MySQL master-slave replikering är ganska enkel och okomplicerad att ställa in. Detta är den främsta anledningen till att människor väljer denna teknik som det första steget för att uppnå bättre databastillgänglighet. Det kommer dock till priset av komplexitet i förvaltning och underhåll; det är upp till administratören att upprätthålla dataintegriteten, särskilt under failover, failback, underhåll, uppgradering och så vidare.
Det finns många artiklar där ute som beskriver hur man utför failover-operation för replikeringsinställningar. Vi har också behandlat detta ämne i det här blogginlägget, Introduktion till Failover för MySQL-replikering - 101-bloggen. I det här blogginlägget kommer vi att täcka uppgifterna efter katastrofen när vi återställer till den ursprungliga topologin - utför failback-operation.
Varför behöver vi Failback?
Replikeringsledaren (master) är den mest kritiska noden i en replikeringsinställning. Det kräver bra hårdvaruspecifikationer för att säkerställa att det kan bearbeta skrivningar, generera replikeringshändelser, bearbeta kritiska läsningar och så vidare på ett stabilt sätt. När failover krävs under katastrofåterställning eller underhåll är det kanske inte ovanligt att vi marknadsför en ny ledare med sämre hårdvara. Den här situationen kan vara okej tillfälligt, men under lång tid måste den utsedda mastern tas tillbaka för att leda replikeringen efter att den bedöms vara frisk.
I motsats till failover, sker failback-operation vanligtvis i en kontrollerad miljö genom switchover, det händer sällan i panikläge. Detta ger operationsteamet lite tid att planera noggrant och repetera övningen för en smidig övergång. Huvudsyftet är helt enkelt att föra tillbaka den gamla goda mästaren till det senaste tillståndet och återställa replikeringsinställningarna till dess ursprungliga topologi. Det finns dock vissa fall där failback är kritiskt, till exempel när den nyligen befordrade mastern inte fungerade som förväntat och påverkar den övergripande databastjänsten.
Hur gör man Failback säkert?
Efter failover skulle den gamla mastern vara utanför replikeringskedjan för underhåll eller återställning. För att utföra omställningen måste man göra följande:
- Tillsätt den gamla mastern till rätt tillstånd genom att göra den till den mest uppdaterade slaven.
- Stoppa programmet.
- Verifiera att alla slavar är ikapp.
- Marknadsför den gamla mästaren som ny ledare.
- Återpeka alla slavar till den nya mastern.
- Starta applikationen genom att skriva till den nya mastern.
Tänk på följande replikeringsinställningar:
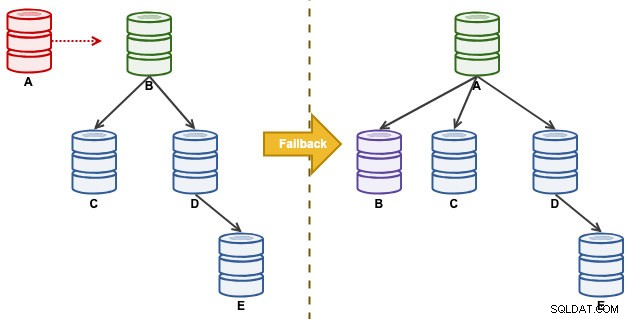
"A" var en master tills en diskfull händelse som orsakade förödelse i replikeringskedjan. Efter en failover-händelse leddes vår replikeringstopologi av B och replikeras till C till E. Failbackövningen kommer att ta tillbaka A som ledare och återställa den ursprungliga topologin före katastrofen. Observera att alla noder körs på MySQL 8.0.15 med GTID aktiverat. Olika större versioner kan använda olika kommandon och steg.
