Om du hanterar en produktionsdatabas är chansen stor att du har varit tvungen att klona din databas till en annan server än produktionsservern. Den grundläggande metoden för att skapa en klon är att återställa en databas från en ny säkerhetskopia till en annan databasserver. En annan metod är att replikera från en källdatabas medan den fortfarande körs, i vilket fall är det viktigt att den ursprungliga databasen inte påverkas av någon kloningsprocedur.
Varför skulle du behöva klona en databas?
Ett klonat databaskluster är användbart i ett antal scenarier:
- Felsök ditt klonade produktionskluster i säkerheten i din testmiljö samtidigt som du utför destruktiva operationer på databasen.
- Lättnings-/uppgraderingstest av en klonad databas för att validera uppgraderingsprocessen innan den appliceras på produktionsklustret.
- Validera säkerhetskopiering och återställning av ett produktionskluster med hjälp av ett klonat kluster.
- Validera eller testa nya applikationer på ett klonat produktionskluster innan det distribueras på det levande produktionsklustret.
- Klona snabbt databasen för revisions- eller informationsefterlevnadskrav, till exempel vid kvartalets eller årsskiftet där innehållet i databasen inte får ändras.
- En rapportdatabas kan skapas med intervaller för att undvika dataändringar under rapportgenereringen.
- Migrera en databas till nya servrar, ny distributionsmiljö eller ett nytt datacenter.
När du kör din databasinfrastruktur i molnet är kostnaden för att äga en värd (delad eller dedikerad virtuell maskin) betydligt lägre jämfört med det traditionella sättet att hyra utrymme i ett datacenter eller äga en fysisk server. Dessutom kan det mesta av molninstallationen automatiseras enkelt via leverantörs-API:er, klientprogramvara och skript. Därför kan kloning av ett kluster vara ett vanligt sätt att duplicera din distributionsmiljö, till exempel, från dev till iscensättning till produktion eller vice versa.
Vi har inte sett den här funktionen erbjudas av någon på marknaden, så det är vårt privilegium att visa upp hur det fungerar med ClusterControl.
Klona ett MySQL Galera-kluster
En av de coola funktionerna i ClusterControl är att du snabbt kan klona ett befintligt MySQL Galera Cluster så att du har en exakt kopia av datamängden på det andra klustret. ClusterControl utför kloningsoperationen online, utan någon låsning eller att det befintliga klustret försvinner. Det är som en klusterskalningsoperation, förutom att båda klustren är oberoende av varandra efter att synkroniseringen är klar. Det klonade klustret behöver inte nödvändigtvis ha samma klusterstorlek som det befintliga. Vi skulle kunna börja med en-nodskluster och skala ut det med fler databasnoder i ett senare skede.
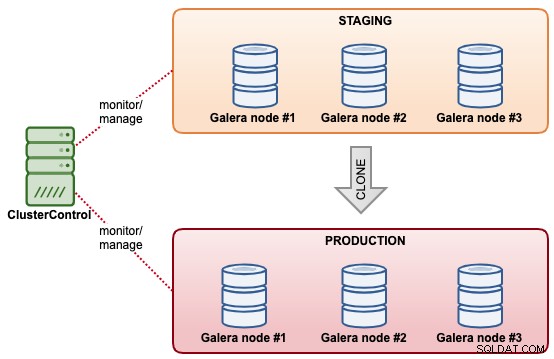
I det här exemplet har vi ett kluster som heter "Staging" som vi skulle vilja klona som ett annat kluster som heter "Production". Utgångspunkten är att iscensättningsklustret redan har lagrat den nödvändiga data som snart kommer att vara i produktion. Produktionsklustret består av ytterligare 3 noder, med produktionsspecifikationer.
Följande diagram sammanfattar den slutliga arkitekturen för vad vi vill uppnå:
Det första du ska göra är att ställa in en lösenordslös SSH från ClusterControl-servern till produktionsservrarna. Kör följande på ClusterControl-servern:
$ whoami
root
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.comAnge root-lösenordet för målservern om du uppmanas.
