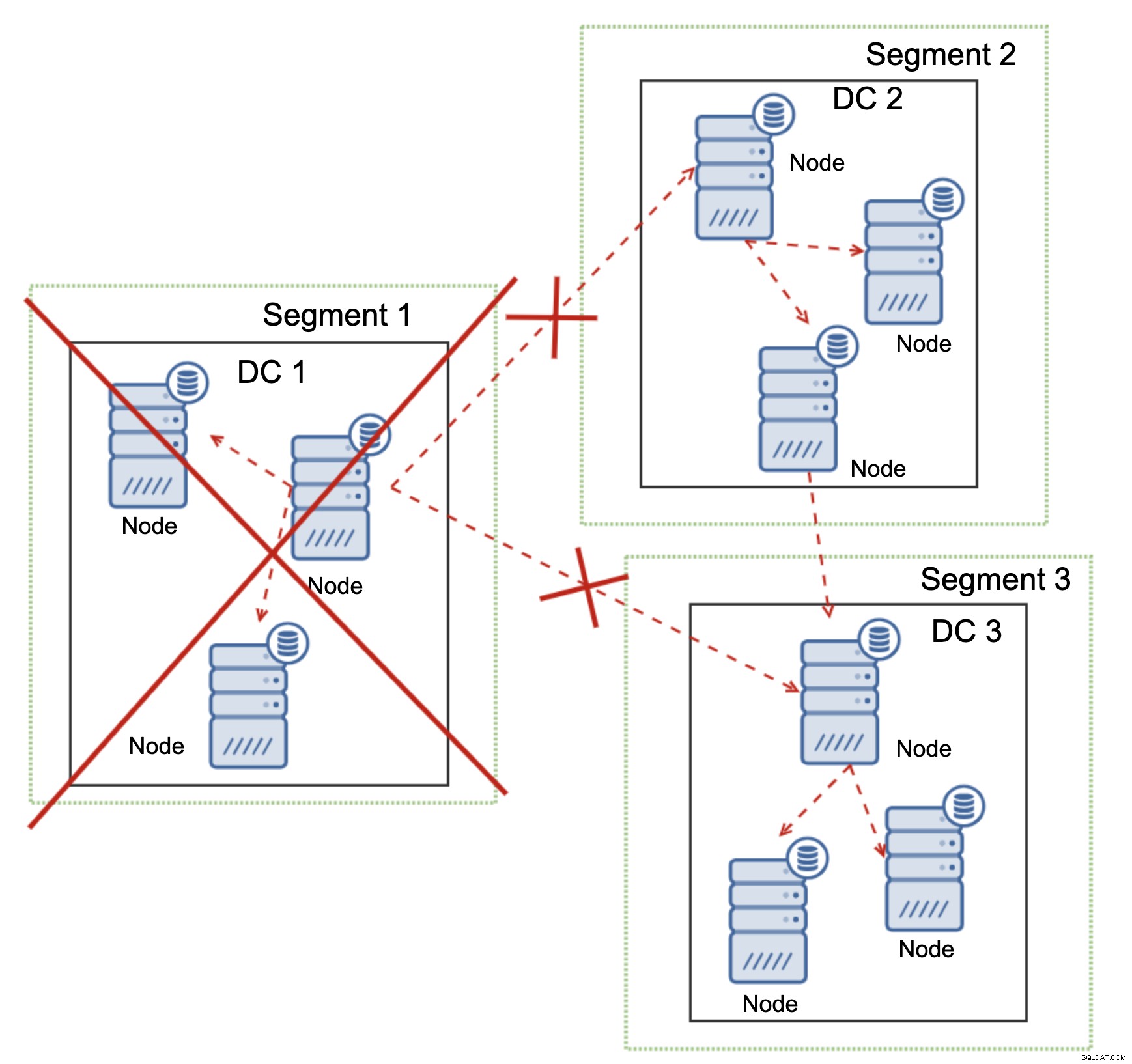
Detta är också sant i en större skala. DC1 fick all kommunikation avbruten. Som ett resultat har hela datacentret tagits bort från klustret och ingen av dess noder kommer att betjäna trafiken. Resten av klustret behöll majoriteten (6 av 9 noder är tillgängliga) och det omkonfigurerade sig för att behålla anslutningen mellan DC 2 och DC3. I diagrammet ovan antog vi att skrivningen träffar noden i DC2, men kom ihåg att Galera kan köras med flera skrivare.
MySQL-replikering har ingen form av klustermedvetenhet, vilket gör det problematiskt att hantera nätverksproblem. Den kan inte stänga av sig själv när kontakten med andra noder tappas. Det finns inget enkelt sätt att förhindra att den gamla mästaren dyker upp efter att nätverket splittrats.
De enda möjligheterna är begränsade till proxylagret eller ännu högre. Du måste designa ett system som skulle försöka förstå klustrets tillstånd och vidta nödvändiga åtgärder. Ett möjligt sätt är att använda klustermedvetna verktyg som Orchestrator och sedan köra skript som kontrollerar tillståndet för Orchestrator RAFT-klustret och, baserat på detta tillstånd, vidtar nödvändiga åtgärder på databaslagret. Detta är långt ifrån idealiskt eftersom varje åtgärd som vidtas på ett lager högre än databasen lägger till ytterligare latens:det gör det möjligt så att problemet dyker upp och datakonsistensen äventyras innan korrekta åtgärder kan vidtas. Galera, å andra sidan, vidtar åtgärder på databasnivå, för att säkerställa snabbast möjliga reaktion.