Även om det är så här vår arkitektur ser ut nu efter failover (tagen från ClusterControls Topology-vy):
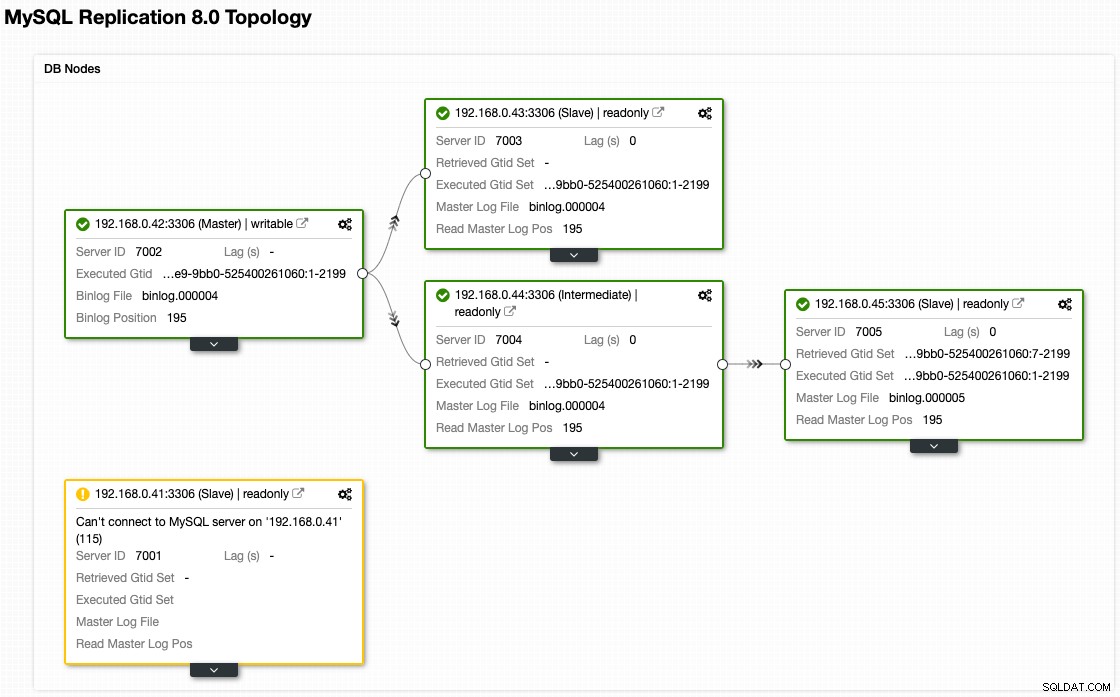
Nodprovisionering
Innan A kan bli en master måste den uppdateras med aktuell databasstatus. Det bästa sättet att göra detta är att göra A som slav till den aktiva mastern, B. Eftersom alla noder är konfigurerade med log_slave_updates=ON (det betyder att en slav också producerar binära loggar), kan vi faktiskt välja andra slavar som C och D som källan till sanning för initial synkronisering. Men ju närmare den aktiva mästaren, desto bättre. Tänk på den extra belastning det kan orsaka när du tar säkerhetskopian. Den här delen tar det mesta av failback-timmarna. Beroende på nodtillstånd och datauppsättningsstorlek kan det ta lite tid att synkronisera den gamla mastern (det kan vara timmar och dagar).
När problemet på "A" är löst och redo att gå med i replikeringskedjan, är det bästa första steget att försöka replikera från "B" (192.168.0.42) med CHANGE MASTER-satsen:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Om replikeringen fungerar bör du se följande i replikeringsstatusen:
Slave_IO_Running: Yes
Slave_SQL_Running: YesOm replikeringen misslyckas, titta på Last_IO_Error eller Last_SQL_Error från slavstatusutdata. Till exempel, om du ser följande fel:
Last_IO_Error: error connecting to master 'example@sqldat.com:3306' - retry-time: 60 retries: 2Sedan måste vi skapa replikeringsanvändaren på den nuvarande aktiva mastern, B:
mysql> CREATE USER example@sqldat.com IDENTIFIED BY 'p4ss';
mysql> GRANT REPLICATION SLAVE ON *.* TO example@sqldat.com;Starta sedan om slaven på A för att börja replikera igen:
mysql> STOP SLAVE;
mysql> START SLAVE;Ett annat vanligt fel du skulle se är denna rad:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: ...Det betyder förmodligen att slaven har problem med att läsa den binära loggfilen från den aktuella mastern. I vissa tillfällen kan slaven vara långt efter där de nödvändiga binära händelserna för att starta replikeringen har saknats från den nuvarande mastern, eller binären på mastern har rensats under failover och så vidare. I det här fallet är det bästa sättet att utföra en fullständig synkronisering genom att ta en fullständig säkerhetskopia på B och återställa den på A. På B kan du använda antingen mysqldump eller Percona Xtrabackup för att ta en fullständig säkerhetskopia:
$ mysqldump -uroot -p --all-databases --single-transaction --triggers --routines > dump.sql # for mysqldump
$ xtrabackup --defaults-file=/etc/my.cnf --backup --parallel 1 --stream=xbstream --no-timestamp | gzip -6 - > backup-full-2019-04-16_071649.xbstream.gz # for xtrabackupÖverför säkerhetskopian till A, återinitiera den befintliga MySQL-installationen för en ordentlig rensning och utför databasåterställning:
$ systemctl stop mysqld # if mysql is still running
$ rm -Rf /var/lib/mysql # wipe out old data
$ mysqld --initialize --user=mysql # initialize database
$ systemctl start mysqld # start mysql
$ grep -i 'temporary password' /var/log/mysql/mysqld.log # retrieve the temporary root password
$ mysql -uroot -p -e 'ALTER USER example@sqldat.com IDENTIFIED BY "p455word"' # mandatory root password update
$ mysql -uroot -p < dump.sql # restore the backup using the new root passwordNär den har återställts, ställ in replikeringslänken till den aktiva master B (192.168.0.42) och aktivera skrivskyddad. På A, kör följande satser:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */För Percona Xtrabackup, se dokumentationssidan om hur man återställer till A. Det innebär ett förutsättningssteg att förbereda säkerhetskopian först innan MySQL-datakatalogen ersätts.