Från ClusterControls databasklusterlista, klicka på knappen Cluster Action och välj Clone Cluster. Följande guide kommer att visas:
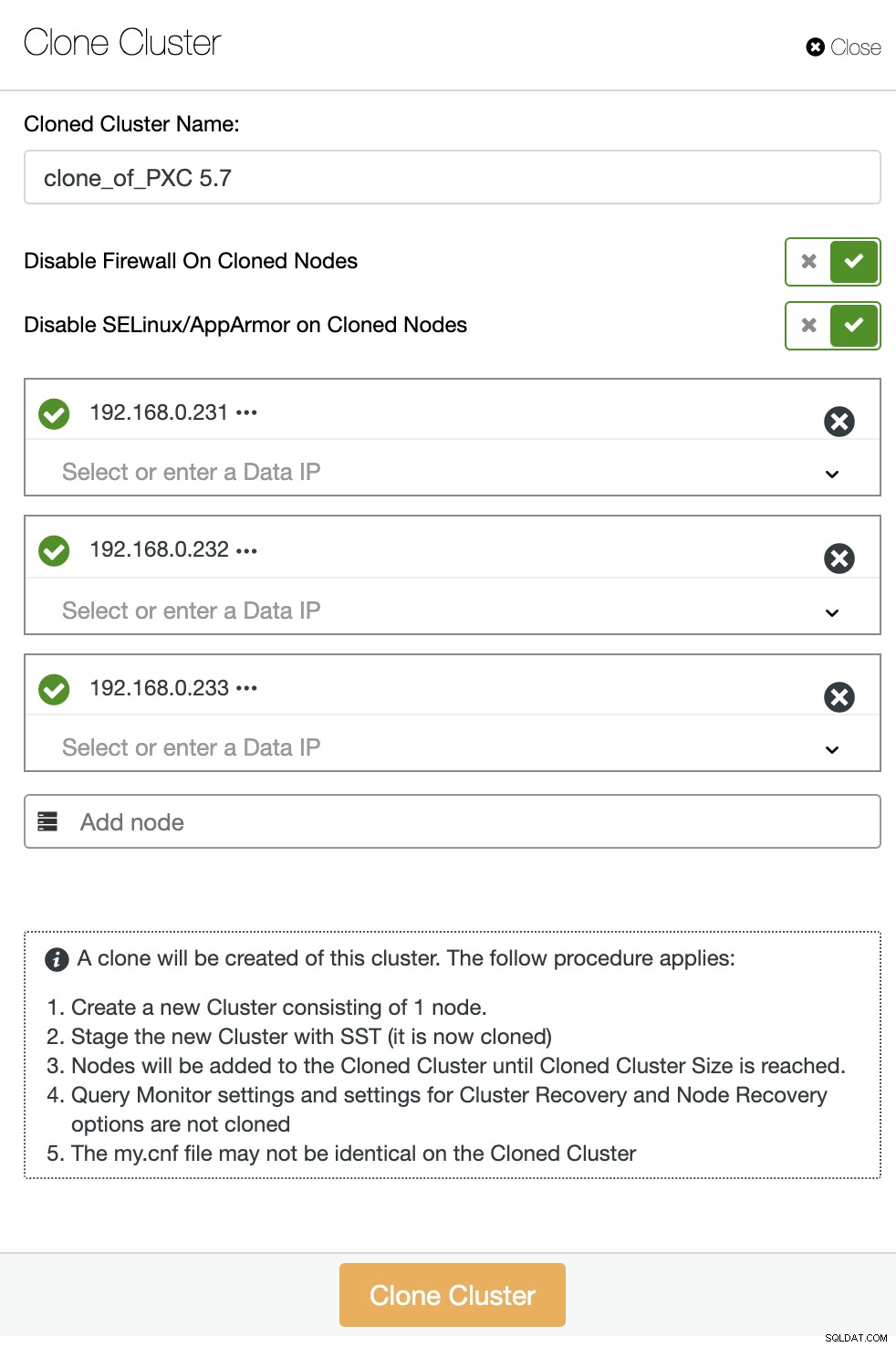
Ange IP-adresserna eller värdnamnen för det nya klustret och se till att du får alla gröna bockikonen bredvid den angivna värden. Den gröna ikonen betyder att ClusterControl kan ansluta till värden via lösenordslös SSH. Klicka på knappen "Klona kluster" för att starta distributionen.