När A har börjat replikera korrekt, övervaka Seconds_Behind_Master i slavstatus. Detta kommer att ge dig en uppfattning om hur långt slaven har lämnat bakom sig och hur länge du behöver vänta innan den kommer ikapp. Vid det här laget ser vår arkitektur ut så här:
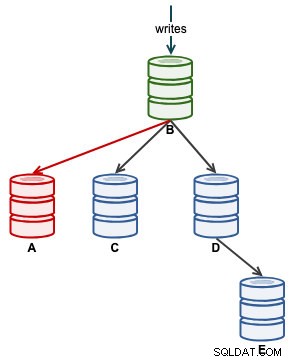
När Seconds_Behind_Master faller tillbaka till 0, är det ögonblicket då A har kommit ikapp som en uppdaterad slav.
Om du använder ClusterControl har du möjlighet att synkronisera om noden genom att återställa från en befintlig säkerhetskopia eller skapa och strömma säkerhetskopian direkt från den aktiva huvudnoden:
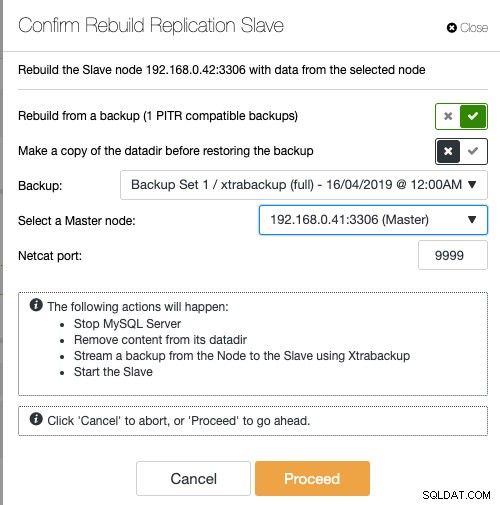
Att iscensätta slaven med befintlig backup är det rekommenderade sättet att göra för att bygga slaven, eftersom det inte påverkar den aktiva huvudservern när noden förbereds.
Marknadsför den gamla mästaren
Innan du marknadsför A som den nya mastern är det säkraste sättet att stoppa all skrivoperation på B. Om detta inte är möjligt, tvinga helt enkelt B att arbeta i skrivskyddat läge:
mysql> SET GLOBAL read_only = 'ON';
mysql> SET GLOBAL super_read_only = 'ON';Kör sedan SHOW SLAVE STATUS på A och kontrollera följande replikeringsstatus:
Read_Master_Log_Pos: 45889974
Exec_Master_Log_Pos: 45889974
Seconds_Behind_Master: 0
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updatesVärdet på Read_Master_Log_Pos och Exec_Master_Log_Pos måste vara identiska, medan Seconds_Behind_Master är 0 och tillståndet måste vara 'Slaven har läst all relälogg'. Se till att alla slavar har bearbetat alla uttalanden i sin relälogg, annars riskerar du att de nya frågorna påverkar transaktioner från reläloggen, vilket utlöser alla möjliga problem (till exempel kan en applikation ta bort några rader som nås av transaktioner från relälogg).
På A, stoppa replikeringen och använd RESET SLAVE ALL-satsen för att ta bort all replikeringsrelaterad konfiguration och inaktivera skrivskyddad:
mysql> STOP SLAVE;
mysql> RESET SLAVE ALL;
mysql> SET GLOBAL read_only = 'OFF';
mysql> SET GLOBAL super_read_only = 'OFF';Vid denna tidpunkt är A redo att acceptera skrivningar (read_only=OFF), men slavar är inte anslutna till den, som illustreras nedan:
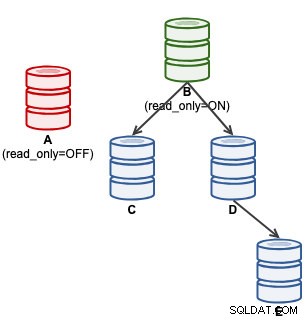
För ClusterControl-användare kan marknadsföring av A göras genom att använda funktionen "Främja slav" under Nodåtgärder. ClusterControl kommer automatiskt att degradera den aktiva master B, befordra slav A som master och peka om C och D för att replikera från A. B kommer att läggas åt sidan och användaren måste uttryckligen välja "Ändra replikeringsmaster" för att återgå till B som replikerar från A i ett senare skede .