Isättningsstegen är:
- Skapa ett nytt kluster som består av en nod.
- Synkronisera det nya ennodsklustret via SST. Donatorn är en av källservrarna.
- De återstående nya noderna kommer att gå med i klustret efter att donatorn av det klonade klustret har synkroniserats med klustret.
När det är klart kommer ett nytt MySQL Galera-kluster att listas under ClusterControl-klusterinstrumentpanelen när distributionsjobbet är klart.
Observera att klusterkloningen endast klonar databasservrarna och inte hela stacken av klustret. Det betyder att andra stödjande komponenter relaterade till klustret som lastbalanserare, virtuell IP-adress, Galera-arbitrator eller asynkron slav inte kommer att klonas av ClusterControl. Ändå, om du vill klona som en exakt kopia av din befintliga databasinfrastruktur, kan du uppnå det med ClusterControl genom att distribuera dessa komponenter separat efter att databaskloningen har slutförts.
Skapa ett databaskluster från en säkerhetskopia
En annan liknande funktion som erbjuds av ClusterControl är "Skapa kluster från säkerhetskopia". Den här funktionen introduceras i ClusterControl 1.7.1, specifikt för Galera Cluster och PostgreSQL-kluster där man kan skapa ett nytt kluster från den befintliga säkerhetskopian. I motsats till klusterkloning ger den här operationen inte ytterligare belastning till källklustret med en avvägning av att det klonade klustret inte kommer att vara i det aktuella tillståndet som källklustret.
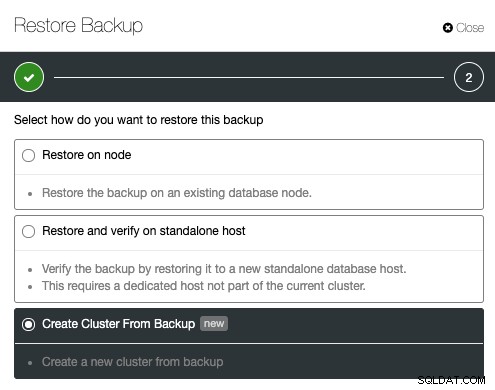
För att skapa ett kluster från en säkerhetskopia måste du skapa en fungerande säkerhetskopia. För Galera Cluster stöds alla backupmetoder medan för PostgreSQL är det bara pgbackrest som inte stöds för ny klusterdistribution. Från ClusterControl kan en säkerhetskopia skapas eller schemaläggas enkelt under ClusterControl -> Backups -> Create Backup. Från listan över skapad säkerhetskopia, klicka på Återställ säkerhetskopia, välj säkerhetskopian från listan och välj "Skapa kluster från säkerhetskopia" från återställningsalternativet:
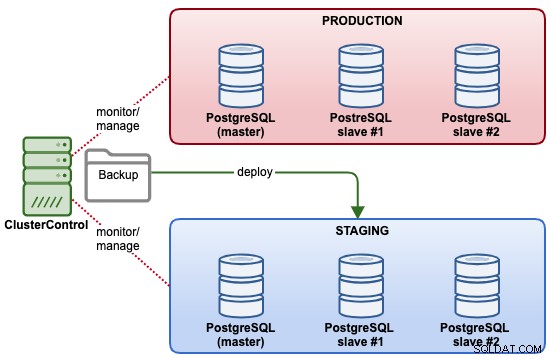
I det här exemplet kommer vi att distribuera ett nytt PostgreSQL Streaming Replication-kluster för iscensättningsmiljö, baserat på den befintliga backup vi har i produktionsklustret. Följande diagram illustrerar den slutliga arkitekturen:
Det första du ska göra är att ställa in en lösenordslös SSH från ClusterControl-servern till produktionsservrarna. Kör följande på ClusterControl-servern:
$ whoami
root
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.comNär du väljer Skapa kluster från säkerhetskopia kommer ClusterControl att öppna en dialogruta för distributionsguiden som hjälper dig att konfigurera det nya klustret:
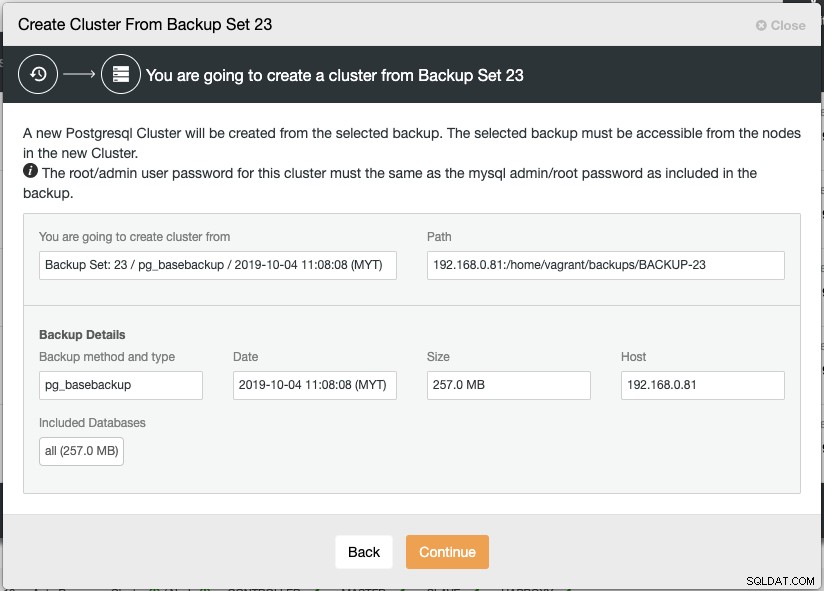
En ny PostgreSQL Streaming Replication-instans kommer att skapas från den valda säkerhetskopian, som kommer att användas som basdatauppsättning för det nya klustret. Den valda säkerhetskopian måste vara tillgänglig från noderna i det nya klustret, eller lagras i ClusterControl-värden.
Om du klickar på "Fortsätt" öppnas standardinstallationsguiden för databaskluster:
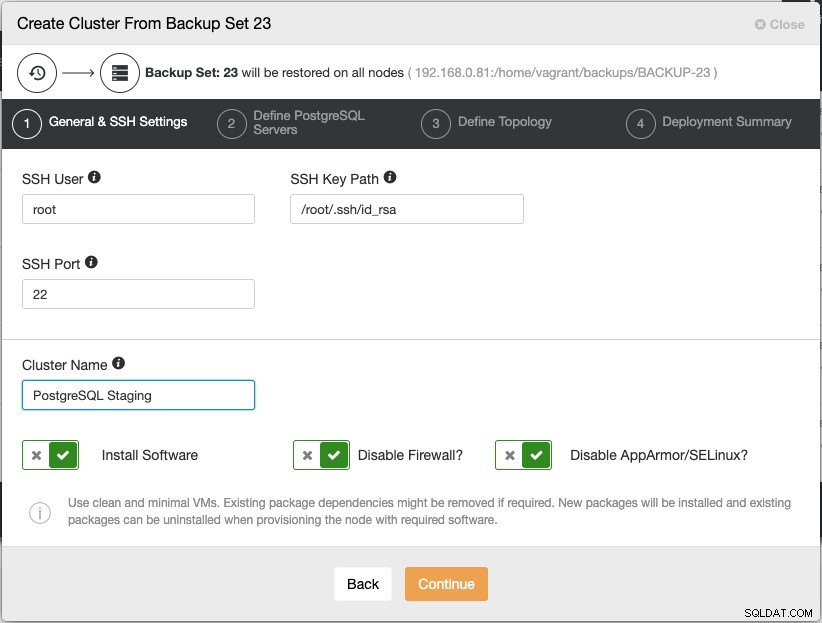
Observera att användarlösenordet för root/admin för detta kluster måste vara detsamma som PostgreSQL-admin/rootlösenordet som ingår i säkerhetskopian. Följ konfigurationsguiden i enlighet med detta och ClusterControl utför sedan distributionen i följande ordning:
- Installera nödvändig programvara och beroenden på alla PostgreSQL-noder.
- Starta den första noden.
- Strömma och återställ säkerhetskopia på den första noden.
- Konfigurera och lägg till resten av noderna.
När det är klart kommer ett nytt PostgreSQL-replikeringskluster att listas under ClusterControl-klusterinstrumentpanelen när distributionsjobbet är klart.