Slavrepointing
Det är nu säkert att ändra mastern på relaterade slavar för att replikera från A (192.168.0.41). På alla slavar utom E, konfigurera följande:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.41', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Om du är en ClusterControl-användare kan du hoppa över det här steget eftersom ompekning utförs automatiskt när du bestämde dig för att marknadsföra A tidigare.
Vi kan sedan starta vår applikation för att skriva på A. Vid det här laget ser vår arkitektur ut ungefär så här:
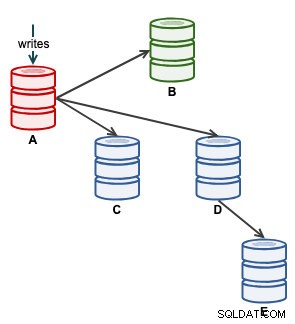
Från ClusterControl-topologivyn har vi återställt vårt replikeringskluster till dess ursprungliga arkitektur som ser ut så här:
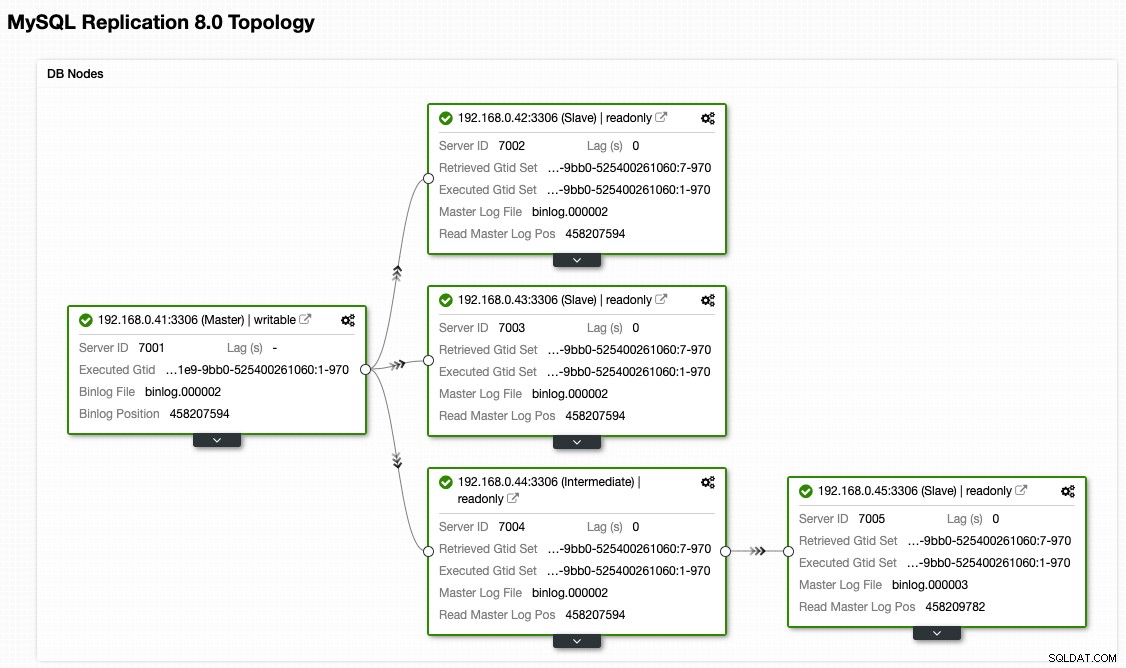
Notera att failback-träning är mycket mindre riskabelt jämfört med failover. Det är viktigt att schemalägga denna övning under lågtrafik för att minimera påverkan på ditt företag.
Sluta tankar
Failover och failback operation måste utföras noggrant. Operationen är ganska enkel om du har ett litet antal noder men för flera noder med komplex replikeringskedja kan det vara en riskabel och felbenägen övning. Vi visade också hur ClusterControl kan användas för att förenkla komplexa operationer genom att utföra dem via användargränssnittet, plus att topologivyn visualiseras i realtid så att du har förståelsen för replikeringstopologin du vill bygga.